

Я думал, что у меня есть возможность наблюдать — моя краткая история DNS
15 ноября 2022 г. <цитата>Я думал, что у меня есть возможность наблюдать, но этого было недостаточно.
Картинка выше говорит мне, что вы должны знать свою инфраструктуру и прислушиваться к собственным советам.
Привет, гениальный человек! Как оказалось, в критической среде возникла проблема.
Как можно предотвратить подобные проблемы до того, как они повлияют на клиентов? Я расскажу вам чуть позже в этой статье.
Если вы читаете это, скорее всего:
- У вас есть или были похожие проблемы с DNS или симптомы DNS
- Вы трудолюбивы и хотели бы научиться не наступать на грабли
:::предупреждение Если у вас нет времени читать, и вы хотите сразу увидеть решение, например, как вы просматриваете все ответы на stackoverflow в поисках отмеченного решения, затем прочитайте это подробное руководство по устранению неполадок AWS DNS. .
:::
:::предупреждение Еще один спойлер: официальная документация Kubernetes относится к использованию NodeLocal DNSCache. Это неверный путь, и он не устранит основную причину.
:::
Эта статья поможет вам, если у вас есть один из следующих вопросов или проблем:
- Поиск Kubernetes в DNS выполняется медленно
- Как изменить значение DNS по умолчанию ndots в Kubernetes
- Внешний поиск DNS не работает в пакетах
- Рекомендации по DNS для Kubernetes kube (или CoreDNS)
- Kubernetes добавляет неправильный суффикс URL cluster.local в конце запроса
- CoreDns получил тысячи ответов RCode
- На первый взгляд у CoreDns была высокая нагрузка без всякой причины.
- Самое главное, приложения не могли разрешать DNS-запросы и не могли извлекать важные данные.
:::подсказка RCodes
Когда CoreDNS обнаруживает ошибку, он возвращает rcode — стандартный код ошибки DNS.
Такие ошибки, как NXDomain и FormErr, могут указывать на проблему с запросами, которые получает CoreDNS, а ошибка ServFail может указывать на проблему с функцией самого сервера CoreDNS.
:::
Итак, ниже я расскажу вам о 3 темах:
* Решение проблем с DNS * Рекомендации по DNS для Kubernetes (но на самом деле больше о DNS с Linux) * Как предотвратить подобные проблемы до того, как они повлияют на клиентов
Подробно о конкретной проблеме с DNS
