

Как определить разницу между хранилищами данных, озерами данных и хранилищами данных
11 марта 2022 г.Полное руководство по хранилищу данных, озеру данных и озеру данных
Избавьтесь от путаницы: хранилище данных, озеро данных или хранилище данных
Пытаясь справиться с разрастанием данных, ИТ-директора разных отраслей сталкиваются с серьезными проблемами. Один из них — это место хранения всех корпоративных данных для обеспечения [надежной аналитики данных] (https://itrexgroup.com/services/data-analytics/). Традиционно существует два решения для хранения данных: хранилища данных и озера данных.
Хранилища данных в основном хранят преобразованные структурированные данные из операционных и транзакционных систем и используются для быстрых сложных запросов к этим историческим данным.
Озера данных действуют как дамп, в котором хранятся все виды данных, включая полуструктурированные и неструктурированные данные. Они расширяют возможности расширенной аналитики, такой как потоковая аналитика для обработки данных в реальном времени или машинного обучения. Исторически сложилось так, что развертывание хранилищ данных обходилось дорого, потому что нужно было платить как за место для хранения, так и за вычислительные ресурсы, помимо навыков, необходимых для их обслуживания. Поскольку стоимость хранения снизилась, хранилища данных стали дешевле. Некоторые считают, что озера данных (традиционно более экономичная альтернатива) уже мертвы. Некоторые утверждают, что озера данных все еще в моде.
Между тем, другие говорят о новом гибридном решении для хранения данных — хранилищах данных. Что не так с каждым из них? Давайте внимательно посмотрим. В этом блоге рассматриваются ключевые различия между хранилищами данных, озерами данных и хранилищами данных, популярные технологические стеки и варианты использования. В нем также содержатся советы по выбору правильного решения для вашей компании, хотя это и сложно.
Что такое хранилище данных?
Хранилища данных предназначены для хранения структурированных, курируемых данных, организации наборов данных в таблицы и столбцы. Эти данные легко доступны пользователям для традиционной бизнес-аналитики, информационных панелей и отчетов.
Архитектура хранилища данных
Трехуровневая архитектура является наиболее часто используемым подходом к проектированию хранилищ данных. Он включает в себя:
- Нижний уровень: промежуточная область и сервер базы данных хранилища данных, который используется для загрузки данных из различных источников. Процесс извлечения, преобразования и загрузки (ETL) — это традиционный подход к передаче данных в хранилище данных.
