

Как использовать Ollama: практический опыт работы с местными LLM и создание чат-бота
15 марта 2024 г.Это первая часть более глубокого погружения в Олламу и то, что я узнал о локальных LLM и о том, как их можно использовать для приложений, основанных на логических выводах. В этом посте вы узнаете о —
- Как использовать Олламу
- Как создать собственную модель в Ollama
- Использование Ollama для создания чат-бота. <блок-цитата>
Чтобы понять основы LLM (включая локальные LLM), вы можете обратиться к моему предыдущему сообщению по этой теме здесь.
Во-первых, немного предыстории
В сфере местных программ LLM я впервые столкнулся с LMStudio. Хотя приложение само по себе простое в использовании, мне понравилась простота и маневренность, которые обеспечивает Ollama. Чтобы узнать больше об Олламе, вы можете перейти здесь.
tl;dr: В Ollama есть собственный список моделей, к которым у вас есть доступ.
Вы можете загрузить эти модели на свой локальный компьютер, а затем взаимодействовать с ними через командную строку. Альтернативно, когда вы запускаете модель, Оллама также запускает сервер вывода, размещенный на порту 11434 (по умолчанию), с которым вы можете взаимодействовать через API и другие библиотеки, такие как Langchain.
На момент публикации в Ollama имеется 74 модели, включая такие категории, как встраивание моделей.
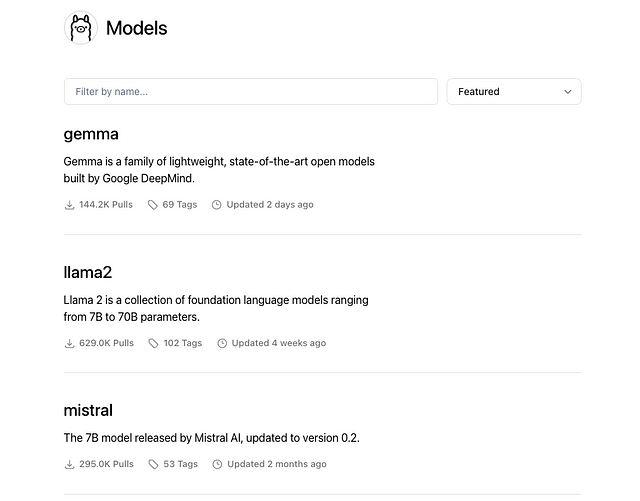
Как использовать олламу
Загрузите Ollama для выбранной вами ОС. Как только вы это сделаете, вы запустите команду ollama, чтобы убедиться, что она работает. Должно появиться меню справки —
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
Чтобы использовать любую модель, вам сначала нужно «вытащить» ее из Ollama, так же, как вы извлекаете образ из Dockerhub (если вы использовали его раньше) или чего-то вроде Elastic Container Registry (ECR).
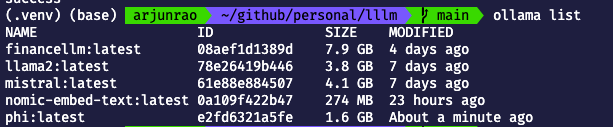
Ollama поставляется с некоторыми моделями по умолчанию (например, llama2, LLM Facebook с открытым исходным кодом), которые вы можете увидеть, запустив.
ollama list
Выберите модель (скажем, phi), с которой вы хотите взаимодействовать, на странице библиотеки Ollama . Теперь вы можете снять эту модель, выполнив команду
ollama pull phi

