

Сколько это стоит для самостоятельного ИИ? Я построил систему, чтобы узнать
13 августа 2025 г.То, что началось как обещание демократизированного доступа к ИИ через облачных провайдеров, превратилось в разочаровывающий опыт ухудшенной работы, агрессивной цензуры и непредсказуемых затрат. Для опытных пользователей ИИ решение все чаще заключается в самостоятельстве.
Скрытая стоимость производительности облачного искусственного искусства
Поставщики Cloud AI разработали тревожный шаблон: запуск с исключительной производительностью для привлечения подписчиков, а затем постепенно снижать качество обслуживания. Пользователи OpenAI сообщили, что GPT-4O теперь «реагирует очень быстро, но если контекст и инструкции игнорируются, чтобы обеспечить быстрые ответы, то инструмент не подходит». Это не изолировано-разработчики отмечают, что способность CHATGPT отслеживать изменения в нескольких файлах и рекомендовать модификации по всему проекту полностью исчезла. Виновник?Токеновая партия- метод, в котором поставщики группируют несколько запросов пользователей вместе на эффективность графического процессора, заставляя отдельные запросы ждать до 4x дольше при увеличении размеров партий.
Деградация производительности выходит за рамки простых задержек. Статическое партии заставляет все последовательности в партии, чтобы завершить вместе, что означает, что ваш быстрый запрос ждет чужого длительного поколения. Даже «непрерывное партия» вводит накладные расходы, которые замедляют отдельные запросы. Облачные провайдеры оптимизируют для общей пропускной способности за счет вашего опыта-компромисс, который имеет смысл для их бизнес-модели, но разрушает пользовательский опыт.
Цензура: когда безопасность становится непригодной для использования
Тестирование показывает, что Google Gemini отказывается отвечать 10 из 20 спорных, но законных вопросов - больше, чем любой конкурент. Заявки на выжившие в сексуальном насилии заблокированы как «небезопасной контент». Исторические разговоры ролевой игры внезапно перестают работать после обновлений. Приложения поддержки психического здоровья запускают фильтры безопасности. Claude's Antropic стал «пограничным бесполезным», согласно пользователям, разочарованным тяжелой цензурой, которая блокирует законные варианты использования.
Местное преимущество
Самостоятельный ИИ полностью устраняет эти разочарования. С помощью надлежащего оборудования локальный вывод достигает 1900+ токенов/секунд-10-100x быстрее, чем на первом времени, чем облачные сервисы. Вы поддерживаете полный контроль над версиями моделей, предотвращая нежелательные обновления, которые нарушают рабочие процессы. Никакие цензуры фильтры блокируют законное содержание. Никакие ограничения ставки прерывают вашу работу. Не удивительно, что счета из шипов использования. В течение пяти лет подписки Cloud стоят 1200 долларов США+ за базовый доступ и 10 раз больше для расширенных подписок. И цены по провайдерам искусственного интеллекта растут, а ограничения становятся более строгими и строгими, в то время как одноразовые инвестиции в оборудование обеспечивают неограниченное использование только с физическими аппаратными ограничениями на производительность.
Требования к аппаратному обеспечению: Создание мощности ИИ
Понимание размеров модели и квантования
Ключ к успеху самостоятельного управления заключается в сопоставлении моделей с вашими аппаратными возможностями. Современные методы квантования Сжатие моделей без значительной потери качества:
Что такое квантование?Квантование снижает точность весов модели от их первоначального представления с плавающей точкой до более низких форматов. Подумайте об этом, как сжатие изображения с высоким разрешением-вы обменяете некоторые детали для значительно меньших размеров файлов. В нейронных сетях это означает хранение каждого параметра, используя меньше бит, что напрямую уменьшает использование памяти и ускоряет вывод.
Почему квантование имеет значениеБез квантования даже скромные языковые модели были бы недоступны для большинства пользователей. Модель параметров 70B на полной точности требует 140 ГБ памяти - большинство потребительских графических процессоров. Квантование демократизирует ИИ, заставляя мощные модели, работающие на повседневном аппаратном обеспечении, обеспечивая локальное развертывание, снижение затрат на облако и улучшая скорость вывода с помощью более эффективных моделей доступа к памяти.