- Средний уровень: сервер онлайн-аналитической обработки (OLAP), который преобразует данные в многомерный формат для быстрых вычислений.
- Верхний уровень: API и интерфейсные инструменты для работы с данными.
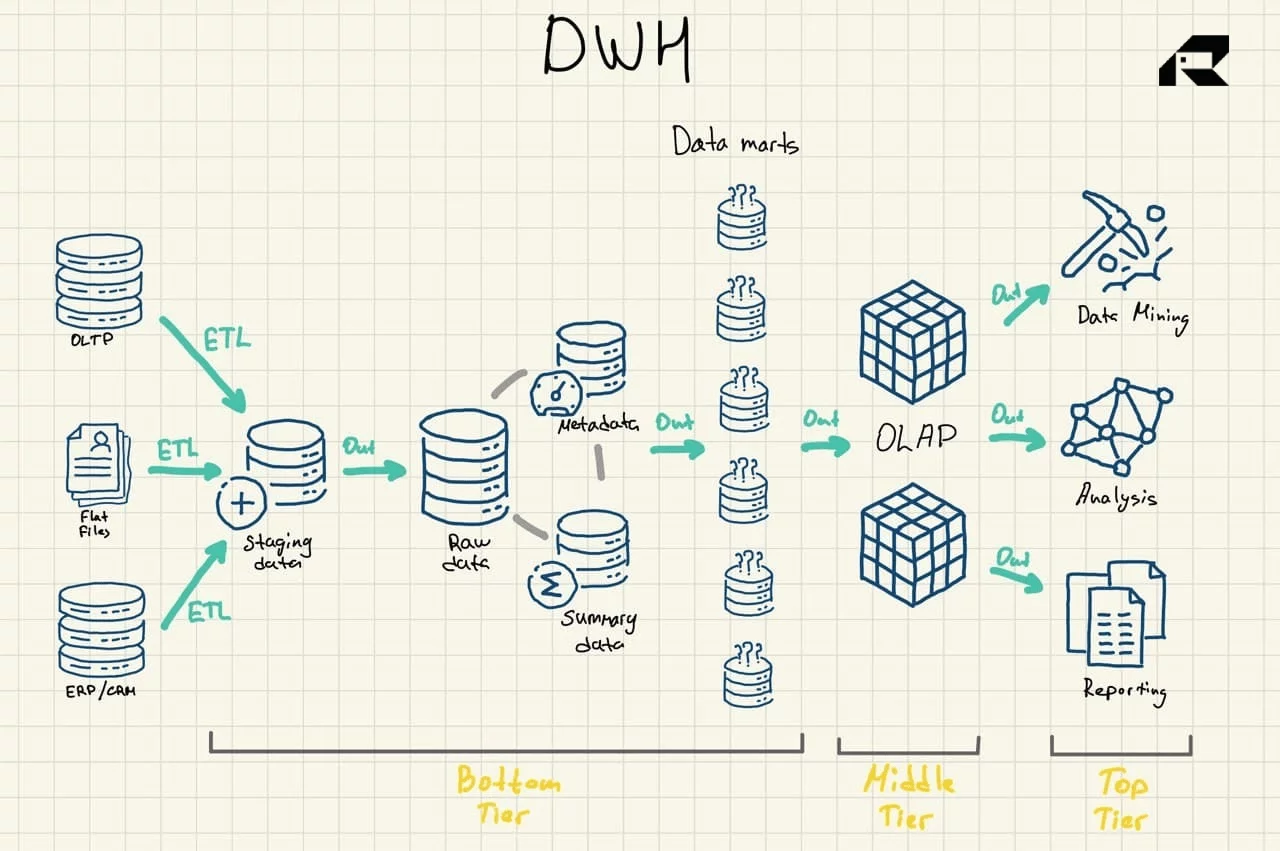
Следует упомянуть еще три жизненно важных компонента хранилища данных: витрина данных, оперативное хранилище данных и метаданные. Витрины данных относятся к нижнему уровню. В них хранятся подмножества данных хранилища данных, обслуживающие отдельные бизнес-направления. * Хранилища операционных данных * действуют как репозиторий, предоставляющий моментальный снимок самых последних данных организации для оперативной отчетности на основе простых запросов. Их можно использовать в качестве промежуточного слоя между источниками данных и хранилищем данных. Также есть метаданные — данные, описывающие данные хранилища данных, — которые хранятся в репозиториях специального назначения, также на нижнем уровне.
Эволюция и технологии хранилища данных
Хранилища данных существуют уже несколько десятилетий. Традиционно хранилища данных размещались локально, а это означало, что компаниям приходилось приобретать все оборудование и развертывать программное обеспечение локально, будь то платные системы или системы с открытым исходным кодом. Им также требовалась целая ИТ-команда для обслуживания хранилища данных.
С другой стороны, традиционные хранилища данных обеспечивали (и продолжают обеспечивать сегодня) быстрое получение информации без проблем с задержками, полный контроль над данными вместе со стопроцентной конфиденциальностью и минимальным риском для безопасности. Благодаря повсеместному распространению облака многие организации теперь предпочитают переходить на решения для облачных хранилищ данных, где все данные хранятся в облаке. Он также анализируется в облаке с использованием встроенного механизма запросов.
На рынке существует множество зарекомендовавших себя решений для облачных хранилищ данных. Каждый провайдер предлагает свой уникальный набор складских возможностей и разные модели ценообразования. Например, Amazon Redshift организован как традиционное хранилище данных. Снежинка похожа.
Microsoft Azure — это хранилище данных SQL, в то время как Google BigQuery основан на бессерверной архитектуре, предлагающей, по сути, программное обеспечение как услугу (SaaS), а не инфраструктуру или платформу как услугу, как, например, Amazon Redshift.
