

Нагрузочное тестирование производительности IoT с помощью Locust и Azure
9 января 2023 г.В настоящее время сквозное тестирование функциональных и нефункциональных требований является обязательным, но требует много времени и может быть решено с использованием нескольких инструментов и подходов. В этой статье рассказывается, как протестировать производительность системы Интернета вещей с помощью Locust и Azure.
Определение области тестирования и требований необходимо для максимизации ценности полученных результатов. Сосредоточение внимания на метриках с более высоким ROI имеет решающее значение (те, которые легко измеримы и имеют высокую ценность для команды разработчиков). Метрики представляют собой объективные измерения производительности системы и зависимых переменных:
* Конфигурация инфраструктуры (узлы кластера, ЦП, память, реплики и т. д.) * Конфигурация EventHub (TU, количество разделов, группы потребителей и т. д.) * Масштабируемость и надежность архитектуры решения
Тесты производительности помогают нам понять, как системы ведут себя при определенной нагрузке: количество телеметрических данных, отправляемых устройством в секунду, умножается на общее количество устройств. Областью тестирования является платформа IoT и интеграция Azure EventHub (это не цель тестирование устройства IoT). Ключевые показатели для измерения производительности решения:
* Время задержки приема событий EventHub (мс) * Коэффициент потерь событий (%)
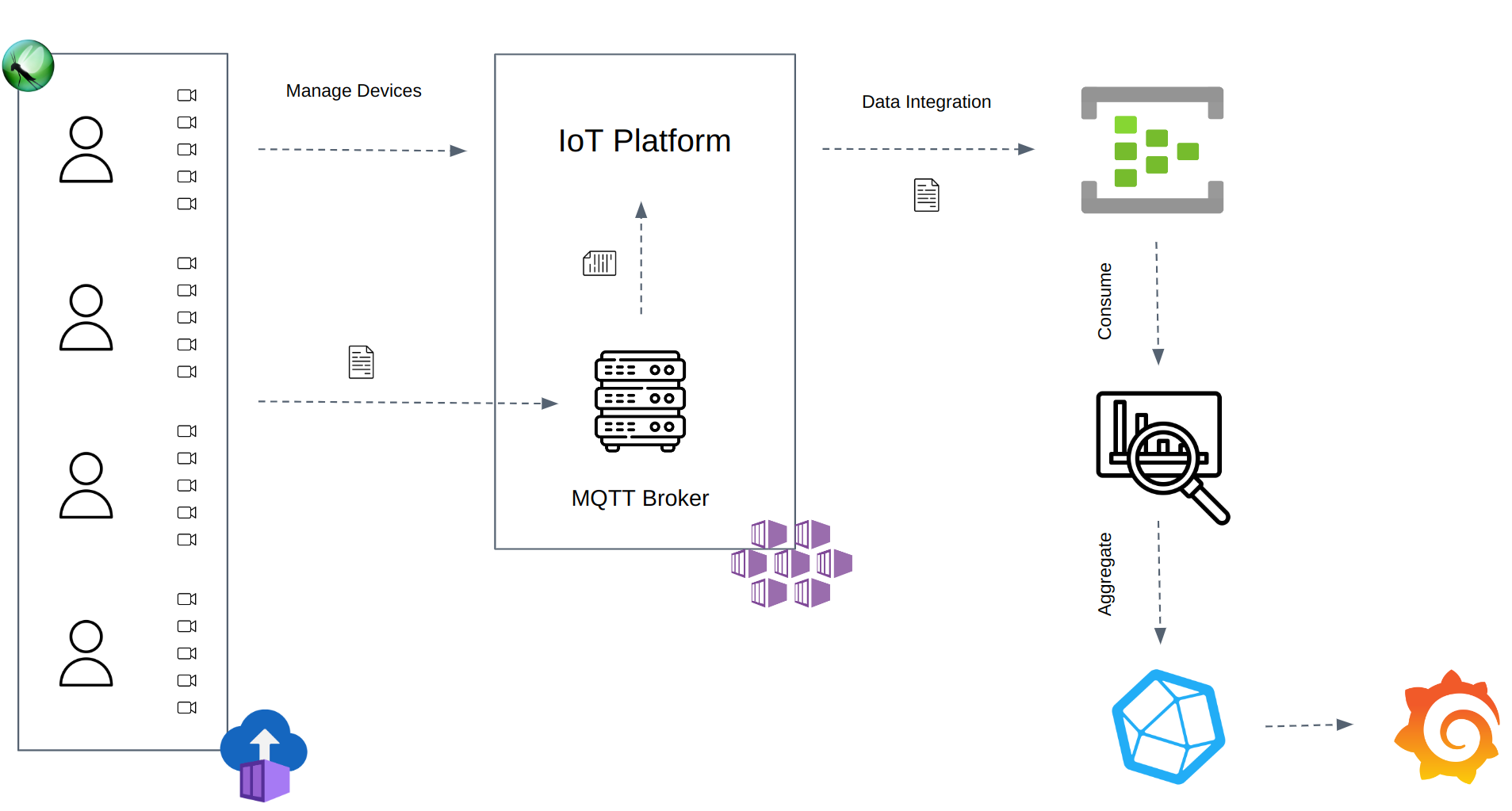
Инструменты и инфраструктура
Саранча
Locust – это инструмент для проверки производительности Python, который официально поддерживает протокол HTTP/HTTPS, но разработчик может расширить его для тестирования любого протокола или системы. Пользователи могут обернуть протокол или системную библиотеку и запускать события Locust после каждого запроса, чтобы информировать Locust о статусе теста.
