:::Информация
ОТКАЗ ОТ ОТВЕТСТВЕННОСТИ: я являюсь сторонником разработчиков в dstack.
Вступление
В нынешнем режиме работы с большими данными сложно разместить все данные в одном процессоре.
В таком случае для обработки данных используется несколько рабочих (ЦП). Даже в облаке настройка инфраструктуры может быть довольно болезненной, а ее автоматизация может сэкономить много времени и сделать процесс более воспроизводимым.
В этом сообщении блога мы будем использовать dstack для создания конвейера непрерывного обучения в облаке с использованием нескольких графических процессоров.
Как только вы определите свои рабочие процессы и их требования к инфраструктуре с помощью кода, вы сможете быстро запустить его в любое время, и dstack автоматически предоставит всю необходимую инфраструктуру в настроенном облаке.
В то же время он будет отслеживать весь код, параметры и выходные данные. Для этого мы будем использовать следующие инструменты:
- PyTorch DDP,
- Молния PyTorch,
- дстек,
- Палочка Б.
Позвольте мне кратко объяснить, что делают эти инструменты.
PyTorch DDP: DDP означает «распределенный параллельный доступ к данным». Идея, лежащая в основе этого, заключается в том, что модель реплицируется на каждом рабочем потоке, а каждый рабочий процесс реплики — на другом наборе выборок данных, что обеспечивает масштабируемость.
Кроме того, задействованные градиенты вычисляются независимо для каждого рабочего процесса, чтобы впоследствии накапливаться посредством связи между ними.
PyTorch Lightning: Основное преимущество Pytorch Lightning по сравнению с Pytorch заключается в том, что нет необходимости писать много шаблонного кода.
dstack: dstack — это платформа для автоматизации конвейеров машинного обучения. В частности, пользователь может определить рабочие процессы и их детали, такие как поставщик рабочего процесса (программа, которая запускает ваш рабочий процесс), скрипт для запуска, артефакты ввода и вывода (например, другие рабочие процессы, от которых зависит текущий рабочий процесс, и папки с выходными файлами). ), необходимые ресурсы (например, объем памяти или количество графических процессоров) и т. д. с помощью декларативных файлов конфигурации. После определения рабочие процессы можно запускать через интерфейс командной строки dstack. dstack позаботится о предоставлении необходимых ресурсов с помощью одного из связанных облаков (например, AWS, GCP или Azure). Представленные прогоны можно отслеживать в пользовательском интерфейсе dstack.
WandB: WandB отлично подходит для отслеживания различных показателей, включая точность, потери при обучении, потери при проверке, использование графических процессоров, памяти и т. д.
Теперь, когда мы понимаем задействованные инструменты, давайте рассмотрим шаги, необходимые для построения нашего конвейера.
Шаги
Конфигурация dstack
После того, как вы вошли в свою учетную запись на dstack.ai, щелкните вкладку «Настройки» слева, а затем щелкните вкладку AWS.
Здесь вы должны предоставить свои учетные данные AWS и указать, какие типы экземпляров AWS разрешено использовать dstack.
Поскольку для нашего рабочего процесса требуется несколько графических процессоров, мы можем добавить тип экземпляра p3.8xlarge. Обязательно выберите регион, в котором у вас есть котировки графического процессора, чтобы использовать этот тип экземпляра.
Чтобы добавить разрешенные типы экземпляров, нажмите кнопку «Добавить ограничение». После того, как вы закончите, пользовательский интерфейс должен выглядеть так, как показано на изображении ниже.