Среди хорошо известных локальных хранилищ данных — IBM Db2, Oracle Autonomous Database, IBM Netezza, Teradata Vantage, SAP HANA и Exasol. Они также доступны в облаке. Облачные хранилища данных, очевидно, дешевле, потому что нет необходимости покупать или разворачивать физические серверы. Пользователи платят только за место для хранения и вычислительную мощность по мере необходимости.
Облачные решения также намного проще масштабировать или интегрировать с другими сервисами. Хранилища данных, удовлетворяющие весьма специфические потребности бизнеса с высочайшим качеством данных и быстрым получением информации, останутся надолго.
Варианты использования хранилища данных
Хранилища данных обеспечивают высокоскоростную и высокопроизводительную аналитику петабайтов и петабайтов исторических данных. Они в основном предназначены для запросов типа BI. Хранилище данных может дать ответ, например, о продажах за определенный период времени, сгруппированных по регионам или подразделениям, а также о движении продаж по годам. Ключевые варианты использования хранилищ данных:
- Транзакционная отчетность для представления картины эффективности бизнеса
- Специальный анализ/отчетность для предоставления ответов на отдельные и «разовые» бизнес-задачи
- Интеллектуальный анализ данных для извлечения полезных знаний и скрытых шаблонов из данных для решения сложных реальных проблем.
- Динамическое представление посредством визуализации данных
- Детализация для просмотра иерархических измерений данных для получения подробной информации
Хранение структурированных бизнес-данных в одном легкодоступном месте за пределами операционных баз данных очень важно для любой компании, специализирующейся на данных. Однако традиционные хранилища данных не поддерживают технологию больших данных. Они также обновляются в пакетном режиме, при этом записи из всех источников периодически обрабатываются за один раз, а это означает, что данные могут устареть к моменту их объединения для аналитики. Озеро данных, кажется, устраняет эти ограничения. С компромиссом. Давайте исследовать.
Что такое озеро данных?
Озера данных в основном собирают необработанные необработанные данные в их исходной форме. Еще одно ключевое различие между озером данных и хранилищем данных заключается в том, что озера данных хранят эти данные, не упорядочивая их в какие-либо логические отношения, называемые схемами. Однако именно так они обеспечивают более сложную аналитику. Озера данных извлекают (i) транзакционные данные из бизнес-приложений, таких как ERP, CRM или SCM, (ii) документы в форматах .csv и .txt, (iii) частично структурированные данные, такие как форматы XML, JSON и AVRO, (iv) журналы устройств и датчики IoT, и (v) изображения, аудио, двоичные файлы, PDF-файлы.
Архитектура озера данных
Озера данных используют плоскую архитектуру для хранения данных. Его ключевыми компонентами являются:
- Бронзовая зона для всех данных, поступающих в озеро. Данные хранятся либо как есть для пакетных шаблонов, либо в виде агрегированных наборов данных для потоковых рабочих нагрузок.
- Серебряная зона, где данные фильтруются и обогащаются для изучения в соответствии с потребностями бизнеса
- Золотая зона, где хранятся хорошо структурированные данные для применения инструментов бизнес-аналитики и алгоритмов машинного обучения. В этой зоне часто находится оперативное хранилище данных, которое питает традиционные хранилища данных и витрины данных.
- Песочница, где можно экспериментировать с данными для проверки гипотез и тестов. Он реализован либо как полностью отдельная база данных для Hadoop или других технологий NoSQL, либо как часть золотой зоны.
