

Как спроектировать гибкую модель базы данных
15 апреля 2022 г.Продукты и услуги, с которыми мы взаимодействуем, развиваются день ото дня, добавляя новые наборы функций и возможностей. Службы доставки еды, доставляющие еду к каждому порогу, теперь предоставляют услуги общественного питания. Первоначально Amazon, продающий книги, теперь превратился в гиганта электронной коммерции, занимающегося различными категориями товаров.
Обработка этих бизнес-изменений на уровне хранилища данных может стать кошмаром для разработчиков программного обеспечения, если дизайн базовой модели не учитывает адаптивность.
«Хороший дизайн — это хороший бизнес».
Томас Уотсон, IBM
Начнем с требования.
Как архитектор базы данных ~~(роль существует в реальном мире?)~~ меня попросили создать модель продукта для приложения электронной коммерции, похожего на Amazon, помогающего конечным пользователям покупать разные продукты на одной и той же платформе.
Чтобы понять фактор расширяемости модели, рассмотрим, что платформа электронной коммерции изначально продает книги как продукт, а затем распространяется на продажу одежды и других категорий продуктов. Все продукты могут иметь или не иметь одинаковый набор атрибутов. Например, тип переплета (твердый переплет, спираль и т. д.) — это атрибут, характерный для книг, а цветовая вариация (красный, черный и т. д.) характерна для одежды. В будущем я могу столкнуться с продуктом, имеющим различные атрибуты, характерные только для него самого.
Давайте рассмотрим различные способы разработки такой модели, которая может быть достаточно расширяемой для хранения различных продуктов с постоянной комбинацией атрибутов, сильных и слабых сторон.
:::Информация
В дальнейшем я буду часто использовать ключевые слова ==product== и ==attributes== при объяснении подходов. Чтобы добавить еще немного контекста, ниже приведены определения этих ключевых слов.
==атрибуты:== Определенные элементы товара, такие как размер и цвет футболки, являются атрибутами.
==продукт:== Продукт определяется сочетанием всех атрибутов. Футболка – это товар.
1. Наследование одной таблицы с дополнительными столбцами.
Создание единой таблицы под названием «продукты» для хранения всех продуктов со значениями их атрибутов («размер», «цвет») в виде столбцов. И иметь несколько дополнительных зарезервированных столбцов (extra_1, …) для атрибутов, которые могут возникнуть при запуске нового продукта и не учитывались при разработке «продуктов». Так что в будущем, если у нового продукта в качестве атрибута будет material_type, я могу выделить extra_1 для хранения его значения.
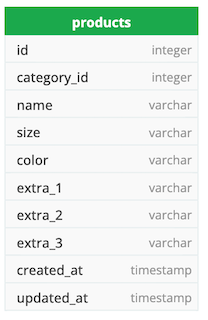
Сильные стороны
- Использование типов данных и ограничений. Поскольку это следует правилам РСУБД для типов данных и ограничений, каждый добавляемый или обновляемый продукт должен удовлетворять этим правилам.
- Никаких взаимодействий с несколькими таблицами — все продукты и их данные хранятся в одной таблице, поэтому для их извлечения не требуются какие-либо объединения разных таблиц.
- Индекс — столбцы могут быть проиндексированы для улучшения поиска и фильтрации.
Слабость
- Гибкость. Этот подход недостаточно гибкий, так как однажды у меня могут закончиться зарезервированные столбцы, а добавление нового столбца после исчерпания зарезервированных столбцов потребует изменений схемы (
ALTER table).
- Хранение. Товары, не имеющие определенных атрибутов, будут иметь «нулевые» значения. Например, строка с книгой в качестве продукта будет иметь значение null как в столбце "размер", так и в столбце "цвет".
- Типы данных зарезервированных столбцов могут использоваться не по назначению, т. е. любые данные могут быть добавлены в эти поля, так как решение об изменении типа данных зарезервированных столбцов принимается задолго до их использования.
- Зарезервированные столбцы не имеют описательных имен, изменение имени зарезервированного столбца потребует изменения схемы.
2. Наследование таблицы классов.
