
Как работать с нумерацией страниц в Python; Пошаговое руководство
23 февраля 2022 г.Если вы работаете над большим проектом по очистке веб-страниц (например, по очистке информации о продукте), то вы, вероятно, наткнулись на страницы с разбивкой на страницы. Стандартной практикой для сайтов электронной коммерции и контента является разбиение контента на несколько страниц для улучшения взаимодействия с пользователем. Однако разбиение на страницы веб-скрапинга усложняет нашу работу.
В этой статье вы узнаете, как всего за несколько минут создать веб-скрейпер для разбиения на страницы, не заблокировав его никакими методами защиты от парсинга.
Хотя вы можете следовать этому руководству без предварительных знаний, было бы неплохо сначала ознакомиться с нашим руководством Scrapy для начинающих для более подробного объяснения структуры, прежде чем приступить к работе.
Без лишних слов, давайте сразу приступим!
Парсинг веб-сайта с нумерацией страниц с помощью Python Scrapy
В этом уроке мы будем очищать категорию мужских головных уборов SnowAndRock, чтобы извлечь все названия продуктов, цены и ссылки.
Небольшой отказ от ответственности — мы пишем эту статью, используя Mac, поэтому вам придется немного адаптировать некоторые вещи для работы на ПК. В остальном все должно быть одинаково.
TLDR: вот краткий фрагмент, чтобы разобраться с нумерацией страниц в Scrapy с помощью кнопки «Далее»:
следующая_страница = response.css('a[rel=next]').attrib['href']
если next_page не None:
yield response.follow (следующая_страница, обратный вызов = self.parse)
Продолжайте читать, чтобы получить подробное объяснение того, как внедрить этот код в ваш скрипт, а также как работать со страницами без кнопки «Далее».
1. Настройте среду разработки
Прежде чем мы начнем писать какой-либо код, нам нужно настроить нашу среду для работы с Scrapy, библиотекой Python, предназначенной для парсинга веб-страниц. Это позволяет нам сканировать и извлекать данные с веб-сайтов, анализировать необработанные данные в структурированном формате и выбирать элементы с помощью селекторов CSS и/или XPath.
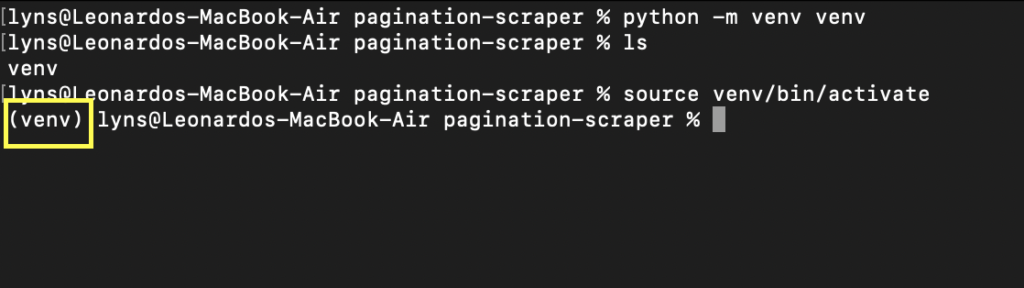
Во-первых, давайте создадим новый каталог (назовем его pagination-scraper) и создадим в нем виртуальную среду python с помощью команды python -m venv venv. Где второй venv — это имя вашего окружения — но вы можете называть его как хотите.
Чтобы активировать его, просто введите source venv/bin/activate. Ваша командная строка должна выглядеть так:
Теперь установить Scrapy так же просто, как ввести pip3 install scrapy — загрузка и установка может занять несколько секунд.
Как только это будет готово, мы введем cd venv и создадим новый проект Scrapy: scrapy startproject scrapypagination.
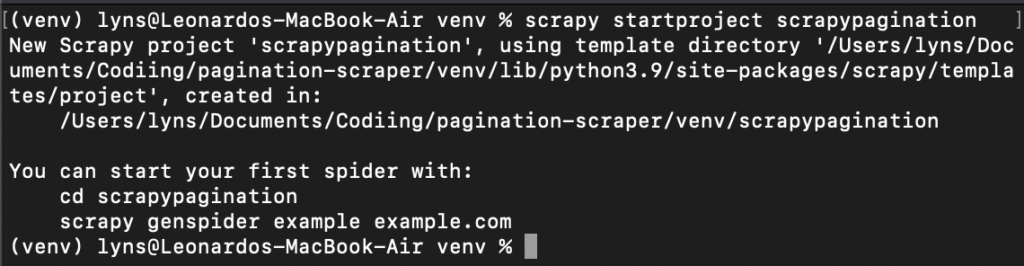
Теперь вы можете видеть, что Scrapy запустил наш проект, установив все необходимые файлы.