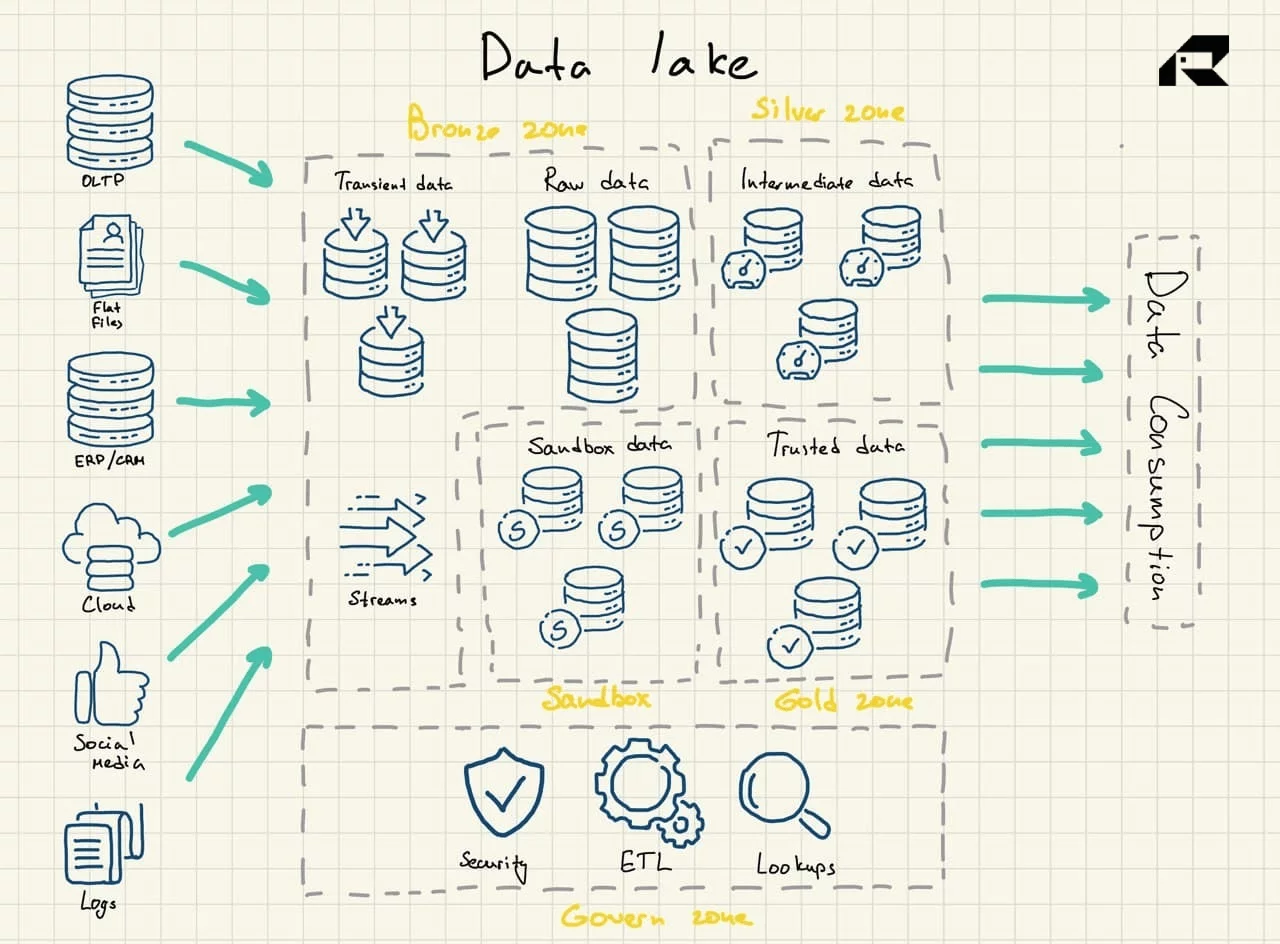
Озера данных по своей сути не содержат аналитических возможностей. Без них они просто хранят необработанные данные, которые сами по себе бесполезны. Таким образом, организации создают хранилища данных или используют другие инструменты поверх озер данных, чтобы использовать данные. Чтобы озеро данных не превратилось в болото данных, важно иметь эффективную стратегию управления данными, чтобы включить встроенные средства управления данными и метаданными в структуру озера данных. В идеальном мире данные, хранящиеся в озере данных, должны быть каталогизированы, проиндексированы, проверены и легко доступны для пользователей данных. Однако это случается редко, и многие проекты озера данных терпят неудачу. Этого можно избежать: вне зависимости от зрелости группы обработки данных крайне важно установить хотя бы необходимые элементы управления для обеспечения проверки и качества данных.
Эволюция озера данных и технологии
Рост больших данных в начале 2000-х годов принес организациям как большие возможности, так и большие проблемы. Бизнес нуждался в новых технологиях для анализа этих огромных, беспорядочных и смехотворно быстрорастущих наборов данных, чтобы [зафиксировать влияние больших данных на бизнес] (https://itrexgroup.com/blog/big-data-and-its-business-impact). /). В 2008 году Apache Hadoop представила инновационную технологию с открытым исходным кодом для сбора и обработки неструктурированных данных в больших масштабах, проложив путь к аналитике больших данных и озерам данных.
