Я помню свой первый день в качестве младшего разработчика. Это все еще свежо в моей памяти, как будто это было вчера. Я ужасно нервничала и не понимала, что делаю. Должно быть, мое беспокойство было очевидным, потому что добрая душа решила взять меня под свое крыло. В тот день я научился писать SQL в моем коде PHP, чтобы делать интересные вещи с базой данных.
Однако, прежде чем я смог начать, мне пришлось попросить администратора базы данных (DBA) создать несколько таблиц. Я быстро понял, что к администратору баз данных нужно обращаться, если вы хотите что-то сделать. Нужна новая колонка? Позвоните администратору базы данных. Хранимая процедура должна быть отредактирована? Это была работа для DBA. Я посмотрел на него. Он был такой суперзвездой, что позже в своей карьере я сам какое-то время работал администратором баз данных.
Конечно, теперь я понимаю, что зависимость от кого-то во всем неизбежно приводит к узким местам. Это безрассудно, напряжно и, что хуже всего, это пустая трата талантов администратора баз данных.
Управление данными с помощью CI/CD
Автоматизация управления данными с помощью CI/CD позволяет нам оставаться гибкими, обновляя схему базы данных в процессе доставки или развертывания. Мы можем инициализировать тестовые базы данных в различных условиях и переносить схему по мере необходимости, гарантируя, что тестирование будет выполнено на правильной версии базы данных. Мы можем одновременно обновлять и понижать версию при развертывании наших приложений. Автоматизированное управление данными позволяет нам отслеживать каждое изменение в базе данных, что помогает отлаживать производственные проблемы.
Использование CI/CD для управления данными — единственный способ правильно выполнить непрерывное развертывание.
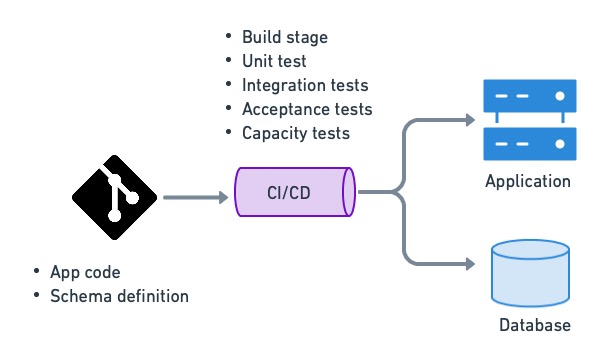
Роль администратора баз данных
Какова роль администратора баз данных при автоматизированном управлении данными? Они неактуальны? Наоборот, освободившись от рутинной работы, они теперь могут сосредоточиться на гораздо более увлекательной работе, добавляющей ценности, например:
* Мониторинг и оптимизация производительности ядра базы данных. * Консультации по разработке схемы. * Планирование нормализации данных. * Экспертная проверка изменений базы данных и сценариев миграции с учетом их влияния на операции базы данных. * Выбор лучшего момента для применения миграций. * Обеспечение работы стратегии восстановления в соответствии с требованиями SLA. * Написание или улучшение сценариев миграции.
Методы управления данными с помощью CI/CD
Что усложняет управление базой данных, так это то, что мы должны сохранять данные при внесении изменений в схему. Мы не можем заменять базу данных с каждым выпуском, как это делаем с приложением.
Эта проблема становится еще более сложной, если учесть, что база данных должна оставаться в сети во время миграции, и ничего не может быть потеряно в случае отката.
Итак, давайте рассмотрим несколько методов, которые помогут нам сделать миграцию безопасной.
Передача скриптов базы данных в систему управления версиями
Как правило, существует два вида сценариев базы данных: язык определения данных (DDL) и язык управления данными (DML). DDL создает и изменяет структуры базы данных, такие как таблицы, индексы, триггеры, хранимые процедуры, разрешения или представления. DML используется для управления фактическими данными в таблицах.
Как и весь код, оба вида сценариев должны храниться в системе контроля версий. Сохранение изменений в системе контроля версий позволяет восстановить всю историю схемы базы данных. Это делает изменения видимыми для команды, поэтому они могут быть проверены коллегами. Сценарии базы данных включают:
* Сценарии для прокрутки версии базы данных вперед и назад между разными версиями. * Скрипты для создания пользовательских наборов данных для приемки и тестирования емкости. * Определения схемы базы данных, используемые для инициализации новой базы данных. * Любые другие скрипты, изменяющие или обновляющие данные.