Сообщается, что некоторые приложения не могут подключиться к службе. Это может быть внешняя служба или внутренняя служба. Пересмотрели эти сервисы, все заработало нормально. Итак, очень странное поведение и не постоянная проблема. Изучив все ошибки в централизованной системе журналов в это конкретное время, мы обнаружили корреляцию со службой DNS (CoreDNS). В то время мы также обнаружили проблемы с этой службой.
Показатели CoreDns во время этого инцидента могут выглядеть следующим образом: количество запросов.
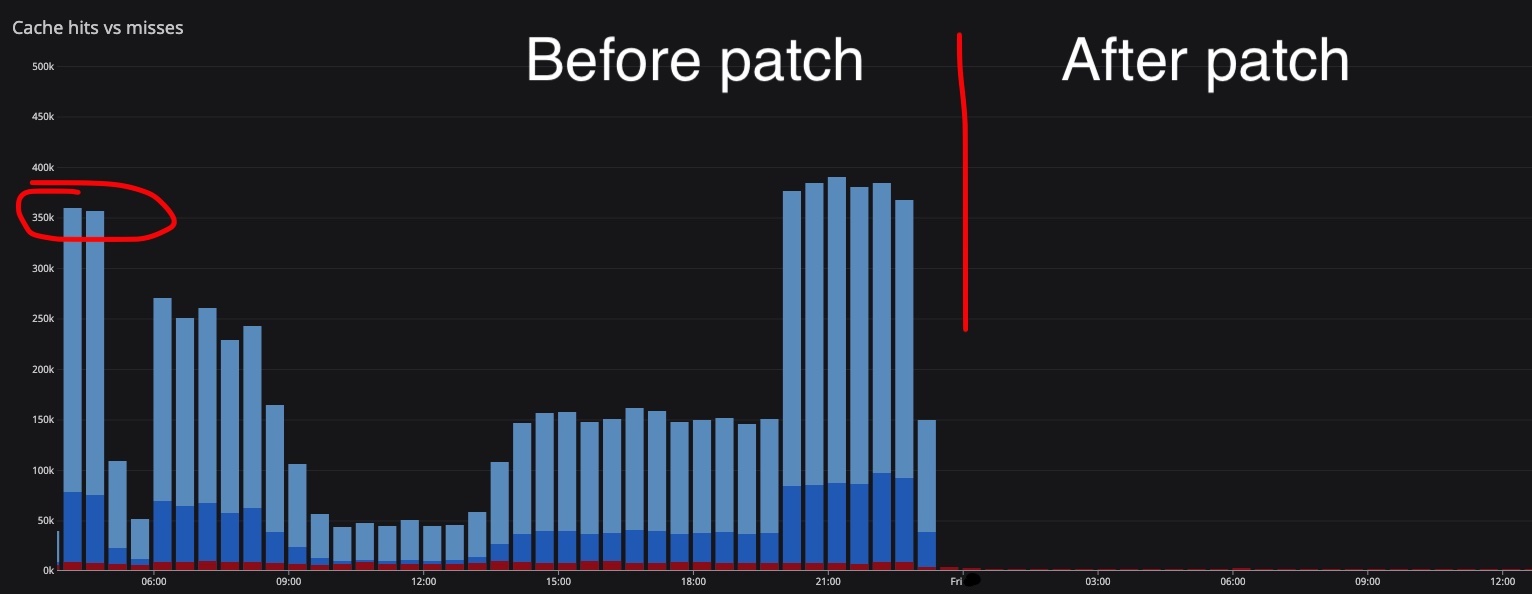
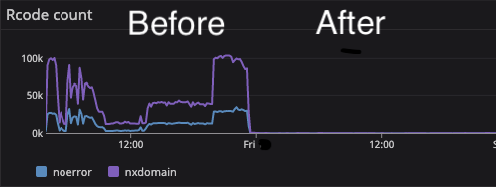
Здесь вы можете увидеть количество ошибок, которые вернули ответ на DNS-запросы
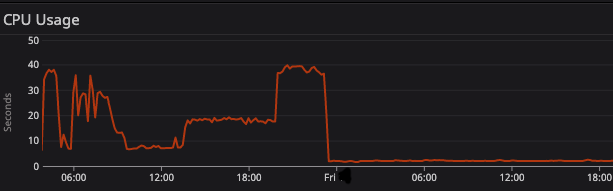
Здесь вы можете увидеть загрузку процессора.
Конфигурация DNS внутри модулей выглядит так, как показано ниже.
/etc/resolv.conf:
nameserver 10.100.0.10
search default.svc.cluster.local svc.cluster.local cluster.local ec2.internal
options ndots:5
:::подсказка NDOTS: нет
Устанавливает пороговое значение количества точек, которое должно появиться в имени, указанном в res_query(), прежде чем будет сделан первоначальный абсолютный запрос. Значение по умолчанию для n равно 1, а это означает, что если в имени есть точки, имя сначала используется как абсолютное имя, прежде чем к нему будут добавлены какие-либо элементы списка поиска.
:::
Журналы ошибок выглядят следующим образом:
[INFO] 192.168.3.71:33238 - 36534 "A IN amazon.com.default.svc.cluster.local. udp 54 false 512" NXDOMAIN qr,aa,rd 147 0.000473434s
[INFO] 192.168.3.71:57098 - 43241 "A IN amazon.com.svc.cluster.local. udp 46 false 512" NXDOMAIN qr,aa,rd 139 0.000066171s
[INFO] 192.168.3.71:51937 - 15588 "A IN amazon.com.cluster.local. udp 42 false 512" NXDOMAIN qr,aa,rd 135 0.000137489s
[INFO] 192.168.3.71:52618 - 14916 "A IN amazon.com.ec2.internal. udp 41 false 512" NXDOMAIN qr,rd,ra 41 0.001248388s
[INFO] 192.168.3.71:51298 - 65181 "A IN amazon.com. udp 28 false 512" NOERROR qr,rd,ra 106 0.001711104s
Как видите, уровень сообщения информационный, поэтому раньше мы этих сообщений не видели. Вы видите, что DNS-имена абсолютно неверны.
:::информация NXDOMAIN означает, что запись домена не найдена, а NOERROR означает, что запись домена найдена.
