

Как повысить скорость запросов, чтобы максимально использовать ваши данные
23 февраля 2023 г.Мир получает все больше и больше пользы от данных, о чем свидетельствует широко обсуждаемый в настоящее время ChatGPT, который, как мне кажется, представляет собой робота-аналитика данных. Однако в современную эпоху более важными, чем сами данные, является возможность быстро найти нужную информацию среди всех избыточных данных. Поэтому в этой статье я расскажу о том, как я повысил общую эффективность обработки данных за счет оптимизации выбора и использования хранилищ данных.
Слишком много данных на моем планшете
До 2021 года выбор хранилищ данных никогда не вызывал у меня беспокойства. Я работаю инженером по обработке данных в финтех-провайдере SaaS с момента его регистрации в 2014 году. Когда компания только зарождалась, у нас не было слишком много данных. жонглировать. Нам нужен был только простой инструмент для OLTP и бизнес-отчетности, а традиционные базы данных справились бы с задачей.
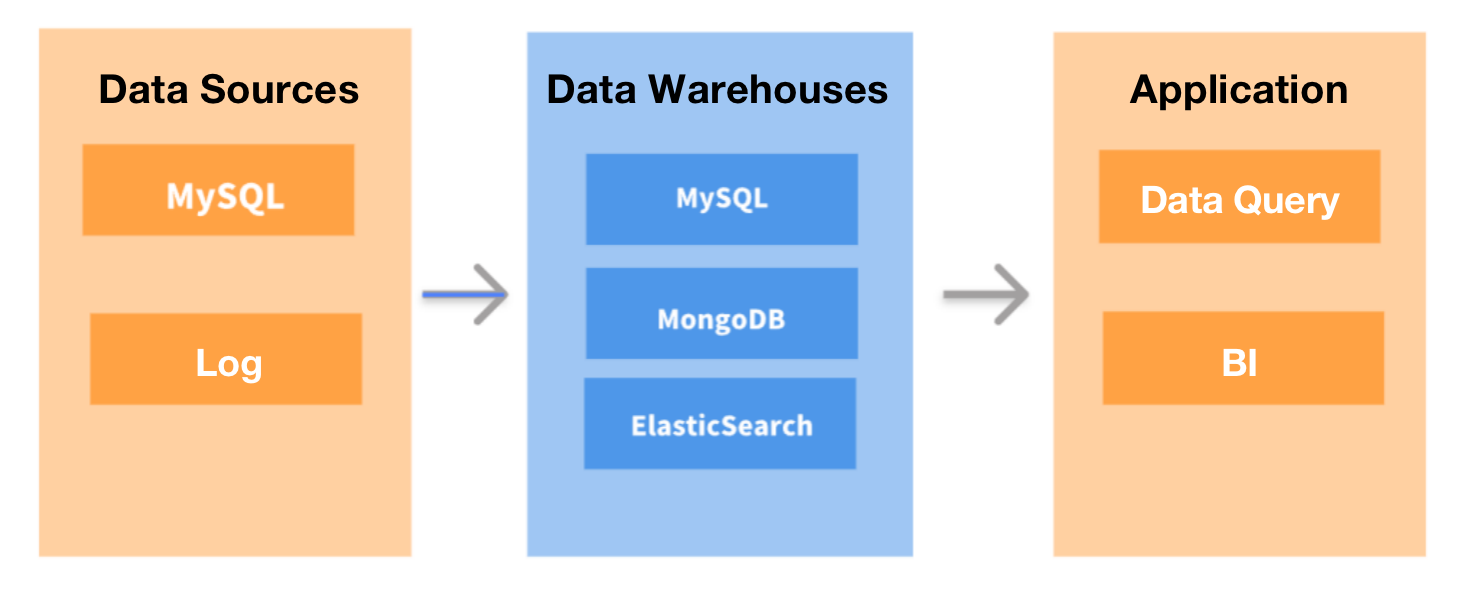
Но по мере роста компании данные, которые мы получали, становились чрезвычайно большими по объему и все более диверсифицированными по источникам. Каждый день у нас было множество учетных записей пользователей, которые входили в систему и отправляли множество запросов. Это было похоже на сбор воды из тысячи кранов, чтобы потушить миллион разбросанных по зданию очагов огня, за исключением того, что вы должны принести точное количество воды, необходимое для каждого очага возгорания. Кроме того, мы получаем все больше и больше писем от наших коллег с вопросами, можем ли мы упростить для них анализ данных. Именно тогда компания собрала команду по работе с большими данными, чтобы справиться с чудовищем.
