

Как повысить эффективность кэширования в приложениях для работы с данными, таких как Presto
23 февраля 2022 г.Запуск Presto с Alluxio набирает популярность в сообществе. Это позволяет избежать длительных задержек при чтении данных из удаленного хранилища за счет использования SSD или памяти для кэширования горячих наборов данных рядом с рабочими Presto. Presto поддерживает планирование мягкого сходства на основе хэшей, чтобы обеспечить кэширование только одной или двух копий одних и тех же данных во всем кластере, что повышает эффективность кэширования, позволяя локально кэшировать больше горячих данных. Однако текущий используемый алгоритм хеширования плохо работает при изменении размера кластера. В этой статье представлен новый алгоритм хеширования для мягкого планирования сходства, согласованное хеширование, для решения этой проблемы.
Планирование мягкого сходства
Presto использует стратегию планирования, называемую мягким планированием сходства , чтобы запланировать разделение (наименьшую единицу обработки данных) на один и тот же рабочий узел Presto (предпочтительный узел). Сопоставление разделения и рабочего процесса Presto вычисляется с помощью хеш-функции разделения, гарантируя, что одно и то же разделение всегда будет хешироваться для одного и того же рабочего процесса. При первой обработке разделения данные будут кэшироваться на предпочтительном рабочем узле. Когда последующие запросы обрабатывают одно и то же разделение, эти запросы будут снова планироваться для одного и того же рабочего узла. Поскольку данные уже кэшированы локально, удаленное чтение не потребуется.
Для улучшения балансировки нагрузки и обработки нестабильных рабочих процессов выбираются два предпочтительных узла. Если первый вариант занят или не отвечает, используется второй. Данные могут кэшироваться на 2 рабочих узлах физически.
Для получения дополнительной информации о планировании soft affinity, пожалуйста, прочитайте "Улучшение задержки Presto с помощью кэширования данных Alluxio".
Алгоритм хеширования
Планирование мягкого сходства основано на алгоритмах хэширования для вычисления сопоставления между разделенными и рабочими узлами. Раньше использовалась модульная функция:
WorkerID1 =Hash(splitID) % workerCount
WorkerID2 =Hash(splitID) % workerCount + 1
Эта стратегия хеширования проста и хорошо работает, когда кластер стабилен и на рабочих узлах нет изменений. Однако, если рабочий процесс временно недоступен или недоступен, количество рабочих процессов может измениться, а сопоставление разделения с рабочими процессами будет полностью перетасовано, что приведет к значительному падению частоты попаданий в кэш. Если проблемный работник вернется в сеть позже, эта перестановка повторится.
Чтобы смягчить эту проблему, Presto использует количество всех рабочих вместо количества активных рабочих при использовании модуля для вычисления назначения рабочих. Однако это может только смягчить повторное хэширование, вызванное отключением временных рабочих узлов. Бывают ситуации, когда имеет смысл добавлять/удалять воркеров из-за колебаний рабочей нагрузки. В этих сценариях возможно ли по-прежнему поддерживать разумную частоту попаданий в кэш и не вводить массовое повторное хеширование? Решение — согласованное хеширование.
Согласованное хеширование
Концепция согласованного хеширования была введена в 1997 году Дэвидом Каргером как способ распределения запросов среди изменяющегося количества веб-серверов. Этот метод широко используется для балансировки нагрузки, распределенных хеш-таблиц и т. д.
Как работает последовательное хеширование?
Представьте, что выходной диапазон хэша [0, MAX_VALUE] отображается в круг (соединяет MAX_VALUE с 0). Чтобы продемонстрировать, как работает последовательное хеширование, предположим, что кластер Presto состоит из 3 рабочих узлов Presto и есть 10 разбиений, которые запрашиваются повторно.
Во-первых, рабочие узлы хэшируются на кольце хеширования. Для каждого разделения он будет назначен рабочему процессу, который находится рядом с его хеш-значением в кольце хэширования.