Вскоре после этого появился Apache Spark. Это было проще в использовании. Кроме того, он предоставил возможности для построения и обучения моделей ML, запросов к структурированным данным с использованием SQL и обработки данных в реальном времени. Сегодня озера данных — это преимущественно облачные репозитории. Все ведущие поставщики облачных услуг, такие как AWS, Azure и Google, предлагают облачные озера данных с экономичными службами хранения объектов.
Их платформы поставляются с различными службами управления данными для автоматизации развертывания. Например, в одном сценарии озеро данных может состоять из системы хранения данных, такой как распределенная файловая система Hadoop (HDFS) или Amazon S3, интегрированная с решением облачного хранилища данных, таким как Amazon Redshift. Эти компоненты будут отделены от сервисов в экосистеме, которые могут включать Amazon EMR для обработки данных, Amazon Glue, обеспечивающий каталог данных и функции преобразования, сервис запросов Amazon Athena или сервис Amazon Elasticsearch, который используется для создания репозитория метаданных и индексирования. данные. Локальные озера данных по-прежнему распространены из-за обычных облачных проблем, таких как безопасность, конфиденциальность или задержка. Есть также поставщики локальных хранилищ, которые предлагают некоторые продукты для озер данных, но их предложения озер данных, однако, не являются четко определенными.
В отличие от хранилищ данных, озера данных не имеют за плечами многолетнего реального развертывания. До сих пор существует много критических замечаний, описывающих концепцию озера данных как размытую и нечеткую. Критики также утверждают, что лишь немногие люди в любой организации обладают навыками (или энтузиазмом, если уж на то пошло) выполнять исследовательские рабочие нагрузки с необработанными данными. По их словам, к идее использования озер данных в качестве центрального хранилища данных всех предприятий следует подходить с осторожностью. Также были провокационные разговоры о том, что дни озера данных сочтены. Называются следующие причины:
- Озера данных не могут эффективно масштабировать вычислительные ресурсы по требованию (ну, это потому, что они изначально не предусмотрены дизайном)
- Озера данных несут в себе большой технологический долг, и их создание обусловлено в первую очередь маркетинговой рекламой, а не техническими причинами (то же самое произошло и со многими хранилищами данных).
- С появлением решений для облачных хранилищ данных озера данных больше не предлагают значительных преимуществ с точки зрения затрат (вопрос затрат не так прост, поскольку трудно прогнозировать затраты на вычисления).
Такая критика является неотъемлемой частью любой более молодой технологии. Однако у озер данных есть четкие варианты использования, такие как потоковая аналитика. И пока что они не угрожают хранилищам данных. В какой-то момент озера данных даже одержали победу над хранилищами данных, предлагая более широкие аналитические возможности, экономичность и гибкость в отношении хранимых данных. Однако по мере развития технологий хранилищ данных многие соглашаются, что сейчас нет явного победителя. Обычно рекомендуется поддерживать их оба или… использовать гибридную архитектуру. Читать дальше.
Варианты использования озера данных
Основная идея озер данных — как можно быстрее предоставить предприятиям доступ ко всем доступным данным из всех источников. Озера данных не просто дают картину того, что произошло вчера. Озера данных предназначены для хранения огромных объемов данных, чтобы организации могли больше узнать как о настоящем (с помощью потоковой аналитики), так и о будущем (с помощью решений для больших данных, включая прогнозную аналитику и машинное обучение).
Ключевые варианты использования озер данных:
- Наполнение корпоративного хранилища данных наборами данных
- Выполнение потоковой аналитики
- Реализация ML-проектов
- Построение расширенных аналитических диаграмм с использованием давно зарекомендовавших себя корпоративных инструментов бизнес-аналитики, таких как Tableau или MS Power BI.
- Создание пользовательских решений для анализа данных
- Запуск анализа первопричин, который позволяет группам данных отслеживать проблемы до их корней.