Создание базовой таблицы под названием «продукты» для хранения всех продуктов и их общих атрибутов («размер» — при условии, что он является общим для книжных продуктов) значений в качестве ее столбцов и наличия разных таблиц, «книги_продукты» и «одежда_продукты» только для хранения атрибуты binding_type и color, material_type, характерные для соответствующих продуктов. Объединение базовой таблицы (products) с таблицей унаследованных продуктов (book_products /clothing_products) приведет к полной информации о продукте (книге или ткани).
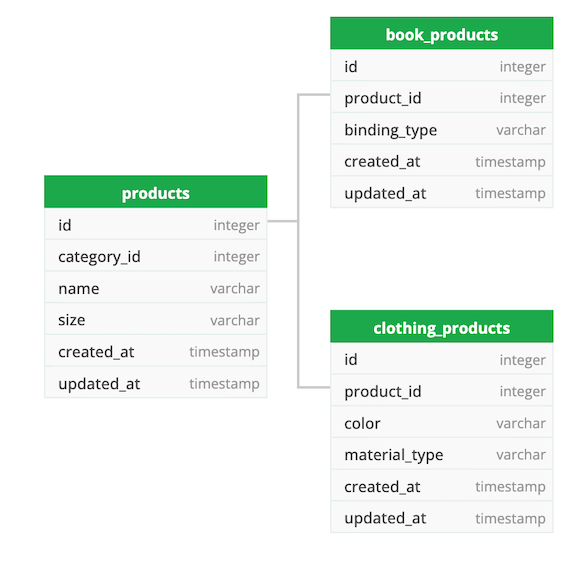 Сильные стороны
Сильные стороны
- Использование типов данных и ограничений. Поскольку это следует правилам РСУБД для типов данных и ограничений, каждый добавляемый или обновляемый продукт должен удовлетворять этим правилам.
- Гибкость — возможность добавлять различные атрибуты в соответствующие таблицы типов продуктов; изменения в одной таблице не повлияют на остальные таблицы продуктов. Введение нового продукта можно осуществить, создав новую таблицу со специфическими для него атрибутами.
- Индекс — возможен также на уровне подпродукта.
- Хранилище — «нулевые» значения могут быть уменьшены, так как все определенные атрибуты присутствуют в разных таблицах.
Слабость
- Требуется взаимодействие с несколькими таблицами — для извлечения всех атрибутов продукта потребуется объединение, поскольку некоторые из них присутствуют в разных таблицах.
- Для добавления одного продукта потребуется несколько операторов вставки.
- Добавление общего атрибута по-прежнему потребует
ALTER table, что приведет к блокировке таблицыproduct.
3. Бетонный стол.
Создание отдельных таблиц для каждого типа продукта (book_products и clothing_products) и наличие всех необходимых атрибутов (size, binding_type, color) в качестве столбцов каждой соответствующей таблицы. Для каждого нового типа продукта будет создана новая таблица.
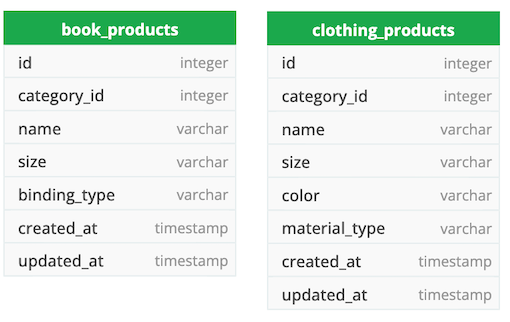
Сильные и слабые стороны этого подхода очень похожи на наследование таблицы классов, за исключением того, что таблица базового класса отсутствует.
4. Одна таблица с JSON.
Создание единой таблицы под названием «продукты» для хранения всех продуктов с общими атрибутами («размер») в виде столбцов. И иметь столбец JSON («дополнительный») для хранения всех атрибутов, характерных для этой записи продукта.
Например: у товара одежды будет размер (S/M/L), хранящийся в столбце «размер», а остальные атрибуты в виде данных JSON ({цвет: красный, тип_материала: хлопок}) в столбце «дополнительно». Если тип СУБД не поддерживает тип данных JSON, то можно использовать такой тип данных, как текст, который позволяет хранить большие сериализованные объекты (строковые объекты JSON).
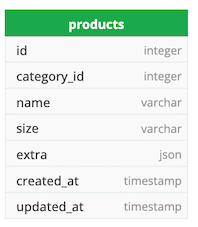
Сильные стороны
- Гибкость. Этот подход является гибким, поскольку различные атрибуты могут храниться в столбце JSON без каких-либо
ALTERв таблице.
