

Как оптимизировать Google Cloud BigQuery и контролировать расходы
18 апреля 2023 г.Я неосознанно потратил 3000 долларов США за 6 часов на один запрос в Google Cloud BigQuery. Вот почему и 3 простых шага по оптимизации затрат.
В этой статье
- 🙈 Вы узнаете, что влияет на затраты BigQuery.
- 🏛️ Мы углубимся в архитектуру BigQuery.
- 💰 Вы узнаете, как выполнить 3 простых шага, чтобы сэкономить 99,97 % на следующем счете за Google Cloud.
Поехали.
Как это произошло?
Я разрабатывал скрипт для подготовки образцов данных для клиентов, которые обратились за консультацией. Образцы содержат по 100 строк в каждом файле и разбиты на 55 локалей. Мой запрос выглядит так
SELECT *
FROM `project.dataset.table`
WHERE
ts BETWEEN TIMESTAMP("2022-12-01") AND TIMESTAMP("2023-02-28")
AND locale = "US"
LIMIT 100;
Данные хранились в europe-west-4, а цена за запрос составляет 6 долларов США за ТБ. Итак, запустив скрипт, я обработал:
* Всего 500 ТБ данных
* В среднем 3 ТБ данных на страну
* В среднем 54 доллара США за файл образца данных
Очень дорого.
Сценарий стоимостью 3000 долларов
Скрипт был написан в модулях JavaScript.
// bq-samples.mjs
import { BigQuery } from "@google-cloud/bigquery";
import { Parser } from "@json2csv/plainjs";
import makeDir from "make-dir";
import { write } from "./write.mjs";
import { locales } from "./locales.mjs";
import { perf } from "./performance.mjs";
const q = (locale, start, end, limit) => `SELECT *
FROM `project.dataset.table`
WHERE
ts BETWEEN TIMESTAMP("2022-12-01") AND TIMESTAMP("2023-02-28")
AND locale = "${locale}"
LIMIT ${limit}`
async function main() {
const timer = perf()
const dir = await makeDir('samples')
const bigquery = new BigQuery()
const csvParser = new Parser({})
try {
const jobs = locales.map((locale) => async () => {
// get query result from BigQuery
const [job] = await bigquery.createQueryJob({
query: q(locale, "2022-12-01", "2023-02-28", 100),
})
const [rows] = await job.getQueryResults()
// parse rows into csv format
const csv = parse(csvParser, rows)
// write data into csv files and store in the file system
await write(csv, dir, locale, "2022-12-01", "2023-02-28", 100)
})
await Promise.all(jobs.map((job) => job()))
console.log(`✨ Done in ${timer.stop()} seconds.`)
} catch (error) {
console.error('❌ Failed to create sample file', error)
}
}
await main()
Он создает один пример файла в формате CSV для каждой локали. Процесс прост:
* Запрос к таблице BigQuery с локальной датой, датой начала, датой окончания и ограничением.
* Преобразование результата запроса в формат CSV.
* Запись CSV в файловую систему.
* Повторение процесса для всех языков.
В чем проблема?
Оказывается, я сделал несколько ошибок в своем запросе. Если вы снова посмотрите на модель ценообразования, вы заметите, что стоимость зависит только от того, сколько данных вы обрабатываете. Итак, ясно, что мой запрос просмотрел слишком много данных для получения 100 строк.
С учетом этого давайте поэтапно оптимизируем запрос.
Не выбирать *
Это немного нелогично. Почему мой оператор select имеет какое-то отношение к тому, сколько данных он обрабатывает? Независимо от того, какие столбцы я выберу, я должен читать из одних и тех же ресурсов и данных, верно?
Это справедливо только для строковых баз данных.
На самом деле BigQuery представляет собой столбцовую базу данных. Он ориентирован на столбцы, что означает, что данные структурированы в столбцах. BigQuery использует Dremel в качестве основного вычислительного движка. Когда данные перемещаются из холодного хранилища в активное хранилище в Dremel, оно сохраняет данные в древовидной структуре.