Обладая сильными навыками обработки данных для перемещения необработанных данных в аналитическую среду, озера данных могут быть чрезвычайно актуальны. Они позволяют командам экспериментировать с данными, чтобы понять, как они могут быть полезны. Это может включать создание моделей для анализа данных и опробования различных схем для просмотра данных по-новому.
Озера данных также позволяют обрабатывать потоковые данные, которые поступают из веб-журналов и датчиков IoT и не подходят для традиционного подхода к хранилищу данных. Короче говоря, озера данных позволяют организациям выявлять закономерности, предвидеть изменения или находить потенциальные возможности для бизнеса, связанные с новыми продуктами или текущими процессами. Озера данных и хранилища данных, используемые для различных бизнес-потребностей, часто реализуются в тандеме. Прежде чем мы перейдем к следующей концепции хранения данных, давайте быстро напомним основные различия между хранилищем данных и озером данных.
Хранилище данных и озеро данных

Как насчет новой гибридной архитектуры, хранилища данных?
Если оставить в стороне маркетинг, ключевой идеей хранилища данных является привнесение вычислительной мощности в озеро данных. Архитектурно домик у озера обычно состоит из:
- Уровень хранения для хранения данных в открытых форматах (например, Parquet). Этот уровень можно назвать озером данных, и он отделен от вычислительного уровня.
- Вычислительный уровень, предоставляющий организации возможности хранилища, поддерживающий управление метаданными, индексирование, применение схемы и транзакции ACID (атомарность, непротиворечивость, надежность и долговечность).
- Уровень API для доступа к ресурсам данных
- Уровень обслуживания для поддержки различных рабочих нагрузок, от отчетов до BI, обработки данных или машинного обучения.
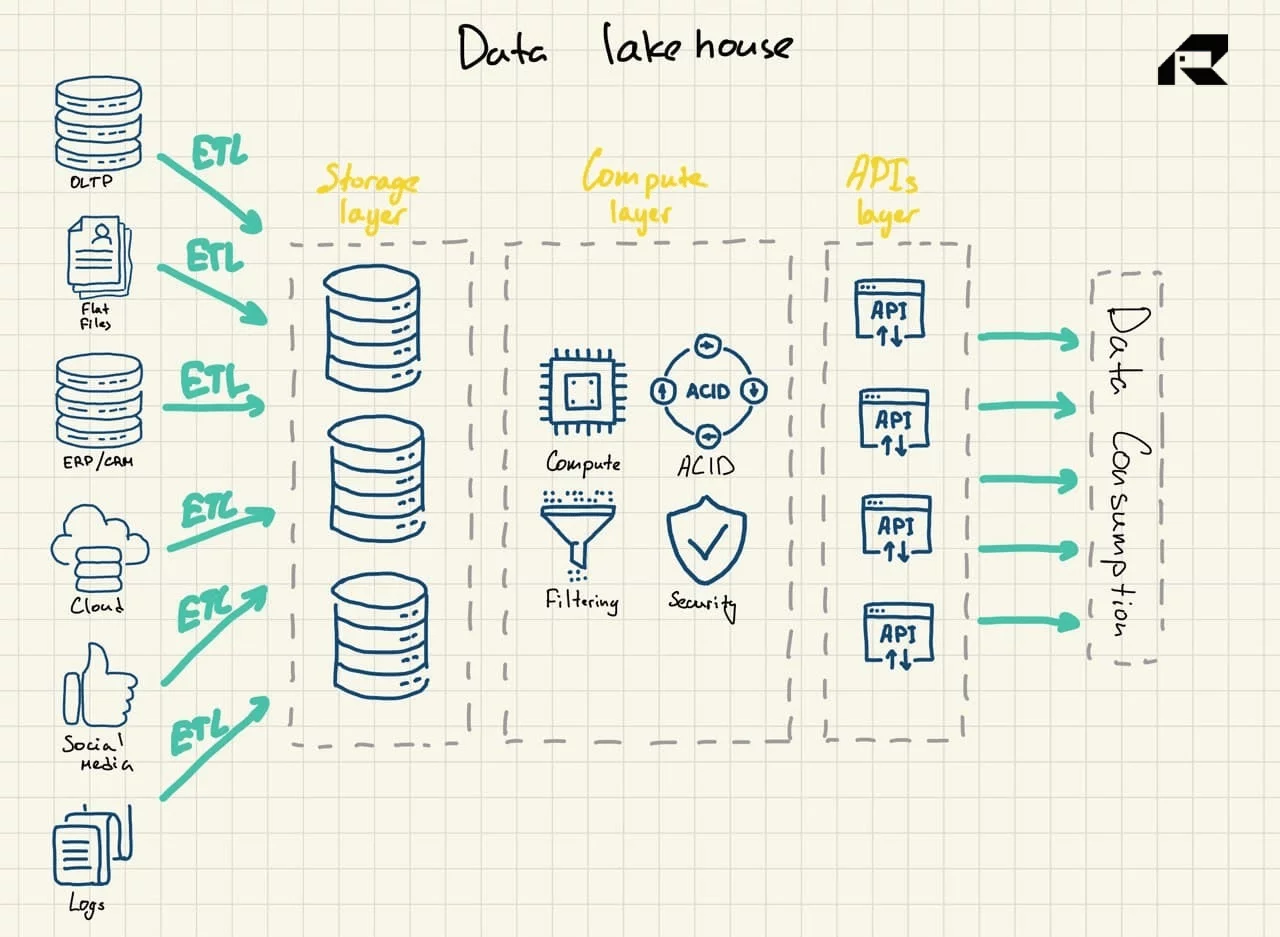
Рекламируемый как решение, объединяющее лучшее из обоих миров, хранилище данных решает обе проблемы:
