
Как отлаживать и оптимизировать обучение с несколькими GPU в TensorFlow
13 августа 2025 г.Обзор контента
Обзор
Рабочий процесс оптимизации производительности
Оптимизируйте производительность на одном графическом процессоре
- Отлаживать входной трубопровод
- Отладка производительности одного графического процессора
- Включить смешанную точность и xla
Оптимизировать производительность на одном хосте с несколькими GPU
- Оптимизируйте градиент Allreduce
- Конфликт потока хоста графического процессора
Обзор
Это руководство покажет вам, как использовать Tensorflow Profiler с Tensorboard, чтобы получить представление о максимальной производительности из ваших графических процессоров, а также отладки, когда один или несколько ваших графических процессоров недостаточно используются.
Если вы новичок в Profiler:
- Начните сTensorflow Profiler: производительность модели профилязаписная книжка с примером кераса иТенсорбордПолем
- Узнайте о различных инструментах и методах профилирования, доступных для оптимизации производительности TensorFlow на хосте (CPU) сОптимизировать производительность TensorFlow с использованием профилировщикагид.
Имейте в виду, что разгрузка вычислений на графический процессор не всегда может быть полезным, особенно для небольших моделей. Могут быть накладные расходы из -за:
- Передача данных между хостом (ЦП) и устройством (графический процессор); и
- Из -за задержки, связанной с задержкой, когда хост запускает ядра графических процессоров.
Рабочий процесс оптимизации производительности
В этом руководстве описывается, как отладить проблемы с производительностью, начиная с одного графического процессора, а затем переходить к одному хосту с несколькими графическими процессорами.
Рекомендуется отладить проблемы с эффективностью в следующем заказе:
Оптимизируйте и отлаживайте производительность на одном графическом процессоре:
- Проверьте, является ли входной трубопровод узким местом.
- Отладка производительности одного графического процессора.
- Включить смешанную точность (с
fp16(float16)) и, необязательно, включитьXlaПолем
Оптимизируйте и отлаживайте производительность на одиночном хосте с несколькими GPU.
Например, если вы используете TensorFlowСтратегия распределенияЧтобы обучить модель на одном хосте с несколькими графическими процессорами и уведомления о неоптимальном использовании графических процессоров, сначала вы должны оптимизировать и отладить производительность для одного графического процессора, прежде чем отладки системой мульти-GPU.
В качестве базового уровня для получения эффективного кода на графических процессорах, это руководство предполагает, что вы уже используетеtf.functionПолем КерасModel.compileиModel.fitAPI будет использоватьtf.functionавтоматически под капотом. При написании индивидуальной учебной петли сtf.GradientTape, см.Лучшая производительность с tf.functionо том, как включитьtf.functionс