Каждый конечный узел представляет собой ориентированную на столбцы «запись» в формате Protobuf.
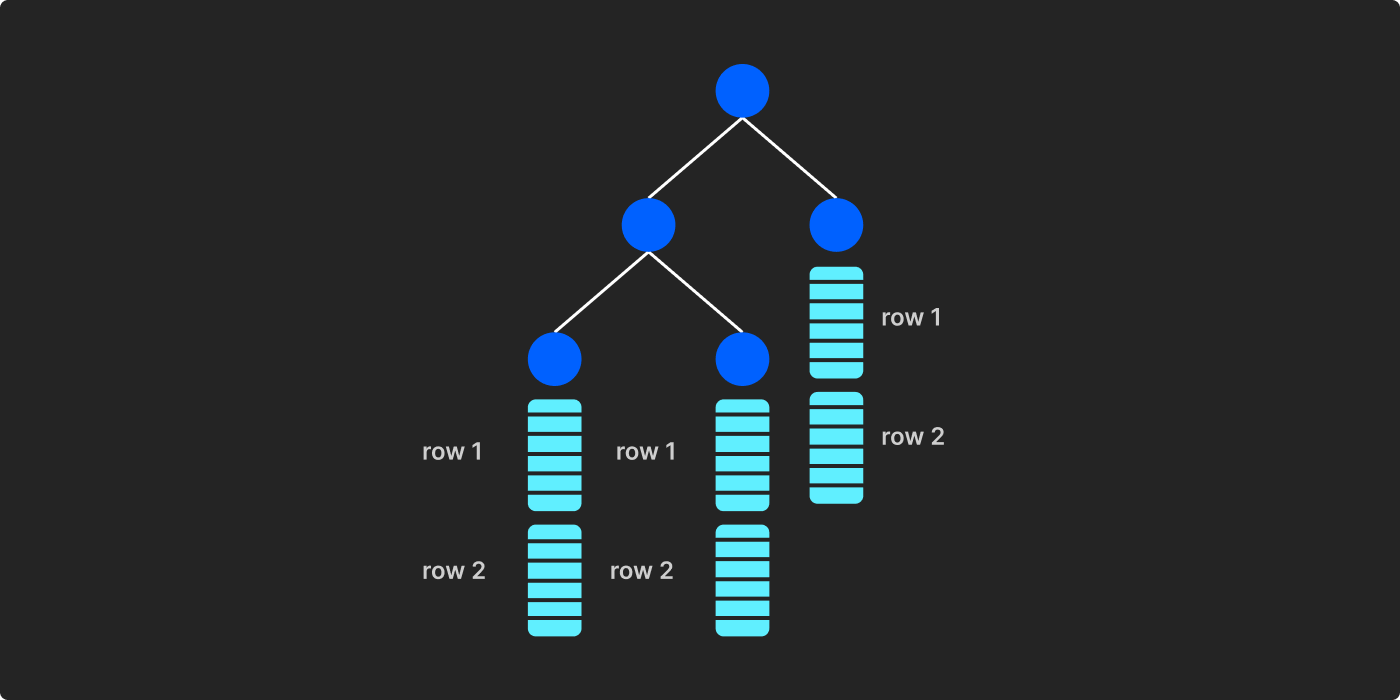
В BigQuery каждый узел — это виртуальная машина. Выполнение запроса распространяется с корневого сервера (узла) через промежуточные серверы на конечные серверы для извлечения выбранных столбцов.
Мы можем изменить запрос, чтобы выбрать отдельные столбцы:
SELECT
session_info_1,
session_info_2,
session_info_3,
user_info_1,
user_info_2,
user_info_3,
query_info_1,
query_info_2,
query_info_3,
impression_info_1,
impression_info_2,
impression_info_3,
ts
FROM `project.dataset.table`
WHERE
ts BETWEEN TIMESTAMP("2022-12-01") AND TIMESTAMP("2023-02-28")
AND locale = "US"
LIMIT 100;
Просто выбрав все столбцы явно, я смог уменьшить обрабатываемые данные с 3,08 ТБ до 2,94 ТБ. Это уменьшение на 100 ГБ.