Оболочка библиотеки Paho-MQTT является одним из решений для тестирования протокол MQTT и системы Интернета вещей. В Locust есть несколько плагинов, которые расширяют поддерживаемые протоколы и системы:
* https://github.com/SvenskaSpel/locust-plugins
Экземпляр контейнера Azure
Azure Container Instances предлагает простой способ настройки, развертывания и запуска нескольких автоматических управляемые контейнеры. Это служба по требованию, которая позволяет запускать любой контейнер с помощью облака.
Azure EventHub
Azure EventHub — это масштабируемая служба приема данных, управляемая Azure. Продукты Azure могут использовать исходящие сообщения для их анализа, а затем сообщать об анализе на панели мониторинга (Streaming Analytics и PowerBI). Кроме того, Azure разработала несколько пакетов SDK EventHub для обработки исходящих событий и реализации вашей бизнес-логики.
Технический подход
Цель этой статьи – дать обзор общей реализации и архитектуры решения. Подробное техническое объяснение выходит за рамки. Чтобы узнать больше о реализации, воспользуйтесь следующей ссылкой для просмотра исходного кода решения:
* https://github.com/joan-mido-qa/mqtt-locust-on-azure .
Репозиторий содержит пример платформы для тестирования производительности системы IoT с использованием Locust.
Развернуть
Каждый контейнер (основной/рабочий и потребитель Locust) можно легко развернуть с помощью действия Azure GitHub: aci-deploy . Альтернативой GitHub Actions является Terraform. Вы можете определить свою тестовую инфраструктуру с помощью плана Terraform и применить ее с помощью рабочего процесса GitHub.
Главный узел подключил общую папку (учетные записи хранения Azure) для сохранения журналов тестовой настройки и отчетов в формате HTML.
Действие может быть запущено автоматически любым событием GitHub или вручную пользователем. Используя пользовательский интерфейс GitHub, пользователь может определить входные данные теста: время выполнения, скорость создания, количество пользователей и т. д. Количество развернутых рабочих узлов зависит от количества устройств (~ 500 устройств на одного рабочего)
Потребитель также использует действие aci-deploy. Пользователь может развернуть Consumer, указав имя контейнера, регион Azure, имя EventHub, строку подключения и группу потребителей.
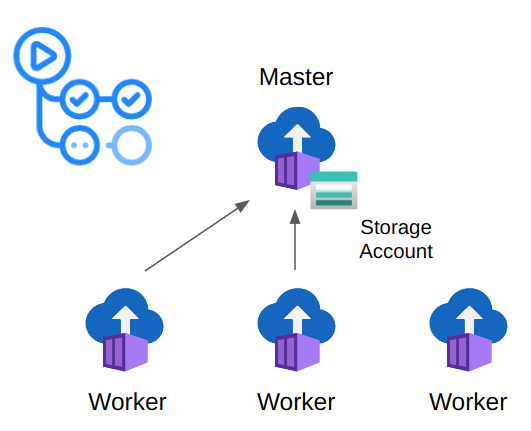
Тест производительности
Системы IoT используют протокол MQTT. Устройства могут публиковать данные телеметрии по теме с помощью брокера MQTT. Затем подписчики могут выбрать тему для подписки и получать телеметрию из подписки. В этом случае платформа IoT получает и обрабатывает данные телеметрии, отправленные устройствами, чтобы передать их в EventHub. Для сквозного тестирования системы используется Locust для подключения нескольких IoT-устройств к брокеру MQTT и публикации телеметрии с постоянной пропускной способностью. EventHub получает телеметрию от платформы IoT после обработки. Наконец, потребитель EventHub считывает исходящие данные телеметрии, чтобы агрегировать количество полученных событий и время задержки приема.