В следующих разделах обсуждаются предлагаемые подходы для каждого из приведенных выше сценариев, чтобы помочь идентифицировать и исправить узкие места производительности.
1. Оптимизировать производительность на одном графическом процессоре
В идеальном случае ваша программа должна иметь высокое использование графического процессора, минимальный процессор (хост) для GPU (устройства), а также накладных расходов из входного трубопровода.
Первым шагом в анализе производительности является получение профиля для модели, работающей с одним графическим процессором.
Профилировщик TensorboardОбзор страница- Что показывает представление о том, как ваша модель выполнялась во время профиля, - может дать представление о том, насколько далеко ваша программа от идеального сценария.
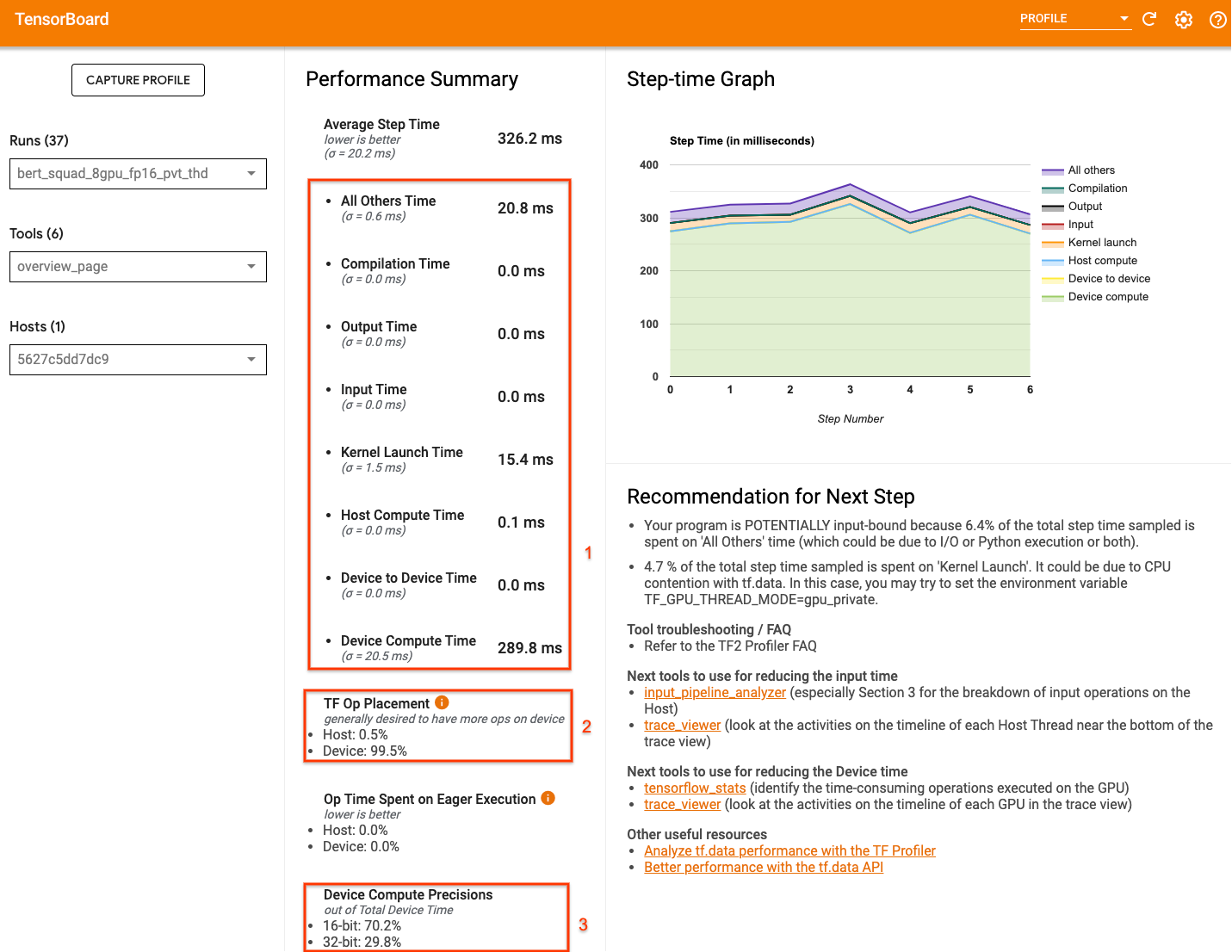
Ключевые номера, чтобы обратить внимание на страницу обзора:
- Сколько шага от реального выполнения устройства
- Процент OPS, размещенного на хосте Device Vs
- Сколько ядра используют
fp16
Достижение оптимальной производительности означает максимизация этих чисел во всех трех случаях. Чтобы получить глубокое понимание вашей программы, вам нужно быть знакомы с профилировщиком Tensorboardпросмотр просмотраПолем Приведенные ниже разделы показывают некоторые общие шаблоны просмотра трассировки, которые вы должны искать при диагностике узких мест производительности.
Ниже приведено изображение вида с трассировкой модели, работающего на одном графическом процессоре. ИзTensorflow Name ScopeиTensorflow OpsРазделы, вы можете идентифицировать различные части модели, такие как прямой проход, функция потерь, вычисление обратного прохода/градиента и обновление веса оптимизатора. Вы также можете использовать OPS на GPU рядом с каждымТранслировать, которые относятся к потокам CUDA. Каждый поток используется для конкретных задач. В этом следе,Поток № 118используется для запуска вычислительных ядер и копий устройства в устройстве.Поток № 119используется для копии хоста и устройства иПоток № 120для устройства для размещения копии.
След, ниже, показывают общие характеристики исполнительской модели.
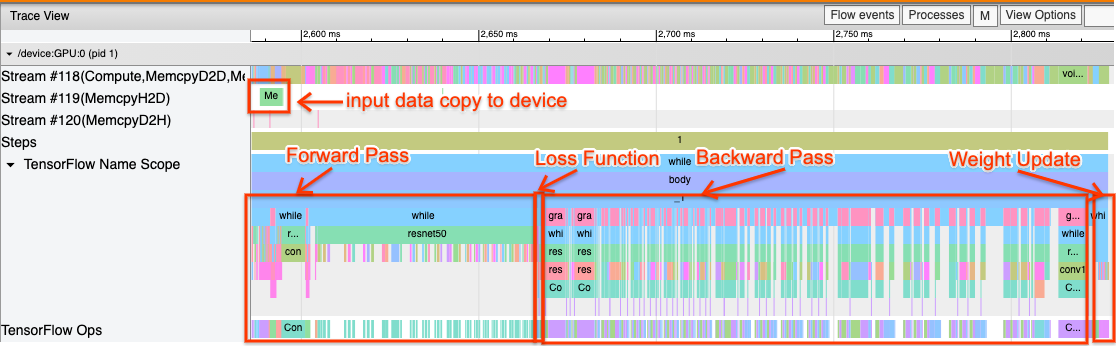
Например, графический процесс вычисления (Поток № 118) выглядит «занятым» с очень небольшим количеством пробелов. Есть минимальные копии от хоста к устройству (Поток № 119) и от устройства до хоста (Поток № 120), а также минимальные пробелы между шагами. Когда вы запускаете Profiler для вашей программы, вы не сможете определить эти идеальные характеристики в своем представлении. Остальная часть этого руководства охватывает общие сценарии и как их исправить.
1. Отладка входного трубопровода
Первый шаг в отладке от отладка GPU-это определить, является ли ваша программа вводится. Самый простой способ выяснить это - использовать профилировщикАнализатор ввода-пиплены, на Tensorboard, который предоставляет обзор времени, проведенного в входном трубопроводе.
