A look at two databases that have made claims to the Kubernetes native label: TiDB and DataStax Astra DB.
Революция в области облачных вычислений вдохновила и извлекла выгоду из множества взаимосвязанных тенденций. Доступность общедоступной облачной инфраструктуры самообслуживания способствовала внедрению микросервисных архитектур и методов DevOps, включая автоматизацию и наблюдаемость.
Стремление к контейнеризации и оркестровке контейнеров привело к широкому внедрению Kubernetes в качестве среды для управления облачными приложениями.
<цитата>Но одной из отстающих областей этой революции были данные и инфраструктура данных. Слишком долго данные были чем-то, что существовало за пределами Kubernetes, что приводило к большим дополнительным усилиям и сложности для разработчиков при развертывании облачных приложений.
Одной из часто повторяемых аксиом в первые годы существования Kubernetes было то, что он еще не был готов к рабочим нагрузкам с отслеживанием состояния. К счастью, серьезные изменения происходят незаметно и достигли точки зрелости.
Первоначально преобразование происходило медленно, начиная с усилий по контейнеризации существующих баз данных. Это работало относительно хорошо в небольших базах данных, которые работали на одном вычислительном узле, или в базах данных, разработанных для облачных систем, таких как Apache Cassandra и DynamoDB, но проблемы оставались.
За последние два-три года появилось новое поколение баз данных. Эти «родные» базы данных Kubernetes были разработаны с нуля для работы в этой системе оркестровки с открытым исходным кодом.
Здесь мы определим качества, которые делают базу данных нативной для Kubernetes, и преимущества внедрения нативной базы данных Kubernetes. Для этого мы рассмотрим две базы данных, претендующие на собственный ярлык Kubernetes: TiDB и DataStax Astra DB.
Нативный MySQL Kubernetes с TiDB
Во-первых, давайте рассмотрим базу данных с упором на отношения: TiDB (сокращение от Titanium Database). TiDB — это система с открытым исходным кодом, созданная PingCAP, которая предоставляет базу данных, совместимую с MySQL, и базу данных столбцов. для поддержки гибридной обработки транзакций и аналитики (сокращенно HTAP).
Как показано на рис. 1 ниже, TiDB имеет микросервисный дизайн. Слой запросов TiDB, базы данных TiKV MySQL, столбцовые базы данных TiFlash, узлы Spark и управление метаданными развертываются как масштабируемые микросервисы в своих кластерах. Этот дизайн отделяет работу с интенсивными вычислениями от работы с интенсивным хранением, поскольку уровни запросов и базы данных масштабируются независимо друг от друга.
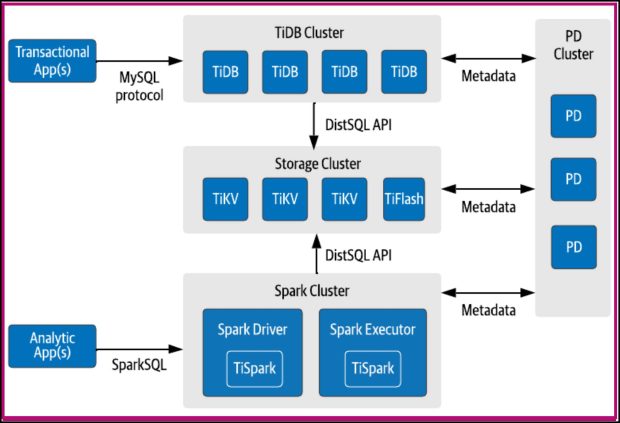
Одно из важнейших обязательств, которое взяли на себя создатели TiDB, заключалось в том, что база данных работает только в Kubernetes.
Достаточно ли этого, чтобы сделать его нативным для Kubernetes?
Давайте копнем немного глубже.
Во-первых, TiDB развертывается и управляется оператором Kubernetes с использованием пользовательских ресурсов ( CRD). CRD TiDB включает TiDBCluster, который позволяет указать масштабирование и конфигурацию каждой микрослужбы, а также то, как компоненты уровня базы данных используют хранилище с помощью постоянных томов Kubernetes. Дополнительные CRD используются для развертывания инструментов мониторинга и управления операционными задачами, такими как резервное копирование и восстановление.