:::
:::информация CoreDNS интегрируется с Kubernetes с помощью плагина Kubernetes. , или etcd с плагином etcd.
:::
Это логика этих запросов.
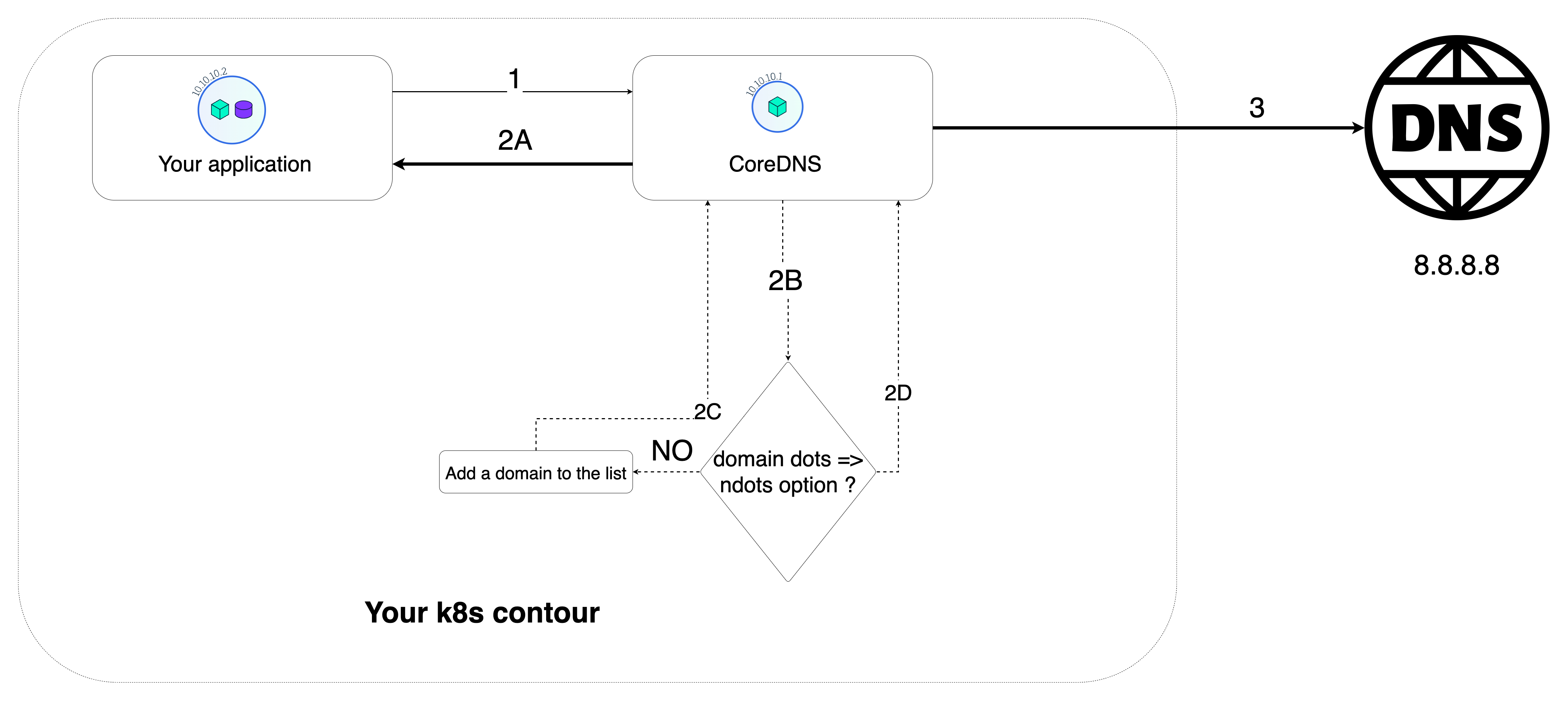
Почему CoreDNS ищет внешние домены в локальных доменах и почему есть 4 новых доменных суффикса, например .default.svc.cluster.local. код> ?
- Приложение выполняет DNS-запрос, например
secretsmanager.ca-central-1.amazonaws.com - CoreDNS проверяет, где следует выполнять поиск в этом домене
k8s основан на Linux, поэтому он ищет этот домен в локальной внутренней системе или внешней системе.