Первое, что мы сделали, — революционизировали нашу архитектуру обработки данных. Мы использовали DataHub для сбора всех наших транзакционных или журнальных данных и загрузки их в автономное хранилище данных для обработки данных (анализа, вычислений и т. д.). Затем результаты будут экспортированы в MySQL, а затем перенаправлены в QuickBI для визуального отображения отчетов. Мы также заменили MongoDB хранилищем данных в реальном времени для бизнес-запросов.
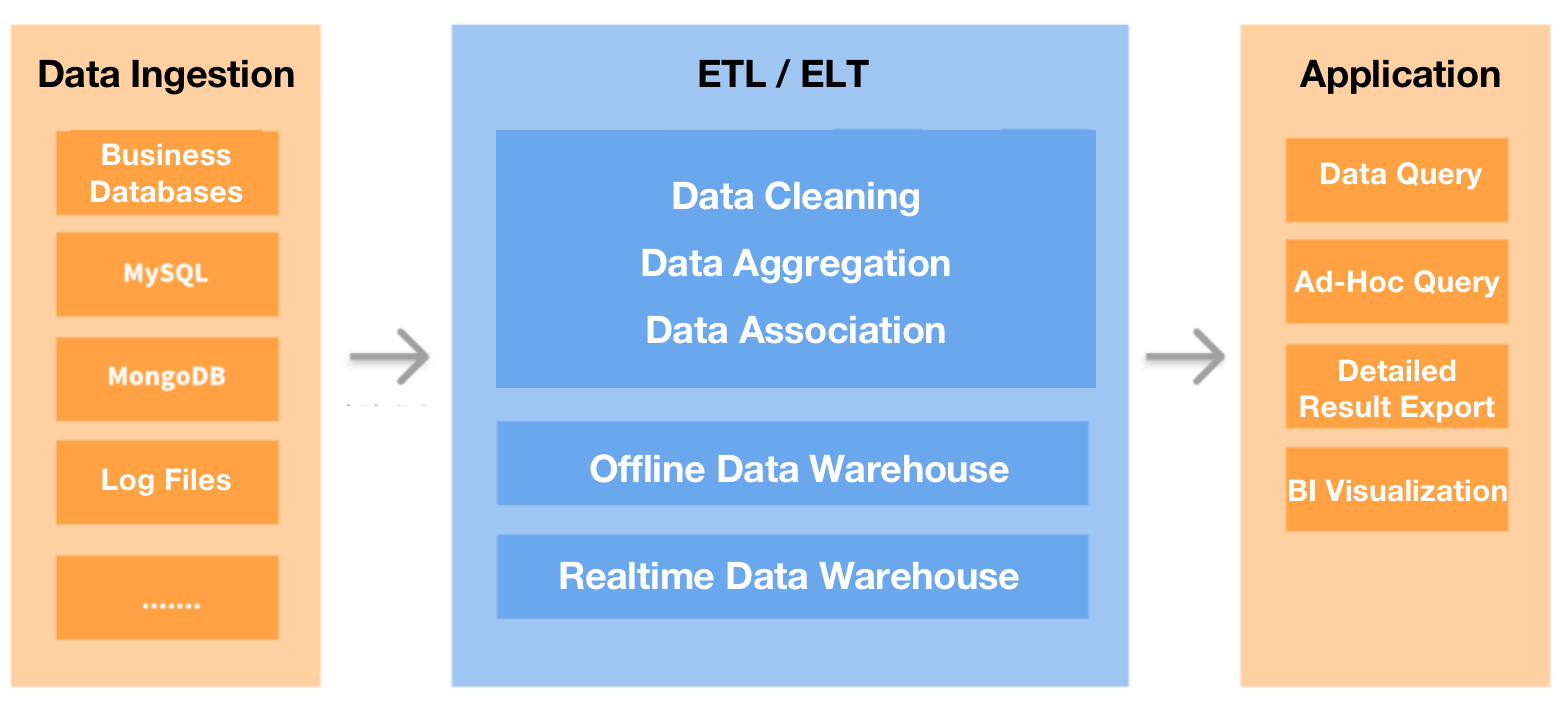
Эта новая архитектура работала, но в наших ботинках оставалось несколько камушков:
* Нам нужны более быстрые ответы. MySQL может медленно агрегировать большие таблицы, но разработчики нашего продукта запросили время ответа на запрос менее пяти секунд. Итак, сначала мы попытались оптимизировать MySQL. Затем мы также попытались пропустить MySQL и напрямую подключить автономное хранилище данных к QuickBI, надеясь, что сочетание возможностей ускорения запросов первого и кэширования второго сделает волшебство. Тем не менее, эта пятисекундная цель казалась недостижимой. Было время, когда я считал, что единственное идеальное решение — это нанимать людей с большим терпением.
