Я всегда хотел научиться программно отделять вокал от трека и не полагаться на программное обеспечение как услугу, выполняющее эту задачу за меня. В этой статье показано, как отделить вокал песни от инструментов с помощью моей новой любимой библиотеки Librosa. Вы можете ознакомиться с блокнотом Google Colab здесь.
Идея возникла, когда я хотел разделить отдельные треки песни, которая мне очень нравилась, поэтому я отправился на Product Hunt и обнаружил melody ml. Это открытие вызвало желание изучать машинное обучение для музыки и, в конечном итоге, открытие библиотеки Python, librosa.
Кстати, у меня закончилась RAM, из-за чего мой ноутбук взорвался.
https://twitter.com/tonypoppinss/status/1620369862630739968?embedable=true

Установить и импортировать зависимости
pip install librosa matplotlib IPython
import librosa
from librosa import display
import numpy as np
import IPython.display as ipd
import matplotlib as plt
Загрузить и отобразить песню.
Я использовал My Last Serenade от KSE, так как мне было интересно, как рычание или выходили кричащие части песни.
y, sr = librosa.load('My Last Serenade.wav')
ipd.Audio(data=y[90*sr:110*sr], rate=sr)
Мы нарезаем 20-секундный фрагмент в припеве песни. Мы показываем звук, используя ipd.Audio(tbh, это немного утомительно). Фотография показана ниже, потому что я не смог найти способ загрузить аудио сюда, на DEV.

Мы разделяем комплексную спектрограмму D на компоненты амплитуды (S) и фазы (P), преобразовываем метки времени в кадры, наносим данные на график, а затем отображаем полную спектрограмму данных.
S_full, phase = librosa.magphase(librosa.stft(y))
idx = slice(*librosa.time_to_frames([90*110], sr=sr))
fig, ax = plt.pyplot.subplots()
img = display.specshow(librosa.amplitude_to_db(S_full[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax)
fig.colorbar(img, ax=ax)
Построчное объяснение
S_full, Phase = librosa.magphase(librosa.stft(y)) — мы разделяем амплитуду и фазу трека, используя кратковременное преобразование Фурье, представляя сигнал в частотно-временной области путем вычисления дискретных преобразований Фурье (ДПФ)(y)
idx = slice(*librosa.time_to_frames([90*110], sr=sr)) — нарезать часть песни, а затем преобразовать ее в stft-кадры с помощью time_to_frames функция librosa.
img = display.specshow(librosa.amplitude_to_db(S_full[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax) - отобразить спектрограмму 20-секундной части песни путем преобразования амплитудной спектрограммы в спектрограмму амплитуды в масштабе дБ, затем сравнить амплитуду и фазу трека и вернуть новый массив, содержащий поэлементные максимумы и, наконец, он отображает оси y и x.
Ниже представлено изображение спектра:
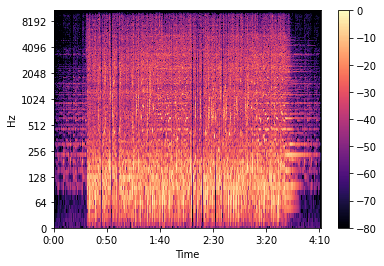
Разложение спектрограммы
S_filter = librosa.decompose.nn_filter(S_full, aggregate=np.median, metric='cosine', width=int(librosa.time_to_frames(2, sr=sr)))
S_filter = np.minimum(S_full, S_filter)
Построчное объяснение
S_filter = librosa.decompose.nn_filter(S_full,aggregate=np.median, metric='cosine', width=int(librosa.time_to_frames(2, sr=sr))) - мы отфильтровать вокал по его ближайшим соседям, агрегировать их медианные значения, сравнить их кадры, используя косинусное сходство, и содержать эти кадры, которые должны быть разделены на 2 секунды, и подавить другие звуки из спектра
S_filter = np.minimum(S_full, S_filter) — получаем рассчитанные данные в память переменных S_full и S_filter для получить минимальное значение.
Отображение спектра фона и переднего плана аудио
margin_i, margin_v = 3, 11
power = 3
mask_i = librosa.util.softmask(S_filter, margin_i * (S_full - S_filter), power=power)
mask_v = librosa.util.softmask(S_full - S_filter, margin_v * S_filter, power=power)
S_foreground = mask_v * S_full
S_background = mask_i * S_full
Построчное объяснение
margin_i, margin_v = 3, 11 — мы используем поля, чтобы уменьшить потери звука в вокале и инструментальных масках
power = 3 — возвращает мягкую маску, вычисленную численно стабильным способом
S_foreground = mask_v * S_full и S_background = mask_i * S_full — умножьте маски на входной спектр, чтобы разделить компоненты
Построение полного спектра, фона и спектра переднего плана
fig, ax = plt.pyplot.subplots(nrows=3, sharex=True, sharey=True)
img = display.specshow(librosa.amplitude_to_db(S_full[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax[0])
ax[0].set(title='Full Spectrum')
ax[0].label_outer()
display.specshow(librosa.amplitude_to_db(S_background[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax[1])
ax[1].set(title='Background Spectrum')
ax[1].label_outer()
display.specshow(librosa.amplitude_to_db(S_foreground[:, idx], ref=np.max), y_axis='log', x_axis='time', sr=sr, ax=ax[2])
ax[2].set(title='Foreground Spectrum')
ax[2].label_outer()
fig.colorbar(img, ax=ax)
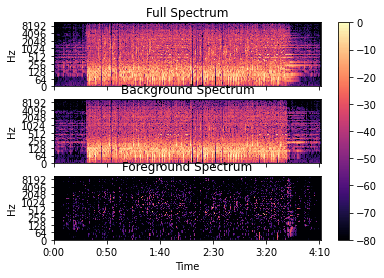
Восстановить звук переднего плана из замаскированной спектрограммы и воспроизвести звук
y_foreground = librosa.istft(S_foreground * phase)
ipd.Audio(data=y_foreground[90*sr:110*sr], rate=sr)
Построчное объяснение
y_foreground = librosa.istft(S_foreground * фаза) — инвертирует кратковременное преобразование Фурье ipd.Audio(data=y_foreground[90*sr:110*sr], rate= sr) - воспроизводит вокал из трека

Заключение
На первый взгляд это казалось простым, и когда я читал документацию, но копаясь в коде, я понял, что эта идея была немного сложнее. Но что заставило меня продолжить, так это то, что я прочитал о ближайших соседях в одной части документации, которая заставила меня понять, что в будущем я буду пачкать руки машинным обучением с этой библиотекой

Также опубликовано здесь.