Таким образом, если доменное имя имеет формат FQDN, то CoreDNS должен сделать абсолютный запрос (внешняя система), иначе поиск в локальной системе .
НО у нас есть опция ndots.
-
Если доменное имя не является полным доменным именем, выполните поиск во внутренней системе
my-internal-service, CoreDNS возвращает IP-адрес внутренней службы в том же пространстве имен. 2. Проверьте, имеет ли доменное имя формат FQDN, и проверьте параметрndotsи точку в конце имени домена. 3. Если в имени домена меньше точек, чем в параметреndots, сначала выполните поиск этого домена в локальных доменах, определенных в директивеsearch.В нашем примере
secretsmanager.ca-central-1.amazonaws.comимеет только 3 точки, тогда как параметрndotsимеет значение 5.Итак, первый поиск:
баш secretsmanager.ca-central-1.amazonaws.com.default.svc.cluster.local secretsmanager.ca-central-1.amazonaws.com.svc.cluster.local secretsmanager.ca-central-1.amazonaws.com.cluster.local secretsmanager.ca-central-1.amazonaws.com.ec2.internalИ только после этих запросов сделайте абсолютно запрос:
secretsmanager.ca-central-1.amazonaws.com4. Если имя домена содержит более 4 точек или имеет точку в конце, задайте абсолютное значение. 3. Если у доменного имени есть полное доменное имя, сделайте запрос абсолютно. Если доменное имя имеет абсолютное доменное имя (точка в конце) FQDN, сделайте абсолютный запрос
:::информация FQDN: полное доменное имя
Полное доменное имя состоит из двух частей: имени хоста и имени домена. Например, полное доменное имя гипотетического почтового сервера может быть mymail.somecollege.edu. Имя хоста — mymail, и хост расположен в домене somecollege.edu.
:::
:::подсказка Точка в имени домена означает, что этот домен является абсолютным полным доменным именем.
Например: "amazon.com". означает, сделать только абсолютно запрос.
:::
Хорошо, мы нашли первопричину. Есть 2 вопроса:
- Почему в приложении возникали ошибки подключения?
- Как это исправить?
Почему в приложении возникали ошибки подключения?
Как мы обнаружили, CoreDNS выполнял 4 дополнительных запроса на каждый запрос из приложения. В пики высокой нагрузки CoreDNS ему не хватает ресурсов. Мы увеличили количество подов, на какое-то время забыли об этой проблеме.
После того, как мы снова увидели эту проблему, мы добавили NodeLocal, как указано в официальной документации, но это не помогло. устранить первопричину. Через какое-то время количество запросов вырастет, и мы снова увидим эту проблему. Вот почему мы должны устранить основную причину.
Как это исправить?
Мы должны уменьшить значение параметра ndots в resolv.conf.
Что ж, слава богу, k8s позволяет изменить эту опцию в манифесте модуля (потому что, если вы используете управление Kubernetes, у вас не всегда есть разрешение на изменение таких параметров).
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: web-server
spec:
containers:
- name: test
image: nginx
dnsConfig:
options:
- name: ndots
value: "2"
Итак, /etc/resolv.conf в нашем модуле будет выглядеть так:
nameserver 10.100.0.10
search default.svc.cluster.local svc.cluster.local cluster.local ec2.internal
options ndots:2
После устранения основной причины мы можем улучшить настройки DNS с помощью приведенных ниже рекомендаций.
DNS для k8s, советы и рекомендации PRO
Если вы используете управляемую службу k8s, для масштабирования DNS используйте HPA (или что-то вроде KEDA, Kubernetes Event-driven Autoscaling) вместо того, чтобы вручную изменять настройки, потому что ваш провайдер в любой момент может перезаписать ваши изменения.
Пример HPA:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: coredns
namespace: kube-system
spec:
maxReplicas: 20
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: coredns
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageUtilization: 80
Указанного выше параметра должно быть достаточно, чтобы не использовать NodeLocal.
Но если вам нужно изменить параметры в службе DNS, и вы не можете сделать эти изменения (в случае с управлением k8s), вы можете установить NodeLocal в ваш кластер k8s.
Эта опция позволит добавить еще одну точку кэширования DNS (это снимет нагрузку с основного DNS-сервиса) и настроить параметры по своему усмотрению.
Вы не должны изменять параметр сервера имен в своих модулях, если у вас есть dnsPolicy ClusterFirst.
