
Несбалансированные наборы данных и как правильно с ними работать
24 декабря 2022 г.С момента зарождения машинного обучения несбалансированные наборы данных досаждали всем, кто работал над проблемами классификации.
По правде говоря, обработка несбалансированного набора данных не так уж сложна, если вы знаете, что делаете. Если нет, я познакомлю вас с концепцией проблем классификации, расскажу о реальных примерах и поделюсь эффективными способами обработки несбалансированных данных.
Что такое проблемы классификации в машинном обучении?
Для тех, кто только сейчас изучает… машинное обучение… я включу это краткое введение в проблемы классификации. Это поможет вам лучше понять общую концепцию статьи.
Задачи классификации — это контролируемое обучение, которые классифицируют данные в несколько категорий (метки классов). Если таких категорий всего две, то это называется бинарной классификацией. Для меток нескольких классов мы используем термин полиномиальная классификация.
Наиболее распространенным примером бинарной классификации является определение того, является ли электронное письмо спамом или нет. Классификатор будет маркировать электронные письма на основе предоставленных ему образцов данных. Обычно он делает вывод, что электронные письма, содержащие определенные фразы, такие как печально известный «нигерийский принц» скорее является спамом, чем нет.
Алгоритм полиномиальной классификации будет делать то же самое, но он должен быть более сложным и способным помечать электронные письма как рекламные материалы, новости или любую другую категорию, которую вы придумаете.
Когда и почему возникают несбалансированные наборы данных?
Теперь, когда мы знаем, что такое проблемы классификации, давайте сосредоточимся на несбалансированных наборах данных.
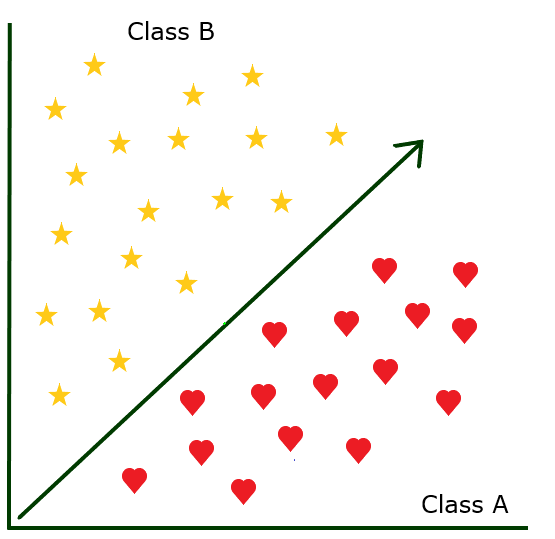
Если один ярлык класса имеет значительно более низкую частоту наблюдений, чем другие ярлыки классов в том же наборе данных, мы отмечаем этот набор данных как несбалансированный.
Используя наш предыдущий пример с электронной почтой, если классификатор обнаружил только пару писем со спамом при проверке тысяч, то у вас есть несбалансированный набор данных. На практике около 50% всех отправляемых писем являются спамом. Это означает, что классификатор либо проверял набор писем, которые уже были отобраны, либо просто не работал должным образом.
Как обращаться с несбалансированными данными?
Существуют десятки способов управления несбалансированными наборами данных, но я сосредоточусь на объяснении самых популярных из них. Их можно использовать для устранения 99,9 % проблем с дисбалансом данных, с которыми вы можете столкнуться.
А как насчет 0,01%? Что с ними делать?
Большинство людей никогда не столкнется с такими специфическими примерами несбалансированных данных. Если вы это сделаете, вам потребуются годы опыта для создания индивидуального решения. Простая статья, как бы блестяще она ни была написана, ничем вам не поможет.
