

Как использовать .NET C# для парсинга веб-страниц
7 февраля 2023 г.Руководство по анализу веб-страниц в .NET C# с примерами кода.
Что такое парсинг веб-страниц
В английском языке слово Scraping имеет разные значения, но все они имеют одно и то же значение.
<цитата>удалить (внешний слой, налипшие вещества и т.п.) таким способом: соскоблить краску и лак со стола.
<цитата>снятие поверхности с чего-либо острым краем или чем-то грубым.
Однако нас наверняка интересует, что означает веб-скрейпинг в программном обеспечении.
В программном обеспечении веб-скрейпинг – это процесс извлечения некоторой информации из веб-ресурса из его пользовательского интерфейса, а не из его законных API. Таким образом, это не похоже на вызов REST API веб-сайта для получения некоторых данных, это похоже на извлечение страницы веб-сайта, как это делает браузер, анализирует HTML и затем извлекает данные, отображаемые в HTML.
Зачем нам удалять веб-сайт
Просто потому, что нам нужно, чтобы данные были представлены на этом веб-сайте, а веб-сайт не предоставляет нам официальный API для получения этих данных.
Законен ли веб-скрейпинг
Это зависит от самого веб-ресурса. На некоторых веб-сайтах это где-то написано, является ли это законным или нет, а иногда это нигде не написано.
Кроме того, есть еще один фактор, который заключается в том, что вы собираетесь делать с данными, которые вы собрали. Поэтому всегда старайтесь быть осторожными и берегите себя. Прежде чем приступать к реализации, сначала изучите вопрос.
Как делать парсинг в Интернете
Есть разные способы сделать это, но в большинстве случаев применяется одна и та же концепция; вы пишете код для получения HTML-кода с использованием URL-адреса веб-сайта, анализируете HTML-код и, наконец, извлекаете нужные данные.
Однако, если мы будем придерживаться только этого определения, мы упустим много деталей.
В некоторых случаях все обстоит сложнее. Это зависит от того, как построен веб-сайт.
Для статических веб-сайтов, где данные уже преобразованы в HTML из первого экземпляра, вы можете выполнить те же шаги, которые мы описали.
Однако для динамических веб-сайтов, где данные не отображаются в HTML с первого экземпляра, а загружаются динамически с помощью библиотек и фреймворков JavaScript (например, Angular, React, Vue и т. д.), вам необходимо использовать другой подход.
По сути, в этом случае вы пытаетесь имитировать действия веб-браузера (например, Chrome, Firefox, IE, Edge и т. д.), а затем получаете окончательный HTML-код из виртуального браузера, который вы использовали. Когда у вас будет полный HTML-код, в котором отображаются данные, все остальное будет таким же.
Должны ли мы сделать это сами с нуля
Нет, у нас уже есть некоторые библиотеки, которые мы можем использовать для достижения ожидаемых результатов.
Например, вот список некоторых библиотек, которые мы можем использовать.
Выполнение звонков:
Разбор HTML:
Виртуальный браузер:
Это не единственные библиотеки, которым мы должны помочь в нашем проекте Web Scraping. Если поискать в Интернете, можно найти намного больше.

Очистка статического веб-сайта
Для начала попытаемся удалить некоторые данные со статического веб-сайта. В этом примере мы собираемся удалить мой собственный профиль GitHub https://github.com/AhmedTarekHasan< /p>
Мы попытаемся получить список закрепленных репозиториев в моем профиле. Каждая запись будет состоять из имени репозитория и его описания.
Итак, приступим.
Наблюдение за структурой данных в HTML
До момента написания этой статьи мой профиль на GitHub выглядел так.
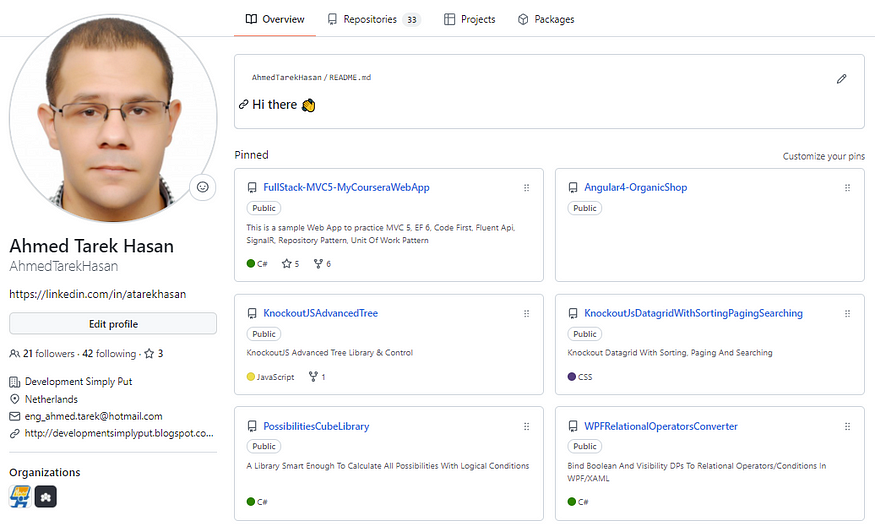
Когда я проверил HTML, я обнаружил следующее:
- Все мои закрепленные репозитории находятся внутри основного контейнера по следующему пути: div[@class=js-pinned-items-reorder-container] > пр > ли
- Каждый закрепленный репозиторий содержится внутри контейнера со следующим относительным путем к родительскому пути: div > раздел
- Каждый закрепленный репозиторий будет иметь свое имя внутри div > раздел > диапазон > a и его описание внутри p
Написание кода
Вот шаги, которые я выполнил:
- Создано консольное приложение. Решение: WebScraping. Проект: WebScraper.
- Установлен пакет NuGet HtmlAgilityPack.
- Добавлена директива using
using HtmlAgilityPack - Определил метод
private static Task<string> GetHtml()для получения HTML. - Определил метод
private static List<(string RepositoryName, string Description)> ParseHtmlUsingHtmlAgilityPack(string html)для анализа HTML. - И наконец, код должен выглядеть следующим образом:
using System.Collections.Generic;
using System.Net.Http;
using System.Threading.Tasks;
using HtmlAgilityPack;
namespace WebScraper
{
class Program
{
static async Task Main(string[] args)
{
var html = await GetHtml();
var data = ParseHtmlUsingHtmlAgilityPack(html);
}
private static Task<string> GetHtml()
{
var client = new HttpClient();
return client.GetStringAsync("https://github.com/AhmedTarekHasan");
}
private static List<(string RepositoryName, string Description)> ParseHtmlUsingHtmlAgilityPack(string html)
{
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var repositories =
htmlDoc
.DocumentNode
.SelectNodes("//div[@class='js-pinned-items-reorder-container']/ol/li/div/div");
List<(string RepositoryName, string Description)> data = new();
foreach (var repo in repositories)
{
var name = repo.SelectSingleNode("div/div/span/a").InnerText;
var description = repo.SelectSingleNode("p").InnerText;
data.Add((name, description));
}
return data;
}
}
}
Запустив этот код, вы получите следующее