* Мы хотели упростить обслуживание таблиц измерений. Автономное хранилище данных выполняло синхронизацию данных каждые пять минут, что делало его неприменимым для частых сценариев обновления или удаления данных. Если бы нам нужно было поддерживать в нем таблицы измерений, нам пришлось бы регулярно фильтровать и дедуплицировать данные, чтобы обеспечить согласованность данных. Из-за инстинкта неприятия неприятностей мы решили этого не делать.
* Нам нужна поддержка точечных запросов с высокой степенью параллелизма. Базе данных реального времени, которую мы использовали ранее, требовалось до 500 мс для ответа на точечные запросы с высокой степенью параллельности как в столбцовом, так и в строковом хранилище даже после оптимизации. Этого было недостаточно.
Бей по самому больному месту
В марте 2022 г. мы начали искать лучшее хранилище данных. К нашему разочарованию, универсального решения не было. Большинство рассмотренных нами инструментов хорошо справлялись только с одной или несколькими задачами, но если бы мы выбрали лучших исполнителей для каждого сценария использования, то получили бы громоздкий и беспорядочный набор инструментов, что противоречило инстинкту.
Поэтому мы решили сначала решить нашу самую большую головную боль: медленный отклик, так как это вредило как опыту наших пользователей, так и нашей внутренней эффективности работы.
Для начала мы попытались перенести самые большие таблицы из MySQL в Apache Doris, аналитическую базу данных реального времени, поддерживающую протокол MySQL. Это сократило время выполнения запроса в восемь раз. Затем мы попытались использовать Дорис для размещения дополнительных данных.
На данный момент мы используем два кластера Doris: один для обработки точечных запросов (высокий QPS) от наших пользователей, а другой — для внутренних специальных запросов и отчетов. В результате пользователи сообщают о более плавной работе, и мы можем предоставить больше функций, которые раньше были узким местом из-за медленного выполнения запросов. Перенос наших таблиц измерений в Doris также привел к уменьшению количества ошибок данных и повышению эффективности разработки.