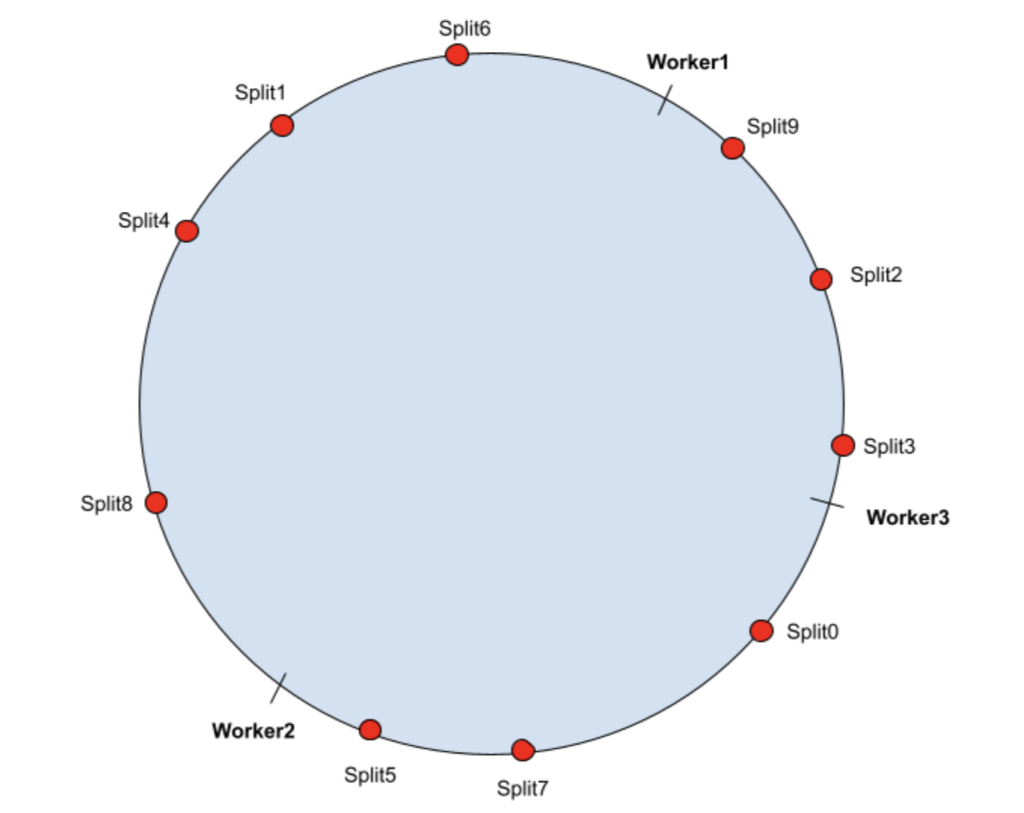
В приведенном выше сценарии разделения назначаются следующим образом:
| Рабочий1 | Разделить1, Разделить4, Разделить6, Разделить8 |
| Рабочий2 | Сплит0, Сплит5, Сплит7 |
| Рабочий3 | Сплит2, Сплит3, Сплит9 |
Удаление воркера
Теперь, если worker2 по какой-то причине отключится, в соответствии с алгоритмом разделение 0, 5 и 7 будет запланировано для worker со следующим значением хеш-функции, то есть worker2:
| Рабочий1 | Split0, Split1, Split4, Split5, Split6, Split7, Split8 |
| Рабочий3 | Сплит2, Сплит3, Сплит9 |
Перехэшировать нужно только те разбиения, которые были хэшированы для автономного рабочего (worker3 в нашем примере). Другие данные не пострадали. Если worker3 подключится к сети позже, Split 2, 3 и 9 снова будут хэшированы в worker3, что не повлияет на частоту попаданий на других worker.