TiDB также имеет дополнительное расширение планировщика, которое взаимодействует с планировщиком K8s по умолчанию, чтобы принимать больше решений по планированию с учетом приложений. Этот акцент на использовании существующих возможностей Kubernetes там, где они доступны, является признаком собственной базы данных Kubernetes.
Kubernetes Native Cassandra с базой данных DataStax Astra DB
Теперь взгляните на другую собственную базу данных Kubernetes и обратите внимание на некоторые сходства и различия.
Cassandra – это масштабируемая база данных NoSQL, был одним из первых, кто объявил себя облачным, но как выглядит развертывание Cassandra в Kubernetes?
DataStax Astra DB — это версия Cassandra, интегрированная в микросервисы, как показано на рис. 2.
Как и TiDB, база данных включает микросервисы, связанные с обработкой запросов и хранением данных, а также сервисы для идентификации и контроля доступа, восстановления данных и резервного копирования/восстановления.
Службы данных особенно интересны тем, что используют хранилище с Постоянные тома Kubernetes используются только для кэширования, а объектное хранилище используется для долгосрочного сохранения. Разделение сжатия на службу позволяет выполнять эту ресурсоемкую обработку в фоновом режиме, не влияя на производительность служб данных, обслуживающих трафик чтения и записи.
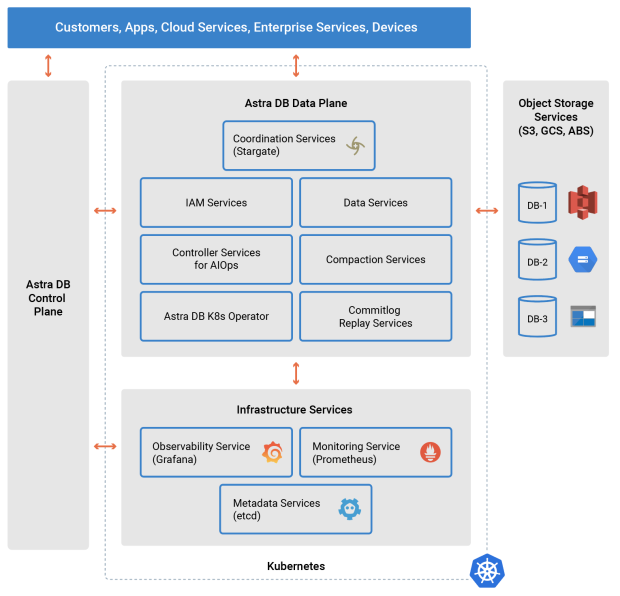
Astra DB предлагается как управляемая служба, доступная в нескольких облачных регионах. Каждый регион содержит уровень данных, состоящий из упомянутых выше сервисов, управляемых оператором Kubernetes, а также сервисов инфраструктуры, включая Kube-Promethus для наблюдения и etcd для управления метаданными.
Плоскости данных управляются плоскостью управления, которая может работать в одном или нескольких облаках для управления учетными записями клиентов и базами данных, а также предоставления кластеров Kubernetes в новых регионах.
Одним из новых аспектов Astra DB является многопользовательская архитектура, в которой несколько пользовательских баз данных могут совместно использовать одни и те же микросервисы и поддерживающую инфраструктуру, что снижает удельную стоимость для небольших пользователей.
По мере расширения своих приложений пользователи могут переходить на выделенные ресурсы для достижения оптимальной производительности в нужном масштабе по принципу оплаты по мере использования. "основа.