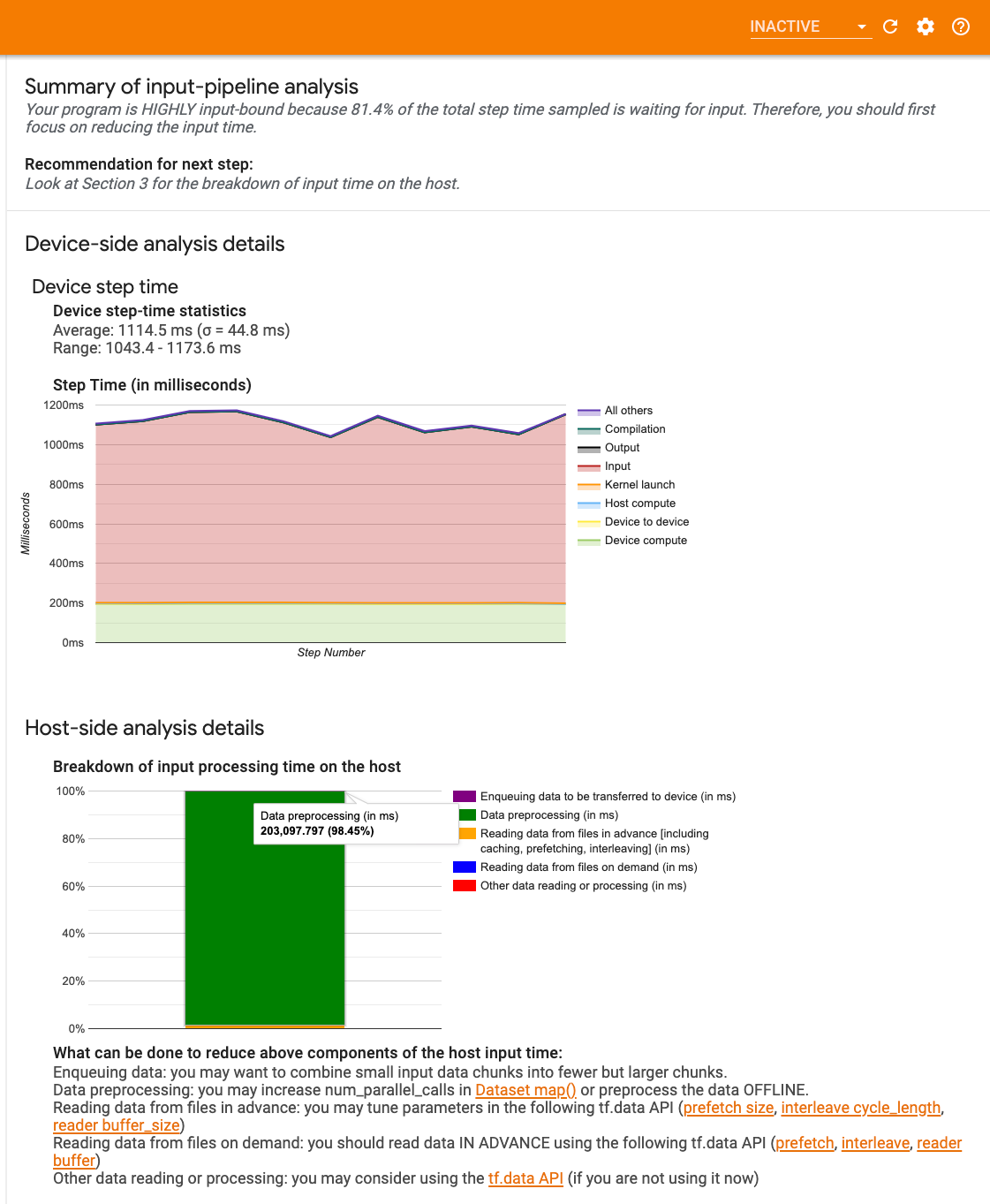
Вы можете предпринять следующие потенциальные действия, если ваш входной пипетлин значительно внесет свой вклад в шаг:
- Вы можете использовать
tf.data-специфическийгидЧтобы узнать, как отлаживать свой входной конвейер. - Другим быстрым способом проверить, является ли входной трубопровод, является узким местом,-это использовать случайно сгенерированные входные данные, которые не нуждаются в предварительной обработке.Вот примериспользования этой техники для модели Resnet. Если входной конвейер является оптимальным, вы должны испытывать аналогичную производительность с реальными данными и с генерируемыми случайными/синтетическими данными. Единственные накладные расходы в случае синтетических данных будут связаны с копией входных данных, которые снова могут быть предварительно выбранные и оптимизированные.
Кроме того, обратитесь кЛучшие методы оптимизации входного конвейера данныхПолем
2. Отладка производительности одного графического процессора
Есть несколько факторов, которые могут способствовать низкому использованию графического процессора. Ниже приведены некоторые сценарии, обычно наблюдаемые при просмотре напросмотр просмотраи потенциальные решения.
1. Проанализируйте пробелы между шагами
Распространенным наблюдением, когда ваша программа не работает оптимально, является пробелом между этапами обучения. На изображении вида трассировки ниже существует большой разрыв между шагами 8 и 9, что означает, что графический процессор простаивает в течение этого времени.
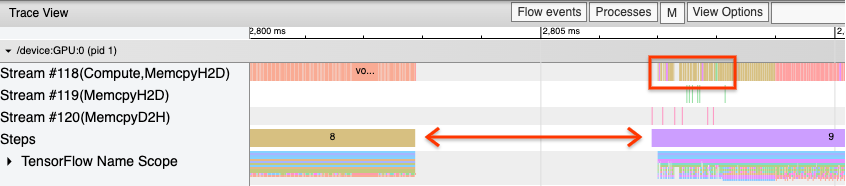
Если ваш просмотрщик трассировки показывает большие пробелы между шагами, это может быть признаком того, что ваша программа связана с входной. В этом случае вам следует обратиться к предыдущему разделу о отладке вашего входного конвейера, если вы еще этого не сделали.
Тем не менее, даже при оптимизированном входном трубопроводе, вы все равно можете иметь пробелы между концом одного шага и началом другого из -за спора потока процессора.tf.dataИспользует фоновые потоки для параллелизации обработки трубопроводов. Эти потоки могут влиять на активность на стороне хоста графического процессора, которая происходит в начале каждого шага, например, копирование данных или планирование операций с графическими процессорами.