Добавление воркера
Теперь, если рабочая нагрузка возрастет и в кластер необходимо добавить еще один рабочий узел, worker4. Хэш-значение Worker4 находится в кольце хеширования следующим образом:
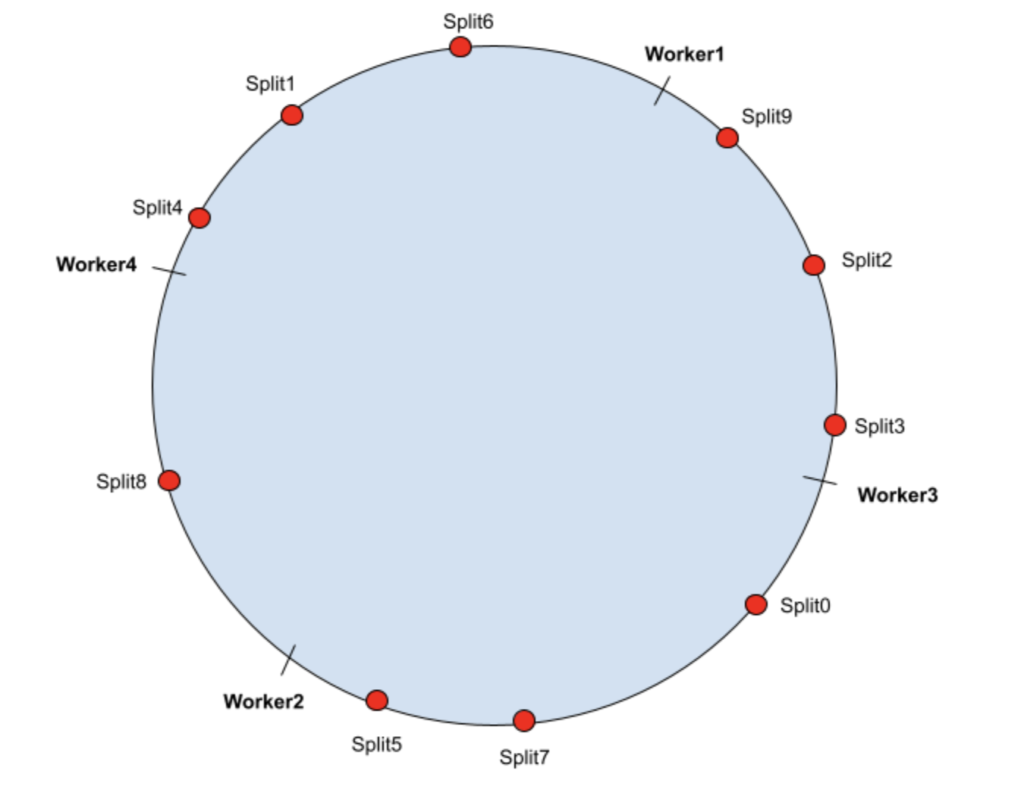
В этом случае split8 попадет в диапазон worker4, все остальные назначения split не будут затронуты, поэтому частота попаданий в кэш для этих split не пострадает. Новое задание:
| Рабочий1 | Разделить1, Разделить4, Разделить6 |
| Рабочий2 | Сплит0, Сплит5, Сплит7 |
| Рабочий3 | Сплит2, Сплит3, Сплит9 |
| Рабочий4 | Сплит8 |
Виртуальные узлы
Как видно из вышеизложенного, последовательное хеширование может гарантировать, что в ситуации изменения узлов в среднем требуется повторное хэширование только Nsplits / Nnodes разбиений. Однако из-за отсутствия случайности в распределении рабочих процессов расщепления могут быть неравномерно распределены между всеми рабочими узлами. Чтобы смягчить эту проблему, вводится понятие «виртуальные узлы». Виртуальные узлы также могут помочь перераспределить нагрузку узла на несколько узлов, когда они отключены, что уменьшает колебания нагрузки из-за нестабильности кластера.
