

Держите канал, измените фильтр: более разумный способ к моделям искусственного искусства с тонкой настройкой
1 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
- Предварительный
- Методы
- Эксперименты
- Связанные работы
- Заключение и ссылки
- Детали экспериментов
- Дополнительные экспериментальные результаты
3 Методы
В этом разделе мы разлагаем фильтры свертков на небольшой набор элементов подпространства фильтров, называемый какатомы FITLER.Эта формулировка включает новый метод настройки модели через подпространство фильтра, исключительно регулируя атомы фильтра.
3.1 Сформулирование разложения фильтра
Наш подход включает в себя разложение каждого сверточного слоя F на два стандартных сверточных слоев: слой атома фильтра, который моделирует подпространство фильтрования [1, и слой коэффициента атома α с фильтрами 1 × 1, которые представляют комбинированные правила атомов фильтров, как показано на рисунке 2 (а). Эта формулировка написана как

• Пространственная свертка с D.Каждый канал входных функций x convolers с каждым атомом фильтра отдельно для получения промежуточных функций
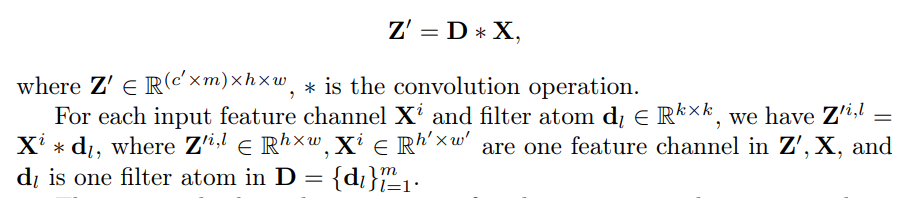
Этот процесс приводит к генерации M различных промежуточных выходных каналов для каждого входного канала, который показан на рисунке 2 (b). На этом этапе атомы фильтров фокусируются только на обработке пространственной информации о входных функциях, а перекрестное смешивание откладывается на следующий шаг.
• Межканальное смешивание с α.Впоследствии коэффициенты атома весят и линейно объединяют промежуточные функции для получения выходных функций
Z = a x z ’
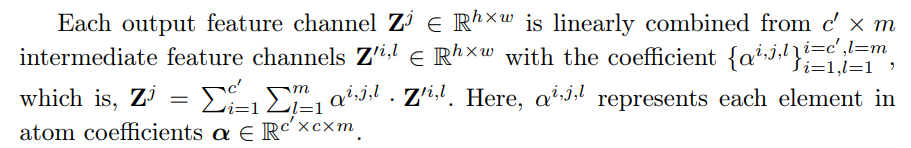
Пространственные инвариантные веса канала, коэффициенты атомаα, служат операторами для смешивания каналов, функционируя в виде различных комбинационных правил, которые строят выходные функции из карт элементарных признаков, генерируемых атомами фильтра. Во время модельной настройки,αполучается из предварительно обученной модели и остается неизменным, в то время как только атомы фильтровДюймовыйадаптироваться к целевой задаче.
Краткое содержание. Двухэтапная операция свертки объясняет различные функции атомов фильтровДюймовыйи коэффициенты атома α, то естьДюймовыйтолько способствует пространственной свертке иαтолько выполняйте межканальное смешивание. На практике операция свертки по -прежнему выполняется как один слой, не генерируя промежуточные функции, чтобы избежать стоимости памяти. В процессе тонкой настройки мы исключительно корректируемДюймовый, который содержит небольшой набор количества параметров, k × k ≪ c ′ × c, тем самым облегчая эффективную точную настройку параметров.
3.2 Overclete Filter Atoms
Параметры атомов фильтра чрезвычайно малы по сравнению с общими параметрами модели. Например, атомы фильтра составляют всего 0,004% от общего количества параметров в Resnet50 [13]. Чтобы полностью исследовать потенциал подпространства фильтров, мы показываем следующий простой способ построить набор атомов фильтра «2] путем повторного применения вышеуказанного разложения к каждому атому фильтра», чтобы расширить пространство параметров для точной настройки по мере необходимости.



