

Как Zoom создал облачную систему планирования пакетного потока на Kubernetes
25 июля 2025 г.По мере расширения бизнеса Zoom и его сценарии данных стали более сложными, также развивались потребности в планировании компании - от традиционной партийной обработки до единого управления потоковыми заданиями. Чтобы решить это, Zoom выбралApache Dolphinschedulerв качестве основной структуры планирования и создал унифицированную платформу планирования, которая поддерживает как пакетные, так и потоковые задачи. Эта платформа была глубоко настроена и оптимизирована с использованием современной инфраструктуры, подобной такойKubernetesиРазвертывание с несколькими облакамиПолем В этой статье мы погрузимся в архитектурную эволюцию системы, ключевые проблемы встречались, как они были решены, и планы команды-все это на основе реального производственного опыта.
Фон и проблемы: расширение от партии до потоковой передачи
На ранних стадиях платформа данных Zoom была сосредоточена в основном наSpark SQL -обработка, с задачами, запланированными с использованием стандартных плагинов DolphinschedulerAWS EMRПолем
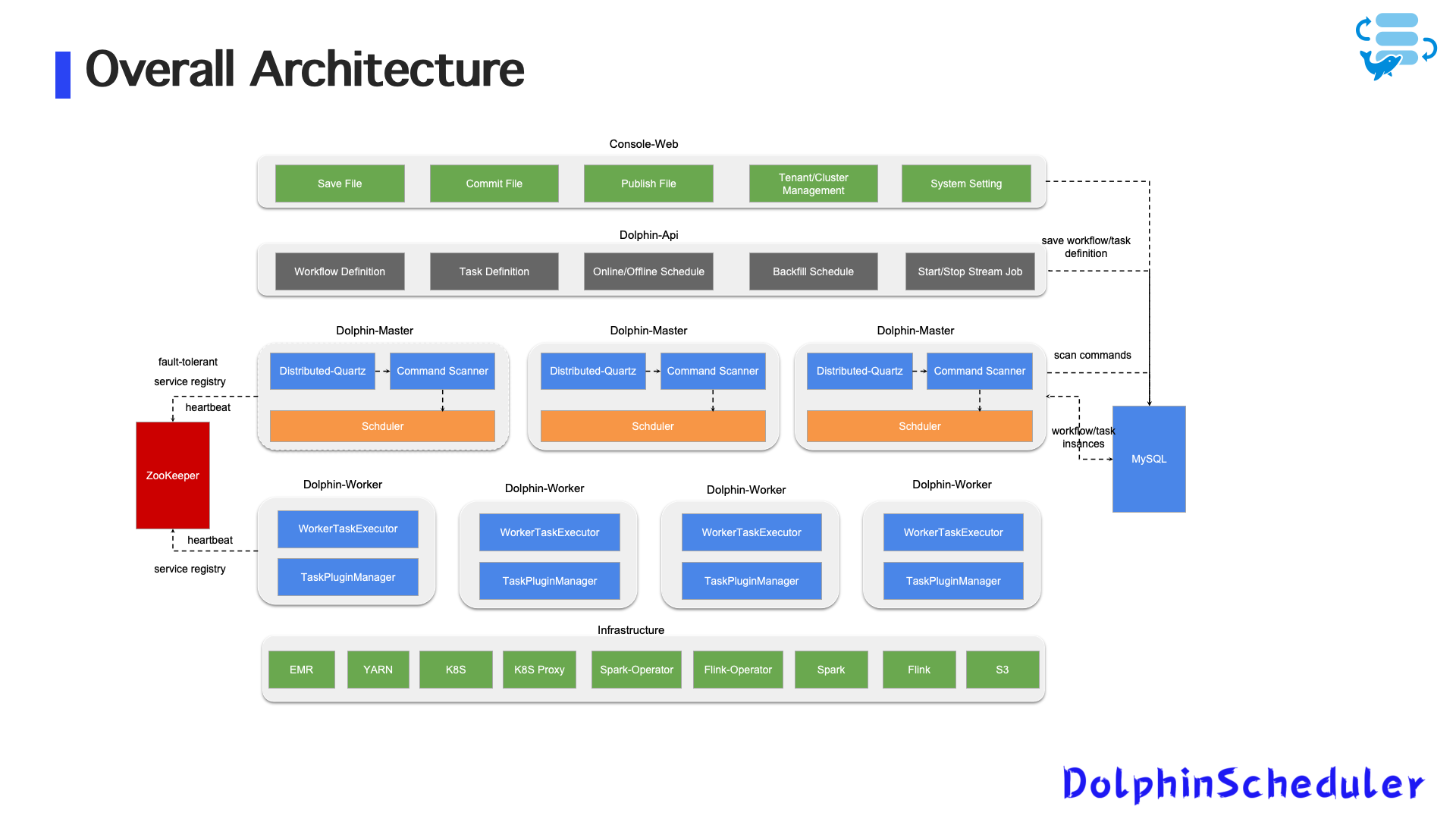
Тем не менее, новые требования бизнеса привели к росту потребностей в обработке в реальном времени, например:
- Вычисление метрик в реальном времени с использованиемFlink SQL
- Структурированная потоковая передачаДля обработки журналов и данных о событиях
- Длительные потоковые задачи, требующие отслеживания состояний и восстановления разломов
Это стало новым вызовом для Dolphinscheduler:Как потоковые задачи могут быть «запланированными» и «управляемыми», как пакетные задачи?
Ограничения первоначальной архитектуры
Первоначальный подход
В ранней интеграции потоковых заданий Zoom использовал Dolphinscheduler'sПлагин задачи оболочкиЧтобы вызвать API API AWS EMR и запуск потоковых задач (например, Spark/Flink).
Эта реализация была простой, но быстро выявила несколько вопросов:
- Нет государственного контроля: После подачи задача сразу же вышла без состояния отслеживания - приведена к дублирующимся представлениям или ложным сбоям.
- Нет экземпляров или журналов.: Устранение неполадок было затруднено из -за отсутствия журналов и наблюдения.
- Фрагментированная логика: Потоковые и партийные задания использовали разные логические пути, что делает униженное обслуживание.