2. Настройка ScraperAPI для избежания банов
Самая сложная часть обработки разбитых на страницы страниц — это не написание самого скрипта, а то, как не заблокировать нашего бота сервером.
Для этого нам нужно создать функцию (или набор функций), которая меняет наш IP-адрес после нескольких попыток (это означает, что нам также нужен доступ к пулу IP-адресов). Кроме того, некоторые веб-сайты используют передовые методы, такие как CAPTCHA и профилирование поведения браузера.
Чтобы сэкономить нам время и нервы, мы будем использовать ScraperAPI, API, использующий машинное обучение, огромные фермы браузеров, сторонние прокси-серверы и годы статистического анализа для автоматической обработки каждого механизма защиты от ботов, с которым может столкнуться наш скрипт.
Лучше всего то, что настроить ScraperAPI в нашем проекте с помощью Scrapy очень просто:
импорт скрейпа
из urllib.parse импортировать urlencode
API_KEY = '51e43be283e4db2a5afb62660xxxxxxx'
деф get_scraperapi_url(url):
полезная нагрузка = {'api_key': API_KEY, 'url': url}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(полезная нагрузка)
вернуть proxy_url
Как видите, мы определяем метод get_scraperapi_url(), чтобы помочь нам создать URL-адрес, на который мы будем отправлять запрос. Сначала мы добавили наши зависимости вверху, а затем добавили переменную API_KEY, содержащую наш ключ API — чтобы получить ключ, просто зарегистрируйте бесплатную учетную запись ScraperAPI, и вы найдете ее на своей панели инструментов.
Этот метод будет создавать URL-адрес для запроса для каждого URL-адреса, который находит наш парсер, и поэтому мы настраиваем его таким образом, а не более прямым способом, просто добавляя все параметры непосредственно в URL-адрес, например:
start_urls = ['http://api.scraperapi.com?api_key={yourApiKey}&url={URL}']
3. Понимание структуры URL веб-сайта
Структура URL в значительной степени уникальна для каждого веб-сайта. Разработчики, как правило, используют различные структуры, чтобы облегчить им навигацию, а в некоторых случаях оптимизировать навигацию для сканеров поисковых систем, таких как Google, и реальных пользователей.
Чтобы очистить содержимое с разбивкой на страницы, нам нужно понять, как это работает, и соответствующим образом спланировать это, и нет лучшего способа сделать это, чем проверять страницы и видеть, как сам URL-адрес меняется с одной страницы на другую.
Итак, если мы перейдем на https://www.snowandrock.com/c/mens/accessories/hats.html и прокрутим до последнего продукта в списке, мы увидим, что он использует пронумерованную нумерацию страниц и кнопку «Далее».
Это отличная новость, так как выбирать следующую кнопку на каждой странице будет проще, чем циклически переключаться между номерами страниц. Тем не менее, давайте посмотрим, как изменится URL-адрес при нажатии на вторую страницу.
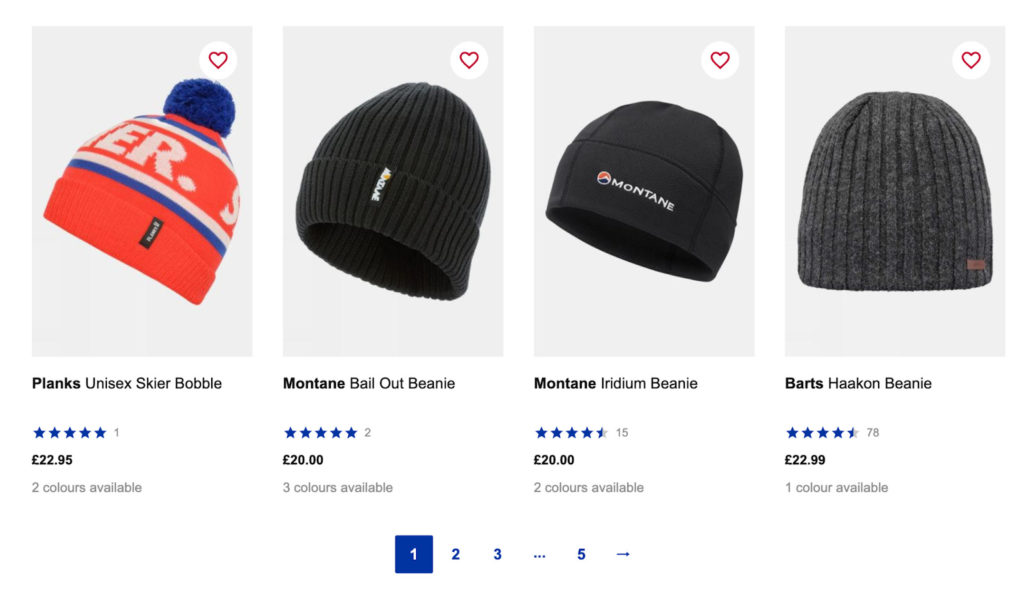
Вот что мы нашли:
**Страница 1: https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48
Страница 2: https://www.snowandrock.com/c/mens/accessories/hats.html?page=1&size=48
Страница 3: https://www.snowandrock.com/c/mens/accessories/hats.html?page=2&size=48**
Обратите внимание, что URL-адрес первой страницы меняется, когда вы возвращаетесь на страницу с помощью навигации, изменяясь на page=0. Хотя мы собираемся использовать кнопку «Далее» для навигации по страницам этого веб-сайта, это не всегда так просто.