Использовать инструменты переноса базы данных
Существует множество инструментов для написания и поддержки сценариев переноса. Некоторые фреймворки, такие как Rails, Laravel и Django, уже встроены в них. Но если это не так для вашего стека, есть общие инструменты, такие как Flyway, DBDeploy и SQLCompare для выполнения этой задачи.
Целью всех этих инструментов является поддержка непрерывного набора дельта-скриптов, которые обновляют и понижают схему базы данных по мере необходимости. Эти инструменты могут определить, какие обновления необходимы, изучив существующую схему и запустив сценарии обновления в правильной последовательности. Это гораздо более безопасная альтернатива написанию скриптов вручную.
Например, чтобы перейти с версии 66 на версию 70, инструмент миграции должен выполнить сценарии с номерами 66, 67, 68, 69 и 70. То же самое можно сделать и наоборот, чтобы откатить базу данных назад.
| Версия | Скрипт обновления | Скрипт отката | DDL-схема | |----|----|----|----| | ... | | | | | 66 | дельта-66.sql | отменить-66.sql | схема-66.sql | | 67 | дельта-67.sql | отменить-67.sql | схема-67.sql | | 68 | дельта-68.sql | отменить-68.sql | схема-68.sql | | 69 | дельта-69.sql | отменить-69.sql | схема-69.sql | | 70 | дельта-70.sql | отменить-70.sql | схема-70.sql | | ... | | | |
Автоматическая миграция покрывает 99 % ваших потребностей в управлении данными. Существуют ли случаи, когда управление должно осуществляться вне CI/CD? Да, но обычно это разовые или ситуативные изменения, когда огромные объемы данных должны быть перемещены в рамках масштабной инженерной работы. Отличным примером этого является миграция миллионов записей Stripe.
Сохраняйте небольшие изменения
В разработке программного обеспечения мы идем быстрее, когда можем идти безопасными маленькими шагами. Это политика, которая также применяется к управлению данными. Одновременные масштабные изменения могут привести к неожиданным результатам, таким как потеря данных или блокировка таблицы. Лучше всего разбивать изменения на части и применять их с течением времени.
Отделите развертывание от миграции данных
Развертывание приложений и перенос данных имеют очень разные характеристики. В то время как развертывание обычно занимает несколько секунд и может выполняться несколько раз в день, миграция базы данных происходит реже и выполняется в нерабочее время.
Мы должны отделить миграцию данных от развертывания приложений, поскольку они требуют разных подходов. Разделение делает обе задачи проще и безопаснее.
Разделение развертывания приложений и миграции БД. Каждый выпуск имеет ряд совместимых версий БД.
Разделение может работать только в том случае, если у приложения есть некоторая свобода действий в отношении совместимости с базой данных, т. е. дизайн приложения должен стремиться сделать его максимально совместимым с предыдущими версиями.
Настройка конвейеров непрерывного развертывания и миграции
Отключение миграции от развертывания позволяет нам разделить конвейеры непрерывной доставки на две части: одну для миграции базы данных и один для развертывания приложения. Это дает нам преимущество непрерывного развертывания приложения при одновременном контроле выполнения миграции. В Semaphore мы можем использовать рабочие процессы на основе изменений для автоматического запуска соответствующего конвейера.
Непрерывное развертывание баз данных с использованием стратегии разделения.
Сделайте миграции аддитивными
Аддитивные изменения в базе данных создают новые таблицы, столбцы или хранимые процедуры, а не переименовывают, перезаписывают или удаляют их. Такие изменения более безопасны, поскольку их можно отменить с гарантией того, что данные не будут потеряны.
Например, допустим, у нас есть следующая таблица в нашей производственной базе данных.
CREATE TABLE pokedex (
id BIGINT GENERATED BY DEFAULT AS IDENTITY (START WITH 1) PRIMARY KEY,
name VARCHAR(255)
category VARCHAR(255)
);
Добавление нового столбца будет дополнительным изменением:
ALTER TABLE pokedex ADD COLUMN height float;
Откат изменения — это просто удаление нового столбца:
ALTER TABLE pokedex DROP COLUMN height;
Однако мы не всегда можем вносить дополнительные изменения. Когда нам нужно изменить или удалить данные, мы можем сохранить целостность данных, временно сохранив исходные данные. Например, изменение типа столбца может привести к усечению исходных данных. Мы можем сделать изменение более безопасным, сохранив старые данные во временном столбце.