- Ограничения хранилища данных, в том числе отсутствие поддержки расширенной аналитики данных, основанной как на структурированных, так и на неструктурированных данных, и значительные затраты на масштабирование с использованием традиционных хранилищ данных, которые не отделяют хранилище от вычислительных ресурсов.
- Проблемы озера данных, включая дублирование данных, качество данных и необходимость доступа к нескольким системам для различных задач или реализации сложных интеграций с инструментами аналитики.
Озеро данных — это новое достижение в сфере анализа данных. Концепция впервые была использована в 2017 году применительно к платформе Snowflake. В 2019 году AWS использовала термин «хранилище данных» для описания своего сервиса Amazon Redshift Spectrum, который позволяет пользователям его сервиса хранилища данных Amazon Redshift выполнять поиск в данных, хранящихся в Amazon S3. В 2020 году термин «хранилище данных» получил широкое распространение, и компания Databricks приняла его для своей платформы Delta Lake.
У хранилища данных может быть светлое будущее, поскольку компании из разных отраслей внедряют ИИ для улучшения операций обслуживания, предложения инновационных продуктов и услуг или достижения успеха в маркетинге. Структурированные данные из операционных систем, предоставляемые хранилищами данных, плохо подходят для интеллектуальной аналитики, в то время как озера данных просто не предназначены для надежных методов управления, безопасности или соответствия требованиям ACID.
Озеро данных и хранилище данных
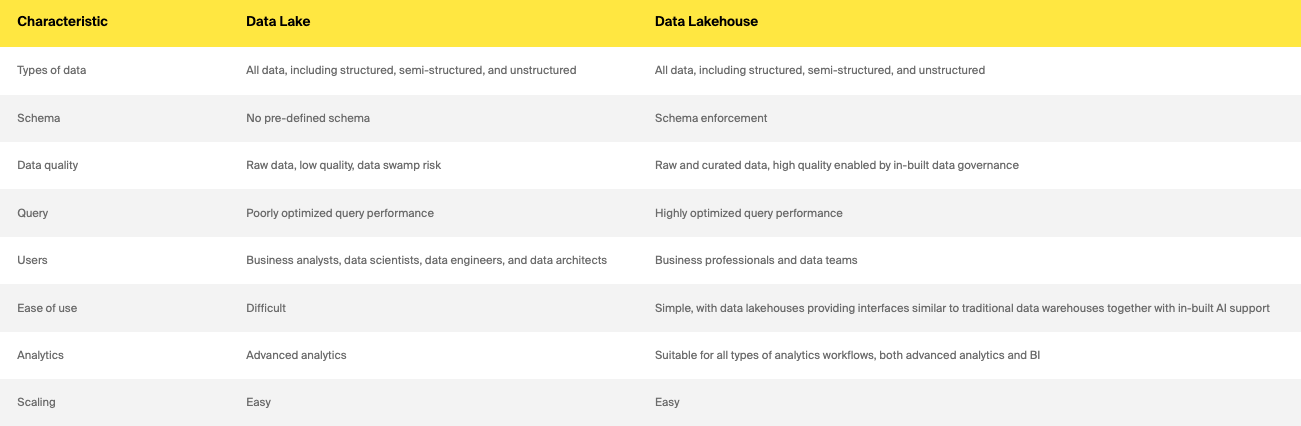
Итак, хранилище данных, озеро данных или хранилище данных: что выбрать
Если вы хотите создать решение для хранения данных с нуля или модернизировать свою устаревшую систему для поддержки машинного обучения или повышения производительности, правильный ответ будет непростым. По-прежнему много неясностей по поводу ключевых отличий, преимуществ и затрат, а предложения и модели ценообразования от поставщиков быстро развиваются. Кроме того, это всегда сложный проект, даже если у вас есть поддержка заинтересованных сторон. Однако при выборе хранилища данных, озера данных и хранилища данных необходимо учитывать некоторые ключевые моменты.