Принципы собственной базы данных Kubernetes
Основываясь на наших наблюдениях за TiDB и Astra DB, мы можем сделать некоторые выводы о том, что делает базу данных родной для Kubernetes. Многие из них соответствуют списку принципов работы с облачными данными, который я описал в предыдущая статья:
* Компонуемая микросервисная архитектура. Во-первых, база данных, разбитая на составные микросервисы, позволяет независимо масштабировать каждый сервис. Некоторые типы обработки с интенсивными вычислениями могут быть даже сведены к нулю для настоящего бессерверного решения, особенно в сочетании с многопользовательской архитектурой. * Относитесь к вычислениям, сети и хранилищу как к товарам. Микросервисы, состоящие из собственной базы данных Kubernetes, должны максимально использовать API Kubernetes для управления основными ресурсами облачных приложений: вычислительными ресурсами, такими как StatefulSets и развертывания для управления рабочими нагрузками, подсистема Persistent Volume для хранения, вход и службы Kubernetes для предоставления сетевого доступа к данным и многое другое. Это включает в себя использование возможностей, уже имеющихся в Kubernetes, таких как etcd для управления метаданными, вместо использования компонентов с дублирующей функциональностью. * Использование лучших практик Kubernetes. Использование распространенных шаблонов для приложений Kubernetes принесет множество операционных преимуществ, например, предоставление проверок работоспособности и готовности для каждого микросервиса для повышения доступности и предоставления метрик через API Prometheus PromQL. для наблюдения. По умолчанию сам Kubernetes подает отличный пример, которому должны следовать базы данных для обеспечения безопасности: использование секретов Kubernetes для распространения учетных данных безопасности, предоставление портов только по мере необходимости и т. д. * Декларативное управление с помощью операторов. Собственная база данных Kubernetes должна воплощать в себе принципы декларативного управления Kubernetes с помощью операторов и пользовательских ресурсов, а не полагаться на устаревшие пользовательские интерфейсы управления базами данных и интерфейсы командной строки. При необходимости можно использовать точки расширения Kubernetes, например расширения планировщика, для добавления поведения конкретного приложения. Цель состоит в четком разделении функций плоскости данных (управление данными) и функций плоскости управления (управление базой данных).
Базы данных и другие инфраструктуры данных, которые добросовестно принимают эти принципы, принесут преимущества, в том числе высокую производительность при оптимальной стоимости на всех масштабах, более низкую операционную сложность, что приведет к более быстрому выходу на рынок, и решения, соответствующие стандартам, отвечающие сегодняшним высоким требованиям. требования к доступности и безопасности.
Будущее собственной инфраструктуры данных Kubernetes
Предстоит еще многое сделать, и это касается не только баз данных. Собственные принципы Kubernetes можно применять к другим типам инфраструктуры данных, включая потоковую передачу, аналитику и машинное обучение.
Нативные решения Kubernetes будут продолжать развиваться в мультикластерных и мультиоблачных развертываниях для глобального масштабирования и будут использовать принципы мультиарендности и бессерверности для лучшей оптимизации затрат.
Kubernetes сам по себе может быть улучшен, добавив большую гибкость StatefulSets и поддержку многокластерной федерации.
Ключом к дальнейшему прогрессу является открытое сотрудничество. Сообщество Data on Kubernetes – это очень активная группа специалистов по данным, объединяющая разработчиков приложений, интенсивно использующих данные, и поддерживающей их инфраструктуры.
Присоединяйтесь к нам, чтобы обсудить такие идеи, как разработка повторно используемых операторов, которые могут управлять несколькими базами данных, или определение общего набора CRD для таких концепций, как резервное копирование/восстановление и загрузка данных. Вместе мы продолжим расширять горизонты облачных вычислений на благо всех.
Узнайте больше о нативных базах данных Kassandra и о многом другом на цифровом саммите Cassandra Forward 14 марта 2023 г.< /сильный>
Эта статья основана на главе 7 «Собственная база данных Kubernetes» из книги О'Рейли «Управление облачными данными в Kubernetes", Джефф Карпентер и Патрик Макфадин.
[

Джефф Карпентер, DataStax
Джефф Карпентер работал инженером-программистом и архитектором в различных отраслях, а также адвокатом разработчиков в DataStax, помогая инженерам добиться успеха с Apache Cassandra. Он участвует в нескольких проектах с открытым исходным кодом в экосистемах Cassandra и Kubernetes, включая Stargate и K8ssandra. Он является соавтором книг O’Reilly «Cassandra: The Definitive Guide» и «Managing Cloud Native Data on Kubernetes».