Использовать секционированную таблицу и запрашивать только подмножества данных
Google Cloud рекомендует разделять таблицы по дате. Это позволяет нам запрашивать только подмножество данных.
Для дальнейшей оптимизации запроса мы можем сузить диапазон дат в операторе where, поскольку таблица разделена по столбцу «ts».
SELECT
session_info_1,
session_info_2,
session_info_3,
user_info_1,
user_info_2,
user_info_3,
query_info_1,
query_info_2,
query_info_3,
impression_info_1,
impression_info_2,
impression_info_3,
ts
FROM `project.dataset.table`
WHERE
ts = TIMESTAMP("2022-12-01")
AND locale = "US"
LIMIT 100;
Я сузил диапазон дат до одного дня вместо трех месяцев. Мне удалось сократить обрабатываемые данные до 37,43 ГБ. Это всего лишь часть исходного запроса.
Поэтапное использование материализованных результатов запроса
Еще один способ сократить расходы — уменьшить набор данных, из которого вы запрашиваете. BigQuery предлагает целевые таблицы для хранения результатов запросов в виде небольших наборов данных. Таблицы назначения бывают двух видов: временные и постоянные.
Поскольку временные таблицы имеют срок жизни и не предназначены для совместного использования и выполнения запросов, я создал постоянную целевую таблицу, чтобы материализовать результат запроса:
// bq-samples.mjs
const dataset = bigquery.dataset('materialized_dataset')
const materialzedTable = dataset.table('materialized_table')
// ...
const [job] = await bigquery.createQueryJob({
query: q(locale, '2022-12-01', '2023-02-28', 100),
destination: materialzedTable,
})
Результаты запроса будут сохранены в целевой таблице. Он послужит ориентиром для будущих запросов. Всякий раз, когда есть возможность сделать запрос из целевой таблицы, BigQuery будет обрабатывать данные из таблицы. Это значительно сократит объем данных, которые мы просматриваем.
Заключительные мысли
Это очень интересное исследование по снижению затрат в BigQuery. Всего три простых шага:
* Не используйте *
* Использовать секционированную таблицу и запрашивать только подмножества данных
* Используйте материализованные результаты запросов поэтапно
Мне удалось уменьшить размер обрабатываемых данных с 3 ТБ до 37,5 ГБ. Это значительно снижает общую стоимость с 3000 до 30 долларов США.
Если вам интересно узнать больше об архитектуре BigQuery, вот ссылки, которые мне помогли:
* Объяснение BigQuery: обзор архитектуры BigQuery< /p>
* Колосс под капотом: взгляд на масштабируемая система хранения
* Развитие Jupiter: размышления о трансформации сети центров обработки данных Google< /а>
Подробнее об оптимизации затрат BigQuery можно прочитать в документации Google Cloud.
<цитата>Особая благодарность Абу Наширу за сотрудничество со мной в изучении примера и предоставление ценной информации, которая помогла я понимаю архитектуру BigQuery.
Ссылки
- Абу Нашир — LinkedIn
- Взгляд на Дремел — Питер Голдсборо< /li>
- BigQuery — Google Cloud
- Объяснение BigQuery: обзор архитектуры BigQuery — Облако Google
- Колосс под капотом: быстрый взгляд в масштабируемую систему хранения Google — Google Cloud
- столбцовая СУБД — Википедия
- Значения, разделенные запятыми — Википедия
- Создание секционированных таблиц — Google Cloud
- модули JavaScript — MDN
- Эволюция Jupiter: анализ сети центров обработки данных Google трансформация — Google Cloud
- Метод: jobs.query — Google Cloud
- Protocol_Buffers — Википедия
- Выполнение интерактивных и пакетных запросов – Google Cloud
- Использование кешированных результатов запросов — Google Cloud
- Запись результатов запроса — Google Cloud
Хотите подключиться?
Эта статья изначально была опубликована на веб-сайте Daw-Chih.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27156)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)