
Представление Speechverse: крупномасштабная обобщаемая модель аудио-языка
18 июня 2025 г.Авторы:
(1) Nilaksh Das, AWS AI Labs, Amazon и равный вклад;
(2) Saket Dingliwal, AWS AI Labs, Amazon (skdin@amazon.com);
(3) Шрикант Ронанки, AWS AI Labs, Amazon;
(4) Рохит Патури, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Цзе Юань, AWS AI Labs, Amazon;
(8) Дхануш Бекал, AWS AI Labs, Amazon;
(9) Син Ниу, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Карел Мунднич, AWS AI Labs, Amazon;
(13) Моника Сункара, AWS AI Labs, Amazon;
(14) Даниэль Гарсия-Ромеро, AWS AI Labs, Amazon;
(15) Кю Дж. Хан, AWS AI Labs, Amazon;
(16) Катрин Кирххофф, AWS AI Labs, Amazon.
Таблица ссылок
Аннотация и 1 введение
2 подхода
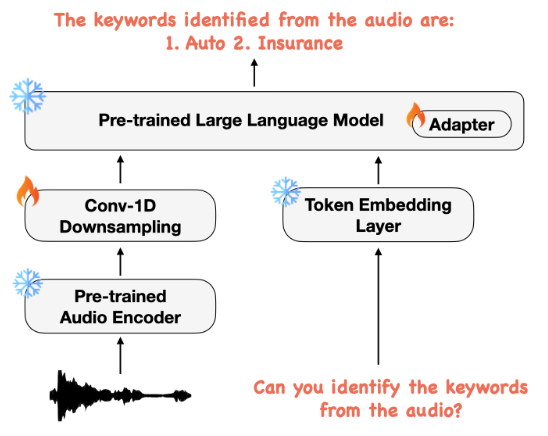
2.1 Архитектура
2.2 Multimodal Trancing Paneletuning
2.3 Учебное обучение программы с эффективным характеристиком параметров
3 эксперименты
4 Результаты
4.1 Оценка моделей речи.
4.2 Обобщение между инструкциями
4.3 Стратегии повышения производительности
5 Связанная работа
6 Заключение, ограничения, заявление о этике и ссылки
Приложение
A.1 Audio Encoder перед тренировкой
A.2 Гиперпараметры
A.3 Задачи
Абстрактный
Большие языковые модели (LLMS) показали невероятные знания в выполнении задач, которые требуют семантического понимания инструкций естественного языка. В последнее время многие работы дополнили эту возможность воспринимать мультимодальные аудио и текстовые входы, но их возможности часто ограничиваются конкретными тонкими задачами, такими как автоматическое распознавание речи и перевод. Поэтому мы разрабатываем речи, надежную многозадачную учебную структуру и учебную структуру, которая сочетает в себе модели речевого и текстового основания с помощью небольшого набора обучаемых параметров, сохраняя при этом предварительно обученные модели заморожены во время обучения. Модели создаются инструкции с использованием непрерывных скрытых представлений, извлеченных из модели речевого фонда, для достижения оптимальной производительности с нулевым выстрелом при разнообразных задачах обработки речи с использованием инструкций естественного языка. Мы выполняем обширный анализ, который включает в себя сравнение нашей модели производительности с традиционными базовыми показателями в нескольких наборах данных и задачах. Кроме того, мы оцениваем возможность модели для обобщенных инструкций, следуя тестированию на наборах данных вне доменов, новых подсказок и невидимых задач. Наши эмпирические эксперименты показывают, что наша многозадачная речевая модель даже превосходит традиционные базовые показатели, специфичные для задачи на 9 из 11 задач.
1 Введение
Большие языковые модели (LLMS) [1–3] достигли замечательных результатов по различным задачам естественного языка посредством самоотверженного предварительного обучения по массовым текстовым корпусам. Они также продемонстрировали поразительную способность следовать открытым инструкциям от пользователей посредством дальнейшей настройки инструкций [4–7], что обеспечивает сильные возможности обобщения. Несмотря на успех, значительное ограничение заключается в неспособности языковых моделей воспринимать не текстовые методы, такие как изображения и аудио.
Речь, в частности, представляет собой наиболее естественный способ человеческого общения. Расширение прав и возможностей LLM для глубокого понимания речи может значительно улучшить взаимодействие человека с компьютером [8] и мультимодальные диалогового агента [9, 10]. Таким образом, позволив LLMS понимать речь
В последнее время существенное внимание. Некоторые подходы сначала транскрибируют речь через систему автоматического распознавания речи (ASR), а затем обрабатывают текст с LLM для улучшения транскрипции [11–13]. Тем не менее, такие трубопроводы не могут отражать не текстовые паралингвистические и просодические особенности, такие как тон динамика, интонация, эмоция, валентность и т. Д.