Если вы заметите большие пробелы на стороне хоста, которые планируют эти OPS на графическом процессоре, вы можете установить переменную средыTF_GPU_THREAD_MODE=gpu_privateПолем Это гарантирует, что ядра графического процессора запускаются из их собственных выделенных потоков и не попадают в очередь позадиtf.dataработа.
Пробелы между шагами также могут быть вызваны метрическими расчетами, обратными вызовами кераса или OP за пределамиtf.functionкоторые бегают на хосте. Эти Ops не имеют такой хорошей производительности, как OPS в графике TensorFlow. Кроме того, некоторые из этих операций работают на процессоре и копируют тензоры туда -сюда из графического процессора.
Если после оптимизации вашего входного конвейера вы все равно заметите разрывы между шагами в просмотре трассировки, вы должны посмотреть на код модели между шагами и проверить, улучшает ли вызов/метрики отключение вызовов/метрик. Некоторые детали этих OPS также находятся на Trace Viewer (как на устройстве, так и на стороне хоста). Рекомендация в этом сценарии состоит в том, чтобы амортизировать накладные расходы этих операций, выполняя их после фиксированного количества шагов вместо каждого шага. При использованииModel.compileМетод вtf.kerasAPI, установлениеsteps_per_executionФлаг делает это автоматически. Для индивидуальных тренировок, используйтеtf.while_loopПолем
2. Достижение более высокого использования устройств
1. Небольшие ядра графического процессора и задержки запуска ядра хозяина
Ядра Enqueues, которые будут запускаться на графическом процессоре, но задержка (около 20-40 мкс) задействована, прежде чем ядра фактически выполняются на графическом процессоре. В идеальном случае хост -вводил достаточно ядер на графическом процессоре, так что графический процессор тратит большую часть своего времени, а не ожидая, чтобы хост, чтобы включить больше ядра.
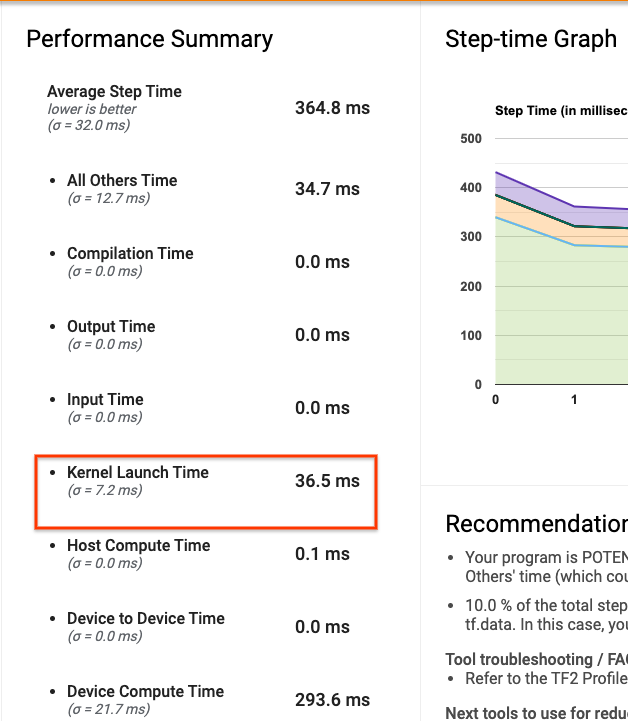
ПрофилировщикОбзор страницаНа Tensorboard показывает, сколько времени графический процессор был бездействующим из -за ожидания хоста, чтобы запустить ядра. На рисунке ниже графический процессор простаивает около 10% от шага, ожидающего запуска ядра.
Апросмотр просмотраДля этой же программы показывают небольшие пробелы между ядрами, где хост занят запуска ядра на графическом процессоре.

Запустив много небольших OPS на графическом процессоре (например, скалярное добавление), хост может не отставать от GPU. АTensorflow StatsИнструмент в Tensorboard для того же профиля показывает 126 224 операций Mul, занимающих 2,77 секунды. Таким образом, каждое ядро составляет около 21,9 мкс, что очень мало (примерно в то же время, что и задержка запуска) и потенциально может привести к задержкам запуска ядра хоста.
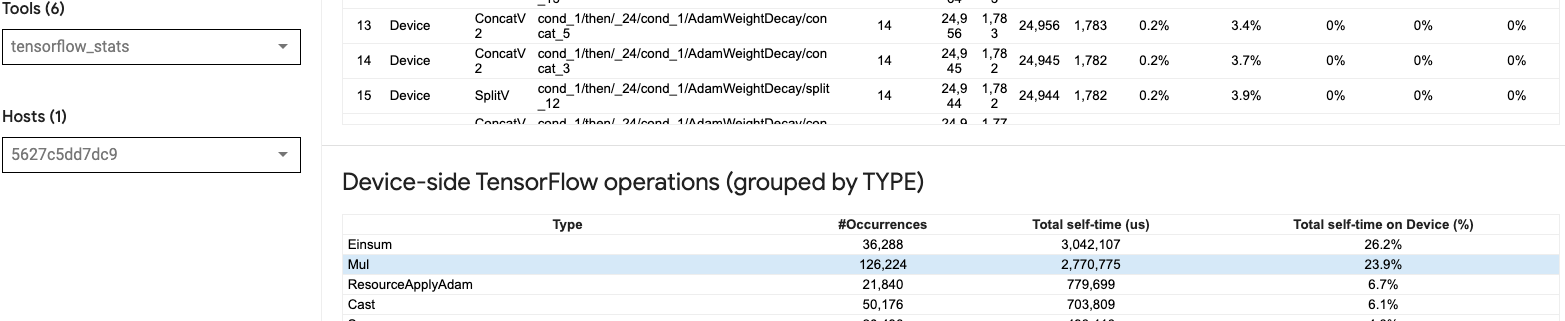
Если тыпросмотр просмотрапоказывает много небольших пробелов между OPS на графическом процессоре, как на изображении выше, вы можете:
- Конкатенате небольшие тензоры и используйте векторизованные операционные операции или используйте больший размер партии, чтобы каждое запускаемое ядро выполняло больше работы, что будет занять графический процессор дольше.