- FP16 (полная точность): Первоначальное качество модели, максимальные требования к памяти
- 8-битная квантование: ~ 50% снижение памяти, минимальное качество воздействия
- 4-битная квантование: ~ 75% снижение памяти, небольшой качественный компромисс
- 2-битная квантование: ~ 87,5% снижение памяти, заметное деградация качества
Для модели параметров 7B это переводится на 14 ГБ (FP16), 7 ГБ (8-бит), 3,5 ГБ (4-бит) или 1,75 ГБ (2-бит) требуемой памяти.
Популярные модели с открытым исходным кодом и их требования
Небольшие модели (параметры 1,5B-8B):
- Qwen3 4b/8b: Последнее поколение с гибридными режимами мышления. QWEN3-4B превосходит многие 72B-модели по задачам программирования. Требуется ~ 3-6 ГБ в 4-битной квантовании
- DeepSeek-R1 7b: Отличные возможности рассуждений, минимум 4 ГБ оперативной памяти
- Mistral Small 3.1 24b: Новейшая модель Apache 2.0 с мультимодальными возможностями, контекстным окном 128K и производительность 150 токенов/сек. Запускается на одном RTX 4090 или 32 ГБ MAC
Средние модели (параметры 14B-32B):
- GPT-OSS 20B: Первая открытая модель Openai с 2019 года, Apache 2.0 Licensed. Архитектура MOE с активными параметрами 3,6B обеспечивает производительность O3-Mini. Работает на RTX 4080 с 16 ГБ VRAM
- QWEN3 14B/32B: Плотные модели с возможностями режима мышления. QWEN3-14B соответствует производительности QWEN2.5-32B, а также более эффективно
- DeepSeek-R1 14b: Оптимально на RTX 3070 TI/4070
- Мишстрал маленький 3.2: Последнее обновление с улучшенными инструкциями, следующим и уменьшенным повторением
Большие модели (параметры 70B+):
- Лама 3.3 70b: ~ 35 ГБ в 4-битной квантовании, требуется двойной RTX 4090 или A100
- DeepSeek-R1 70b: 48 ГБ VRAM Рекомендуется, достижимо с 2x RTX 4090
- GPT-OSS 120B: Флагманская открытая модель Openai с 5,1B активными параметрами через 128-эксперт MOE. Сопоставление O4-Mini Performance, работает на одном H100 (80GB) или 2-4X RTX 3090S
- QWEN3-235B-A22B: Флагманская модель MOE с активными параметрами 22B, конкурентоспособная с O3-Mini
- DeepSeek-R1 671b: Гигант, требующий 480 ГБ+ VRAM или специализированные настройки
Специализированные модели кодирования:
Маленькие модели кодирования (1B-7B Активные параметры):
- QWEN3-CODER 30B-A3B: Moe Model только с 3,3B активными параметрами. Наземный контекст 256K (1 м с пряжей) для задач масштаба хранилища. Запускается на RTX 3060 12 ГБ в 4-битной квантовании
- QWEN3-CODER 30B-A3B-FP8: Официальная 8-битная квантование, поддерживающая 95%+ производительность. Требуется 15 ГБ VRAM, оптимальный для RTX 4070/3080
- USLOTH QWEN3-CODER 30B-A3B: Динамические количественные характеристики с фиксированным набором инструментов. Q4_K_M работает на 12 ГБ, Q4_K_XL на 18 ГБ с более высоким качеством
Большие модели кодирования (35b+ активные параметры):
- QWEN3-CODER 480B-A35B: Флагманская агентская модель с 35B активна через 160-эксперт MOE. Достигает 61,8% на SWE-Bench, сравнимо с Claude Sonnet 4. требует 8x H200 или 12x H100 при полной точности
- QWEN3-CODER 480B-A35B-FP8: Официальное 8-битное снижение памяти до 250 ГБ. Запускается на 4X H100 80 ГБ или 4x A100 80GB
- USLOTH QWEN3-CODER 480B-A35B: Q2_K_XL при 276 ГБ работает на 4X RTX 4090 + 180 ГБ ОЗУ. IQ1_M при 150 ГБ, осуществимый на 2x RTX 4090 + 100 ГБ ОЗУ
Аппаратные конфигурации по бюджету
Бюджетная сборка (~ 2000 долларов):
- AMD Ryzen 7 7700x процессор
- 64 ГБ DDR5-5600 ОЗУ
- PowerColor RX 7900 XT 20 ГБ или использованный RTX 3090
- Обрабатывает модели до 14b комфортно
Строительство производительности (~ 4000 долларов):
- Amd ryzen 9 7900x
- 128 ГБ DDR5-5600 ОЗУ
- RTX 4090 24 ГБ
- Эффективно выполняет модели 32B, меньшие модели 70B с разгрузкой
Профессиональная настройка (~ 8000 долларов):
- Двойные процессоры Xeon/Epyc
- 256 ГБ+ ОЗУ
- 2x RTX 4090 или RTX A6000
- Обрабатывает модели 70b на скорости производства
Параметры Mac:
- MacBook M1 Pro 36GB: Отлично для моделей 7B-14b, преимущество в объединенной памяти
- Mac Mini M4 64GB: Удобно с моделями 32B
- Mac Studio M3 Ultra 512GB: Ultimate Option-Runs Deepseek-R1 671b в 17-18 токенах/с за ~ 10 000 долларов США.
