Введение
Данные Google Maps – это важная часть данных для компаний, занимающихся разработкой программного обеспечения для обзоров, сентиментальных аналитиков и сборщиков данных, поскольку они содержат такую информацию, как оценки пользователей, отзывы пользователей, адреса и изображения определенного места.
В этом руководстве мы узнаем, как извлечь ценную информацию из Карт Google с помощью Node JS. И в конце мы увидим, как Серпдог | Google Maps Reviews API может помочь вам извлечь отзывы Google Maps без каких-либо дополнительных усилий, которые требуются нам при очистке данных Google.

Требования:
Веб-анализ с помощью селекторов CSS
Поиск тегов в HTML-файлах — это не только сложная задача, но и трудоемкий процесс. Лучше использовать гаджет CSS-селекторов для выбора идеальных тегов, которые упростят ваш поиск в Интернете.
Этот гаджет может помочь вам создать идеальный селектор CSS для ваших нужд. Вот ссылка на руководство, которое научит вас использовать этот гаджет для выбора лучших селекторов CSS в соответствии с вашими потребностями.
Агенты пользователя
User-Agent используется для идентификации приложения, операционной системы, поставщика и версии запрашивающего пользовательского агента, что может сэкономить помощь при поддельном посещении Google, действуя от имени реального пользователя.
Вы также можете чередовать пользовательские агенты, подробнее об этом читайте в этой статье: Как подделывать и чередовать пользовательские агенты с помощью Python 3.
Если вы хотите дополнительно защитить свой IP от блокировки Google, вы можете попробовать эти 10 советов, как избежать блокировки при парсинге веб-сайтов.
Установить библиотеки
Прежде чем мы начнем, установите эти библиотеки, чтобы мы могли двигаться дальше и подготовить наш парсер.
Или вы можете ввести следующие команды в терминале вашего проекта, чтобы установить библиотеки:
npm i puppeteer
Цель:
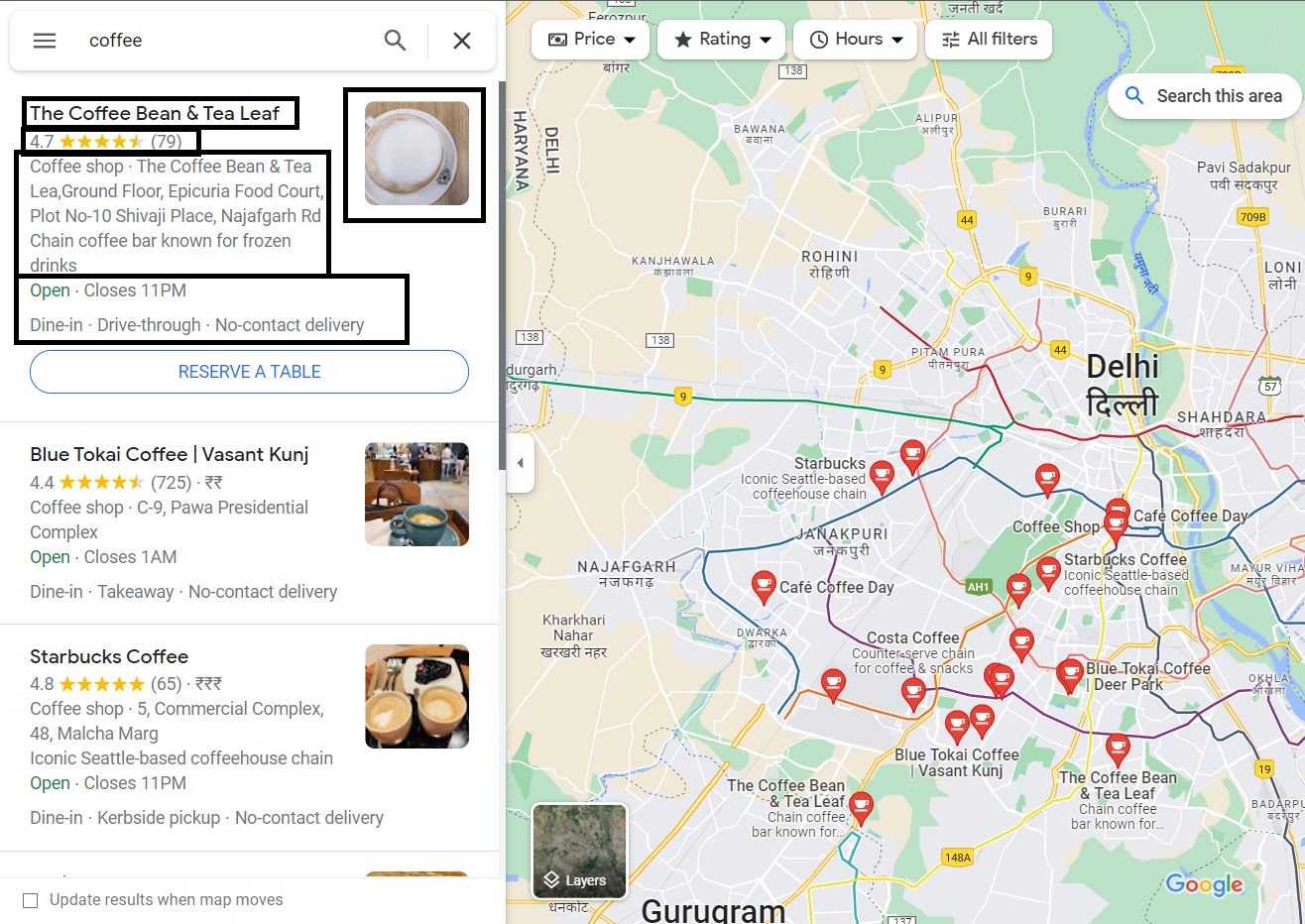
Процесс:
Скопируйте указанный ниже целевой URL, чтобы извлечь данные HTML:
https://www.google.com/maps/search/coffee/@28.6559457,77.1404218,11z