- Убедитесь, что вы используете
tf.functionЧтобы создать графики тензора, так что вы не запускаете OPS в чистом нетерпеливом режиме. Если вы используетеModel.fit(В противоположность индивидуальной тренировочной петле сtf.GradientTape), затемtf.keras.Model.compileавтоматически сделает это для вас. - Ядра предохранителя с использованием xla с
tf.function(jit_compile=True)или автоматическая кластеризация. Для получения более подробной информации перейдите вВключить смешанную точность и xlaРаздел ниже, чтобы узнать, как позволить XLA повысить производительность. Эта функция может привести к высокопоставлению устройств.
2. Площадь Tensorflow OP
ПрофилировщикОбзор страницаПоказывает вам процент OPS, размещенных на устройстве хоста против.просмотр просмотраПолем Как и на изображении ниже, вы хотите, чтобы процент OPS на хосте был очень небольшим по сравнению с устройством.

В идеале, большинство вычислительных интенсивных OPS должны быть размещены на графическом процессоре.
Чтобы узнать, какие устройства назначаются операции и тензоры в вашей модели, установитьtf.debugging.set_log_device_placement(True)как первое заявление вашей программы.
Обратите внимание, что в некоторых случаях, даже если вы указываете ОП, который будет размещен на конкретном устройстве, его реализация может переопределить это условие (пример:tf.unique) Даже для одиночного обучения графического процессора, указание стратегии распространения, например, какtf.distribute.OneDeviceStrategy, может привести к более детерминированному размещению OPS на вашем устройстве.
Одна из причин того, что большинство OP, размещенных в GPU, заключается в предотвращении чрезмерных копий памяти между хостом и устройством (ожидаются копии памяти для данных ввода/вывода модели между хостом и устройством). Пример чрезмерного копирования демонстрируется в представлении трассировки ниже на потоках графических процессоров#167В#168, и#169Полем
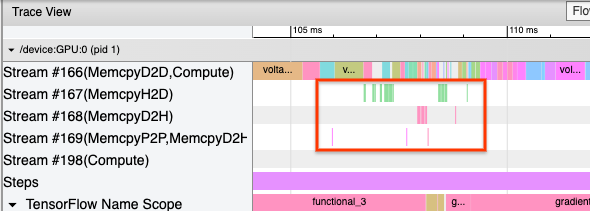
Эти копии иногда могут повредить производительности, если они блокируют ядра графического процессора от выполнения. Операции копирования памяти впросмотр просмотраЕсть больше информации о OPS, которые являются источником этих копированных тензоров, но не всегда легко связать мемкопию с OP. В этих случаях полезно посмотреть на OPS поблизости, чтобы проверить, происходит ли копия памяти в одном и том же месте на каждом шаге.
3. Более эффективные ядра на графических процессорах
После того, как использование графических процессоров вашей программы будет приемлемо, следующим шагом является изучение повышения эффективности ядер графических процессоров, используя тензорные ядра или слитие OPS.
1. Используйте тензорные ядра
Modern NVIDIA® GPU специализировалисьТенсорные ядраЭто может значительно улучшить производительность подходящих ядра.
Вы можете использовать Tensorboard'sСтатистика ядра графического процессораЧтобы визуализировать, какие ядра графического процессора имеют тензорное ядро, а какие ядра используют тензоры. Включает в себяfp16(См. Раздел «Включение смешанной точности» ниже) - это один из способов заставить ядра Multiply Multiply Multiply (GEMM) (Matmul Ops) использовать ядро тензора. Ядра графического процессора эффективно используйте ядра тензора, когда точность равна FP16, а измерения ввода/выходного тензора делятся на 8 или 16 (дляint8)
Примечание:С Cudnn v7.6.3 и более поздними размерами свертки будут автоматически проладить, где это необходимо, чтобы использовать тензоры.
Для других подробных рекомендаций о том, как сделать ядра эффективными для графических процессоров, см.NVIDIA® глубокое обучениегид.
2. Предохраните Ops
Использоватьtf.function(jit_compile=True)чтобы объединить меньшие OPS, чтобы сформировать большие ядра, ведущие к значительному повышению производительности. Чтобы узнать больше, обратитесь кXlaгид.
3. Включить смешанную точность и XLA
После выполнения вышеуказанных этапов, включение смешанной точности и XLA - это два дополнительных шага, которые вы можете предпринять для дальнейшего повышения производительности. Предлагаемый подход заключается в том, чтобы включить их один за другим и убедиться, что преимущества производительности, как и ожидалось.
1. Включить смешанную точность
ТензорфлоуСмешанная точностьРуководство показывает, как включитьfp16Точность на графических процессорах. Давать возможностьУсилительНа графических процессорах NVIDIA® для использования тензоров и реализации до 3 -кратных общих ускорений по сравнению с использованием простоfp32(float32) Точность на Volta и более новых архитектурах GPU.