Если один из модулей CoreDNS в вашей системе k8s вернет ошибку, все будет неработоспособно, просто повторите запрос DNS. Этот параметр мы можем настроить на системном уровне.
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: web-server
spec:
containers:
- name: test
image: nginx
dnsConfig:
options:
- name: ndots
value: "2"
- name: attempts
value: "3"
Если у вас недостаточно времени, чтобы сделать патч для вашей среды, добавьте «точку» в конце вашего DNS-запроса. Тогда ваше доменное имя будет полностью полным доменным именем, например, secretsmanager.ca-central-1.amazonaws.com.
Чтобы распространить эти изменения на все узлы, вы должны изменить настройки kubelet, используя resolvConf option для настроек kubelet
~~В чем твоя проблема?~~ Почему я сначала не знал о проблеме?
Короткий ответ: я не выполнял следующие шаги:
- Недостаточно внимания уделялось настройке уведомлений о критических ошибках.
- Аудит всех критически важных компонентов не проводился, чтобы потом проверить настройки мониторинга
- Не существовало «контрольного списка перед отправкой», такого как этот контрольный список
Подробнее об этой методике.
Как вы знаете, DevOps — это не человек, это набор лучших практик и подходов, предполагающих реализацию непрерывной интеграции и развертывания...
У нас есть журналы, метрики и трассировки, которые часто называют тремя столпами наблюдаемости (как описано в Наблюдаемость распределенных систем).
Все журналы, извлеченные из текущей среды, отправляются в централизованную систему журналов, такую как ELK, New Relic, DataDog. Таким образом, в одном месте вы можете найти и проанализировать практически любую проблему, связанную с вашим приложением или системной службой.
Трассировки приложений отправляются в том же месте, что и журналы, и помогают найти последовательность событий, пошагово отфильтровать все приложения, связанные с конкретным событием/запросом.
Все метрики из текущего окружения отправляются в централизованную систему мониторинга и соотносятся с логами и трассировками.
У нас есть оповещения, уведомления о некоторых проблемах с мониторингом, например: слишком много перезапусков модулей, недостаточно места на диске и т. д.….

Мое лицо, когда я впервые увидел критическую проблему в критической среде, тогда как я думал, что все в порядке.
Фото из фильма "Они живут" (1988).
Как предотвратить подобные проблемы до того, как они повлияют на клиентов?
Но журналов, метрик было недостаточно, почему?
У нас были логи, метрики, трейсы, у нас были ошибки в наших логах, но кто непрерывно смотрит все логи (10к записей в логах каждый день — это нормально)? Мы копаемся в журналах, метриках и т. д., когда сталкиваемся с проблемой. Но это очень дорого, когда проблема находит ваших клиентов. Вот почему мы должны предсказывать проблемы по некоторым симптомам и предотвращать проблемы до того, как они повлияют на что-то критическое.
Другими словами. Потому что недостаточно внимания уделялось настройке уведомлений о критических ошибках. DNS в инфраструктуре kubernetes — одна из критически важных систем.
Итак, как я упоминал выше, мы должны составить контрольный список env для критических компонентов и пройти его шаг за шагом. Некоторые пункты этого контрольного списка должны быть такими: мы должны иметь журналы, метрики и уведомления о критических проблемах и, конечно же, проверять их в реальной инфраструктуре.
В результате должны быть выполнены следующие шаги:
- Исправить проблему
- Выполнить вскрытие (пример: вскрытие базы данных сбой 31 января)
- Составьте контрольный список для критически важных компонентов, особенно для важных миграций, обновлений и развертываний.
- Используйте этот список по крайней мере один раз в существующей инфраструктуре или используйте его перед такими событиями, как миграция, обновление
Список полезных ссылок
- Конфигурация DNS модуля
- resolv.conf(5) — справочная страница Linux
- Как устранять сбои DNS с помощью Amazon EKS?
- Исправление EKS DNS
- Готовая конфигурация EKS CoreDNS
- Racy conntrack и таймауты поиска DNS
Итак, почему я написал эту историю сегодня?
Все совершают ошибки (например: инцидент с базой данных GitLab.com< /a>), тот, кто ничего не делает и не учится на своих ошибках, не достигает успеха!
Удачи! Надеюсь, это поможет.
Пожалуйста, не стесняйтесь оставлять комментарии и связываться со мной https://kazakov.xyz.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27409)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)