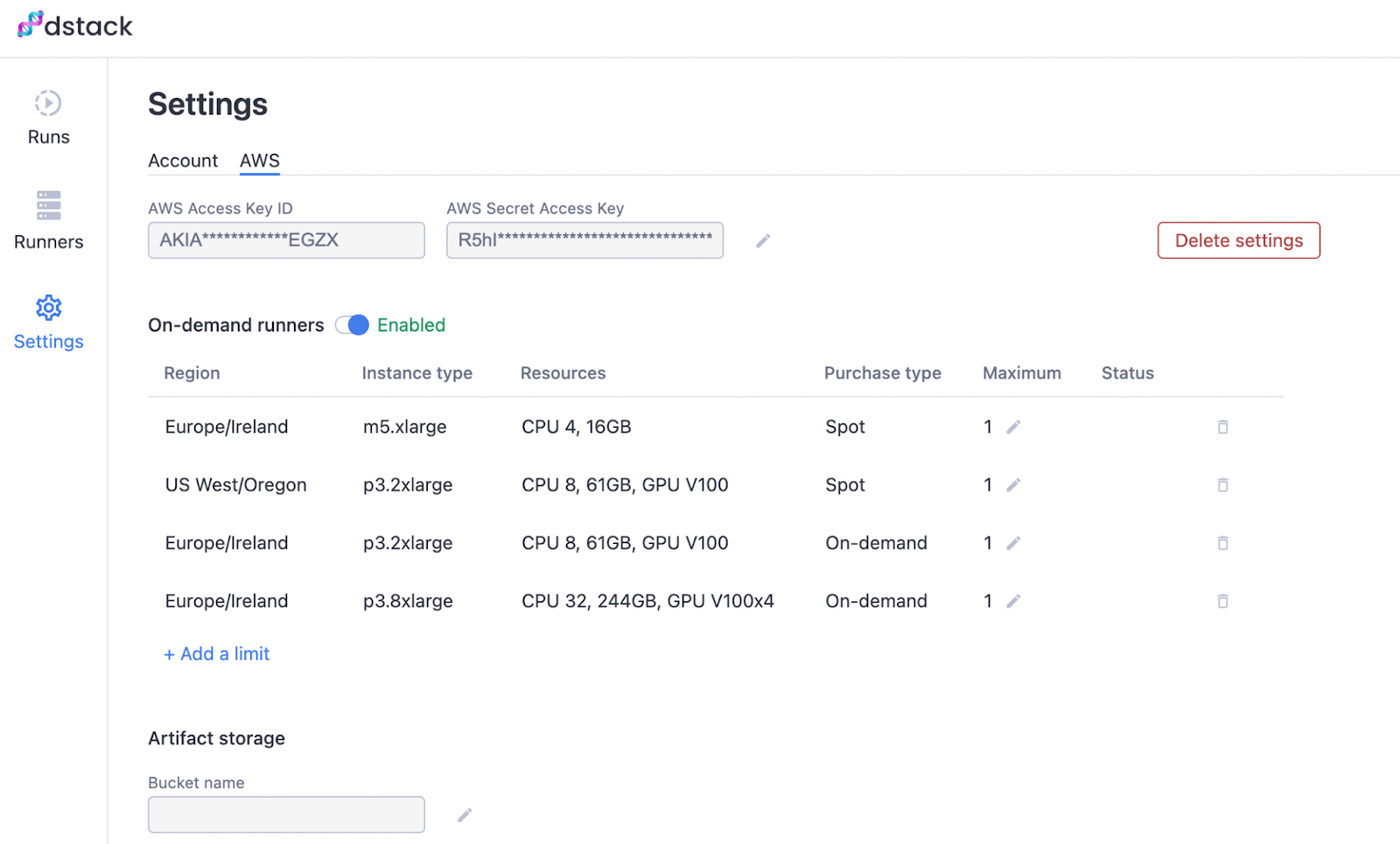
Держите пользовательский интерфейс dstack открытым, так как мы будем продолжать возвращаться, чтобы увидеть ход выполнения наших рабочих процессов.
Конфигурация WandB
Поскольку мы собираемся использовать Wandb, нам нужно будет указать наш ключ API WandB в качестве секрета в настройках dstack. Ваш ключ API WandB можно найти в разделе «Настройки», как показано ниже.
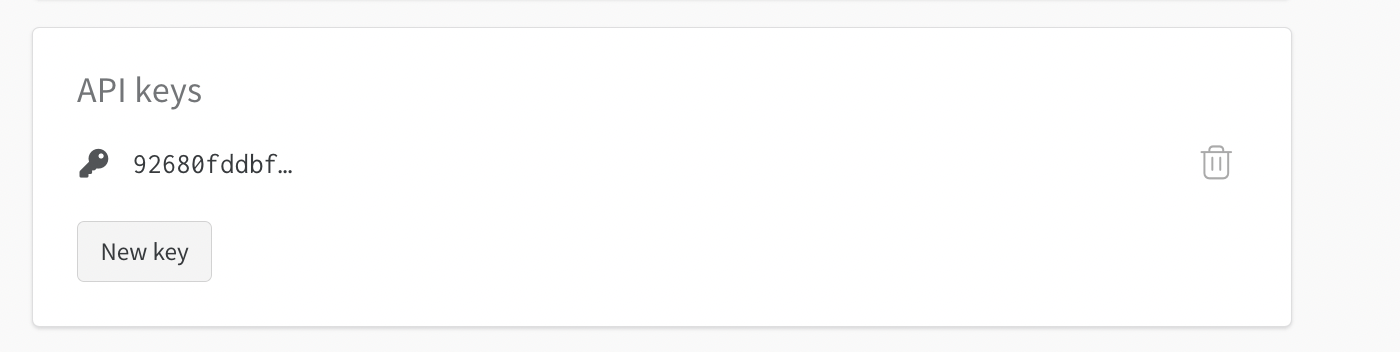
Скопируйте соответствующий ключ API и добавьте его в качестве секрета в настройках своей учетной записи dstack.