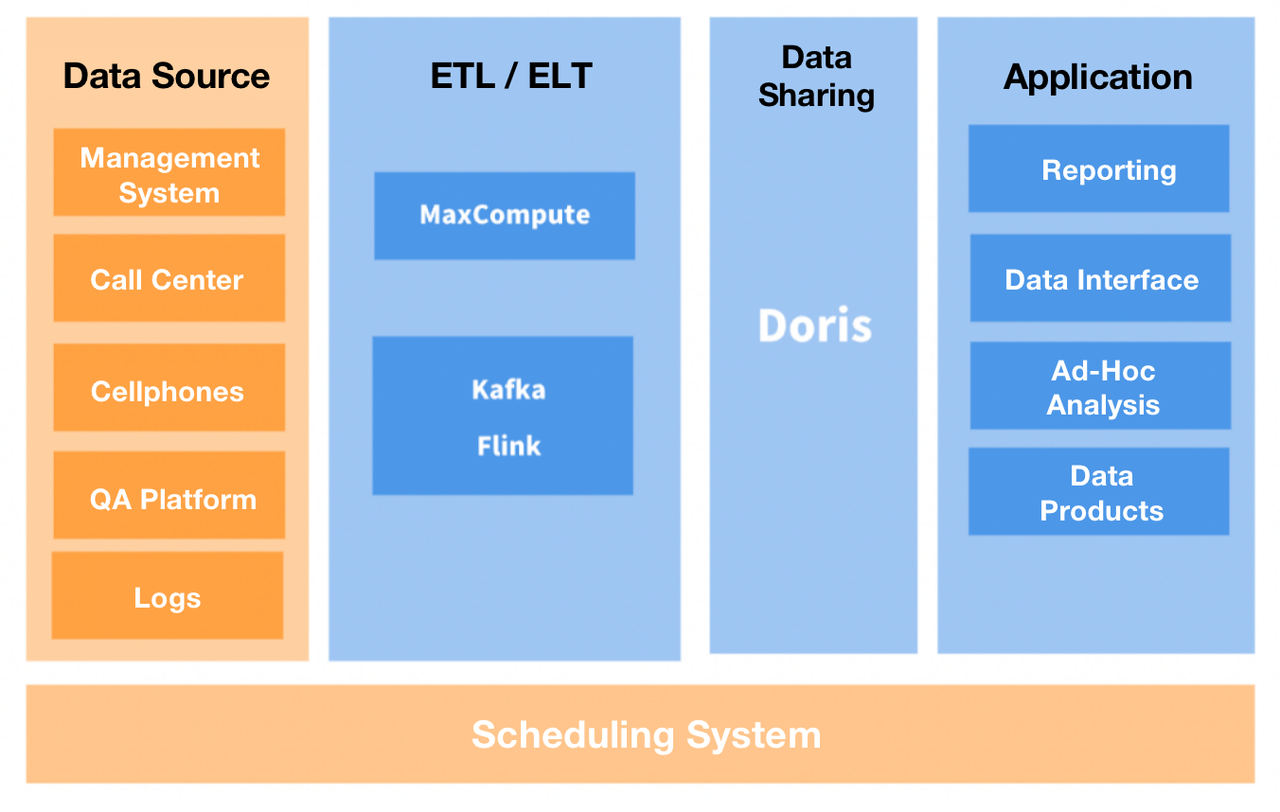
Процессы FE и BE Doris можно масштабировать, поэтому десятки ПБ данных, хранящихся на сотнях устройств, можно поместить в один кластер. Кроме того, два типа процессов реализуют протокол согласованности для обеспечения доступности службы и надежности данных. Это устраняет зависимость от Hadoop и, таким образом, снижает затраты на развертывание кластеров Hadoop.
Советы
Вот несколько наших практик, которыми мы можем поделиться с вами:
Модель данных:
Из трех моделей данных Doris нам больше всего подходят Уникальная модель и Агрегированная модель. Например, мы используем уникальную модель для обеспечения согласованности данных при приеме таблиц измерений и исходных таблиц, а агрегированную модель — для импорта данных отчета.
Прием данных:
Для приема данных в режиме реального времени мы используем Flink-Doris-Connector: после того, как наши бизнес-данные, бинарные журналы на основе MySQL, будут записаны в Kafka, они будут проанализированы Flink, а затем загружены в Doris в режиме реального времени. способ времени.
Для приема данных в автономном режиме мы используем DataX: в основном это касается вычисляемых данных отчета в нашем автономном хранилище данных.
Управление данными:
Мы делаем резервную копию данных нашего кластера в удаленной системе хранения через Broker. Затем он может восстановить данные из резервных копий в любой кластер Doris, если это необходимо, с помощью команды восстановления.
Мониторинг и оповещения:
В дополнение к различным показателям мониторинга Doris мы развернули подключаемый модуль журнала аудита, чтобы более внимательно следить за определенным медленным SQL определенных пользователей для оптимизации.