3.3 разложение линейных слоев


3.4. Параметр эффективная тонкая настройка

4 эксперименты
В этом разделе мы начинаем с изучения эффективности нашего метода в различных конфигурациях, чтобы определить наиболее подходящий сценарий приложения для каждой конфигурации. Впоследствии мы демонстрируем, что только точные атомы фильтров требуют гораздо меньшего количества параметров при сохранении способности предварительно обученных моделей по сравнению с базовыми методами в контекстах дискриминационных и генеративных задач.
4.1 Экспериментальные настройки
Наборы данныхПолем Наши экспериментальные оценки проводятся в основном на эталоне адаптации визуальной задачи (VTAB) [76], который содержит 19 различных задач визуального распознавания, полученных из 16 наборов данных. В качестве подмножества VTAB VTAB-1K содержит всего 1 000, помеченные в учебные примеры в каждом наборе данных.
МоделиПолем Для эксперимента по проверке мы выбираем Resnet50 [13], предварительно обученные ImageNet-1K. Для дискриминационных задач мы выбираем модель, основанную на свертке, Convnext-B [32], предварительно обученная на ImageNet-21K в качестве инициализации для создания. Для генеративных задач мы выбираем стабильную диффузию [49], которая содержит автоэкодер-фактор с падбампингом 8 с 860 м UNET и Clip Vit-L/14 в качестве текстового кодера для диффузионной модели. Модель предварительно обучена на наборе данных LAION [54], который содержит более 5 миллиардов пар изображений. Более подробная информация о предварительных моделях перечислена в Приложении 7.
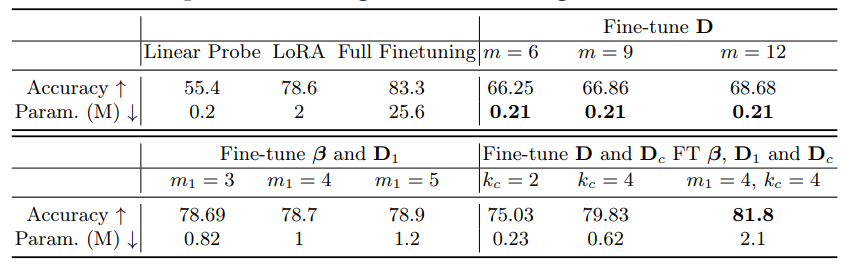
4.2 Эксперименты по проверке
В этом разделе мы изучаем производительность нашего подхода в различных конфигурациях.


4.3 Генеративные задачи
В этом разделе мы применяем наш метод к генеративной задаче, оценивая генеративные образцы из набора данных VTAB [76].
Базовые линииПолем Мы сравниваем наш метод с 6 базовыми подходами точной настройки: (i) Полная точная настройка, которая влечет за собой обновление всех параметров модели во время процесса создания; (ii) Lora [16], включающая введение низкопермерческой структуры накопленного обновления градиента путем разложения его в качестве повышения и понижения. (iii) Loha [71] использует продукт хадамарда в двух наборах декомпозиций с низким уровнем рода, чтобы поднять ранг результирующей матрицы и уменьшить ошибку приближения. (iv) Lokr [71] вводит продукт Kronecker для матричной разложения, чтобы уменьшить настраиваемые параметры. (v) BitFit [74] тонко настраивает термин смещения каждого слоя. (vi) difffit [69] тонко настраивает термин смещения, а также норму слоя и коэффициент масштаба каждого слоя.

![Fig. 5: Fine-tune Stable Diffusion [49] to learn the concept from (a) and generate images using text prompt: “A peacock in front of the ”. (b) Images generated by the pre-trained model, without any fine-tuning, align well with the text prompt but fail to match the target concept. (d) When only fine-tuning the filter atoms D, our approach achieves good alignment with the text prompt and the target concept. (h) However, fine-tuning the spatially-invariant channel weights, i.e., atom coefficients α, results in generated images only align with the target concept, compromising the capability of the pre-trained model of producing diverse images that align with the text prompt. This issue is also observed in (e-g).](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-oi53202.png)