Кофе — наш запрос. После этого у нас есть широта и долгота. Число перед z в конце — это не что иное, как интенсивность масштабирования Google Maps. Вы можете уменьшить или увеличить его по своему выбору. Его значение варьируется от 2,92, при котором карта полностью уменьшается, до 21, при котором карта полностью увеличивается.
Примечание. Широта и долгота должны передаваться в URL. Но параметр масштабирования является необязательным.
Мы будем использовать метод бесконечной прокрутки Puppeteer для очистки результатов Google Maps. Итак, приступим к подготовке нашего парсера.
Во-первых, давайте создадим основную функцию, которая запустит браузер и перейдет к целевому URL-адресу.
const getMapsData = async () => {
browser = await puppeteer.launch({
headless: false,
args: ["--disabled-setuid-sandbox", "--no-sandbox"],
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent":
"Mozilla/5.0 (Macintosh; Intel Mac OS X 11_10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4882.194 Safari/537.36",
})
await page.goto("https://www.google.com/maps/search/Starbucks/@26.8484046,75.7215344,12z/data=!3m1!4b1" , {
waitUntil: 'domcontentloaded',
timeout: 60000
})
await page.waitForTimeout(3000);
let data = await scrollPage(page,".m6QErb[aria-label]",2)
console.log(data)
await browser.close();
};
Пошаговое объяснение:
puppeteer.launch()— это запустит браузер Chromium с параметрами, которые мы установили в нашем коде. В нашем случае мы запускаем браузер в автономном режиме.browser.newPage()— откроет новую страницу или вкладку в браузере.page.setExtraHTTPHeaders()— используется для передачи заголовков HTTP с каждым запросом, инициируемым страницей.page.goto()– переместит страницу по указанному целевому URL-адресу.page.waitForTimeout()– заставит страницу ждать 3 секунды для выполнения дальнейших операций.scrollPage(). Наконец, мы вызвали наш бесконечный скроллер, чтобы извлечь нужные нам данные с помощью страницы, тега для скроллераdiv и количество элементов, которые мы хотим использовать в качестве параметров.