Конечно, вы можете использовать некоторую очистку струн здесь, но это не имеет большого значения.
Как видите, использовать HttpClient и HtmlAgilityPack просто. Все, что вам нужно, это привыкнуть к их API, и тогда это будет несложно.
Что вам также нужно иметь в виду, так это то, что некоторые веб-сайты потребуют дополнительной работы с вашей стороны. Иногда веб-сайту могут потребоваться данные для входа, токены аутентификации, некоторые определенные заголовки и т. д.
Все это вы по-прежнему можете обрабатывать с помощью HttpClient или других библиотек, которые вы можете использовать для выполнения вызова.
Парсинг динамического веб-сайта
Теперь мы должны попытаться удалить некоторые данные с динамического веб-сайта. Однако, поскольку я должен быть осторожен перед парсингом веб-сайта, я бы применил тот же пример, что и раньше, но теперь предполагая, что веб-сайт является динамическим.
Поэтому, опять же, в этом примере мы собираемся удалить мой собственный профиль GitHub https://github.com/AhmedTarekHasan< /сильный>
Наблюдение за структурой данных в HTML
Это будет то же самое, что и раньше.
Написание кода
Вот шаги, которые я выполнил:
- Создано консольное приложение. Решение: WebScraping. Проект: WebScraper.
- Установлен пакет NuGet HtmlAgilityPack.
- Установлен пакет NuGet Selenium.WebDriver.
- Установлен пакет NuGet Selenium.WebDriver.ChromeDriver.
- Добавлена директива using
using HtmlAgilityPack - Добавлена директива using
using OpenQA.Selenium.Chrome; - Определен метод
private static string GetHtml()для получения HTML. - Определил метод
private static List<(string RepositoryName, string Description)> ParseHtmlUsingHtmlAgilityPack(string html)для анализа HTML. - И наконец, код должен выглядеть следующим образом:
using System.Collections.Generic;
using HtmlAgilityPack;
using OpenQA.Selenium.Chrome;
namespace WebScraper
{
class Program
{
static void Main(string[] args)
{
var html = GetHtml();
var data = ParseHtmlUsingHtmlAgilityPack(html);
}
private static string GetHtml()
{
var options = new ChromeOptions
{
BinaryLocation = @"C:Program Files (x86)GoogleChromeApplicationchrome.exe"
};
options.AddArguments("headless");
var chrome = new ChromeDriver(options);
chrome.Navigate().GoToUrl("https://github.com/AhmedTarekHasan");
return chrome.PageSource;
}
private static List<(string RepositoryName, string Description)> ParseHtmlUsingHtmlAgilityPack(string html)
{
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var repositories =
htmlDoc
.DocumentNode
.SelectNodes("//div[@class='js-pinned-items-reorder-container']/ol/li/div/div");
List<(string RepositoryName, string Description)> data = new();
foreach (var repo in repositories)
{
var name = repo.SelectSingleNode("div/div/span/a").InnerText;
var description = repo.SelectSingleNode("p").InnerText;
data.Add((name, description));
}
return data;
}
}
}
Запустив этот код, вы получите следующее
Конечно, вы можете использовать некоторую очистку струн здесь, но это не имеет большого значения.
Как видите, использовать Selenium.WebDriver и Selenium.WebDriver.ChromeDriver очень просто.

Заключительные слова
Как видите, парсинг веб-страниц не так уж и сложен, но на самом деле он зависит от веб-сайта, который вы пытаетесь удалить. Иногда вы можете столкнуться с веб-сайтом, который нуждается в некоторых хитростях, чтобы заставить его работать.
Вот и все, надеюсь, вам было так же интересно читать эту статью, как мне было ее писать.
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27242)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)