Альтернатива AMD EPYC:Для моделей сверхуровневых систем AMD EPYC предлагают исключительную ценность. Система ~ $ 2500 EPYC 7702 с 512GB-1TB DDR4 обеспечивает 3,5-8 токенов/с на DeepSeek-R1 671B, чем графические процессоры, но гораздо более доступные для моделей такого размера.
Сборка EPYC за 2000 долларов (настройка Digital SpacePort):Эта конфигурация может запустить DeepSeek-R1 671B при 3,5-4,25 токенах/второй:
- Процессор: AMD EPYC 7702 (64 ядра) - 650 долл. США или обновление до EPYC 7C13/7V13 - 599-735 долл. США.
- Материнская плата: MZ32 -AR0 (16 DIMM -слоты, поддержка 3200 МГц) - $ 500
- Память: 16x 32 ГБ DDR4-2400 ECC (512 ГБ) - 400 долл. США, или 16x 64 ГБ для 1 ТБ - 800 долл. США.
- Хранилище: 1 ТБ Samsung 980 Pro NVME - $ 75
- Охлаждение: Corsair H170i Elite Capellix XT - $ 170
- Пипс: 850 Вт (только процессор) или 1500 Вт (будущее расширение графического процессора)-80-150 долларов США
- Случай: Рамка с стойкой - 55 долларов США
Общая стоимость: ~ 2000 долл. США за 512 ГБ, ~ 2500 долл. США за конфигурацию 1 ТБ
Результаты производительности:
- DeepSeek-R1 671b Q4: 3,5-4,25 токенов/второй
- Контекст окна: 16K+ поддерживается
- Силовая рисунка: 60 Вт холостое время, 260 Вт загружено
- Пропускная способность памяти: Критическое-сбыточный DDR4-3200 значительно повышает производительность
Эта настройка доказывает, что массовые модели могут работать доступно в системах только для процессоров, что делает Frontier AI доступным без требований GPU. Возможности с двумя составами и массивная поддержка памяти делают EPYC идеальным для моделей, которые превышают ограничения VRAM GPU.
Источник:Digital Spaceport - Как запустить DeepSeek R1 671B полностью локально на сервере EPYC за 2000 долл. США
Настройка программного обеспечения: от установки до производства
Оллама: Фонд
Оллама стал де -факто стандартом для развертывания местной модели, предлагая простоту, не жертвуя властью.
Установка:
# Linux/macOS
curl -fsSL https://ollama.com/install.sh | sh
# Windows: Download installer from ollama.com/download
Основная конфигурация:
# Optimize for performance
export OLLAMA_HOST="0.0.0.0:11434" # Enable network access
export OLLAMA_MAX_LOADED_MODELS=3 # Concurrent models
export OLLAMA_NUM_PARALLEL=4 # Parallel requests
export OLLAMA_FLASH_ATTENTION=1 # Enable optimizations
export OLLAMA_KV_CACHE_TYPE="q8_0" # Quantized cache
# Download models
ollama pull qwen3:4b
ollama pull qwen3:8b
ollama pull mistral-small3.1
ollama pull deepseek-r1:7b
Запуск нескольких экземпляров:Для настройки с несколькими GPU запустите отдельные экземпляры Ollama:
# GPU 1
CUDA_VISIBLE_DEVICES=0 OLLAMA_HOST="0.0.0.0:11434" ollama serve
# GPU 2
CUDA_VISIBLE_DEVICES=1 OLLAMA_HOST="0.0.0.0:11435" ollama serve
Exo.labs: магия распределенного вывода
Exo.labs позволяет работать массивными моделями на нескольких устройствах - даже смешивая Macbook, ПК и малиновые PIS.