Теперь давайте подготовим бесконечный скроллер.
const scrollPage = async(page, scrollContainer, itemTargetCount) => {
let items = [];
let previousHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
while (itemTargetCount > items.length) {
items = await extractItems(page);
await page.evaluate(`document.querySelector("${scrollContainer}").scrollTo(0, document.querySelector("${scrollContainer}").scrollHeight)`);
await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight > ${previousHeight}`);
await page.waitForTimeout(2000);
}
return items;
}
Пошаговое объяснение:
previousHeight— прокрутка высоты контейнера.extractItems()– функция для анализа извлеченного HTML-кода.- На следующем шаге мы просто прокрутили контейнер вниз до высоты, равной
previousHeight. - И на последнем шаге мы ждали, пока контейнер прокрутится вниз, пока его высота не станет больше, чем предыдущая высота.
И, наконец, поговорим о нашем парсере.
const extractItems = async(page) => {
let maps_data = await page.evaluate(() => {
return Array.from(document.querySelectorAll(".Nv2PK")).map((el) => {
const link = el.querySelector("a.hfpxzc").getAttribute("href");
return {
title: el.querySelector(".qBF1Pd")?.textContent.trim(),
avg_rating: el.querySelector(".MW4etd")?.textContent.trim(),
reviews: el.querySelector(".UY7F9")?.textContent.replace("(", "").replace(")", "").trim(),
address: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(1) > span:last-child")?.textContent.replaceAll("·", "").trim(),
description: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(2)")?.textContent.replace("·", "").trim(),
website: el.querySelector("a.lcr4fd")?.getAttribute("href"),
category: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(1) > span:first-child")?.textContent.replaceAll("·", "").trim(),
timings: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(3) > span:first-child")?.textContent.replaceAll("·", "").trim(),
phone_num: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(3) > span:last-child")?.textContent.replaceAll("·", "").trim(),
extra_services: el.querySelector(".qty3Ue")?.textContent.replaceAll("·", "").replaceAll(" ", " ").trim(),
latitude: link.split("!8m2!3d")[1].split("!4d")[0],
longitude: link.split("!4d")[1].split("!16s")[0],
link,
dataId: link.split("1s")[1].split("!8m")[0],
};
});
});
return maps_data;
}
Пошаговое объяснение:
document.querySelectorAll()— возвращает все элементы, соответствующие указанному селектору CSS. В нашем случае этоNv2PK.getAttribute()– возвращает значение атрибута указанного элемента.textContent— возвращает текстовое содержимое внутри выбранного элемента HTML.split()– используется для разделения строки на подстроки с помощью указанного разделителя и возврата их в виде массива.trim()– удаляет пробелы в начале и в конце строки.replaceAll()— заменяет указанный шаблон из всей строки.
Вот полный код:
const puppeteer = require('puppeteer');
const extractItems = async(page) => {
let maps_data = await page.evaluate(() => {
return Array.from(document.querySelectorAll(".Nv2PK")).map((el) => {
const link = el.querySelector("a.hfpxzc").getAttribute("href");
return {
title: el.querySelector(".qBF1Pd")?.textContent.trim(),
avg_rating: el.querySelector(".MW4etd")?.textContent.trim(),
reviews: el.querySelector(".UY7F9")?.textContent.replace("(", "").replace(")", "").trim(),
address: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(1) > span:last-child")?.textContent.replaceAll("·", "").trim(),
description: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(2)")?.textContent.replace("·", "").trim(),
website: el.querySelector("a.lcr4fd")?.getAttribute("href"),
category: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(1) > span:first-child")?.textContent.replaceAll("·", "").trim(),