Убедитесь, что размеры матрицы/тензора удовлетворяют требованиям для вызова ядра, которые используют тензорные ядра. Ядра графического процессора эффективно используют ядра тензора, когда точность равна FP16, а измерения ввода/выходных данных делятся на 8 или 16 (для Int8).
Обратите внимание, что с Cudnn v7.6.3 и более поздними измерениями разбросы будут автоматически проладить, где это необходимо для использования тензоров.
Следуйте лучшим методам ниже, чтобы максимизировать преимущества производительностиfp16точность.
1. Используйте оптимальные ядра FP16
Сfp16Включено, ядра для умножения матрицы вашей программы (GEMM) должны использовать соответствующиеfp16Версия, которая использует тензорные ядра. Однако в некоторых случаях этого не происходит, и вы не испытываете ожидаемого ускорения от включенияfp16, поскольку ваша программа возвращается к неэффективной реализации вместо этого.
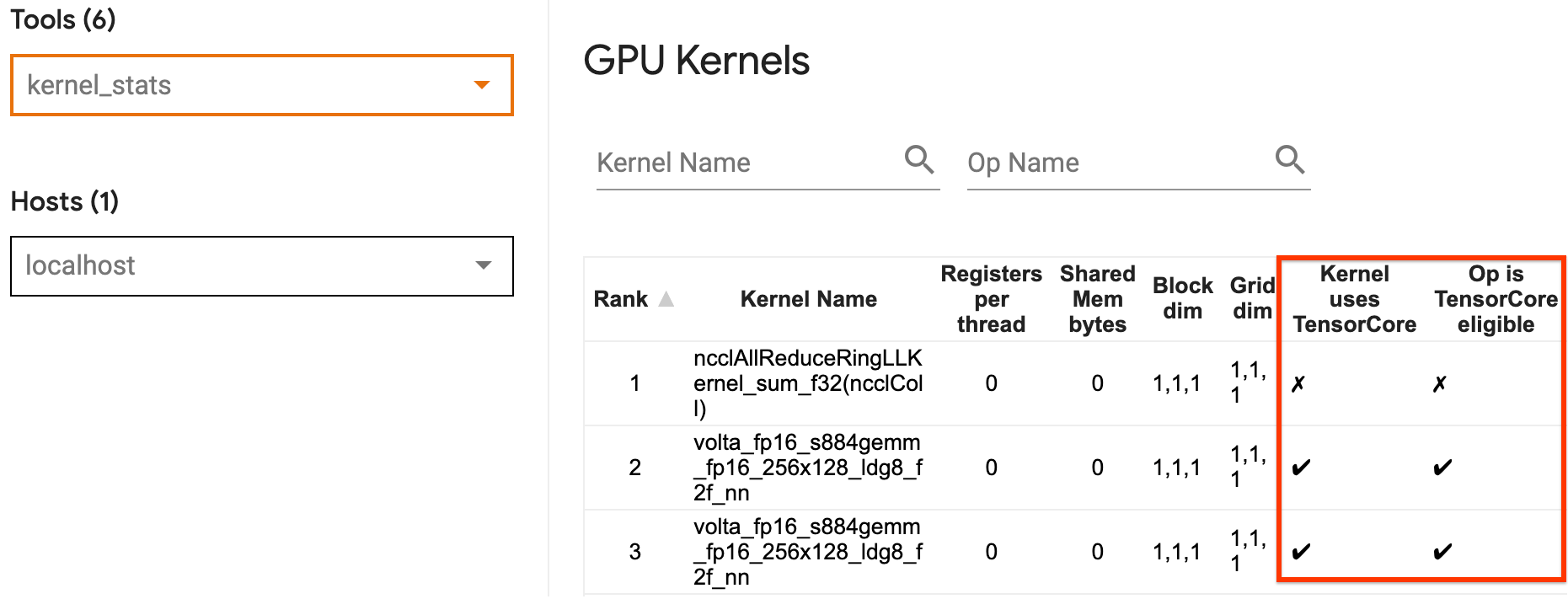
АЯдро графического процессораСтатизированная страница показывает, какие OPS имеют право на тензор, а какие ядра на самом деле используют эффективное тензорное ядро. АРуководство NVIDIA® по производительности глубокого обученияСодержит дополнительные предложения о том, как использовать тензоры. Кроме того, преимущества использованияfp16также покажут в ядрах, которые ранее были связаны с памятью, так как теперь OPS займет половину времени.
2. Динамическое и статическое масштабирование потерь
Масштабирование потерь необходимо при использованииfp16Чтобы предотвратить недостаточность из -за низкой точности. Существует два типа масштабирования потерь, динамического и статического, оба из которых более подробно объясняются вСмешанная точная гидПолем Вы можете использоватьmixed_float16Политика автоматически включает масштабирование потерь в оптимизаторе кераса.
Примечание:Керас смешанный API по умолчанию по умолчанию оценки автономных Softmax Ops (OPS не является частью функции потери кераса) какfp16что может привести к численным вопросам и плохой конвергенции. Разыграть такие операцииfp32Для оптимальной производительности.
При попытке оптимизировать производительность, важно помнить, что масштабирование динамических потерь может представлять дополнительные условные операции, которые работают на хосте, и привести к пробелам, которые будут видны между шагами в просмотре трассировки. С другой стороны, статическое масштабирование потерь не имеет таких накладных расходов и может быть лучшим вариантом с точки зрения производительности с уловами, который необходимо для указания правильного значения шкалы статического потери.