Нажмите кнопку «Добавить секрет» и установите ключ WANDB_API_KEY, а в поле значения вставьте свой ключ WandB API, который вы скопировали ранее. Наконец, ваши настройки dstack должны выглядеть следующим образом:

Установите необходимые пакеты
Вот файл requirements.txt, который мы собираемся использовать в нашем проекте:
dstack
pytorch-молния
факел
факельное зрение
жезл
Идите вперед и установите его, используя следующую команду:
``` ударить
pip install -r требования.txt
Теперь все необходимые пакеты установлены, включая интерфейс командной строки dstack.
Структура каталогов
Для проекта мы должны следовать структуре каталогов, представленной ниже:
<папка проекта>/
.dstack/
рабочие процессы.yaml
поезд.py
требования.txt
Модель и тренер
Файл «train.py» обрабатывает модель и обучающие объекты конвейера обучения машинного обучения.
В зависимости от количества графических процессоров на устройстве (можно проверить с помощью torch.cuda.is_available()) мы должны соответствующим образом установить аргументы объекта тренера.
Для ЦП нам нужно установить accelerator = 'cpu', а для остальных случаев мы устанавливаемaccelerator = 'gpu', что мы делаем через переменнуюaccelerator_name`.
```питон
экземпляр трейнера с соответствующими настройками
Trainer = pl.Trainer(accelerator=имя_акселератора,
limit_train_batches=0,5,
макс_эпох = 10,
регистратор = wandb_logger,
устройства = количество_устройств,
стратегия = "ддп")
Обратите внимание, что мы используем strategy="ddp", чтобы убедиться, что Pytorch Lightning использует стратегию обучения DDP, упомянутую ранее во введении к этому блогу.
Мы также устанавливаем logger=wandb_logger в объекте pl.Trainer, чтобы использовать WandB для отслеживания метрик и другой системной информации.
Полный код из этого руководства можно найти здесь.
рабочие процессы dstack
Теперь мы указываем рабочий процесс через файл .dstack/workflows.yaml. Содержимое файла .dstack/workflows.yaml выглядит следующим образом.
``ямл
рабочие процессы:
- имя: train-mnist-multi-gpu
провайдер: питон
версия: 3.9
требования: требования.txt
скрипт: train.py
артефакты:
- данные
- модель
Ресурсы:
GPU: 4
dstack работает
Чтобы запустить рабочий процесс, все, что нам нужно сделать, это выполнить следующую команду в терминале.
``` ударить
dstack запустить train-mnist-multi-gpu
Теперь откройте dstack.ai, чтобы увидеть рабочие процессы (после входа в систему). Вы увидите содержимое вкладки «Runs», как показано ниже.

Вы можете нажать «Выполнить», чтобы увидеть ход рабочего процесса. На вкладке «Журналы» вы увидите облачный сервер, на котором работает «train.py», через несколько минут после запуска задания.
На вкладке «Работа» вы увидите информацию, как показано ниже.
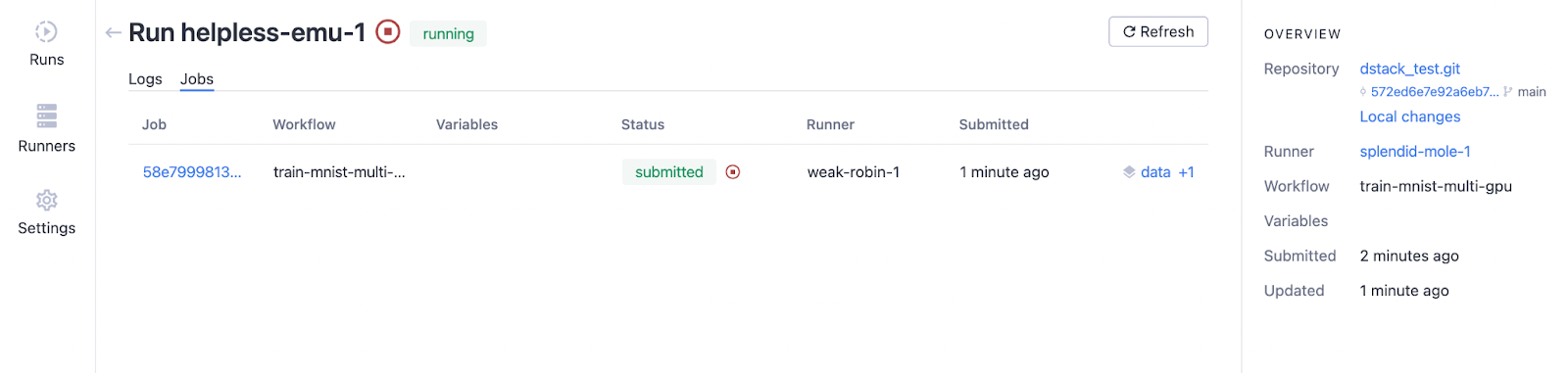
После завершения прогона мы можем отслеживать артефакты, нажав кнопку «данные + 1», и после нажатия папок «данные» и «модель» результат выглядит следующим образом.