Новая многообещающая парадигма напрямую объединяет текстовые LLM с речевыми кодерами в рамках с конечной учебной системой [14, 15]. Включение совместного моделирования речи и текста имеет обещание для более богатых речевых и звуковых методов по сравнению с методами только текста. В частности, модели, посвященные инструкциям мультимодального аудиоязычия [16–18], все чаще получают больше внимания благодаря своей возможности обобщения. Несмотря на некоторый успех, существующие работы в многозадачных звукоязычных моделях, таких как SpeechT5 [19], Whisper [20], Виола [15], SpeechGPT [18] и SLM [17] ограничены обработкой небольшого количества речевых задач.
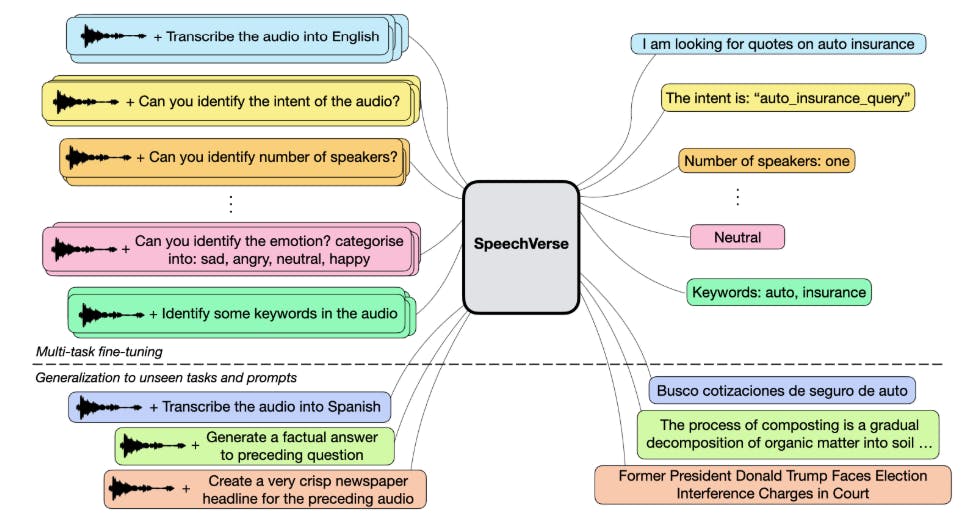
Поэтому мы предлагаем Sherceverse, надежную многократную структуру, которая использует контролируемое обучение, чтобы включить различные задачи речи (см. Рисунок 1). В отличие от SpeechGPT [18], мы предлагаем использовать непрерывные представления, извлеченные из самоотверженной предварительно обученной модели речевого фонда, фокусируясь на задачах, которые генерируют только текстовый выход. Совсем недавно [16] предложил Qwen-Audio, многозадачную аудиоязычную модель, способную воспринимать человеческие речи и звуковые сигналы, и обучается 30 задачам из различных типов аудио, включая музыку и песни. Тем не менее, это требует тщательно разработанного иерархического помечения и широкомасштабного контролируемого аудиокодера для Fusion, что делает его неоптимальным для невидимых речевых задач. Напротив, наша учебная парадигма включает в себя многозадачное обучение и контролируемое обучение в единой учебной программе, без необходимости тегации специфических для задачи, что позволяет обобщать невидимые задачи с использованием инструкций естественного языка.
Мы суммируем наши вклад ниже:
Масштабируемое мультимодальное обучение, создание для разнообразных задач речи.Speechverse-это новая аудиоязычная структура на основе LLM, которая масштабируется, демонстрируя сильные показатели на целых 11 разнообразных задачах. Мы тщательно сравниваем наши модели по общедоступным наборам данных, охватывающим ASR, понимание разговорного языка и паралингвистические речевые задачи.
Универсальное обучение после возможности для новых открытых задач.Мы демонстрируем способность речевой модели использовать надежное языковое понимание основы LLM, чтобы адаптироваться к открытым задачам, которые были невидимыми во время мультимодального создания.
Стратегии улучшения обобщения до невидимых задач.Мы дополнительно изучаем стратегии подсказки и декодирования, включая ограниченные и совместные декодирование, которые могут повысить способность модели обобщать до совершенно невидимых задач, улучшая абсолютные показатели до 21%.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)