Эти проблемы подчеркнули срочную необходимость вОбъединенная архитектура планирования партийного потокаПолем
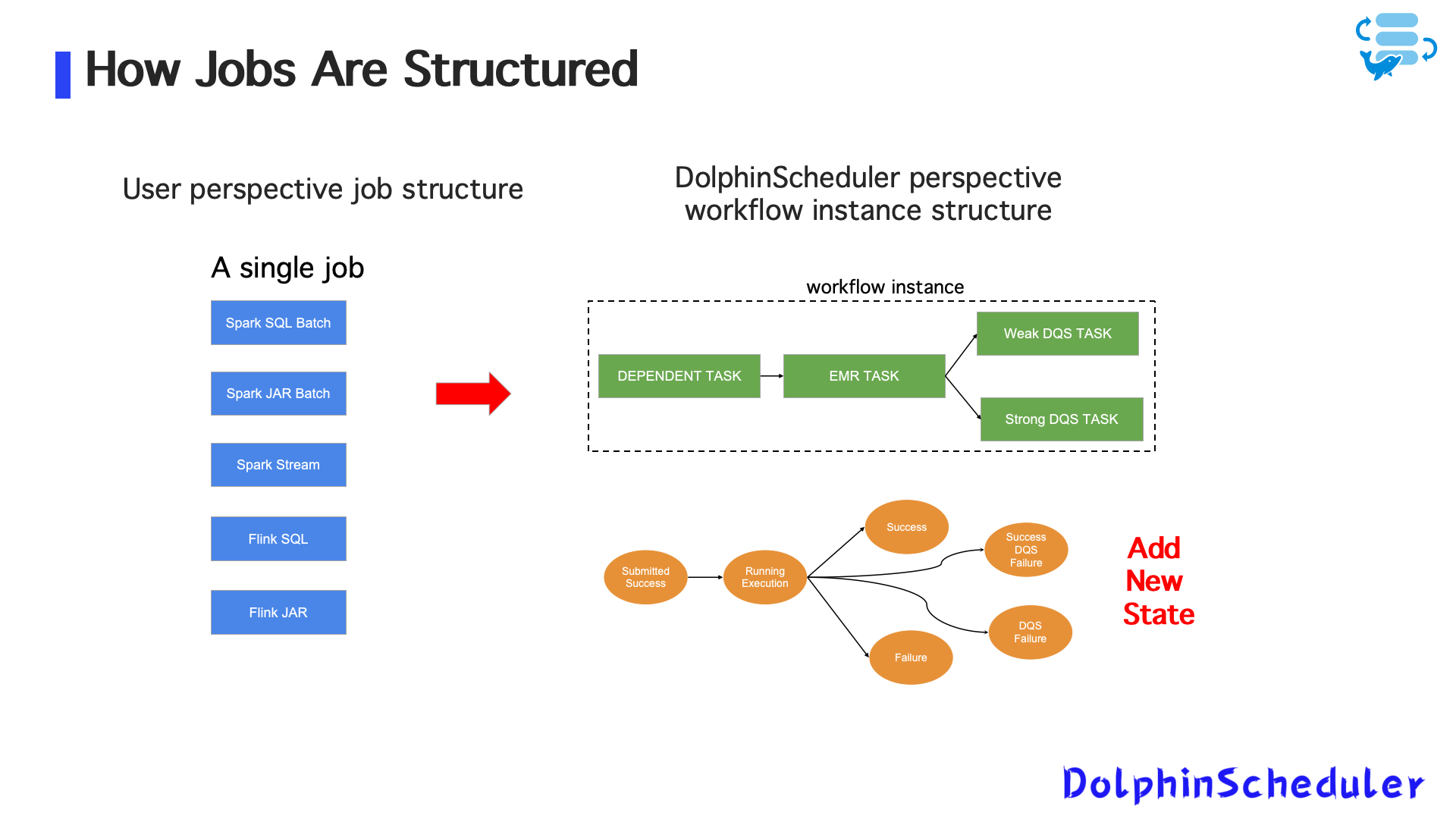
Эволюция системы: введение государственной машины для потоковых заданий
Чтобы обеспечить государственное планирование потоковых заданий, Zoom разработалДвухступенчатая модель задачиДля потоковых рабочих нагрузок на основе возможности состояния задачи Dolphinscheduler:
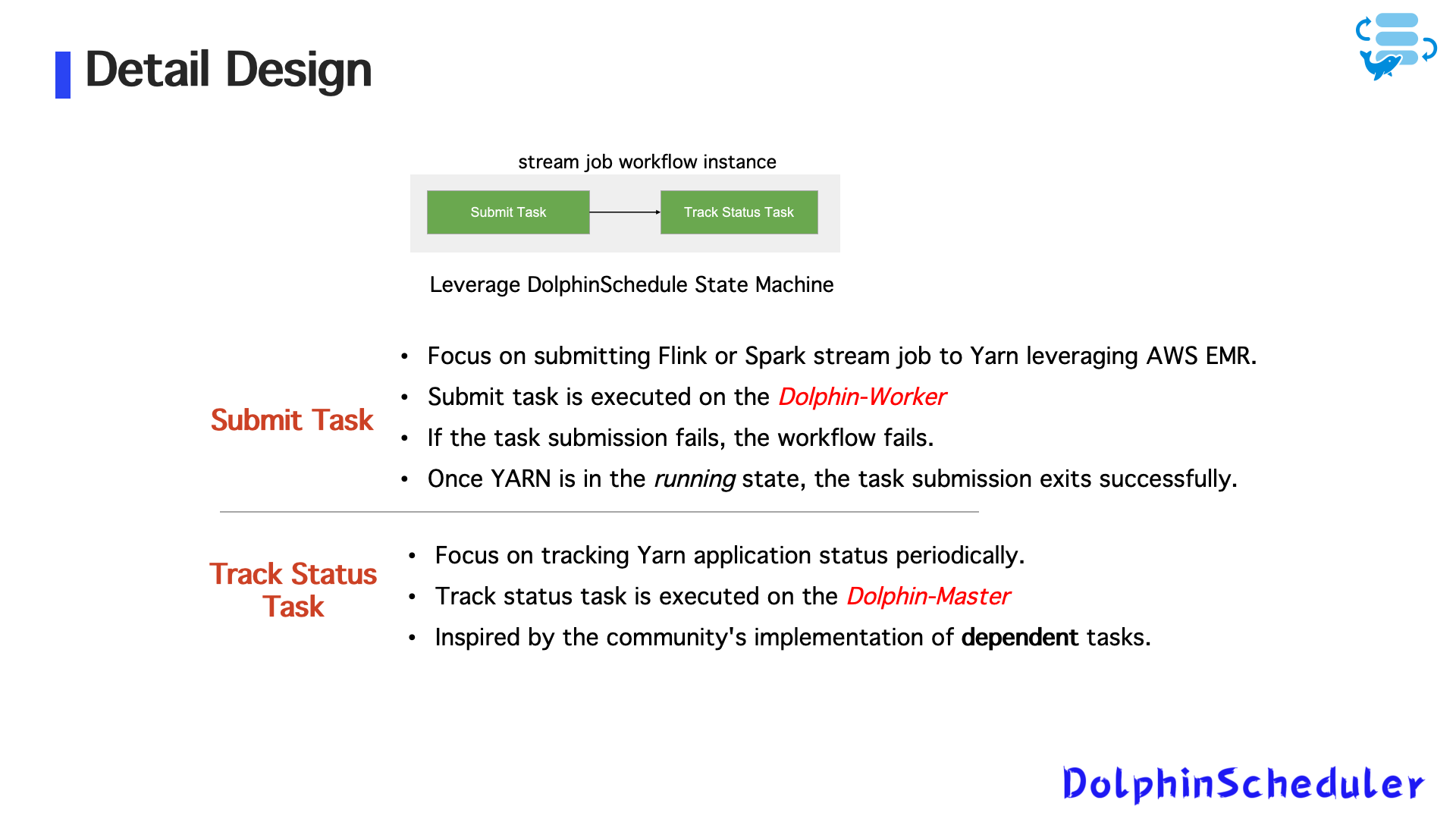
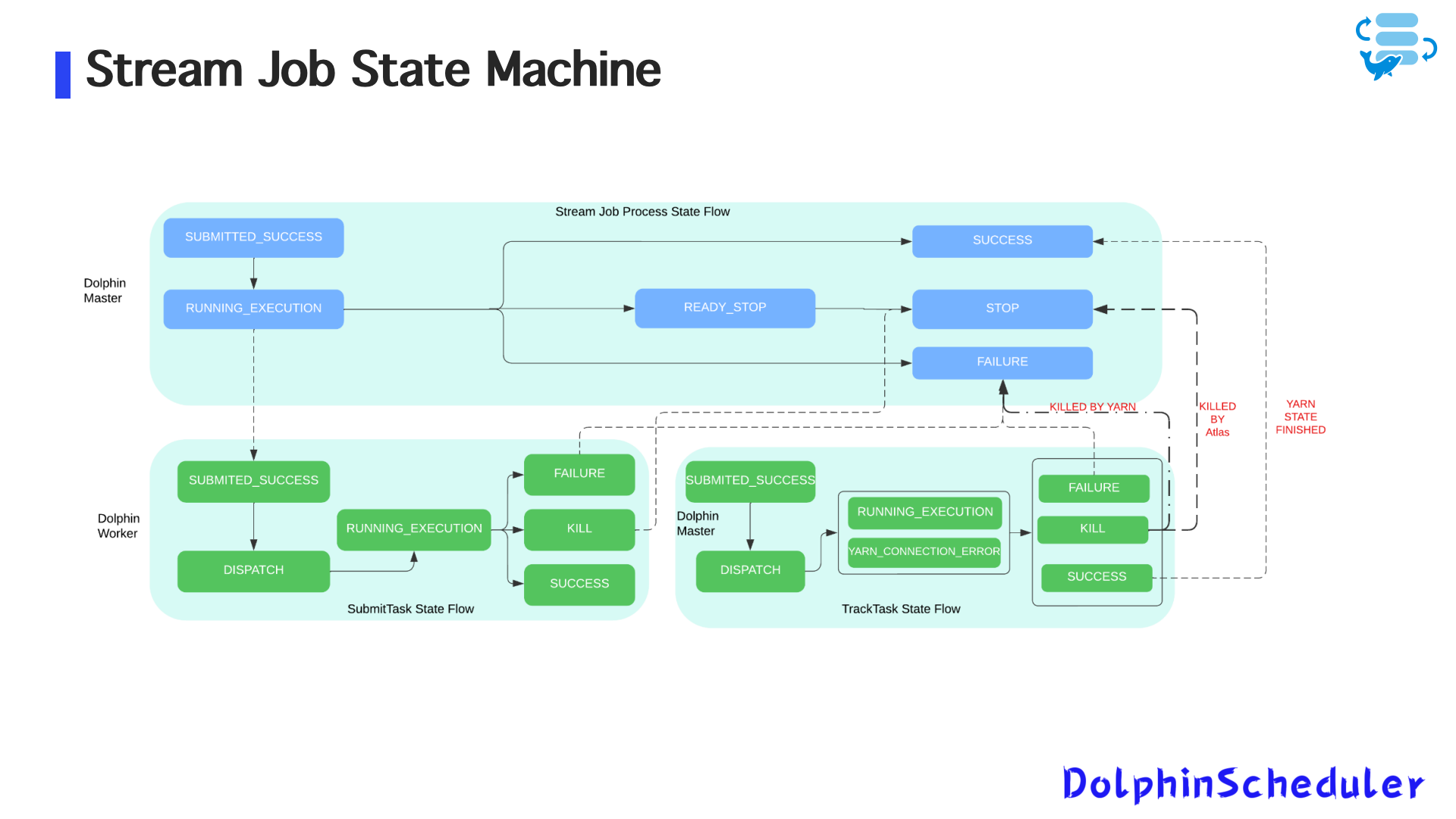
1. Отправить задачу - этап подачи
- Бегает на работнике дельфинов
- Подчиняет потоковые задания Flink/Spark на пряжу или кубики
- Считается успешным после того, как приложение пряжи входит вБегсостояние
- Сразу же сбой, если отправка не удается
2. Отслеживать задачу состояния - этап отслеживания состояния
- Бежит на мастере дельфина
- Периодически проверяет статус работы на пряжу/Kubernetes
- Реализовано какнезависимая задача, аналогично зависимой задаче
- Непрерывно обновляет статус работы в центр метаданных Dolphinscheduler
Эта модель с двумя заданиями эффективно решает несколько ключевых вопросов:
- Предотвращает дублирующие материалы
- Приносит потоковые задания в единое государство и систему ведения журнала
- Обеспечивает архитектурную согласованность с партийными рабочими местами для облегчения технического обслуживания и масштабирования
Высокая доступность: сбои мастера/работника.