Главный вопрос, на который вы должны ответить: ПОЧЕМУ. Здесь следует помнить, что ключевые различия между хранилищем данных, озерами и домиками на озере не связаны с технологиями. Они предназначены для удовлетворения различных потребностей бизнеса. Итак, зачем вам вообще нужно решение для хранения данных? Это для регулярной отчетности, бизнес-аналитики, аналитики в реальном времени, [науки о данных] (https://itrexgroup.com/services/data-science-consulting/) или другого сложного анализа? Согласованность или своевременность данных важнее для нужд вашего бизнеса? Потратьте некоторое время на разработку вариантов использования. Ваши потребности в аналитике должны быть четко определены. Вы также должны глубоко понимать своих пользователей и наборы навыков. Несколько эмпирических правил:
- Хранилище данных — хороший выбор, если у вас есть конкретные вопросы и вы знаете, какие аналитические результаты вы хотите получать регулярно.
- Если вы работаете в жестко регулируемой отрасли, такой как здравоохранение или страхование, вам, возможно, потребуется прежде всего соблюдать обширные правила отчетности. Таким образом, хранилище данных будет лучшим выбором.
- Если ваши ключевые показатели эффективности и требования к отчетности можно удовлетворить с помощью простого исторического анализа, озеро данных или гибридное решение будет излишним. Вместо этого используйте хранилище данных.
- Если вашей группе данных нужен экспериментальный и исследовательский анализ, выберите озеро данных или гибридное решение. Однако для работы с неструктурированными данными вам потребуются сильные навыки анализа данных.
- Если вы являетесь организацией, специализирующейся на данных, которая хочет использовать технологию машинного обучения, гибридное решение или озеро данных будут естественным выбором.
Учитывайте также свой бюджет и временные ограничения. Озера данных, безусловно, создаются быстрее, чем хранилища данных, и, вероятно, дешевле. Возможно, вы захотите реализовать свою инициативу постепенно и добавлять возможности по мере масштабирования. Если вы хотите модернизировать свою устаревшую систему хранения данных, опять же, вы должны спросить, ЗАЧЕМ вам это нужно. Это слишком медленно? Или он не позволяет выполнять запросы к большим наборам данных? Не хватает каких-то данных? Вы хотите получить другой тип аналитики? Ваша организация потратила много денег на устаревшую систему, поэтому вам определенно нужно серьезное экономическое обоснование, чтобы отказаться от нее. Привяжите его к ROI тоже. Архитектуры хранения данных все еще развиваются. Нельзя точно сказать, как они будут развиваться. Однако независимо от того, какой путь вы выберете, полезно распознавать распространенные ловушки и максимально использовать уже существующие технологии.
Мы надеемся, что эта статья развеяла некоторую путаницу между хранилищами данных, озерами данных и хранилищами данных. Если у вас все еще есть вопросы или вам нужны передовые технические навыки или советы по созданию решения для хранения данных, напишите ITRex. Они помогут вам
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27430)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)