Недостаточная выборка & Передискретизация
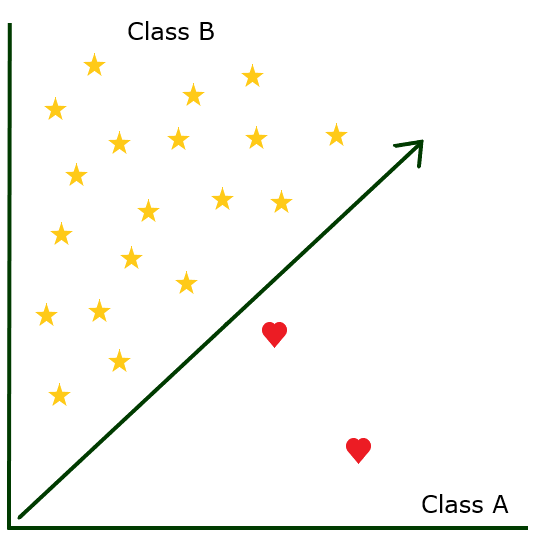
Недостаточная выборка означает, что вы уменьшаете размер большинства классов. Это довольно простой метод обработки несбалансированных данных, но он отлично работает при работе с бинарной классификацией. Самый эффективный способ недостаточной выборки — сохранить все экземпляры из редкого класса и случайным образом выбрать экземпляры из богатого класса.

Перевыборка работает наоборот. Вы сохраняете все образцы из богатого класса, но добавляете в набор данных несколько новых копий всего редкого класса. Подобно недостаточной выборке, избыточная выборка наиболее эффективна при решении проблем бинарной классификации.
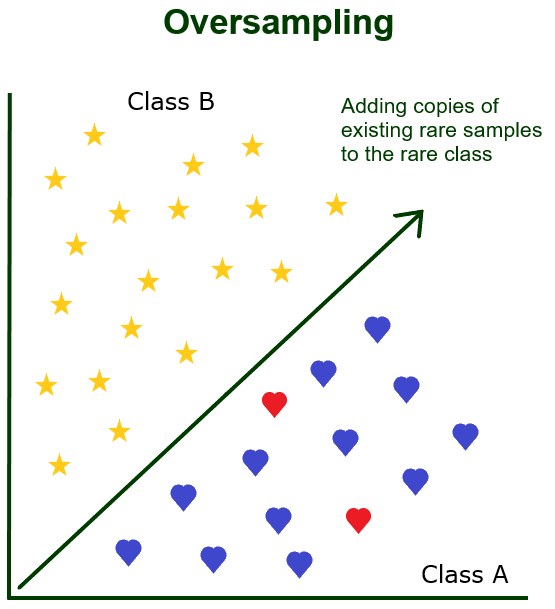
Оба метода гарантируют, что вы создадите новый набор данных, который будет сбалансированным и с ним будет проще работать. Ваш классификатор сможет узнать больше и лучше предсказать будущие результаты, просматривая больше «плохих» выборок.
Перераспределить class_weight
Я не большой поклонник этой техники, потому что считаю ее слишком сложной без веской на то причины. Однако многие хотели бы посадить меня в тюрьму за науку о данных, если бы я не представил ее здесь, так что давайте быстро взглянем.
Параметр class_weight присутствует почти во всех популярных библиотеках моделей классификаторов. Значение class_weight по умолчанию равно 0, поэтому модель автоматически присваивает веса различным классам, которые обратно пропорциональны численности. Искажая параметры class_weight и применяя функцию потери журнала в качестве основы стоимости, вы можете «наказать» свой классификатор гораздо строже, когда он ошибочно классифицирует редкий образец, чем ошибочную классификацию обильного образца.
Изменить критерии оценки
В то время как два вышеупомянутых метода касались данных, представляемых классификатору, этот метод изменяет сам классификатор. Во-первых, нужно решить, что нужно изменить и почему. Это делается с помощью показателей оценки.
Проще говоря, метрики оценки — это то, что используется для изменения качества модели машинного обучения. Хотя их существует много, пять, которые я считаю абсолютно необходимыми:
- Точность, точность, полнота
- Оценка F1
- AUC/РПЦ
- Категорная кроссэнтропия
- Журнал потерь
Возьмем другой гипотетический пример. Наша модель пытается предсказать, станет ли когда-нибудь Опра богом-императрицей нашей планеты. Будем надеяться, что модель каждый раз говорит НЕТ в зависимости от того, как вы ее построили.