Такие методы, как Лора [16] или полная точная настройка, потенциально обновляют эти α, поэтому они приводят к более низкому разнообразию и выравниванию текста до изображения на сгенерированных изображениях. Напротив, BitFit [74] и Difffit [69] в основном настраивают смещение, оставляя α фиксированным, таким образом, они имеют более высокое разнообразие и выравнивание текста до изображения, чем Лора. Тем не менее, они также сохраняют пространственную операцию D без изменений, что приводит к более низкой оценке верности по сравнению с C2. Больше результатов можно найти в Приложении 8.
Сравнение производительности при образовании генеративного переноса.Мы сообщаем о FIDS моделей, обученных и оцененных по задачам VTAB в таблице 3. В отличие от полной настройки и LORA, наш подход достигает самых низких показателей FID (54,7 V.S.5.5). При использовании наименьшего количества параметров точной настройки (1,11 мкв. 22,67 м). Несмотря на точную настройку только 0,13% от общих параметров модели, наш метод эффективно адаптирует предварительно обученную стабильную диффузию, чтобы выровнять ее с желаемым распределением целей.
4.4 Дискриминационные задачи
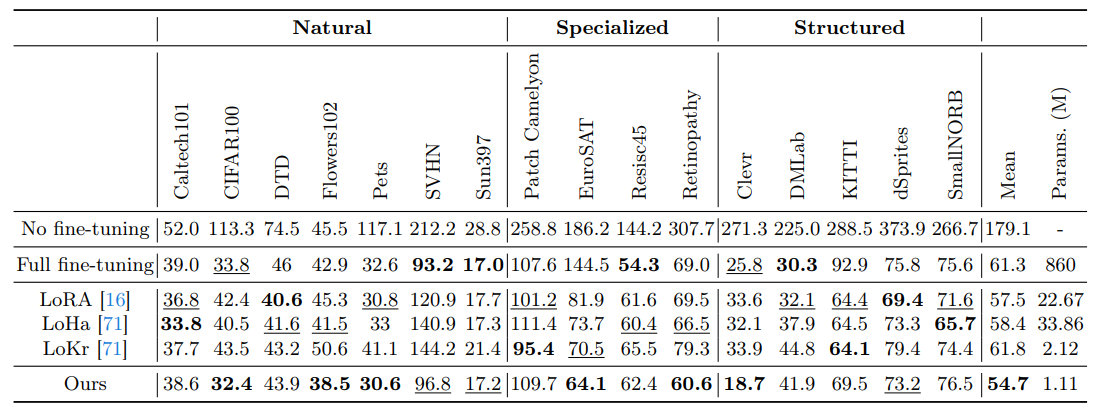
В этом разделе мы применяем наш метод к дискриминационной задаче, а именно классификации на VTAB-1K [76]. Мы сравниваем наш метод с 4 базовыми подходами тонкой настройки: (i) Полная точная настройка, (ii) линейное зондирование, (iii) BitFit [74] и (iv) Lora [16].
Детали реализации.Изображения изменяются до 224 × 224, после настройки по умолчанию в VTAB [76]. Мы используем оптимизатор ADAMW [33] для моделей тонкой настройки для 100 эпох. Стратегия распада косинуса принята для графика обучения, а линейная разминка используется в первые 10 эпох.
В этом эксперименте мы точно настраиваем D и DC, сохраняя фиксированные α и αC, так как эта конфигурация обеспечивает достаточную точность без увеличения параметров.
Сравнение производительности при нескольких выстрелах.Мы сравниваем производительность нашего подхода и других базовых методов, а также результаты
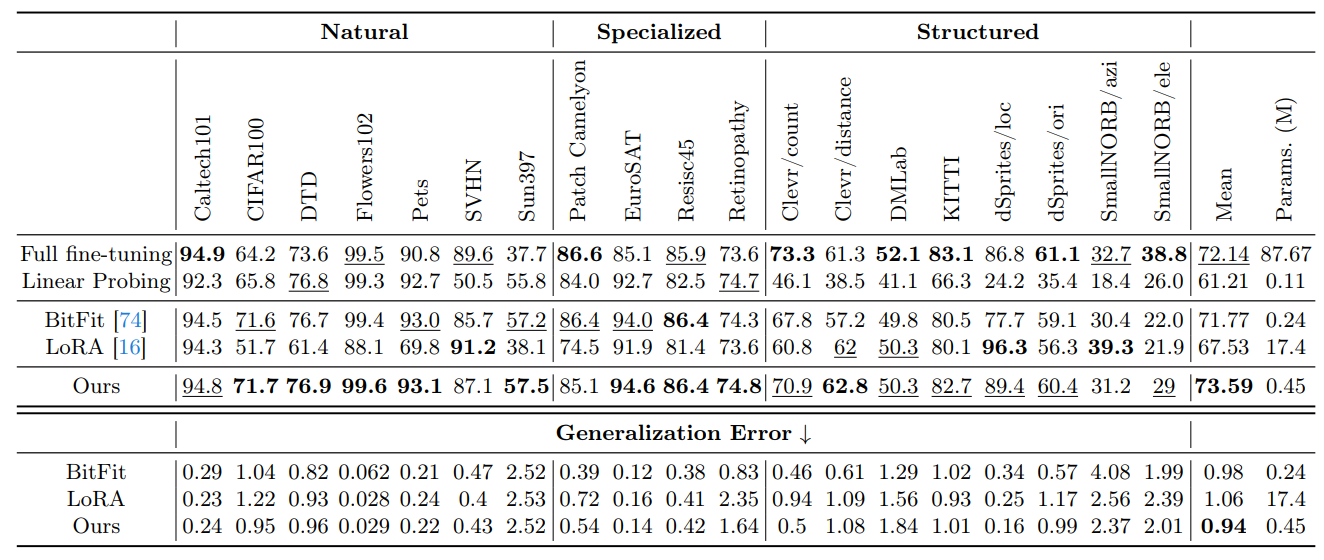
На VTAB-1K показаны в таблице 4. В этих таблицах жирный шрифт показывает наилучшую точность всех методов, а подчеркнутый шрифт показывает вторую лучшую точность. Наш метод превосходит другие методы точной настройки и даже превосходит полную точную настройку. В частности, наш метод получает на 6% повышение точности по сравнению с LORA на эталонном эталоне VTAB-1K, используя значительно меньше обучаемых параметров (0,45 м против 17,4 м).
Ошибка обобщения измеряется расхождением между потерей обучения и потерей теста, при этом результаты показаны в таблице 4 и рисунке 7 из Приложения 8. Наша техника, в которой используются фиксированные коэффициенты атома, приводит к сравнительно более низкой ошибке обобщения. Это означает, что наш метод настройки лучше сохраняет способность обобщения предварительно обученной модели.
Авторы:
(1) Вэй Чен, Университет Пердью, Индиана, США (chen2732@purdue.edu);
(2) Zichen Miao, Университет Пердью, Индиана, США (miaoz@purdue.edu);
(3) Qiang Qiu, Университет Пердью, Индиана, США (qqiu@purdue.edu).
Эта статья есть
[1] Подпространство фильтра представляет собой промежуток атомов M фильтра D.

Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)