Понимание этой структуры поможет нам создать функцию для изменения параметра страницы в URL-адресе и увеличения его на 1, что позволит нам перейти на следующую страницу без кнопки «Далее».
Примечание: не все страницы имеют одинаковую структуру, поэтому всегда проверяйте, какие параметры изменяются и как.
Теперь, когда мы знаем исходный URL-адрес запроса, мы можем создать собственный паук.
4. Отправка исходного запроса методом Start_Requests()
Для первоначального запроса мы создадим класс Spider и назовем его Pagi:
класс PaginationScraper (scrapy.Spider):
имя = "паги"
Затем мы определяем метод start_requests():
деф start_requests (я):
start_urls = ['https://www.snowandrock.com/c/mens/accessories/hats.html']
для URL в start_urls:
выход scrapy.Request (url = get_scraperapi_url (url), обратный вызов = self.parse)
Теперь, после запуска нашего скрипта, он будет отправлять каждый новый найденный URL-адрес этому методу, где новый URL-адрес будет сливаться с результатом метода get_scraperapi_url(), отправляя запрос через серверы ScraperAPI и защищая наш проект.
5. Создание нашего парсера
После тестирования наших селекторов с помощью Scrapy Shell мы получили следующие селекторы:
деф синтаксический анализ (я, ответ):
для головных уборов в response.css('div.as-t-product-grid__item'):
урожай {
'имя': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'цена': hats.css('.as-a-price__value--sell strong::text').get(),
'ссылка': hats.css('a').attrib['href'],
Если вы не знакомы со Scrapy Shell или со Scrapy в целом, было бы неплохо ознакомиться с нашим полным руководством по Scrapy, в котором мы рассмотрим все основы, которые вам нужно знать.
Однако в основном мы выбираем все элементы div, содержащие нужную нам информацию (response.css('div.as-t-product-grid__item'), а затем извлекаем название, цену и ссылку на продукт.
6. Заставьте Scrapy перемещаться по нумерации страниц
Здорово! У нас есть нужная информация с первой страницы, что теперь? Что ж, нам нужно сказать нашему синтаксическому анализатору каким-то образом найти новый URL-адрес и отправить его методу start_requests(), который мы определили ранее. Другими словами, нам нужно найти идентификатор или класс, который мы можем использовать, чтобы получить ссылку внутри следующей кнопки.
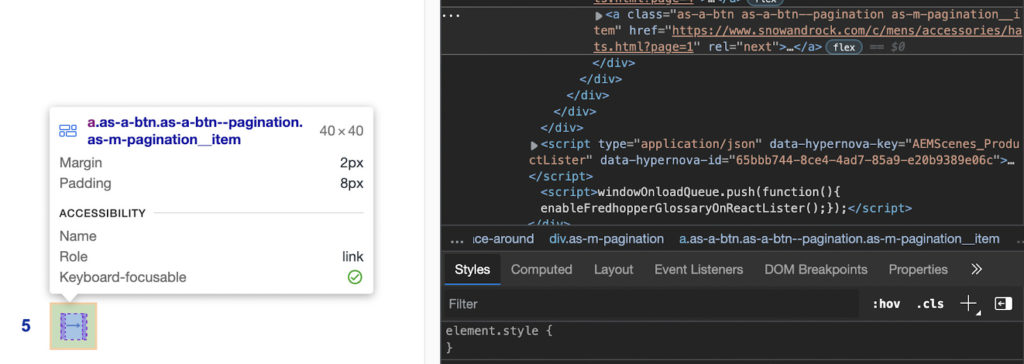
Технически мы могли бы использовать класс ‘.as-a-btn.as-a-btn—pagination as-m-pagination__item’, но, к счастью для нас, есть цель получше: rel=next. Его нельзя спутать ни с какими другими селекторами, а выбрать атрибут с помощью Scrapy очень просто.
следующая_страница = response.css('a[rel=следующий]').attrib['href']
если next_page не None:
yield response.follow (следующая_страница, обратный вызов = self.parse)
Теперь он будет перебирать страницы до тех пор, пока в разбиении на страницы не останется страниц, поэтому нам не нужно устанавливать какой-либо другой механизм остановки.