2. Включить xla с tf.function (jit_compile = true) или автоматическая кластеризация
В качестве последнего шага в получении наилучшей производительности с одним графическим процессором, вы можете экспериментировать с включением XLA, который будет объединять OPS и привести к лучшему использованию устройств и более низкому следам памяти. Для получения подробной информации о том, как включить XLA в вашей программе сtf.function(jit_compile=True)или автоматическая кластеризация, обратитесь кXlaгид.
Вы можете установить глобальный уровень JIT на-1(выключенный),1, или2Полем Более высокий уровень является более агрессивным и может уменьшить параллелизм и использовать больше памяти. Установить значение на1Если у вас есть ограничения на память. Обратите внимание, что XLA не работает хорошо для моделей с переменными входными формами тензора, так как компилятор XLA должен будет продолжать собирать ядра, когда он сталкивается с новыми формами.
2. Оптимизировать производительность на одном хосте с несколькими GPU
Аtf.distribute.MirroredStrategyAPI может использоваться для масштабирования модельного обучения от одного графического процессора до нескольких графических процессоров на одном хосте. (Чтобы узнать больше о том, как пройти распределенное обучение с Tensorflow, см.Распределенное обучение с TensorFlowВИспользуйте графический процессор, иИспользуйте TPUРуководства иРаспределенное обучение с керасомУчебник.)
Хотя переход от одного графического процессора к нескольким графическим процессорам в идеале должен быть масштабируемым из коробки, вы можете иногда столкнуться с проблемами производительности.
Переходя от тренировок с одним графическим процессором к нескольким графическим процессорам на одном хосте, в идеале вы должны испытать масштабирование производительности только с помощью дополнительных накладных расходов по градиентному общению и увеличения использования потоков хоста. Из -за этой накладной расходы у вас не будет точного 2 -кратного ускорения, если вы перейдете с 1 к 2 графическим процессорам.
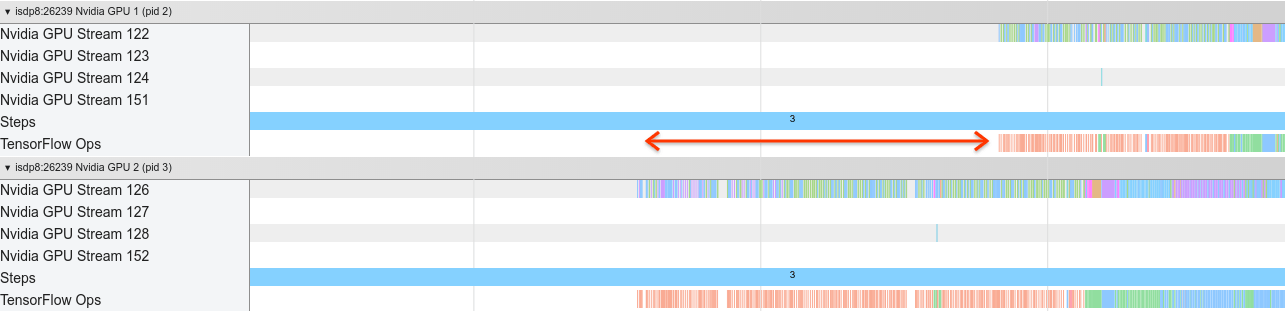
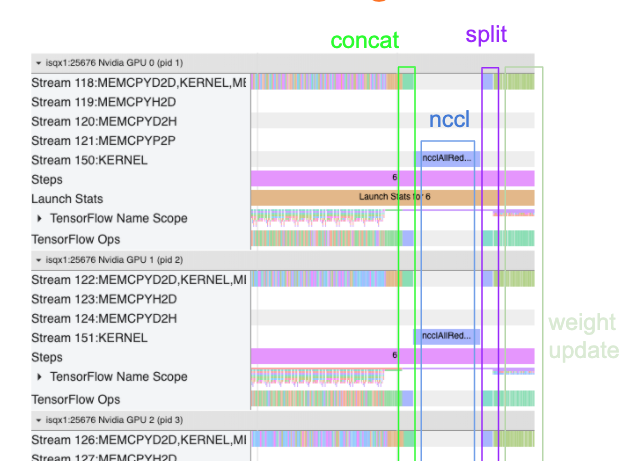
В приведенном ниже представлении трассировки показаны пример дополнительных накладных расходов при обучении на нескольких графических процессорах. Существуют некоторые накладные расходы, чтобы объединить градиенты, передавать их через реплики и разделить их перед тем, как сделать обновление веса.
Следующий контрольный список поможет вам добиться лучшей производительности при оптимизации производительности в сценарии с несколькими GPU:
- Постарайтесь максимизировать размер партии, что приведет к более высокому использованию устройств и амортизируйте затраты на связь между несколькими графическими процессорами. Используяпрофилировщик памятиПомогает понять, насколько близко ваша программа для пикового использования памяти. Обратите внимание, что, хотя более высокий размер партии может повлиять на сходимость, это обычно перевешивается преимуществами производительности.
- Переходя от одного графического процессора к нескольким графическим процессорам, один и тот же хост теперь должен обрабатывать гораздо больше входных данных. Таким образом, после (1) рекомендуется перепроверить производительность входного трубопровода и убедиться, что это не узкое место.
- Проверьте графическую графику в представлении вашей программы для любых ненужных вызовов AllReduce, так как это приводит к синхронизации на всех устройствах. В представлении трассировки, показанном выше, Allroduce выполняется черезNcclЯдро, и есть только один вызов NCCL на каждом графическом процессоре для градиентов на каждом шаге.
- Проверьте ненужные операции D2H, H2D и D2D, которые могут быть сведены к минимуму.