Центральный процессор и память ограничивают максимальное количество пользователей на экземпляр Locust (~ 500-750 пользователей). Locust может работать в распределенном режиме, чтобы преодолеть эти ограничения и создать тысячи пользователей. В тесте используются экземпляры контейнеров Azure для запуска основных и рабочих процессов Locust и потребителей событий. Потребитель событий читает исходящие сообщения EventHub и выгружает агрегированные измерения в базу данных InfluxDB.
Наконец, Grafana строит и отображает результаты производительности, используя данные InfluxDB. InfluxDB вычисляет общее количество телеметрий, телеметрий в минуту и время задержки nth% процентиля, используя агрегированные данные от потребителя.
Показатели
1. Время задержки приема события (мс)
Время задержки приема измеряется как время постановки события в очередь минус время отправки события. Locust добавляет метку времени к каждой отправке данных телеметрии.
2. % потерянных данных телеметрии:
Полученные события/Отправленные данные телеметрии
Отчет
Locust использует плагин InfluxDB собственной разработки, чтобы сообщать о количестве устройств и телеметрии (объяснение реализации плагина выходит за рамки этой статьи). InfluxDB вычисляет каждую метрику с помощью Flux, языка запросов INfluxDB.
Grafana используется не только для визуализации и анализа результатов производительности, но и для мониторинга системной инфраструктуры: ЦП кластера, памяти, узла, модулей и т. д.
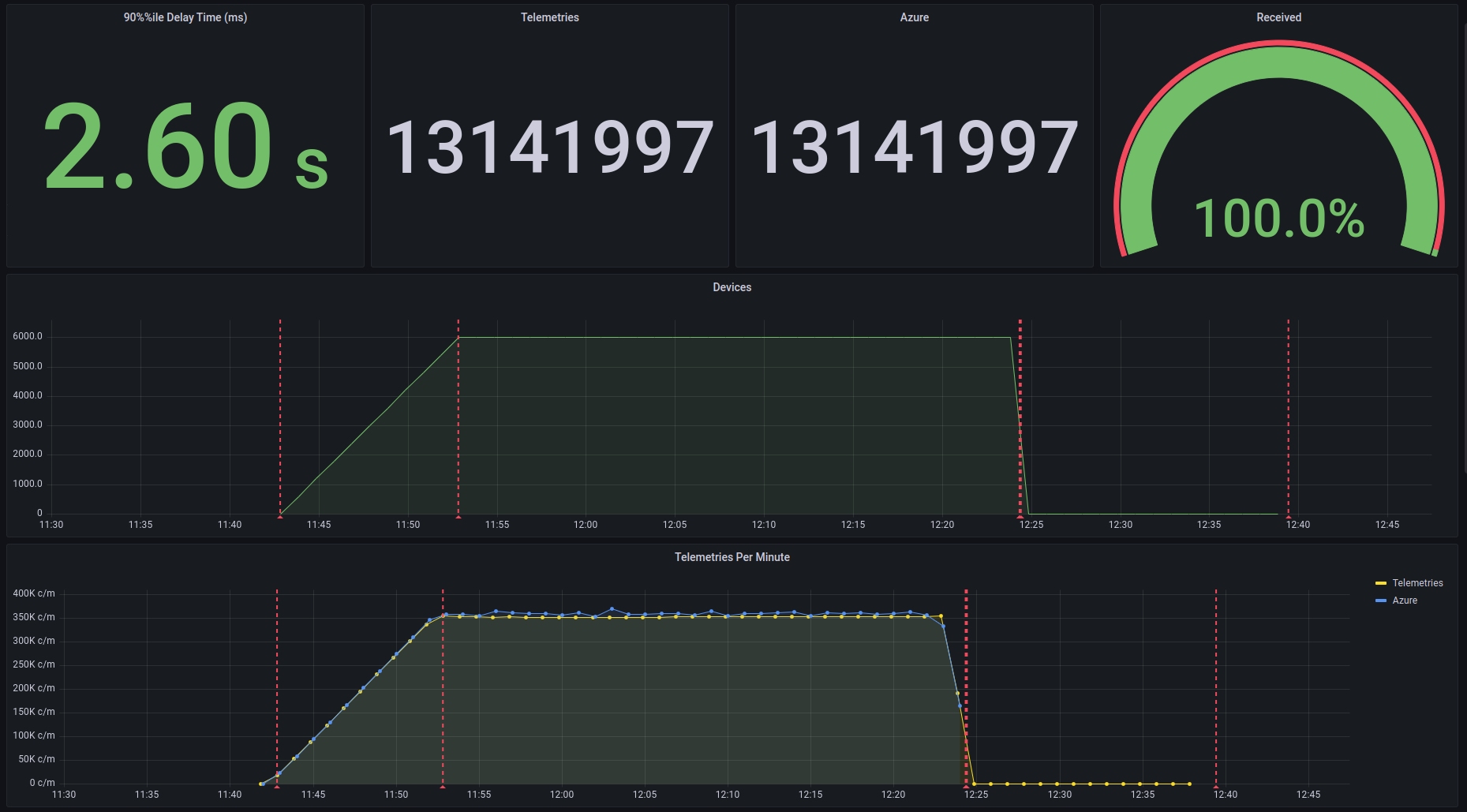
Реализованные решения
Документирование общего решения и проблем, возникающих на этапе разработки, помогает понять архитектуру решения и технические решения. Цель раздела — обсуждение проблем, возникших при разработке, и реализованного решения.
Количество событий
Получить определенное количество событий в минуту, агрегировать статистику и сбросить ее в базу данных — непростая задача. Одним из требований теста была поддержка нагрузки 340к событий в минуту. Это не только количество событий, но и их размер. Чтобы справиться с огромным объемом исходящих данных, были реализованы следующие решения:
- Используйте несколько потребителей для чтения из разных разделов EventHub.
- Не сбрасывайте все события в базу данных. Потребитель агрегирует данные по количеству событий, полученных за время задержки. Каждая строка имеет UUID, чтобы избежать переопределения строк данных при выгрузке в InfluxDB.