Если вы следовали всем инструкциям, ваш файл должен выглядеть так:
импортировать скрейп
из urllib.parse импортировать urlencode
API_KEY = '51e43be283e4db2a5afb62660xxxxxx'
защита get_scraperapi_url (url):
полезная нагрузка = {'api_key': API_KEY, 'url': url}
proxy_url = 'http://api.scraperapi.com/?' + urlencode (полезная нагрузка)
вернуть proxy_url
класс PaginationScraper (scrapy.Spider):
имя = "паги"
деф start_requests (я):
start_urls = ['https://www.snowandrock.com/c/mens/accessories/hats.html']
для URL в start_urls:
выход scrapy.Request (url = get_scraperapi_url (url), обратный вызов = self.parse)
деф синтаксический анализ (я, ответ):
для головных уборов в response.css('div.as-t-product-grid__item'):
урожай {
'имя': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'цена': hats.css('.as-a-price__value--sell strong::text').get(),
'ссылка': hats.css('a').attrib['href'],
следующая_страница = response.css('a[rel=next]').attrib['href']
если next_page не None:
yield response.follow (следующая_страница, обратный вызов = self.parse)
Теперь он готов к запуску!
Работа с нумерацией страниц без кнопки «Далее»
До сих пор мы видели, как создать веб-скрейпер, который перемещается по разбивке на страницы, используя ссылку внутри кнопки «Далее» — помните, что Scrapy на самом деле не может взаимодействовать со страницей, поэтому он не будет работать, если кнопку нужно щелкнуть по порядку. чтобы он показывал больше контента.
Однако что происходит, когда это не вариант? Другими словами, как мы можем перемещаться по страницам без кнопки «Далее», на которую можно положиться.
Вот где может пригодиться понимание структуры URL сайта:
**Страница 1: https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48
Страница 2: https://www.snowandrock.com/c/mens/accessories/hats.html?page=1&size=48
Страница 3: https://www.snowandrock.com/c/mens/accessories/hats.html?page=2&size=48**
Единственное, что меняется между URL-адресами, — это параметр страницы, который увеличивается на 1 для каждой следующей страницы.
Что это значит для нашего скрипта? Ну, во-первых, нам нужно изменить способ отправки исходного запроса, добавив новую переменную:
класс PaginationScraper (scrapy.Spider):
имя = "паги"
номер_страницы = 1
start_urls = ['http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48']
В этом случае мы также используем прямую структуру cURL ScraperAPI, потому что мы просто меняем параметр, а это означает, что нет необходимости создавать совершенно новый URL-адрес. Таким образом, каждый раз, когда он меняется, он все равно будет отправлять запрос через серверы ScraperAPI.
Далее нам нужно изменить наше условие в конце, чтобы оно соответствовало новой логике:
next_page = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=' + str(PaginationScraper.page_number) + '&size =48'
если PaginationScraper.page_number < 6:
PaginationScraper.page_number += 1
yield response.follow (следующая_страница, обратный вызов = self.parse)
Здесь происходит то, что мы обращаемся к переменной page_number из метода PaginationScraper(), чтобы заменить значение параметра страницы внутри URL-адреса.
После этого он проверит, меньше ли значение page_number 6, потому что после страницы 5 больше нет результатов.
Пока условие выполняется, оно увеличивает значение page_number на 1 и отправляет URL-адрес для анализа и очистки, и так далее, пока page_number не станет равным 6 или больше.
Вот полный код для очистки разбитых на страницы страниц без кнопки «Далее»:
импортировать скрейп
класс PaginationScraper (scrapy.Spider):
имя = "паги"
номер_страницы = 1
start_urls = ['http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48']
деф синтаксический анализ (я, ответ):
для головных уборов в response.css('div.as-t-product-grid__item'):
урожай {
'имя': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'цена': hats.css('.as-a-price__value--sell strong::text').get(),
'ссылка': 'https://www.snowandrock.com/' + hats.css('a').attrib['href']
next_page = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660fc6ee44&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=' + str(PaginationScraper.page_number) + '&размер=48'
если PaginationScraper.page_number < 6:
PaginationScraper.page_number += 1
yield response.follow (следующая_страница, обратный вызов = self.parse)
Подведение итогов
Независимо от того, собираете ли вы данные о недвижимости или парсите платформы электронной коммерции, такие как Etsy, разбиение на страницы будет обычным явлением, и вам нужно быть готовым к творчеству.
Альтернативные данные стали обязательными почти для каждой отрасли в мире, а возможность создавать сложные и эффективные парсеры даст вам огромное конкурентное преимущество.
Оригинал
🔥 Популярное на этой неделе
-
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27758)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)