После завершения загрузки вы можете проверить, доступна ли модель локально, запустив —
ollama list
Теперь, когда модель доступна, она готова к использованию. Запустить модель можно с помощью команды —
ollama run phi
Точность ответов не всегда на высшем уровне, но вы можете решить эту проблему, выбрав разные модели или, возможно, проведя тонкую настройку или самостоятельно внедрив решение, подобное RAG, для повышения точности.
Выше я продемонстрировал, как можно использовать модели Олламы с помощью командной строки. Однако, если вы проверите сервер вывода, на котором работает Llama, вы увидите, что существуют программные способы доступа к нему, нажав порт 11434.
Если вы хотите использовать Langchain для доступа к вашей модели Олламы, вы можете использовать что-то вроде —
from langchain_community.llms import Ollama
from langchain.chains import RetrievalQA
prompt = "What is the difference between an adverb and an adjective?"
llm = Ollama(model="mistral")
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
)
response = qa(prompt)
Как создать свою собственную модель в Ollama
Вы также можете создать свой собственный вариант модели, используя концепцию Modelfile в Ollama. Дополнительные параметры для настройки в файле модели можно найти в этой документации.
Пример файла модели —
# Downloaded from Hugging Face https://huggingface.co/TheBloke/finance-LLM-GGUF/tree/main
FROM "./finance-llm-13b.Q4_K_M.gguf"
PARAMETER temperature 0.001
PARAMETER top_k 20
TEMPLATE """
{{.Prompt}}
"""
# set the system message
SYSTEM """
You are Warren Buffet. Answer as Buffet only, and do so in short sentences.
"""
Получив файл модели, вы можете создать свою модель, используя
ollama create arjunrao87/financellm -f Modelfile
где financellm — это имя вашей модели LLM, а arjunrao87 будет заменено вашим именем пользователя ollama.com (которое также действует как пространство имен вашего онлайн-реестра ollama) . На этом этапе вы можете использовать созданную модель, как и любую другую модель на Ollama.
Вы также можете отправить свою модель в удаленный реестр ollama. Чтобы это произошло, вам нужно
* Создайте свою учетную запись на сайте ollama.com. * Добавить новую модель * Настройте открытые ключи, чтобы вы могли отправлять модели с удаленного компьютера.
После того как вы создали локальный файл llm, вы можете отправить его в реестр ollama, используя —
ollama push arjunrao87/financellm
🦄 Теперь перейдем к хорошему.
Использование Ollama для создания чат-бота
Во время моих попыток использовать Ollama одним из наиболее приятных открытий стала экосистема разработчиков веб-приложений на основе Python, с которой я столкнулся. Chainlit можно использовать для создания полноценного чат-бота, такого как ChatGPT. Как написано на их странице,
<блок-цитата>Chainlit — это пакет Python с открытым исходным кодом для создания готового к использованию диалогового искусственного интеллекта
Я просмотрел несколько руководств по Chainlit, чтобы понять, что можно делать с Chainlit, что включает в себя такие вещи, как создание последовательностей задач (называемых «шагами»), включение кнопок и действий, отправка изображений и многое другое. Вы можете следить за этой частью моего путешествия здесь.
Как только я освоил Chainlit, я захотел собрать простого чат-бота, который в основном использовал Ollama, чтобы я мог использовать местный LLM для общения (вместо, скажем, ChatGPT или Claude).
Имея менее 50 строк кода, вы можете сделать это с помощью Chainlit + Ollama. Разве это не безумие?
Chainlit как библиотеку очень проста в использовании. Я также использовал Langchain для использования и взаимодействия с Ollama.
from langchain_community.llms import Ollama
from langchain.prompts import ChatPromptTemplate
import chainlit as cl
Следующий шаг — определить, как должен выглядеть экран загрузки чат-бота, с помощью декоратора @cl.on_chat_start Chainlit —
@cl.on_chat_start
async def on_chat_start():
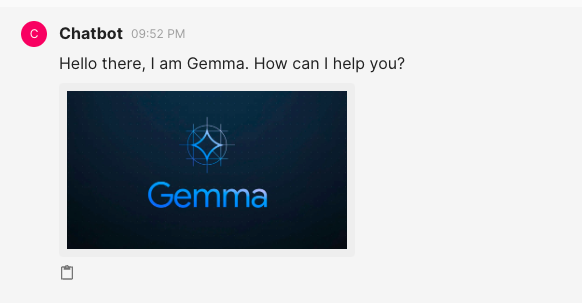
elements = [cl.Image(name="image1", display="inline", path="assets/gemma.jpeg")]
await cl.Message(
content="Hello there, I am Gemma. How can I help you?", elements=elements
).send()
....
....
Интерфейс Message — это то, что Chainlit использует для отправки ответов обратно в пользовательский интерфейс. Вы можете создавать сообщения с помощью простого ключа content, а затем украсить его такими вещами, как elements, в моем случае я добавил Image, чтобы показать изображение при первом входе пользователя в систему.
Следующим шагом является вызов Langchain для создания экземпляра Ollama (с моделью по вашему выбору) и создание шаблона приглашения. Использование cl.user_session в основном предназначено для поддержания разделения пользовательских контекстов и историй, что не является строго необходимым только для запуска быстрой демонстрации.
Chain — это интерфейс Langchain под названием Runnable, который используется для создания пользовательских цепочек. Подробнее об этом можно прочитать здесь.
@cl.on_chat_start
async def on_chat_start():
....
....
model = Ollama(model="mistral")
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a knowledgeable historian who answers super concisely",
),
("human", "{question}"),
]
)
chain = prompt | model
cl.user_session.set("chain", chain)
Теперь у вас есть все необходимое для создания пользовательского интерфейса чат-бота и приема вводимых пользователем данных. Что вы делаете с подсказками, которые предоставляет пользователь? Вы будете использовать обработчик @cl.on_message из Chainlit, чтобы что-то сделать с сообщением, предоставленным пользователем.
@cl.on_message
async def on_message(message: cl.Message):
chain = cl.user_session.get("chain")
msg = cl.Message(content="")
async for chunk in chain.astream(
{"question": message.content},
):
await msg.stream_token(chunk)
await msg.send()
chain.astream, поскольку в документации предлагается «асинхронно передавать фрагменты ответа», это то, что мы хотим для нашего бота.
Это действительно так. Немного импорта, пара функций, немного сахара — и у вас есть функциональный чат-бот.
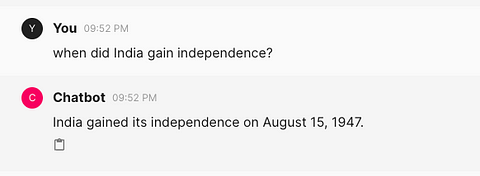

Полный код можно найти на моем GitHub.
Если этот контент вам интересен, нажмите кнопку 👏 или подпишитесь на мою рассылку здесь → https://a1engineering.beehiv.com/subscribe. Это дает мне обратную связь о том, что мне нужно сделать что-то больше или меньше! Спасибо ❤️
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27222)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)