Каждому физическому рабочему узлу сопоставлено несколько виртуальных узлов. Виртуальные узлы помещаются в кольцо хеширования. Разделение будет назначено следующему виртуальному узлу в кольце хэширования, таким образом, маршрут к физическому узлу будет сопоставлен с виртуальным узлом. В следующих примерах показан возможный сценарий, в котором каждый физический рабочий узел имеет 3 виртуальных узла:
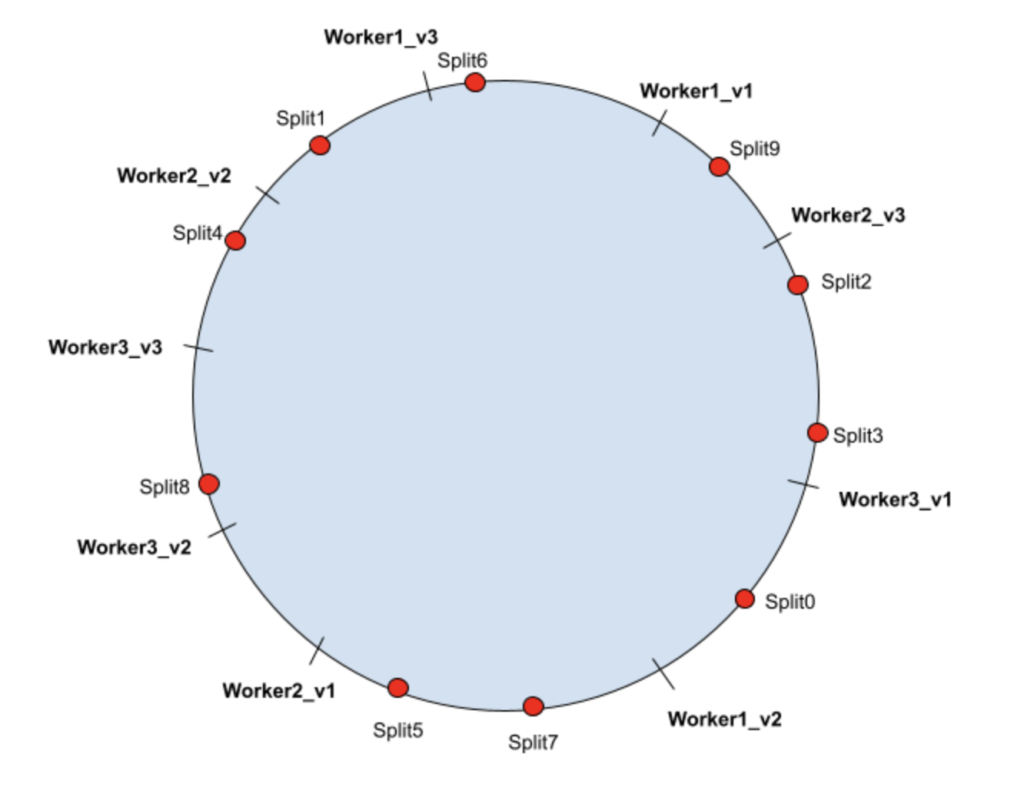
| Рабочий1 | Рабочий1_v1 | Сплит6 |
| | Рабочий1_v2 | Сплит0 |
| | Рабочий1_v3 | Сплит1 |
| Рабочий2 | Рабочий2_v1 | Сплит5, Сплит7 |
| | Рабочий2_v2 | Сплит4 |
| | Рабочий2_v3 | Сплит9 |
| Рабочий3 | Рабочий3_v1 | Сплит2, Сплит3 |
| | Рабочий3_v2 | |
| | Вокер3_v3 | Сплит8 |
По мере увеличения количества узлов в кольце хеширования хеш-пространство с большей вероятностью будет разделено равномерно.
В случае отказа физического узла все виртуальные узлы, соответствующие этому физическому узлу, будут перехэшированы. Но теперь вместо повторного хеширования всех разбиений на одном и том же узле они будут распределены по нескольким виртуальным узлам, таким образом сопоставляясь с несколькими физическими узлами, обеспечивая лучшую балансировку нагрузки.
Ниже показано, когда worker3 удаляется, Split2 и 3 повторно хешируются в worker2, а Split8 перехэшируются в worker1.
