
Как сократить расходы с помощью плотной кластерной упаковки Google Kubernetes Engine (GKE)
22 февраля 2023 г.Всем привет! Сегодня мы хотели бы поделиться нашим опытом использования Google Kubernetes Engine для управления нашими кластерами Kubernetes. Мы используем его последние три года в рабочей среде и рады, что нам больше не нужно беспокоиться об управлении этими кластерами самостоятельно.
В настоящее время все наши тестовые среды и уникальные инфраструктурные кластеры находятся под управлением Kubernetes. Сегодня мы хотим рассказать о том, как мы столкнулись с проблемой в нашем тестовом кластере и как мы надеемся, что эта статья сэкономит другим время и усилия.
Мы должны предоставить информацию о нашей тестовой инфраструктуре, чтобы полностью понять нашу проблему. У нас есть более пяти постоянных тестовых сред, и мы развертываем среды для разработчиков по запросу. Количество модулей в рабочие дни достигает 6000 в течение дня и продолжает расти. Так как нагрузка нестабильна, мы упаковываем модули очень плотно, чтобы сэкономить на расходах, а перепродажа ресурсов — наша лучшая стратегия.
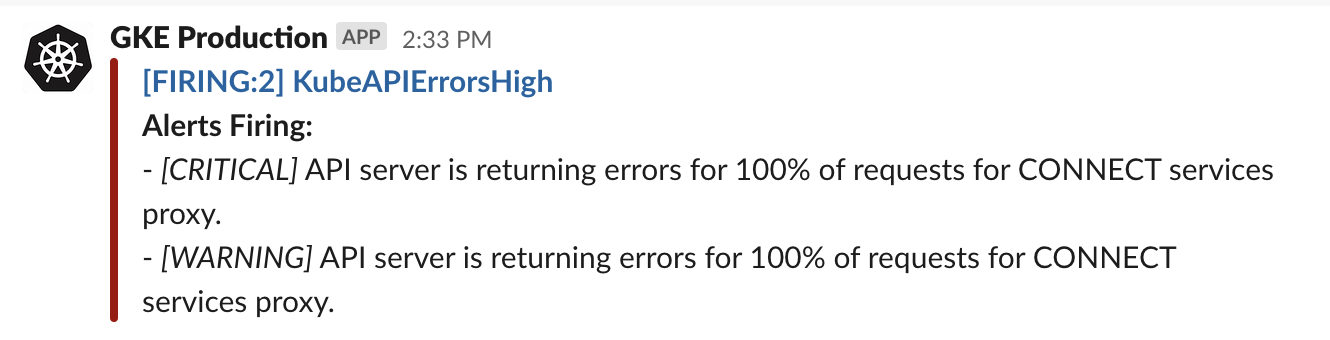
Эта конфигурация хорошо работала для нас, пока однажды мы не получили предупреждение и не смогли удалить пространство имен. Сообщение об ошибке, которое мы получили относительно удаления пространства имен, было следующим:
$ kubectl delete namespace arslanbekov
Error from server (Conflict): Operation cannot be fulfilled on namespaces "arslanbekov": The system is ensuring all content is removed from this namespace. Upon completion, this namespace will automatically be purged by the system.
Даже использование опции принудительного удаления не решило проблему:
$ kubectl get namespace arslanbekov -o yaml
apiVersion: v1
kind: Namespace
metadata:
...
spec:
finalizers:
- kubernetes
status:
phase: Terminating
Чтобы решить проблему зависания пространства имен, мы следовали руководству. Тем не менее, это временное решение не было идеальным, поскольку наши разработчики должны были иметь возможность создавать и удалять свои среды по своему желанию, используя абстракцию пространства имен.
Решив найти лучшее решение, мы решили продолжить расследование. Оповещение указывало на проблему с метриками, которую мы подтвердили, выполнив команду:
$ kubectl api-resources --verbs=list --namespaced -o name
error: unable to retrieve the complete list of server APIs: metrics.k8s.io/v1beta1: the server is currently unable to handle the request
Мы обнаружили, что модуль сервера метрик столкнулся с ошибкой нехватки памяти (OOM) и панической ошибкой в журналах:
apiserver panic'd on GET /apis/metrics.k8s.io/v1beta1/nodes: killing connection/stream because serving request timed out and response had been started
goroutine 1430 [running]:
Причина была в ограничениях ресурсов модуля:
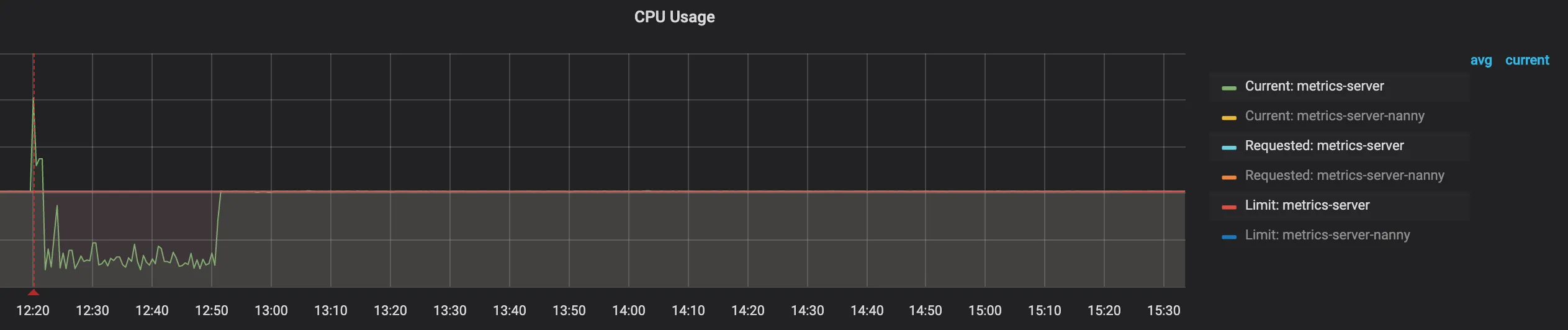
Эти проблемы с контейнером возникали из-за его определения, которое было следующим (блок ограничений):
resources:
limits:
cpu: 51m
memory: 123Mi
requests:
cpu: 51m
memory: 123Mi
Проблема заключалась в том, что контейнеру было выделено всего 51 м ЦП, что примерно эквивалентно 0,05 одного ядра ЦП, и этого было недостаточно для обрабатывать метрики для такого большого количества модулей. В основном используется планировщик CFS.