ALTER TABLE pokedex RENAME COLUMN description to description_legacy;
ALTER TABLE pokedex ADD COLUMN description JSON;
UPDATE pokedex SET description = CAST(description_legacy AS JSON);
Приняв эту меру предосторожности, мы можем без риска выполнить откат:
ALTER TABLE pokedex DROP COLUMN description;
ALTER TABLE pokedex RENAME COLUMN description_legacy to description;
Откат с CI/CD
Будь то понижение версии приложения или неудачная миграция, в некоторых ситуациях нам приходится отменять изменения базы данных, эффективно откатывая ее к предыдущей версии схемы. Это не большая проблема, если у нас есть сценарий отката и сохранены неразрушающие изменения.
Как и в случае любой другой миграции, откат также должен быть запрограммирован и автоматизирован (я видел много случаев, когда откат вручную только усугублял ситуацию). В Semaphore этого можно добиться с помощью конвейера отката и условий продвижения.
Не делайте полную резервную копию, если это не быстро
Несмотря на все меры предосторожности, все может пойти не так, а неудачное обновление может привести к повреждению базы данных. Всегда должен быть какой-то резервный механизм для восстановления базы данных до рабочего состояния.
Вопрос: должны ли мы делать резервную копию перед каждой миграцией? Ответ зависит от размера базы данных. Если резервное копирование базы данных занимает несколько секунд, мы можем это сделать. Однако большинство баз данных слишком велики, и их резервное копирование занимает слишком много времени, чтобы их можно было использовать. Затем мы должны полагаться на любую доступную стратегию восстановления, такую как ежедневные или еженедельные полные дампы в сочетании с восстановлением транзакции на момент времени.
Кроме того, мы должны периодически тестировать нашу стратегию восстановления. Легко убедиться, что у нас есть действительные резервные копии, но мы не можем быть уверены, пока не попробуем их. Не ждите катастрофы, чтобы попытаться восстановить базу данных — разработайте план аварийного восстановления и время от времени проверяйте его.
Рассмотрите сине-зеленые развертывания
⚠️ Сине-зеленое развертывание — это более сложный метод, который требует хорошего знания того, как работают ядра баз данных. Поэтому я рекомендую использовать его с осторожностью и после того, как вы будете уверены в управлении данными в процессе CI/CD.
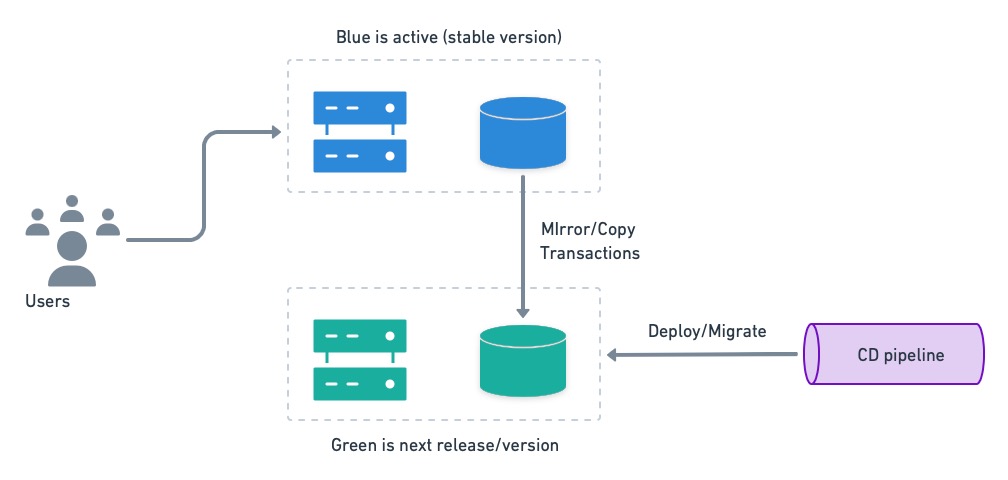
Синие-зеленые развертывания — это стратегия, которая позволяет нам мгновенно переключаться между версиями. Суть сине-зеленого развертывания состоит в том, чтобы иметь две отдельные среды, называемые синей и зеленой. Один активен (есть пользователи), а другой обновлен. Пользователи переключаются туда и обратно по мере необходимости.