Установка:
git clone https://github.com/exo-explore/exo.git
cd exo
pip install -e .
Использование:Просто бегиexoна каждом устройстве в вашей сети. Они автоматически обнаруживают друг друга и распределяют вычисление модели. Настройка с 3X M4 Pro Mac достигает 108,8 токенов/секунд на Llama 3.2 3b-улучшение 2,2 раза по сравнению с однонадежими.
Варианты графического интерфейса
Откройте Webuiпредоставляет лучший опыт, похожий на Chatgpt:
docker run -d -p 3000:8080 --gpus=all \
-v ollama:/root/.ollama \
-v open-webui:/app/backend/data \
--name open-webui \
ghcr.io/open-webui/open-webui:ollama
Доступ кhttp://localhost:3000Для полнофункционального интерфейса с поддержкой RAG, многопользовательским управлением и системой плагинов.
GPT4ALLпредлагает самый простой опыт работы на рабочем столе:
- Скачать из
gpt4all.ioдля Windows, MacOS или Linux - Установка с одним щелчком с автоматическим обнаружением Олламы
- Встроенный модельный браузер и менеджер загрузки
- Идеально подходит для начинающих, которые хотят нативного настольного приложения
- Поддерживает локальный чат и плагины
AI Studioобеспечивает мощный интерфейс, ориентированный на разработку:
- Многомодель сравнения и тестирования
- Усовершенствованное инженерное рабочее пространство
- Управление и тестирование конечной точки API
- Аналитика производительности модели и сравнительный анализ
- Поддерживает Ollama, Localai и пользовательские бэкэнды
- Идеально подходит для разработчиков и исследователей ИИ
- Особенности включают в себя ветвление разговора, шаблоны быстрого
SillytavernПревосходство для творческих приложений и взаимодействия на основе персонажей, предлагая обширную настройку для ролевых сценариев и творческого письма.
Отдаленный доступ с хвостовым кремом: ваш ИИ везде
Одним из самых мощных аспектов самолета ИИ является возможность получить доступ к вашим моделям из любого места при сохранении полной конфиденциальности. Tailscale VPN делает это тривиально простым, создавая безопасную сеть сетки между всеми вашими устройствами.
Настройка хвостового крема для удаленного доступа к искусственному интеллекту
Установите Tailscale на вашем сервере ИИ:
# Linux/macOS
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up
# Windows: Download from tailscale.com/download
Настройте Ollama для доступа к сети:
# Set environment variable to listen on all interfaces
export OLLAMA_HOST="0.0.0.0:11434"
ollama serve
Установите хвост на клиентских устройствах(ноутбук, телефон, планшет) с использованием той же учетной записи. Все устройства автоматически появляются в вашей частной сети сетки с уникальными IP -адресами (обычно 100.x.x.x -диапазон).
Проверьте IP IP -адреса вашего сервера:
tailscale ip -4
# Example output: 100.123.45.67
Доступ с любого устройства на вашей хвостовой сети:
- Веб -интерфейс:
http://100.123.45.67:3000(Open Webui) - Конечная точка API:
http://100.123.45.67:11434/v1/chat/completions - Мобильные приложения: настроить конечную точку Ollama на IP Hailscale
Усовершенствованная конфигурация хвостового мастера
Включить маршрутизацию подсетиЧтобы получить доступ к всей вашей домашней сети:
# On AI server
sudo tailscale up --advertise-routes=192.168.1.0/24
# Replace with your actual subnet
Используйте подачу хвостаДля HTTPS с автоматическими сертификатами:
# Expose Open WebUI with HTTPS
tailscale serve https / http://localhost:3000
Это создает публичный URLhttps://your-machine.your-tailnet.ts.netДоступно только для вашей сети хвостового масштаба.