В крупномасштабном производстве стабильность системы имеет решающее значение. Zoom реализован надежной сдержанностью дляМастер Dolphinscheduler и рабочие узлыПолем
1. Восстановление сбоев работника
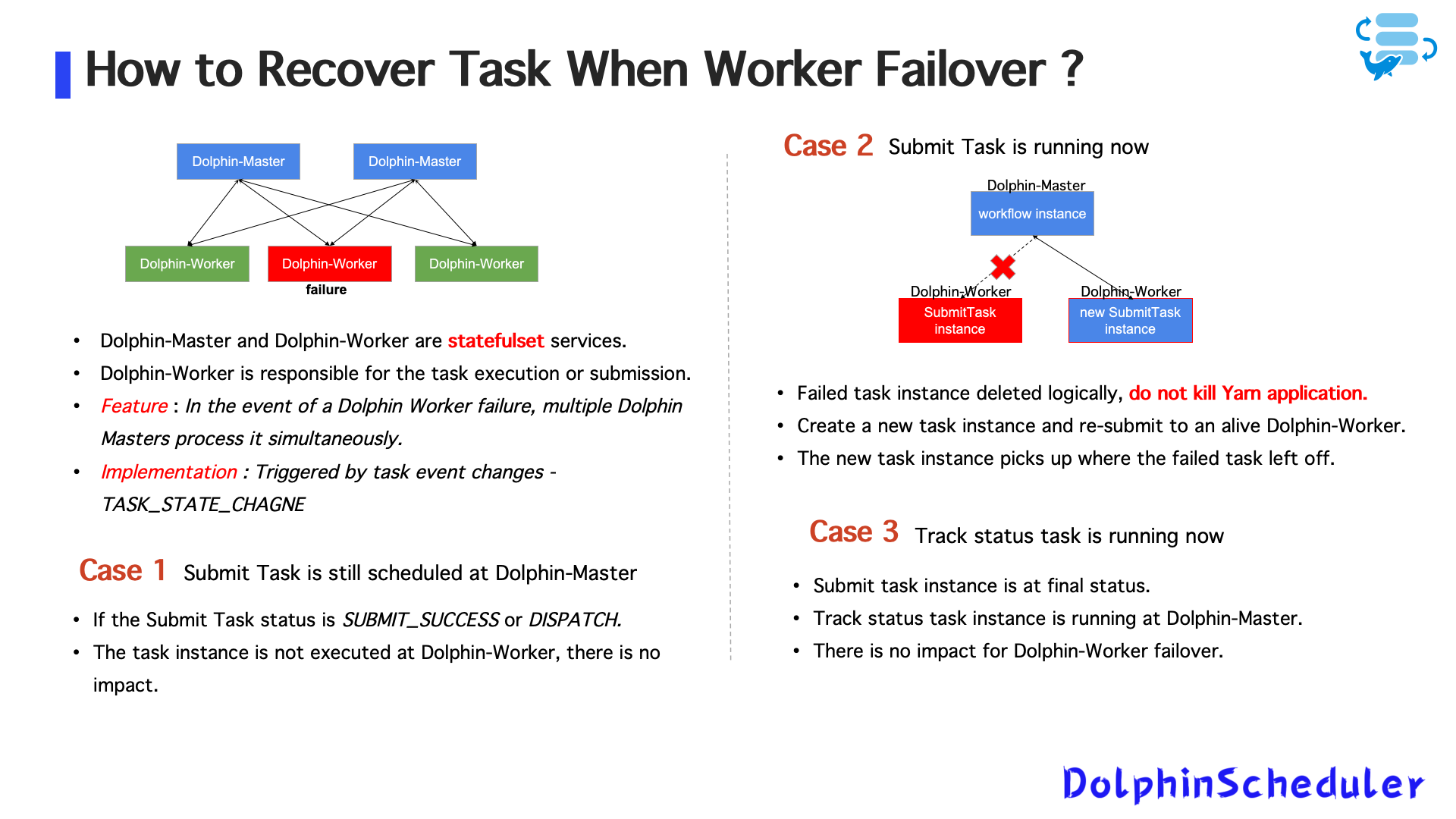
- ЕслиОтправить заданиеработает, и работник сбои:
- Исходный экземпляр задачи логически удален
- Новый экземпляр задачи создается и назначен здоровому работнику
- Ранее поданное заявление о пряжене насильно убит
- ЕслиОтслеживать задачу статусаработает:
- Перепланировать не требуется
- Поскольку задача работает на мастере, сбой работника не влияет на отслеживание статуса
2. Восстановление магистра.
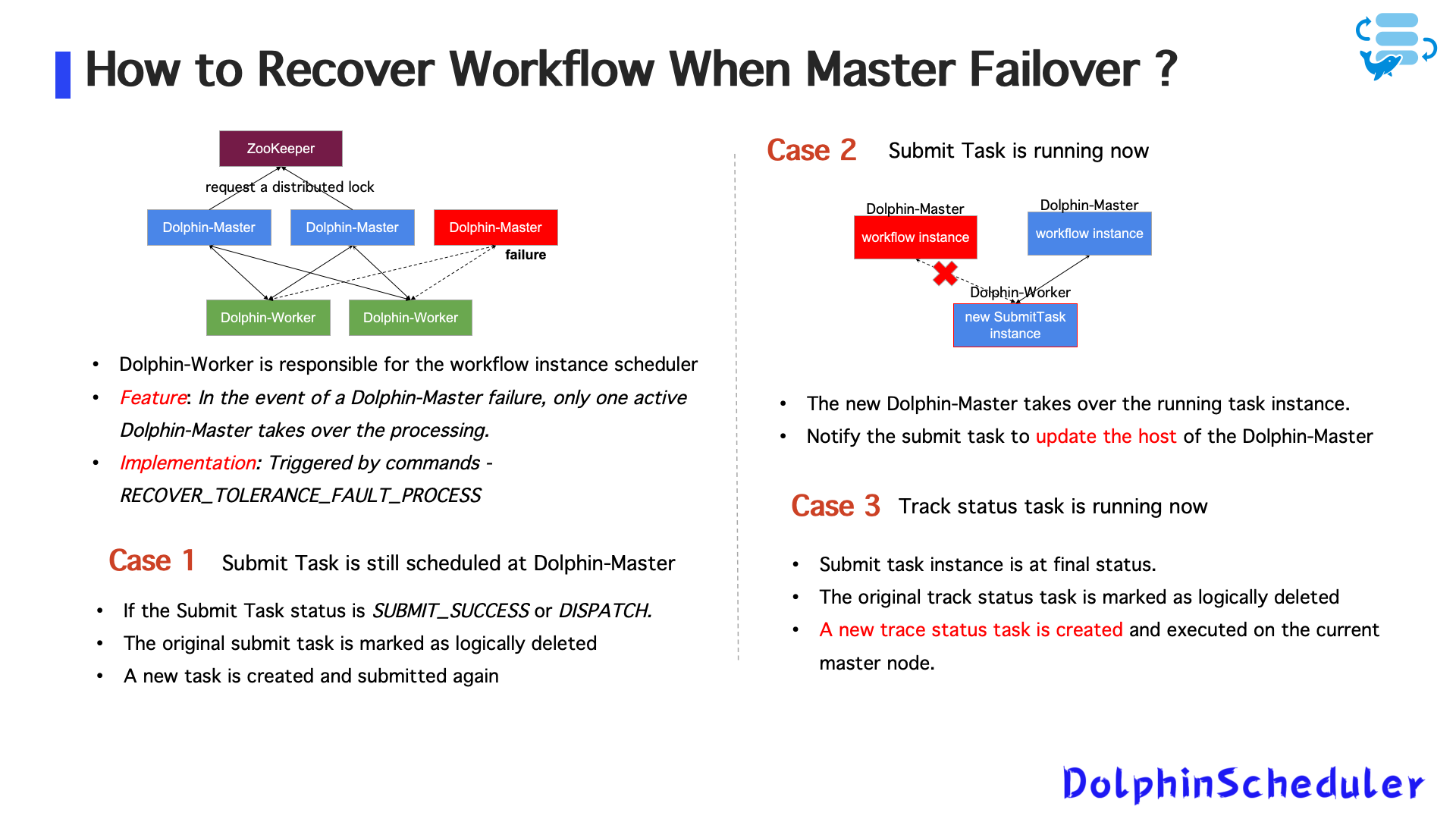
- ИспользованиеZookeeper + mysqlдля терпимости от ошибок
- Несколько главных узлов развернуты с распределенным замком для выборов лидеров
- Когда мастер -узел терпит неудачу:
- Активный узел переключается автоматически
- Все задачи отслеживания статуса перезагружаются и возобновляются
- Idempotent проверяютилогические удаленияявляются ключом к предотвращению дублирования задач
Таким образом, эта архитектура достигает:
- Преимущество 1:
- Использует рабочие процессы Dolphinscheduler и функции состояния задач.