| Время постановки в очередь | Время задержки | Граф | UUID | |----|----|----|----| | 20:00:00 | 1000 | 5 | 704b496b-… | | 20:00:00 | 1050 | 2 | 704b496b-… | | 20:01:00 | 1000 | 10 | 704b496b-… | | 20:01:00 | 950 | 7 | 704b496b-… |
* InfluxDB агрегирует данные перед их отображением в Grafana:
# 95% Delay Time Percentile
getFieldValue = (tables=<-, field) => {
extract = tables
|> map(fn: (r) => ({ r with _value: r._value * 95 / 100 }))
|> findColumn(fn: (key) => key._field == field, column: "_value")
return extract[0]
}
total = from(bucket: "")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "data")
|> filter(fn: (r) => r["run_id"] == "$run_id")
|> filter(fn: (r) => r["_field"] == "count")
|> drop(columns: ["uuid", "delay_ms"])
|> sum()
|> getFieldValue(field: "count")
from(bucket: "")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "data")
|> filter(fn: (r) => r["run_id"] == "$run_id")
|> filter(fn: (r) => r["_field"] == "count")
|> keep(columns: ["delay_ms", "_value"])
|> sum()
|> group()
|> map(fn: (r) => ({ r with delay_ms: int(v: r.delay_ms) }))
|> sort(columns: ["delay_ms"])
|> cumulativeSum(columns: ["_value"])
|> filter(fn: (r) => r._value < total)
|> last()
|> keep(columns: ["delay_ms"])
# Number of Telemetries per Minute
from(bucket: "")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "data")
|> filter(fn: (r) => r["run_id"] == "$run_id")
|> filter(fn: (r) => r["_field"] == "count")
|> drop(columns: ["uuid", "delay_ms"])
|> window(every: 1m)
|> sum()
|> group()
# Number of Telemetries
from(bucket: "")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "data")
|> filter(fn: (r) => r["run_id"] == "$run_id")
|> filter(fn: (r) => r["_field"] == "count")
|> drop(columns: ["uuid", "delay_ms"])
|> sum()
Количество устройств на одного работника
Paho-MQTT использует метод select(..)`, который зависит от переменной FD_SETSIZE (FD_SETSIZE ограничивает количество открытых файлов). Компиляция Python использует фиксированный FD_SETSIZE=1024. Каждый клиент MQTT открывает три файла на одно соединение: 3 * 340 = 1020. У каждого рабочего есть ограничение в ~250-300 устройств, потому что Locust также открывает файл для каждого пользователя. Чтобы создать 6 тысяч устройств, Azure необходимо запустить 24 контейнера.