Настройка мобильного доступа
Для устройств iOS/Android:
- Установите приложение Tailscale из App Store/Play Store
- Войдите с той же учетной записью
- Установить совместимые приложения:
- ios: Enchanted, Mela или любой, совместимый с OpenAI
- Android: Приложение Ollama Android или веб -браузер
Настройте приложение для использования IP -адреса Tailscale:http://100.123.45.67:11434
Лучшие практики безопасности
Tailscale обеспечивает безопасность по умолчанию через свою зашифрованную сеть сетки - не требуется дополнительной конфигурации брандмауэра! Красота хвостового состава в том, что это:
- Автоматически шифруетВесь трафик с использованием проволочной платы
- Только разрешают аутентифицированные устройствав вашей сети
- Создает изолированные соединениячто полностью обходит ваш маршрутизатор
- Предотвращает несанкционированный доступиз общедоступного интернета
Поскольку трафик хвоста зашифрован и доступен только для ваших аутентифицированных устройств, ваш сервер OLLAMA остается совершенно частным, даже когда он удаленно доступен. Нет пересылки портов, нет настройки VPS, нет сложных правил брандмауэра-просто безопасные, прямые подключения к устройству к устройству.
С Tailscale ваш самостоятельный ИИ становится по-настоящему переносимым-с полной конфиденциальностью приобретайте ваши модели, будь то в кафе, путешествуете или работаете в другом месте. Зашифрованная сетчатая сеть гарантирует, что ваши разговоры с ИИ никогда не оставляют ваш контроль.
Агентные рабочие процессы: ИИ, который на самом деле работает
Гусь от блока
Гусь превращает ваши местные модели в автономные помощники по развитию, способные создавать целые проекты.
Установка:
curl -fsSL https://github.com/block/goose/releases/download/stable/download_cli.sh | bash
Конфигурация для Ollama:
goose configure
# Select: Configure Providers → Custom → Local
# Base URL: http://localhost:11434/v1
# Model: qwen3:8b
Goose превосходит миграцию кода, оптимизацию производительности, генерацию тестов и сложные рабочие процессы разработки. В отличие от простого завершения кода, он планирует и выполняет целые задачи разработки автономно.
Раздавить от очарования
Для энтузиастов терминалов Crush обеспечивает гламурный агент кодирования ИИ с глубокой интеграцией IDE.
Установка:
brew install charmbracelet/tap/crush # macOS/Linux
# or
npm install -g @charmland/crush
Конфигурация Олламы (.crush.json):
{
"providers": {
"ollama": {
"type": "openai",
"base_url": "http://localhost:11434/v1",
"api_key": "ollama",
"models": [{
"id": "qwen3:8b",
"name": "Qwen3 8B",
"context_window": 32768
}]
}
}
}
N8N AI Starter Kit
Для автоматизации визуальных рабочих процессов комплект самостоятельного размещения N8N объединяет все необходимое:
git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
cd self-hosted-ai-starter-kit
docker compose --profile gpu-nvidia up
Получить доступ к редактору визуальных рабочих процессов вhttp://localhost:5678/с 400+ интеграциями и предварительно построенными шаблонами ИИ.
Вывод корпоративного масштаба: настройка 50 миллионов токенов/час
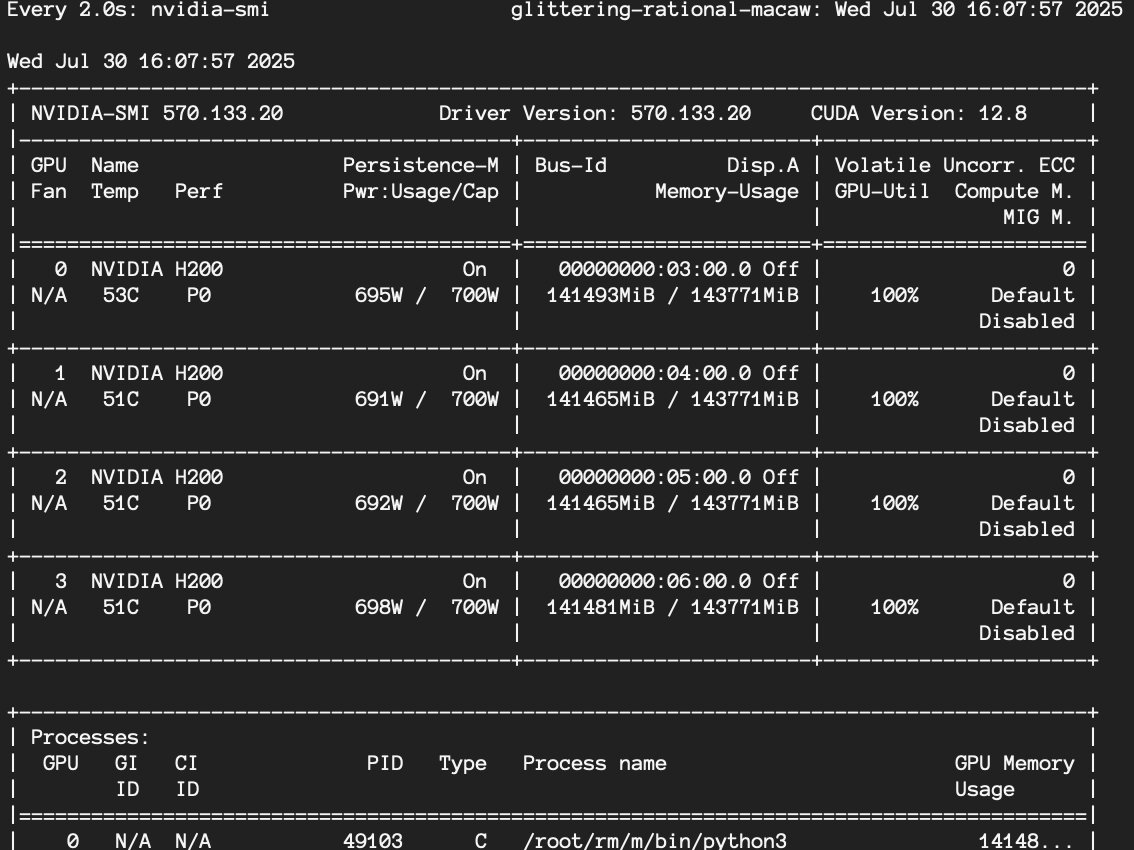
Для организаций, требующих экстремальных результатов, границы самостоятельного управления выходят далеко за рамки традиционных домашних серверов, например, @nisten setup на X.
- Модель: QWEN3-CODER-480B (параметры 480B, Active MoE Active) 35B)
- Аппаратное обеспечение: 4x Nvidia H200
- Выход:50 миллионов токенов/час (около 250 долларов в час, если использование сонета)
 Анализ затрат
Анализ затрат
Первоначальные инвестиции:
- Настройка бюджета: ~ 2000 долларов
- Настройка производительности: ~ 4000 долларов
- Профессиональная настройка: ~ 9000 долларов
Эксплуатационные расходы:
- Электричество: 50-200 долл. США/месяц
- Ноль платы за API
- Нет пределов использования
- Полная предсказуемость затрат
Далее далее:Тяжелые пользователи возмещают инвестиции через 3-6 месяцев. Умеренные пользователи ломаются даже в течение года. Свобода от ограничений по ставке, цензуры и деградации производительности? Бесценный.
Заключение
Самостоятельный ИИ развивался маленьким с одним графическим процессором и олламой. Экспериментируйте с разными моделями. Добавить агентские возможности. Масштаб по мере необходимости. Самое главное, наслаждайтесь свободой ИИ, которая работает точно так же, как вам нужно - нет компромиссов, никакой цензуры, без сюрпризов. Перейти от экспериментального любопытства к практической необходимости. Сочетание мощных моделей с открытым исходным кодом, зрелых программных экосистем и доступного оборудования создает беспрецедентную возможность для независимости ИИ. Независимо от того, разочарованы ли вы облачными ограничениями, обеспокоены конфиденциальностью или просто хотите последовательную производительность, путь к самостоятельному ИИ ясен, чем когда-либо.
Ссылки на соответствующие статьи о самостоятельстве:
- Инго Эйххорст и его прекрасная установка, фотография которой я использовал для этой статьи:https://ingoeichhorst.medium.com/building-awall-shoundation-andwallet-Friendy-ml-rig-0683a7094704
- Digital Spaceport Epyc Rig:https://digitalspaceport.com/how-to-cun-deepseek-r1-671b-fullocally-on-fycy-pyc-rig/
- Покажите мне свою тренаж для установки на локаллама subreddit:https://www.reddit.com/r/localllama/comments/1fqwler/show_me_your_ai_rig/
- Бен Ай Homelab:https://benarent.co.uk/blog/ai-homelab/
- Exo Labs Cluster с 5 Mac Studio:https://www.youtube.com/watch?v=JU0NDY2KWLW
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)