- Предотвращает дублирующиеся работы
- Преимущество 2:
- Легкая отладка и разрешение проблем
- Потоковые задания теперь имеют экземпляры задач и журналы, такие как пакетные задания
- Поддерживает поиск журнала и диагностику неисправностей
- Преимущество 3:
- Объединенная архитектура для потоковой передачи и партии
- Улучшенная обслуживаемость и согласованность между системами
Объединенное планирование Spark и Flink на Kubernetes
Zoom мигрировал как пакетные, так и потоковые задания в Kubernetes, используяОператор SparkиОператор FlinkДля облачной оркестровки задачи.
Обзор архитектуры
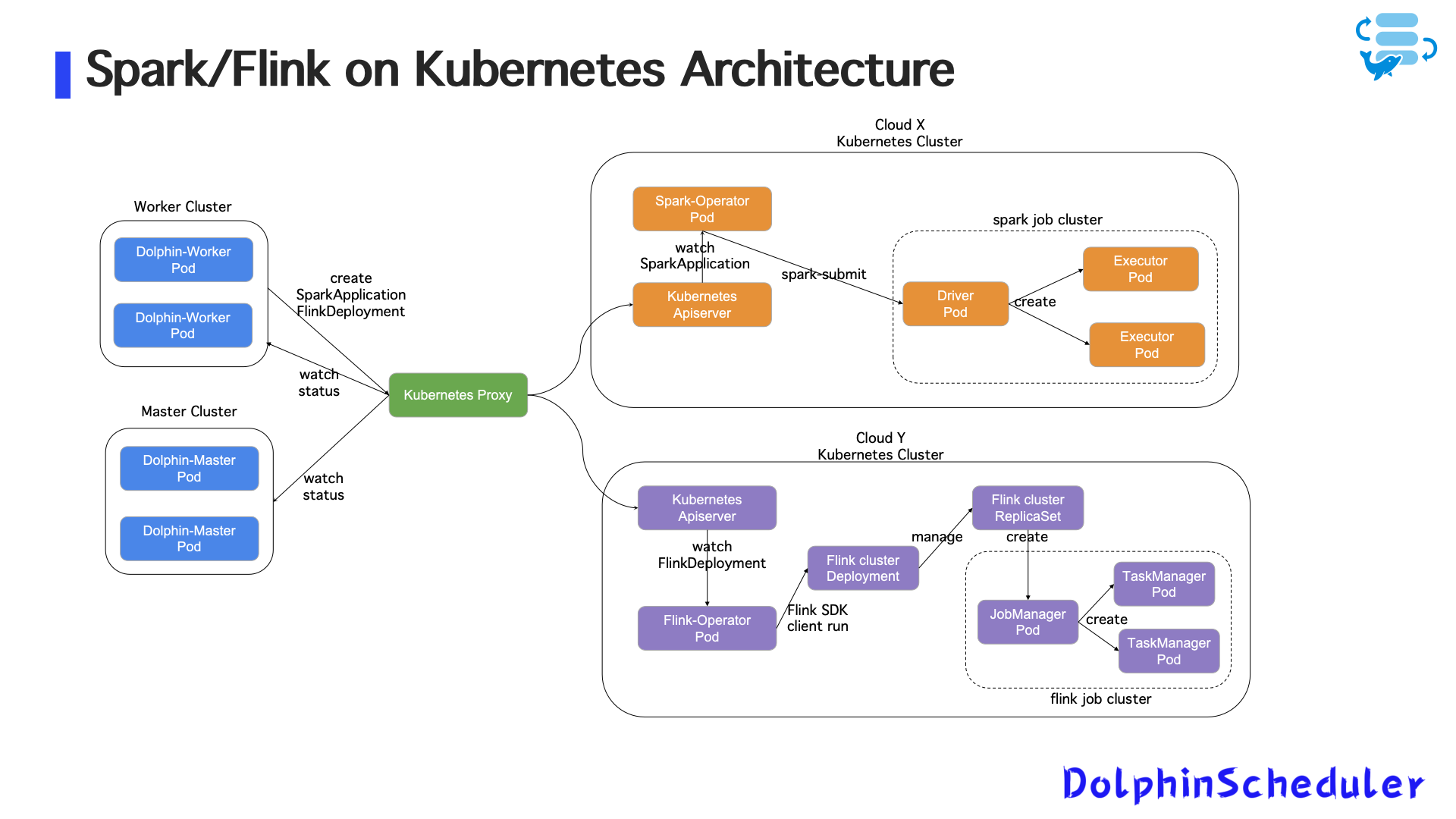
- Задача Spark/Flink представляется как
SparkApplicationилиFlinkDeploymentПользовательские ресурсы (CRD)
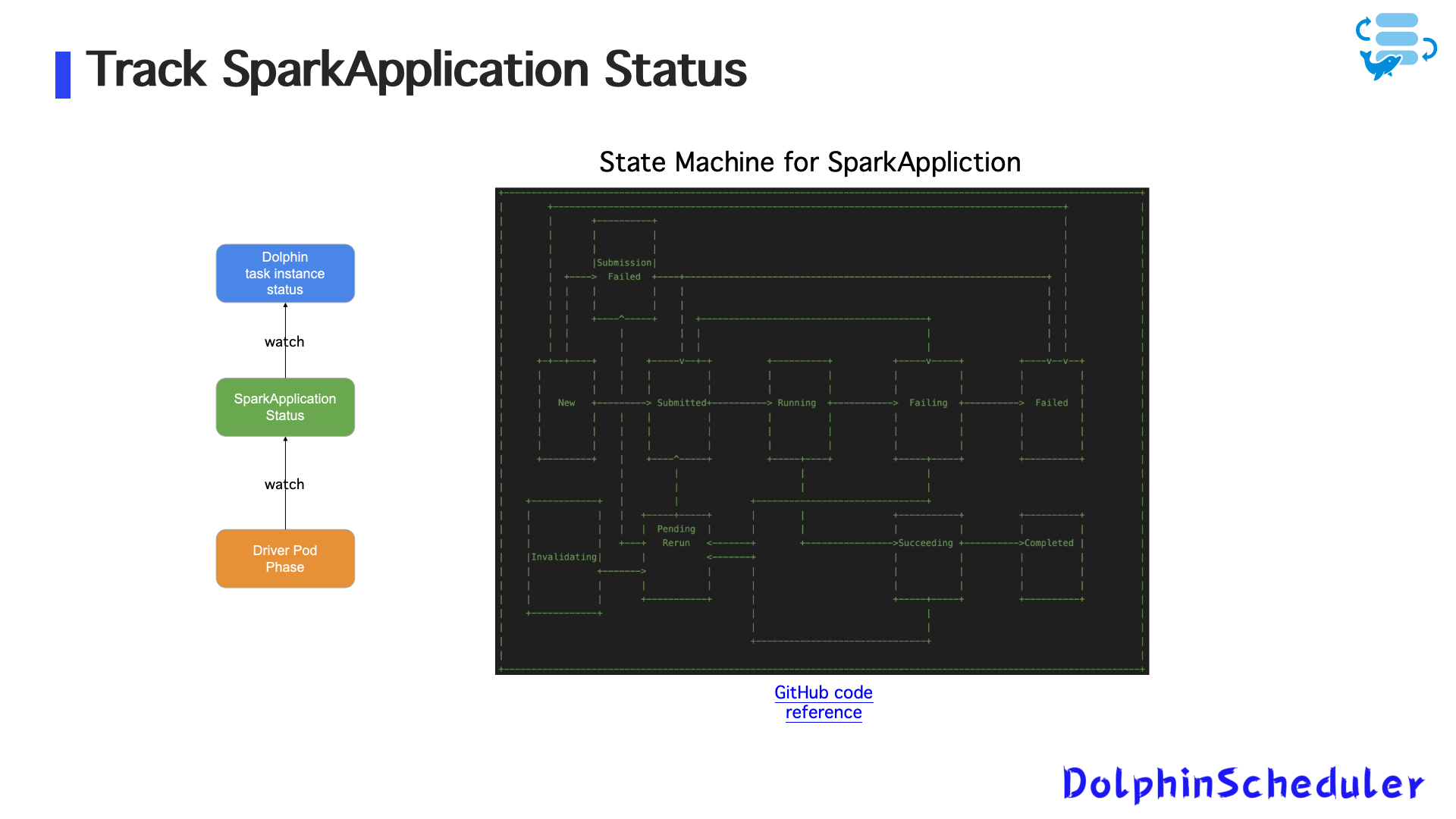
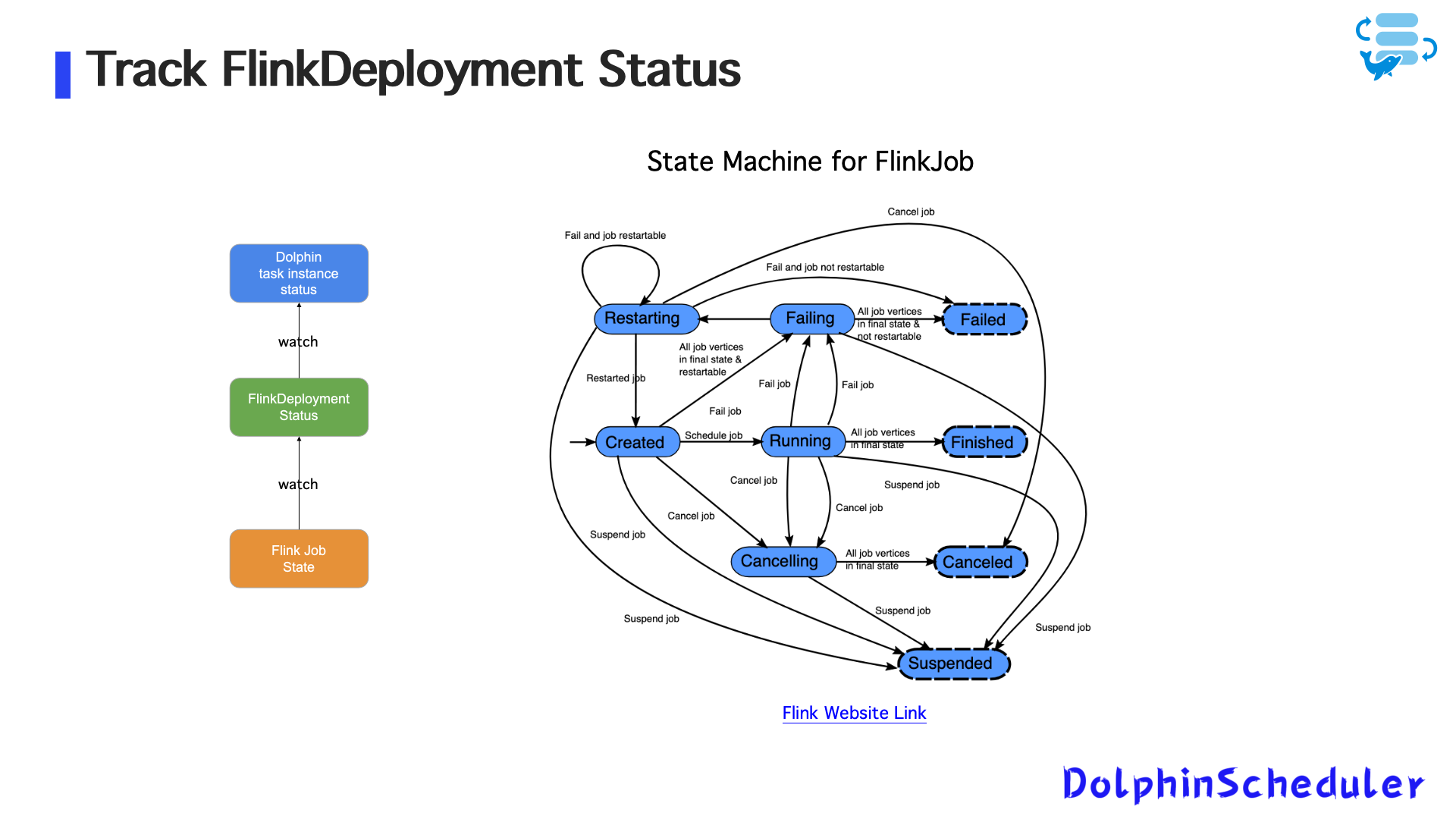
- Dolphinscheduler создает и управляет этими CRS
- Состояние задачи синхронизируется через API -сервер Operator и Kubernetes