Мы можем эффективно использовать функцию мгновенного отката сине-зеленого, если у нас есть отдельные базы данных. Перед развертыванием неактивная система (зеленая на рисунке ниже) получает текущее восстановление базы данных от синего и синхронизируется с механизмом зеркального отображения. Затем он переносится на следующую версию.
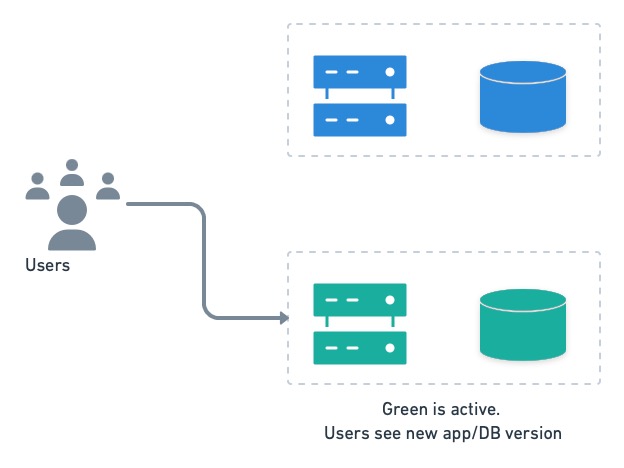
После обновления и тестирования неактивной системы пользователи переключаются.
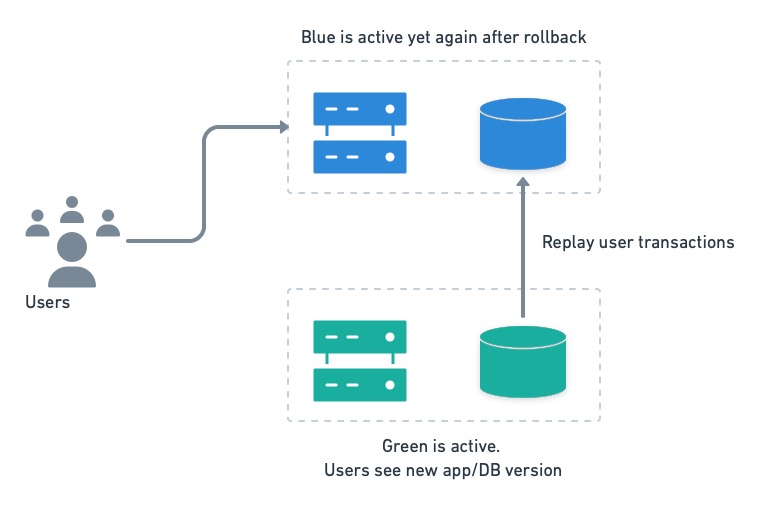
В случае возникновения проблем пользователи могут мгновенно вернуться к старой версии. Единственная проблема с этой настройкой заключается в том, что транзакции, выполненные пользователями на зеленой стороне, должны быть воспроизведены на синей после отката.
Методы тестирования
Поскольку перенос может привести к уничтожению данных или сбоям в работе, мы хотим быть особенно осторожными и тщательно протестировать его перед запуском в рабочую среду. К счастью, есть несколько методов тестирования, которые могут нам помочь.
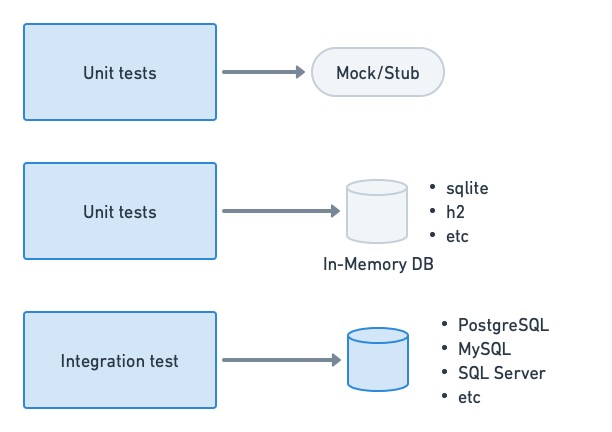
Модульные и интеграционные тесты
Модульные тесты, как правило, не должны зависеть от базы данных или обращаться к ней, если это возможно. Целью модульного теста является проверка поведения функции или метода. Обычно мы можем обойтись без заглушек или моков для этого. Когда это невозможно или слишком неудобно, мы можем использовать для работы базы данных в памяти.