timings: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(3) > span:first-child")?.textContent.replaceAll("·", "").trim(),
phone_num: el.querySelector(".W4Efsd:last-child > .W4Efsd:nth-of-type(3) > span:last-child")?.textContent.replaceAll("·", "").trim(),
extra_services: el.querySelector(".qty3Ue")?.textContent.replaceAll("·", "").replaceAll(" ", " ").trim(),
latitude: link.split("!8m2!3d")[1].split("!4d")[0],
longitude: link.split("!4d")[1].split("!16s")[0],
link,
dataId: link.split("1s")[1].split("!8m")[0],
};
});
});
return maps_data;
}
const scrollPage = async(page, scrollContainer, itemTargetCount) => {
let items = [];
let previousHeight = await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight`);
while (itemTargetCount > items.length) {
items = await extractItems(page);
await page.evaluate(`document.querySelector("${scrollContainer}").scrollTo(0, document.querySelector("${scrollContainer}").scrollHeight)`);
await page.evaluate(`document.querySelector("${scrollContainer}").scrollHeight > ${previousHeight}`);
await page.waitForTimeout(2000);
}
return items;
}
const getMapsData = async () => {
browser = await puppeteer.launch({
headless: false,
args: ["--disabled-setuid-sandbox", "--no-sandbox"],
});
const [page] = await browser.pages();
await page.setExtraHTTPHeaders({
"User-Agent":
"Mozilla/5.0 (Macintosh; Intel Mac OS X 11_10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4882.194 Safari/537.36",
})
await page.goto("https://www.google.com/maps/search/Starbucks/@26.8484046,75.7215344,12z/data=!3m1!4b1" , {
waitUntil: 'domcontentloaded',
timeout: 60000
})
await page.waitForTimeout(5000)
let data = await scrollPage(page,".m6QErb[aria-label]",2)
console.log(data)
await browser.close();
};
getMapsData();
Результаты:
Наш результат должен выглядеть так 👇🏻:
[
{
title: 'The Coffee Bean & Tea Leaf',
avg_rating: '4.7',
reviews: '79',
address: 'The Coffee Bean & Tea Lea,Ground Floor, Epicuria Food Court, Plot No-10 Shivaji Place, Najafgarh Rd',
description: 'Chain coffee bar known for frozen drinks',
category: 'Coffee shop',
timings: 'Open ⋅ Closes 11PM',
phone_num: 'Open ⋅ Closes 11PM',
extra_services: 'Dine-in Drive-through No-contact delivery Reserve a table',
latitude: '28.6511983',
longitude: '77.1215014',
link: 'https://www.google.com/maps/place/The+Coffee+Bean+%26+Tea+Leaf/data=!4m7!3m6!1s0x390ce3a69997ad37:0xff83fd9a57a7a71e!8m2!3d28.6511983!4d77.1215014!16s%2Fg%2F11sgxr14tq!19sChIJN62XmabjDDkRHqenV5r9g_8?authuser=0&hl=en&rclk=1',
dataId: '0x390ce3a69997ad37:0xff83fd9a57a7a71e'
},
{
title: 'The Coffee Bean & Tea Leaf',
avg_rating: '4.0',
reviews: '271',
address: 'T320, Ambience Mall, Gurgaon - Delhi Expy',
description: 'Chain coffee bar known for frozen drinks',
category: 'Coffee shop',
timings: 'Open ⋅ Closes 11PM',
phone_num: 'Open ⋅ Closes 11PM',
extra_services: 'Dine-in Takeaway No-contact delivery',
latitude: '28.5041789',
longitude: '77.0970538',
link: 'https://www.google.com/maps/place/The+Coffee+Bean+%26+Tea+Leaf/data=!4m7!3m6!1s0x390d194c1a223247:0x611f25bf4fddaf08!8m2!3d28.5041789!4d77.0970538!16s%2Fg%2F11cs6ch67r!19sChIJRzIiGkwZDTkRCK_dT78lH2E?authuser=0&hl=en&rclk=1',
dataId: '0x390d194c1a223247:0x611f25bf4fddaf08'
},
.....
API отзывов Google Maps от Serpdog
Сокращение, в конечном счете, может стать трудоемким процессом, так как вам нужно поддерживать парсер в соответствии с изменяющимися селекторами CSS. Чтобы решить эту проблему, мы в Serpdog | Google Search API также предлагает Google Maps Reviews API, который возвращает HTML и готовые структурированные данные JSON. пользователям. В настоящее время мы работаем над Google Maps API, который запустим через некоторое время.