Обычно решение таких проблем простое и требует простого выделения дополнительных ресурсов для модуля. Однако в GKE этот параметр недоступен в пользовательском интерфейсе или через интерфейс командной строки gcloud. Это связано с тем, что Google защищает системные ресурсы от изменения, что понятно, учитывая, что все управление осуществляется на их стороне.
Мы обнаружили, что не единственные, кто столкнулся с этой проблемой, и нашли похожая проблема, когда автор пытался изменить определение модуля вручную. Он добился успеха, а мы нет. Когда мы попытались изменить ограничения ресурсов в файле YAML, GKE быстро отменил их.
Нам нужно было найти другое решение.
Нашим первым шагом было понять, почему лимиты ресурсов были установлены на эти значения. Модуль состоял из двух контейнеров: metrics-server и addon-resizer. Последний отвечал за корректировку ресурсов при добавлении или удалении узлов из кластера, действуя как ответственный за вертикальное автомасштабирование кластера.
Его определение в командной строке было следующим:
command:
- /pod_nanny
- --config-dir=/etc/config
- --cpu=40m
- --extra-cpu=0.5m
- --memory=35Mi
- --extra-memory=4Mi
...
В этом определении ЦП и память представляют собой базовые ресурсы, а дополнительный ЦП и дополнительная память представляют дополнительные ресурсы для каждого узла. Расчеты для 180 узлов будут следующими:
0.5m * 180 + 40m=~130m
Та же логика применяется к ресурсам памяти.
К сожалению, единственным способом увеличения ресурсов было добавление дополнительных узлов, чего мы делать не хотели. Поэтому мы решили изучить другие варианты.
Несмотря на то, что мы не смогли решить проблему полностью, мы хотели как можно быстрее стабилизировать развертывание. Мы узнали, что некоторые свойства в определении YAML могут быть изменены без отката GKE. Чтобы решить эту проблему, мы увеличили количество реплик с 1 до 5, добавили проверку работоспособности и скорректировали стратегию развертывания в соответствии с эту статью.
Эти действия помогли снизить нагрузку на экземпляр сервера метрик и гарантировали, что у нас всегда будет хотя бы один работающий модуль, который может предоставлять метрики. Нам потребовалось некоторое время, чтобы пересмотреть проблему и освежить наши мысли. Решение оказалось простым и очевидным в ретроспективе.
Мы углубились во внутренности addon-resizer и обнаружили, что его можно настроить через файл конфигурации и параметры командной строки. На первый взгляд казалось, что параметры командной строки должны переопределять значения конфига, но это не так.
В ходе расследования мы обнаружили, что файл конфигурации был подключен к модулю через параметры командной строки контейнера addon-resizer:
--config-dir=/etc/config
Файл конфигурации был сопоставлен как ConfigMap с именем metrics-server-config в системном пространстве имен, и GKE не выполняет откат этой конфигурации!
Мы добавили ресурсы через этот конфиг следующим образом:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
baseCPU: 100m
cpuPerNode: 5m
baseMemory: 100Mi
memoryPerNode: 5Mi
kind: ConfigMap
metadata:
И это сработало! Это была наша победа.
Мы оставили два модуля с проверками работоспособности и стратегией нулевого простоя на время изменения размера кластера и больше не получали оповещений после внесения этих изменений.
Выводы
- У вас могут возникнуть проблемы с модулем сервера метрик, если у вас плотно упакованный кластер GKE. Ресурсов по умолчанию, выделенных для модуля, может быть недостаточно, если количество модулей на узел близко к предельному (110 на узел).
- GKE защищает свои системные ресурсы, включая системные модули, и прямой контроль над ними невозможен. Однако иногда можно найти обходной путь.
- Важно отметить, что нет гарантии, что решение будет работать после будущих обновлений. Мы столкнулись с этими проблемами только в наших тестовых средах, где у нас есть стратегия перепродажи ресурсов, поэтому, хотя это и разочаровывает, мы все же можем с этим справиться.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27720)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)