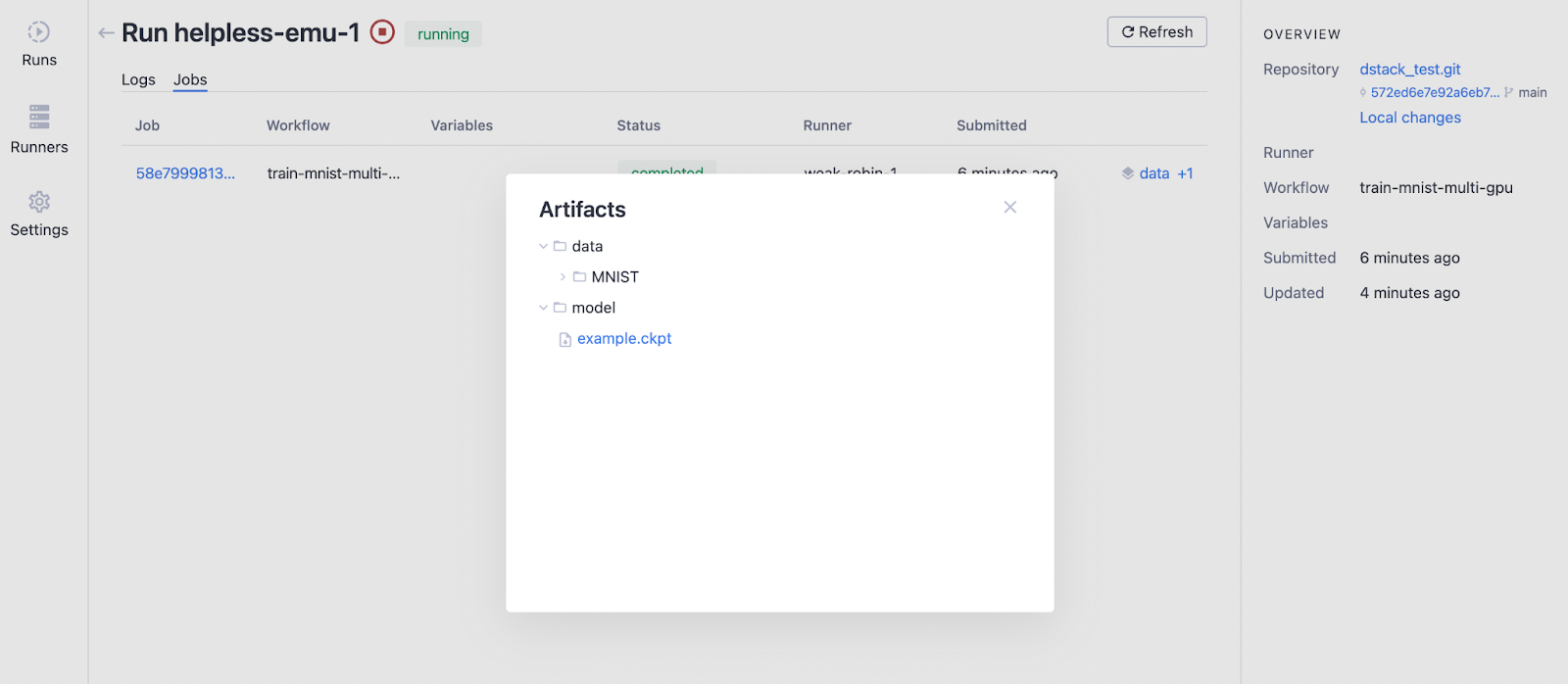
Содержимое артефактов можно загрузить через интерфейс командной строки dstack.
На вкладке «Бегуны» с левой стороны вы найдете информацию о конкретных используемых экземплярах.
Мониторинг WandB
После завершения прогона вы найдете в WandB отслеживаемые вами показатели. Вы также найдете информацию об использовании графического процессора и другие важные детали.
В принципе, вместе с dstack можно использовать любой другой сервис отслеживания экспериментов.
Вывод
Надеюсь, вам понравилось читать этот блог.
Код, использованный в этом сообщении в блоге, можно найти в репозитории git здесь.
Ссылки, которые я использовал, следующие.
:::Информация
ОТКАЗ ОТ ОТВЕТСТВЕННОСТИ: я являюсь сторонником разработчиков в dstack.