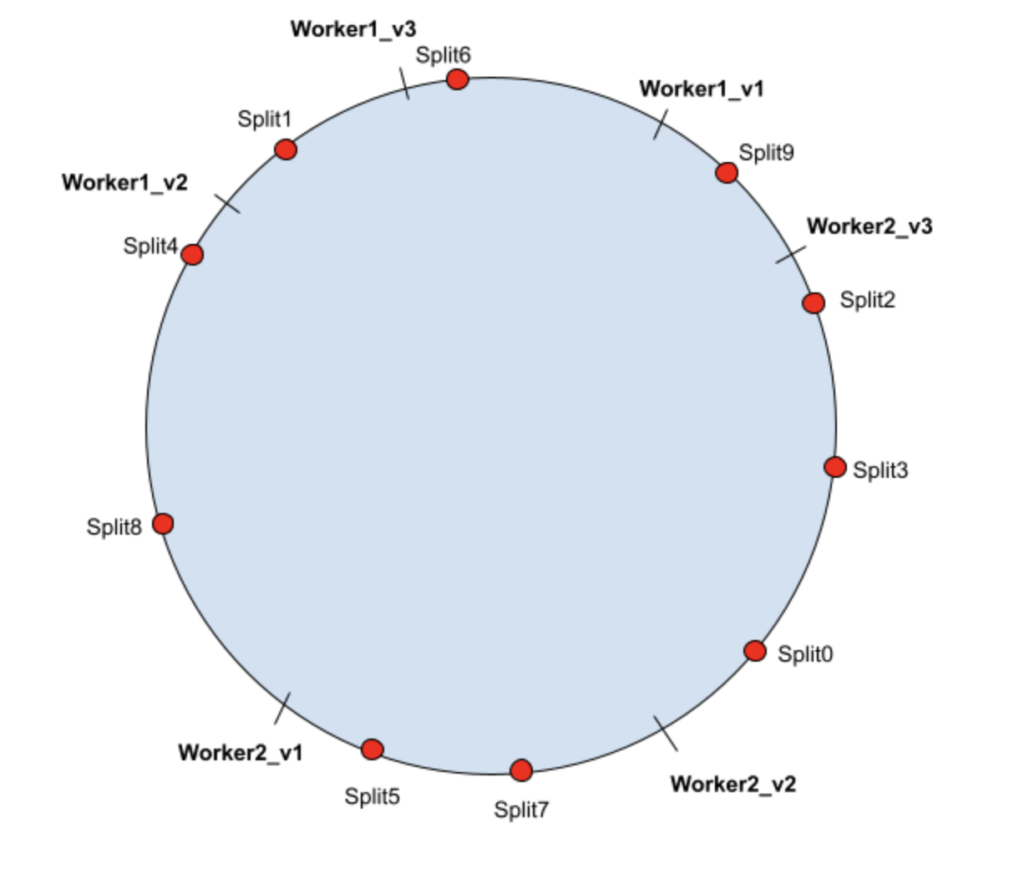
| Рабочий1 | Рабочий1_v1 | Сплит6 |
| | Рабочий1_v2 | Сплит4, Сплит8 |
| | Рабочий1_v3 | Сплит1 |
| Рабочий2 | Рабочий2_v1 | Сплит5, Сплит7 |
| | Рабочий2_v2 | Разделить0, Разделить2, Разделить3 |
| | Рабочий2_v3 | Сплит9 |
Как использовать последовательное хеширование в Presto?
В настоящее время это экспериментальная функция, которую мы недавно добавили в Presto. Не стесняйтесь обращаться к нам, если вы заинтересованы в тестировании или сотрудничестве.
Чтобы использовать эту функцию, сначала включите кэширование в Presto, следуя этой инструкции или этому руководству.
Убедитесь, что вы выбрали SOFT_AFFINITY в качестве политики планирования. В /catalog/hive.properties добавьте hive.node-selection-strategy=SOFT_AFFINITY.
Включите последовательное хеширование. В config.properties добавьте node-scheduler.node-selection-hash-strategy=CONSISTENT_HASHING.
Заключение
Как показано выше, последовательное хеширование может свести к минимуму влияние назначений рабочей нагрузки при добавлении или удалении узлов. Планирование рабочей нагрузки на основе согласованного хеширования может минимизировать влияние на частоту попаданий в кэш существующих узлов при изменении рабочих узлов кластера. Это делает последовательное кэширование лучшей стратегией для использования в ситуациях, когда размер кластера Presto будет увеличиваться и уменьшаться в соответствии с потребностями рабочей нагрузки, или в ситуациях, когда развертывание не имеет полного контроля над оборудованием, а рабочие могут время от времени перемещаться. .
В сообществе Alluxio мы постоянно улучшаем интеграцию между Alluxio и приложениями для работы с данными (например, Presto в этой статье) как с точки зрения функциональности, так и с точки зрения удобства использования. Благодаря внедрению согласованного хеширования в планировщике Presto Alluxio может лучше использовать потенциал мягкого сходства в Presto с более высокой локальностью данных и эффективностью кэширования, что может привести к повышению производительности и экономической эффективности. Мы продолжим вносить дальнейшие улучшения и оптимизации в экосистему данных.
- Впервые опубликовано [здесь] (https://www.alluxio.io/blog/using-consistent-hashing-in-presto-to-improve-caching-data-locality-in-dynamic-clusters/)*
Оригинал
🔥 Популярное на этой неделе
-
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27758)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)