- Магистр дельфинов и рабочие непрерывно отслеживают статус стручков с использованием машины состояния и отражают его в системе планирования
Планирование с несколькими облаками кластера
- Поддерживает планирование в нескольких облачных кластерах Kubernetes (например, Cloud X / Cloud Y)
- Логика планирования и управление ресурсами полностью разделены по кластерам
- ВключаетCross-Cloud, единое управлениеЗадачи партии и потока
Онлайн -проблемы и стратегии смягчения последствий
Выпуск 1: Дублирование задач из -за мастер -аварии
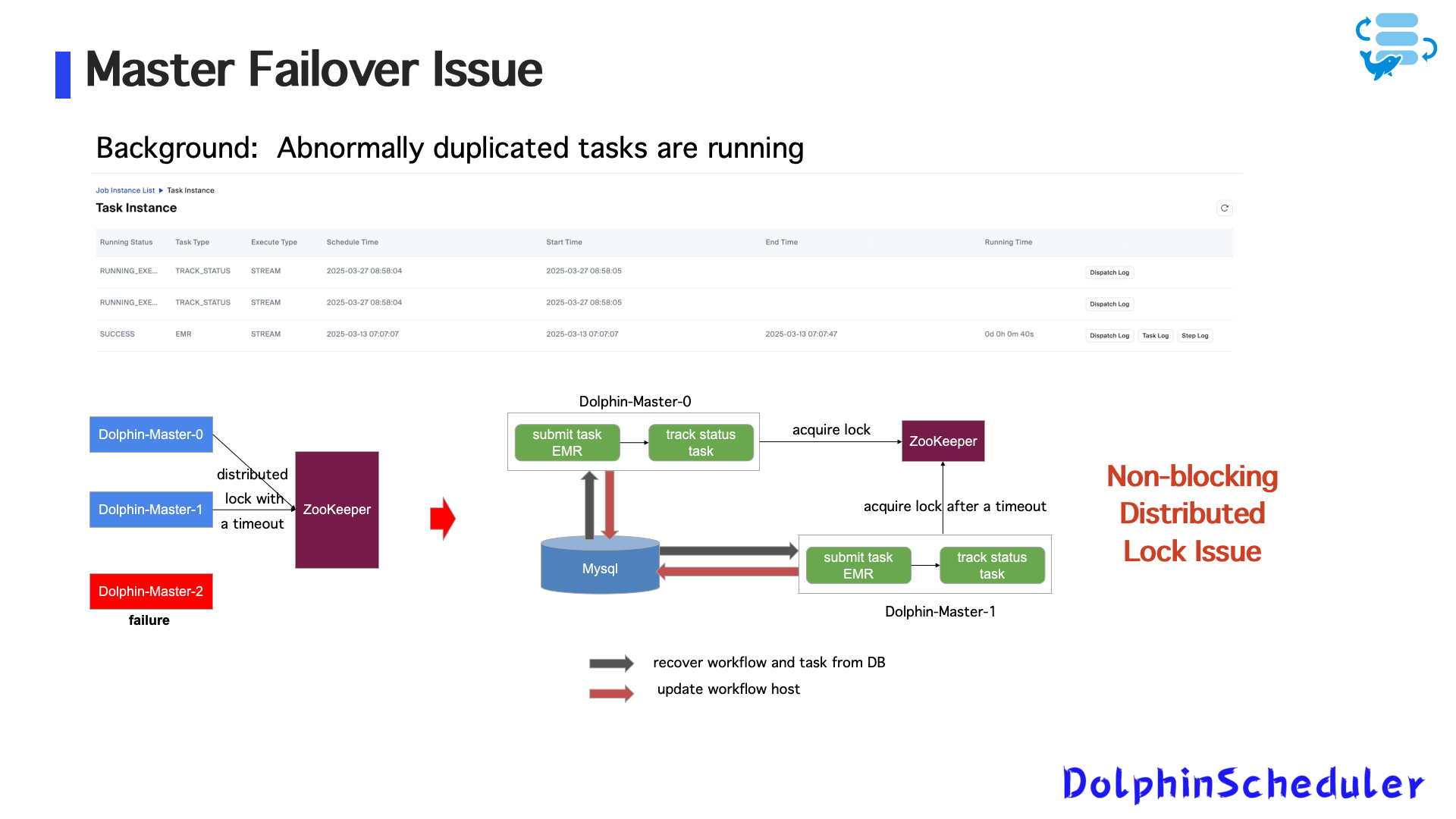
Распределенные замки Dolphinscheduler не блокируются, создавая условия гонки:
- Исправляет:
- Добавить тайм -аут приобретения блокировки
- Применять идентификационное управление для задач отправки (избегайте дублирующихся представлений)
- Проверить статус задачи перед восстановлением из MySQL
Выпуск 2: рабочий процесс застрял вREADY_STOPСостояние
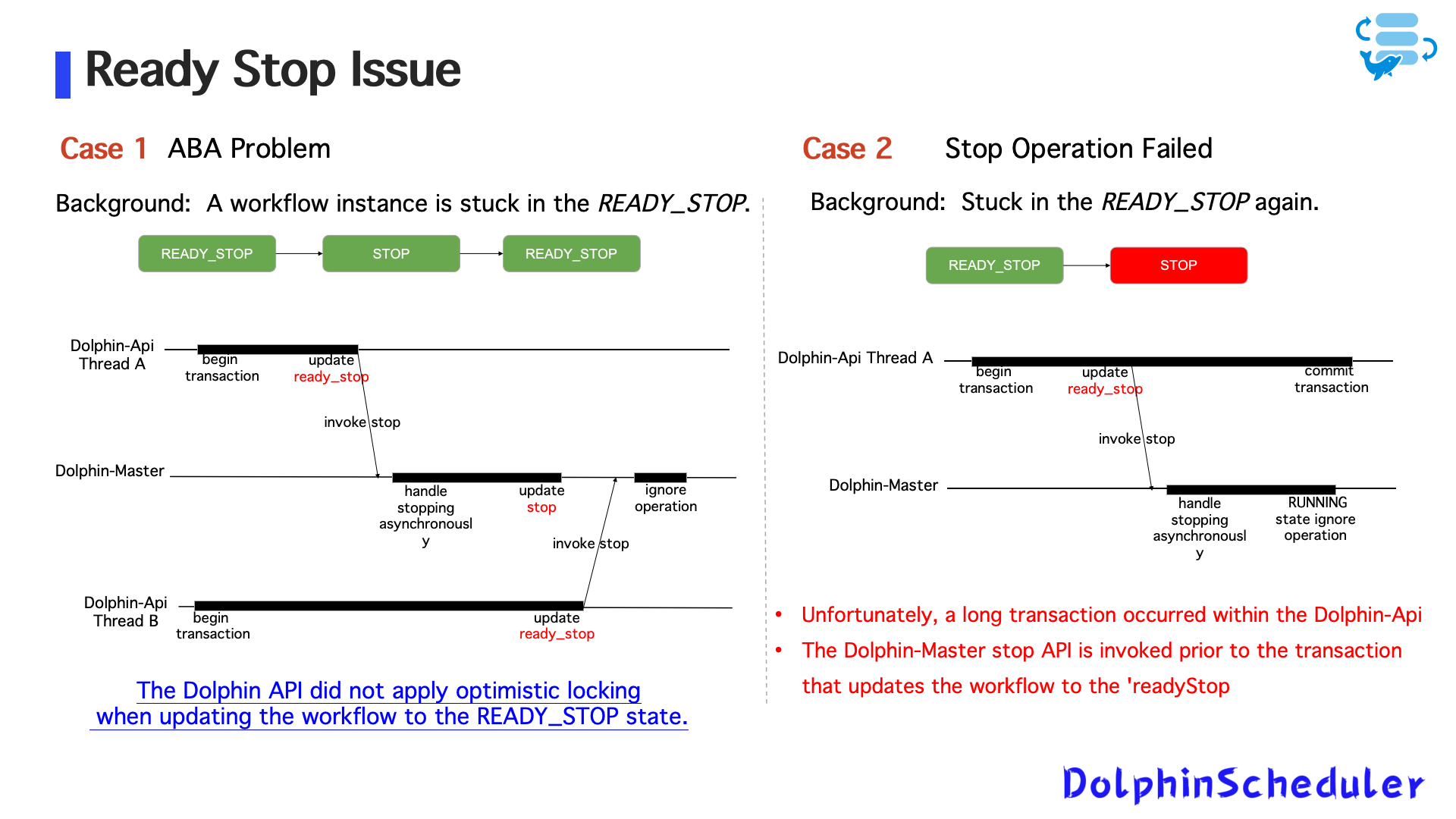