- Нет взаимодействия с несколькими таблицами — все продукты и их данные хранятся в одной таблице, поэтому мне не нужны какие-либо объединения разных таблиц для их извлечения.
- Хранилище — «нулевые» значения могут быть уменьшены, так как все определенные атрибуты представлены в виде данных JSON, но данные JSON занимают намного больше места, чем обычные строки и столбцы.
Слабость
- Использование типов данных и ограничений. Данные JSON могут содержать любые данные и могут привести к неправильному использованию. Добавление ограничений на уровне объекта невозможно.
- Индекс — индексирование определенных атрибутов может быть невозможно, возможно с JSONB.
- Трудно обновить отдельные атрибуты для записи продукта из-за природы объекта. И может привести к проблеме грязного чтения.
- Трудно получить отдельные атрибуты объекта, если версия СУБД не поддерживает тип данных JSON.
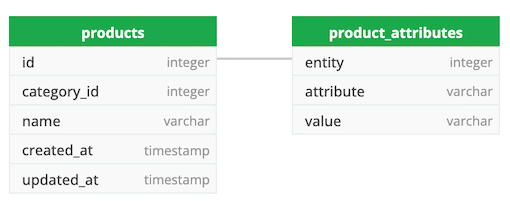
5. EAV (сущность-атрибут-значение).
Следуя этому подходу, я разделю сущность (products) и атрибуты (product_attributes) как две разные таблицы. product не будет хранить никакой информации, связанной с атрибутами. Вместо этого каждый атрибут будет храниться как запись ключа («атрибут»)-значение («значение») в product_attributes. Объединение products в product_attributes приведет к полной информации о продукте (книге или ткани).
Например: чтобы сохранить продукт из ткани, я буду создавать запись продукта в products и каждый атрибут, такой как размер – S, цвет – красный и material_type – хлопок, как разные записи (строки) ключ-значение в product_attributes с сущность, ссылающаяся на products.id.
Сильные стороны
- Гибкость. Этот подход является гибким, так как любое количество атрибутов может быть сохранено в
product_attributes.
- Хранилище — в
product_attributesдобавляются только те атрибуты, которые требуются объекту (продукту).
Слабость
- Использование типов данных и ограничений. Поскольку каждый атрибут хранится в виде строки в
product_attributes, правила типов данных и ограничений РСУБД не могут быть применены и вместо этого должны обрабатываться на уровне приложения.
- Требуется взаимодействие с несколькими таблицами. Для извлечения сведений о продукте и его атрибутах потребуются соединения
product_attributes, ведущие к сложным операциям SQL, т. е. каждый атрибут приведет к объединению.
- Индекс — индексация определенных атрибутов невозможна.
6. NoSQL.
Реляционные таблицы имеют фиксированный набор столбцов и должны определяться при разработке модели, тогда как базы данных NoSQL свободны от этих правил и ограничений. В нереляционной модели можно хранить любые данные.
Сильные стороны
- Гибкость. Этот подход является действительно гибким, так как любой атрибут может присутствовать в каждом продукте.
- Нет взаимодействия с несколькими таблицами — все продукты и их данные хранятся в одной таблице, поэтому для их извлечения не требуются какие-либо объединения разных таблиц.
- Индекс — столбцы могут быть проиндексированы для улучшения поиска и фильтрации.
- Хранение. Нереляционные таблицы занимают мало места, поскольку к каждой записи продукта добавляются только обязательные атрибуты.
Слабость
- Типы данных и ограничения. Это одна из основных слабых сторон баз данных NoSQL, поскольку в таблице нет наборов правил. Эти правила должны управляться на уровне приложения.
Какой подход рассмотреть?
:::Информация
Подходы, описанные в этой статье, являются одними из общих стандартов обработки гибкости модели базы данных. Также может быть несколько других способов разработки моделей, специфичных для каждого варианта использования. Эта статья может рассматриваться как обзор различных способов построения базовых расширяемых моделей и может быть дополнена настройками, характерными для бизнес-требований.
У каждого подхода есть свои сильные и слабые стороны, поэтому наилучший подход зависит от варианта использования решаемой проблемы дизайна и результата мозгового штурма с вашими коллегами :smile:.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27087)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)