Точность – это главный критерий оценки, и это первое, что мы будем использовать для оценки нашей модели.
A = (TN+TP)/(FP+TP+TN+FN)
TP – истинное положительное
TN — истинно отрицательный
FP — ложное срабатывание
FN — ложноотрицательный результат
Применив приведенную выше формулу, вы получите 99,5%. Ваша модель точна на 99,5%. Это помогло? Ни в малейшей степени. У вас все еще есть несбалансированный набор данных, и вы знаете, что он точен. Но это не поможет вам ничего предсказать.
Далее следует Точность.
P = (TP)/(FP+TP)
n Он используется для проверки того, сколько из предсказанных положительных результатов были истинными положительными результатами. Поскольку мы никогда не предсказывали положительный результат, это бесполезно. По сути, это говорит о том, что наша модель не очень хороша, но ничем нам не помогает.
На отзыв.
R = (TP)/(TP+FN)
n Мы используем отзыв, чтобы проверить, сколько из истинных срабатываний имеют правильные метки классов. Поскольку у нас нет истинных положительных результатов, мы не можем его использовать.
Далее у нас есть F1 Score, это мой личный фаворит. Если вам интересно, почему я удосужился расписать приведенные выше примеры точности и полноты, мы скоро к этому вернемся. Показатель F1 всегда равен числу от 0 до 1 и представляет собой среднее гармоническое точности и полноты.
F1 = 2(P*R/P+R)
Когда формула применяется к нашей проблеме Опры, мы получаем 0. Поскольку F1 является довольно продвинутой оценочной метрикой, мы можем сказать, что наша модель совершенно бесполезна для этого конкретного набора данных, и решить решить нашу проблему с несбалансированным набором данных, построив другую модель. .
Реальные примеры несбалансированных наборов данных
Если вы профессиональный аналитик данных и столкнулись с несбалансированными данными в реальной жизни, обычно стоит изучить его.
Отличный пример можно найти в финансах. Если вы работаете в банке и пытаетесь предсказать мошенничество с кредитными картами, вы столкнетесь с несбалансированными наборами данных. Конкуренция между мошенниками и моделями машинного обучения продолжается уже давно, и каждая сторона находит новые способы «перехитрить» другую.

В здравоохранении прогностические модели используются для более точной диагностики различных заболеваний и уже несколько десятилетий спасают жизни людей. Как вы можете себе представить, самые редкие заболевания создают несбалансированные наборы данных, и классификаторы учатся на них, чтобы помочь врачам с диагнозами, которые редко приходят на ум.
Наконец, у нас так много примеров несбалансированных наборов данных в маркетинге, что иногда мне кажется, что некоторые решения были созданы исключительно для того, чтобы помочь маркетологам продавать больше услуг. Текучесть клиентов, запросы на возмещение и даже судебные иски против компаний могут привести к несбалансированности наборов данных, и опережение этого имеет неоценимое значение для ведущих компаний.
Заключительные мысли
К тому времени, когда я закончил писать эту статью, я удалил свой первоначальный вывод (да, я всегда пишу эту часть первой) и решил написать новый. Я сделал это, потому что был уверен, что это будет короткая и приятная статья, которую легко читать и писать.
Однако я обнаружил, что постоянно отвлекаюсь, пытаясь объяснить различные принципы машинного обучения, придумывая новые примеры и тому подобное. Я даже узнал несколько новых вещей, проверяя себя при внесении правок.
Я считаю себя ветераном машинного обучения, но каждый раз, когда пишу подобную статью, я напоминаю себе, что изначально меня в ней взволновало. Это бездонная яма (в хорошем смысле) теорий, проблем и решений, созданных на благо человечества.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27156)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)