- Причина:
- API Dolphin не имел оптимистичной блокировки при прекращении рабочих процессов
- Условия гонки во время многопоточных государственных обновлений привели к застрявшим рабочим процессам
- Улучшения:
- Добавить оптимистичные замки на слое API
- Рефактор длинная логика транзакции
- Добавить несколько слоев проверки состояния при мастер -обновлениях статуса задачи
Планы на будущее
Zoom планирует еще больше оптимизировать Dolphinscheduler для удовлетворения все более сложных производственных требований. Основные области фокуса включают:
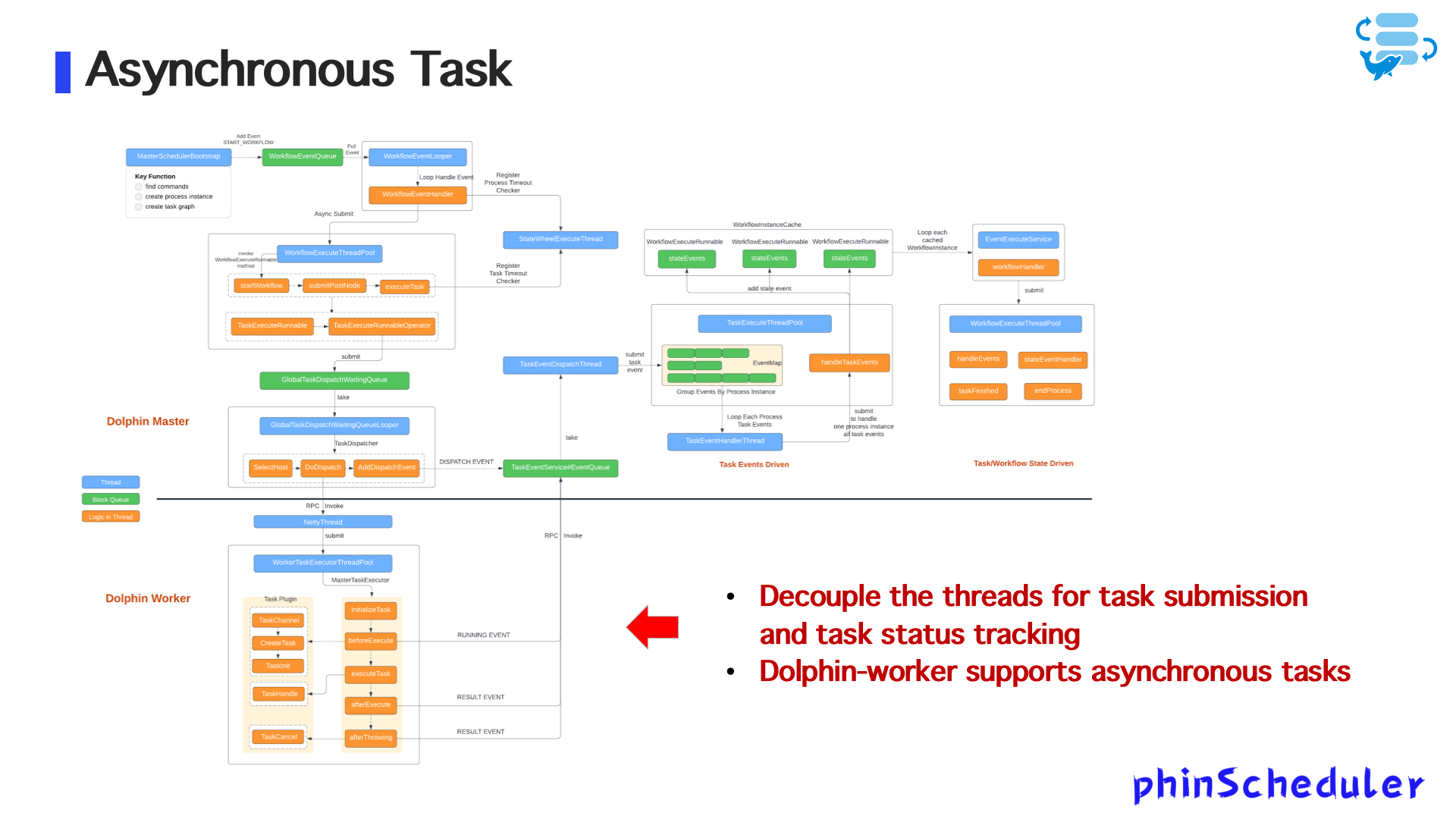
1. Асинхронный механизм задач
- Отправить логику подчинения и отслеживания статуса
- Разрешить рабочие узлы асинхронно выполнять задачи, избегая длинных блоков ресурсов
- Закладывает основу для упругого планирования и передовой обработки зависимостей
2. модернизированная платформа расписания Unified Batch Stream
- Шаблоны рабочего процесса будут поддерживать смешанные типы задач
- Полностью унифицированные журналы, состояния и мониторинг
- Улучшенные облачные возможности для созданияРаспределенный вычислительный центр для крупномасштабного планирования производства
Последние мысли
Глубокая практика Zoom с Dolphinscheduler доказывает масштабируемость, стабильность и архитектурную гибкость платформы в качестве планировщика предприятия. Особенно вОбъединенное планирование партийного потокаВОблачное развертывание на Kubernetes, иМногокластерная терпимость разлома, Архитектура Zoom предлагает ценные уроки для сообщества и других предприятий.
📢 Мы с тепло приветствуем больше разработчиков, чтобы присоединиться кApache Dolphinscheduler Community-Проверьте ваши идеи и опыт и помогите нам создать вместе планировщика с открытым исходным кодом следующего поколения!
GitHub: https://github.com/apache/dolphinscheduler
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)