- Проверьте шаг, чтобы убедиться, что каждая копия выполняет одну и ту же работу. Например, может произойти этот графический процессор (обычно,
GPU0) переподписан, потому что хозяин по ошибке в конечном итоге вносит больше работы. - Наконец, проверьте этап обучения на всех графических процессорах в вашем представлении трассировки для любых операций, которые выполняют последовательно. Обычно это происходит, когда ваша программа включает в себя управляющие зависимости от одного графического процессора к другому. В прошлом отладка производительности в этой ситуации была решена в каждом конкретном случае. Если вы соблюдаете это поведение в своей программе,Задать проблему GitHubс изображениями вашего вида трассировки.
1. Optimize gradient AllReduce
При обучении с синхронной стратегией каждое устройство получает часть входных данных.
После вычисления вперед и назад проходит через модель, градиенты, рассчитанные на каждом устройстве, должны быть агрегированы и уменьшены. ЭтотГрадиент Allreduceпроисходит после расчета градиента на каждом устройстве, и до того, как оптимизатор обновляет веса модели.
Каждый графический процессор сначала объединяет градиенты по модельным слоям, передает их через графические процессоры, используяtf.distribute.CrossDeviceOps (tf.distribute.NcclAllReduceявляется по умолчанию), а затем возвращает градиенты после сокращения на слой.
Оптимизатор будет использовать эти уменьшенные градиенты для обновления весов вашей модели. В идеале этот процесс должен происходить в одно и то же время на всех графических процессорах, чтобы предотвратить любые накладные расходы.
Время до AllReduce должно быть примерно таким же, как и:
(number of parameters * 4bytes)/ (communication bandwidth)
Этот расчет полезен в качестве быстрой проверки, чтобы понять, является ли производительность, которую вы имеете при выполнении распределенной учебной работы, как и ожидалось, или вам нужно сделать дальнейшую отладку производительности. Вы можете получить количество параметров в вашей модели отModel.summaryПолем
Обратите внимание, что каждый параметр модели составляет 4 байта в размере, так как используется TensorFlowfp32(float32) для общения градиентов. Даже когда у тебя естьfp16включен, NCCL Allroduce используетfp32параметры.
Чтобы получить преимущества масштабирования, пошаговое время должно быть намного выше по сравнению с этими накладными расходами. Один из способов достижения этого - использовать более высокий размер партии, так как размер партии влияет на шаг, но не влияет на накладные расходы.
2. Конфликт потока хоста графического процессора
При запуске нескольких графических процессоров задача процессора состоит в том, чтобы занять все устройства заняты, эффективно запустив ядра графического процессора на устройствах.
Однако, когда существует много независимых операций, которые ЦП может запланировать на одном графическом процессоре, ЦП может решить использовать много своих хост-потоков, чтобы заняться одним графическим процессором, а затем запустить ядра на другом графическом процессоре в неэнергинистическом порядке. Это может привести к перекосу или отрицательному масштабированию, что может негативно повлиять на производительность.
Апросмотр просмотраНиже показаны накладные расходы, когда ядро графического процессора станет неэффективно, как ядро графического процессора запускается.GPU1Я холостое, а затем начинает запускать OPS послеGPU2начался.
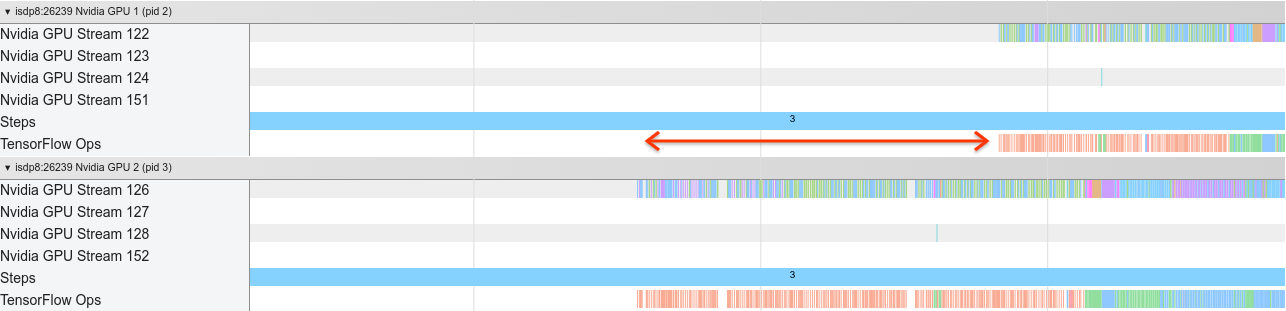
Вид трассировки для хоста показывает, что хост запускает ядра наGPU2Прежде чем запустить их наGPU1(Обратите внимание, что нижеtf_Compute*OPS не указывает на потоки процессора). Если вы испытаете такого рода ошеломляющие ядра графического процессора в следовом представлении вашей программы, рекомендуемое действие - это:
Если вы испытаете такого рода ошеломляющие ядра графического процессора в следовом представлении вашей программы, рекомендуемое действие - это:
- Установите переменную среды TensorFlow
TF_GPU_THREAD_MODEкgpu_privateПолем Эта переменная среды сообщит хосту сохранить потоки для частного графического процессора. - По умолчанию,
TF_GPU_THREAD_MODE=gpu_privateУстанавливает количество потоков на 2, что в большинстве случаев достаточно. Однако это число можно изменить, установив переменную среды TensorFlowTF_GPU_THREAD_COUNTк желаемому количеству потоков.
Первоначально опубликовано на
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)