Запуск большого количества рабочих процессов увеличивает вероятность ошибки. В редких случаях рабочие не могут успешно настроить среду или подключиться к мастеру, что приводит к сбою теста при запуске. Чтобы увеличить количество устройств на одного работника и сделать тест подверженным ошибкам, было реализовано следующее решение:
* Используйте сценарий оболочки, чтобы увеличить программный лимит открытых файлов, и запустите саранчу в качестве точки входа в контейнер:
ulimit -Sn 10000
* Переопределить клиент MQTT `_loop(..)`, чтобы использовать Python селекторы вместо выбрать. Селекторы используют метод, который лучше всего подходит для вашей ОС:
import selectors
class MqttClient(Client):
[...]
def _loop(self, timeout: float = 1.0) -> int:
if timeout < 0.0:
raise ValueError("Invalid timeout.")
sel = selectors.DefaultSelector()
eventmask = selectors.EVENT_READ
with suppress(IndexError):
packet = self._out_packet.popleft()
self._out_packet.appendleft(packet)
eventmask = selectors.EVENT_WRITE | eventmask
if self._sockpairR is None:
sel.register(self._sock, eventmask)
else:
sel.register(self._sock, eventmask)
sel.register(self._sockpairR, selectors.EVENT_READ)
pending_bytes = 0
if hasattr(self._sock, "pending"):
pending_bytes = self._sock.pending()
# if bytes are pending do not wait in select
if pending_bytes > 0:
timeout = 0.0
try:
events = sel.select(timeout)
except TypeError:
return int(MQTT_ERR_CONN_LOST)
except ValueError:
return int(MQTT_ERR_CONN_LOST)
except Exception:
return int(MQTT_ERR_UNKNOWN)
socklist: list[list] = [[], []]
for key, _event in events:
if key.events & selectors.EVENT_READ:
socklist[0].append(key.fileobj)
if key.events & selectors.EVENT_WRITE:
socklist[1].append(key.fileobj)
if self._sock in socklist[0] or pending_bytes > 0:
rc = self.loop_read()
if rc or self._sock is None:
return int(rc)
if self._sockpairR and self._sockpairR in socklist[0]:
socklist[1].insert(0, self._sock)
with suppress(BlockingIOError):
# Read many bytes at once - this allows up to 10000 calls to
# publish() inbetween calls to loop().
self._sockpairR.recv(10000)
if self._sock in socklist[1]:
rc = self.loop_write()
if rc or self._sock is None:
return int(rc)
sel.close()
return int(self.loop_misc())
Выводы
Данные необходимы для принятия обоснованных решений. Вот почему тестирование необходимо для решения известной проблемы. Тестирование позволяет нам понять текущий статус продукта в отношении конкретных требований и помогает нам решить, какие шаги следует предпринять дальше.
Определите выходные метрики в зависимости от полученной технической ценности. Избегайте измерения дорогостоящих и не имеющих технической ценности показателей, чтобы не добавлять шума в анализ производительности. Избегайте разработки чрезмерно сложного решения, установив четкую область тестирования и правильно собрав требования к производительности от групп разработчиков и разработчиков продукта. Лучше протестировать конкретное требование и получить быструю обратную связь, чем пытаться протестировать все возможные сценарии и не получить достаточно отзывов.
Производительность системы зависит от дизайна и архитектуры инфраструктуры продукта. Различные конфигурации инфраструктуры могут привести к совершенно разным результатам. Тестирование системы помогло нам понять, как она ведет себя в зависимости от нагрузки входящих событий, и сфокусироваться на узких местах. Анализ результатов послужил руководством для четкого определения требований к инфраструктуре для оптимальной работы системы при определенной нагрузке.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27471)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)