С другой стороны, реальные базы данных обычно можно увидеть при интеграционном тестировании. Их можно запустить по требованию для теста, загрузить с пустыми таблицами или специально созданным набором данных и закрыть после тестирования.
Приемочные и сквозные тесты
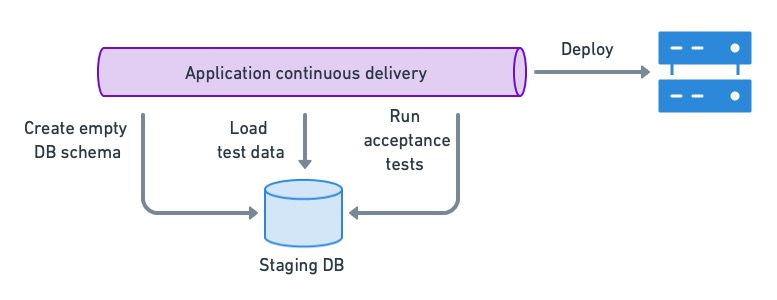
Нам нужна среда, максимально приближенная к производственной, для приемочного тестирования. Хотя заманчиво использовать анонимные рабочие резервные копии в тестовой базе данных, они, как правило, слишком велики и громоздки, чтобы быть полезными. Вместо этого мы можем использовать созданные наборы данных или, что еще лучше, создать пустую схему и использовать внутренний API приложения для ее заполнения тестовыми данными.
Тесты совместимости и миграции
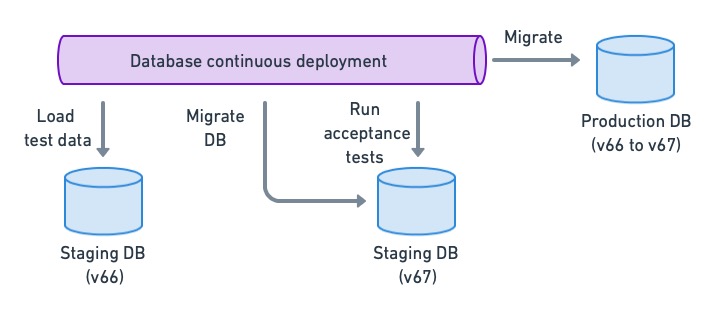
Мы должны выполнить регрессионное тестирование, если хотим, чтобы приложение было совместимо как с предыдущими, так и с предыдущими версиями базы данных. Это можно сделать, запустив приемочные тесты схемы базы данных до и после переноса.
При несвязанной настройке, подобной описанной ранее, конвейер непрерывного развертывания приложения будет выполнять приемочное тестирование для текущей версии схемы. Таким образом, нам нужно только провести приемочное тестирование следующей версии базы данных, когда произойдет миграция:
- Загрузить тестовую базу данных с текущей рабочей схемой.
- Запустите миграцию.
- Выполните приемочные тесты.
Дополнительным преимуществом этого метода является обнаружение проблем в самом скрипте переноса, так как многие вещи могут пойти не так, например новые ограничения не работают из-за существующих данных, конфликтов имен или слишком долгой блокировки таблиц.
Заключительные мысли
К сценариям базы данных следует относиться так же, как и к остальному коду — применяются те же принципы. Убедитесь, что у ваших администраторов баз данных есть доступ к репозиторию кода, чтобы они могли помочь в настройке, пересмотре и расширении. рецензировать скрипты управления данными. Эти скрипты должны иметь версии и подвергаться такому же уровню проверки, что и код.
Усилия, затраченные на настройку автоматизированного управления данными с помощью CI/CD, многократно окупятся скоростью, стабильностью и продуктивностью. Разработчики могут работать без обременений, в то время как администраторы баз данных занимаются тем, что у них получается лучше всего: поддерживают чистоту и смазку базы данных.
Спасибо за прочтение!
Также опубликовано здесь