Медленные запросы SQL:
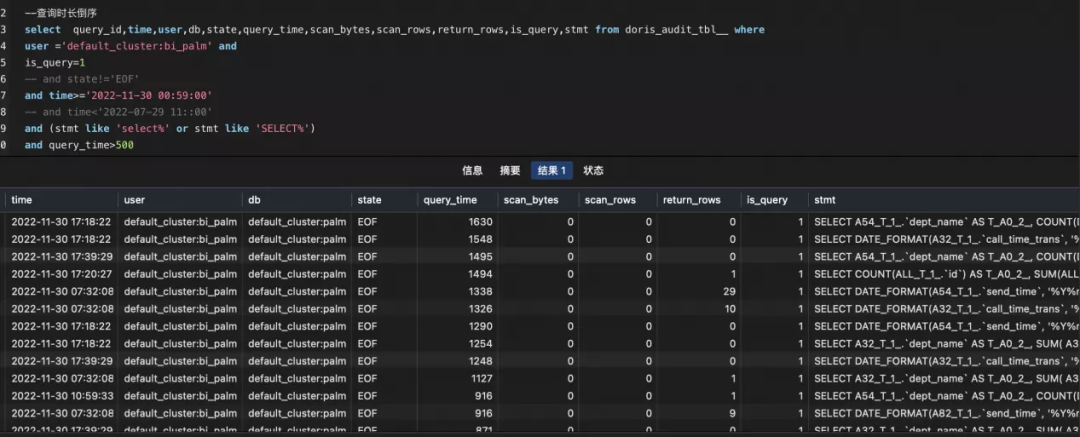
Некоторые из наших часто используемых показателей мониторинга:
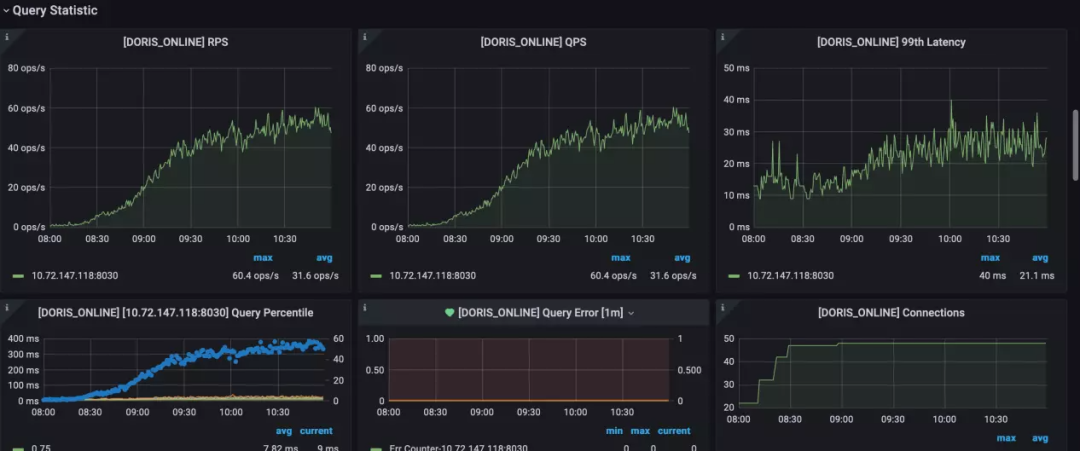
Компромисс между использованием ресурсов и доступностью в реальном времени:
Оказалось, что использование Flink-Doris-Connector для приема данных может привести к высокому использованию ресурсов кластера, поэтому мы увеличили интервал между каждой записью данных с 3 до 10 или 20 секунд, что немного снизило доступность в режиме реального времени. данных в обмен на гораздо меньшее использование ресурсов.
Общение с разработчиками
Мы были в тесном контакте с сообществом Doris, занимающимся открытым исходным кодом, на всем протяжении от нашего расследования до принятия хранилища данных, и мы предоставили разработчикам несколько предложений:
* Включите Flink-Doris-Connector для поддержки одновременной записи нескольких таблиц в один приемник. * Включите материализованные представления для поддержки объединения нескольких таблиц. * Оптимизируйте базовое сжатие данных и максимально сократите использование ресурсов. * Предоставлять предложения по оптимизации для медленного SQL и предупреждения для ненормального поведения при создании таблиц.
Если идеального хранилища данных не найти, я думаю, что предоставление отзыва о втором лучшем способе помочь создать его. Мы также изучаем его коммерческую версию под названием SelectDB, чтобы посмотреть, смогут ли дополнительные настраиваемые расширенные функции смазать колеса.
Заключение
Когда мы решили найти единое хранилище данных, которое могло бы удовлетворить все наши потребности, мы в итоге нашли что-то далеко не идеальное, но достаточно хорошее, чтобы значительно повысить скорость обработки запросов, и попутно обнаружили некоторые его удивительные особенности. . Поэтому, если вы колеблетесь между различными вариантами, вы можете сделать ставку на тот, который вам больше всего нужен, а позаботиться об остальном будет не так сложно.
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27275)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)