Парсинг Google также требует разгадывания капч, большого пула пользовательских агентов и прокси-серверов, но Serpdog решает все эти проблемы от своего имени, обеспечивая беспрепятственный парсинг.
Наши пользователи также получают 100 бесплатных запросов при первой регистрации.
const axios = require('axios');
axios.get('https://api.serpdog.io/reviews?api_key=APIKEY&data_id=0x89c25090129c363d:0x40c6a5770d25022b')
.then(response => {
console.log(response.data);
})
.catch(error => {
console.log(error);
});
Результаты:
"location_info": {
"title": "Statue of Liberty",
"address": "New York, NY",
"avgRating": "4.7",
"totalReviews": "83,109 reviews"
},
"reviews": [
{
"user": {
"name": "Vo Kien Thanh",
"link": "https://www.google.com/maps/contrib/106465550436934504158?hl=en-US&sa=X&ved=2ahUKEwj7zY_J4cv4AhUID0QIHZCtC0cQvvQBegQIARAZ",
"thumbnail": "https://lh3.googleusercontent.com/a/AATXAJxv5_uPnmyIeoARlf7gMWCduHV1cNI20UnwPicE=s40-c-c0x00000000-cc-rp-mo-ba4-br100",
"localGuide": true,
"reviews": "111",
"photos": "329"
},
"rating": "Rated 5.0 out of 5,",
"duration": "5 months ago",
"snippet": "The icon of the U.S. 🗽🇺🇸. This is a must-see for everyone who visits New York City, you would never want to miss it.There’s only one cruise line that is allowed to enter the Liberty Island and Ellis Island, which is Statue Cruises. You can purchase tickets at the Battery Park but I’d recommend you purchase it in advance. For $23/adult it’s actually very reasonably priced. Make sure you go early because you will have to go through security at the port. Also take a look at the departure schedule available on the website to plan your trip accordingly.As for the Statue of Liberty, it was my first time seeing it in person so what I could say was a wow. It was absolutely amazing to see this monument. I also purchased the pedestal access so it was pretty cool to see the inside of the statue. They’re not doing the Crown Access due to Covid-19 concerns, but I hope it will be resumed soon.There are a gift shop, a cafeteria and a museum on the island. I would say it takes around 2-3 hours to do everything here because you would want to take as many photos as possible.I absolutely loved it here and I can’t wait to come back.The icon of the U.S. 🗽🇺🇸. This is a must-see for everyone who visits New York City, you would never want to miss it. …More",
"visited": "",
"likes": "91",
"images": [
"https://lh5.googleusercontent.com/p/AF1QipPOBhJtq17DAc9_ZTBnN2X4Nn-EwIEet61Y9JQo=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipPZ2ut1I7LnECqEB2vzrBk-PSXzBxaHEE4S54lk=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipM8nIogBhwcL-dUrd7KaIxZcc_SA6YnJpp50R0C=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipPQ-YP7uw_gHTNb1gGZSGRGRrzLMzOrvh98AmSN=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipOTqBzK30vQZi9lfuhpk5329bnx-twzgIVjwcI1=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipN0TWUE35ajoTdSKelspuUpK-ZTXlRRR9SfPbTa=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipPQH_4HtdXmSdkCiDTv2jO30LksCxpe9KQI4YKw=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipN_OfX2TgXVNry5fli5v-yExbyTAfV4K7SEy3T0=w100-h100-p-n-k-no",
"https://lh5.googleusercontent.com/p/AF1QipNWKl0TeBmnzMaR_W4-7skitDwHjjJxPePbiSyd=w100-h100-p-n-k-no"
]
},
........
Вывод:
В этом учебном пособии мы научились очищать результаты Google Maps с помощью Node JS. Не стесняйтесь сообщить мне, если я что-то пропустил. Подпишитесь на меня в Твиттере. Спасибо за прочтение!
Дополнительные ресурсы
- Очистить результаты обычного поиска Google
- Очистка изображений Google
- Очистить результаты новостей Google
- Скрапинг веб-страниц Google с помощью Node JS: полное руководство
Первоначально опубликовано здесь