
Как тип модуля и эффективность ранга
17 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
3 Экспериментальная настройка и 3,1 наборов данных для продолжения предварительной подготовки (CPT) и создания инструкций (IFT)
3.2 Измерение обучения с помощью кодирования и математических показателей (оценка целевой области)
3.3 Забыть метрики (оценка доменов источника)
4 Результаты
4.1 Lora Underperforms Полное создание в программировании и математических задачах
4.2 Лора забывает меньше, чем полное создание
4.3 Обмен на обучение
4.4 Свойства регуляризации Лоры
4.5 Полная производительность на коде и математике не изучает низкие возмущения
4.6 Практические выводы для оптимальной настройки LORA
5 Связанная работа
6 Обсуждение
7 Заключение и ссылки
Приложение
А. Экспериментальная установка
B. Поиски скорости обучения
C. Обучающие наборы данных
D. Теоретическая эффективность памяти с LORA для однократных и мульти-GPU настройки
4.5 Полная производительность на коде и математике не изучает низкие возмущения

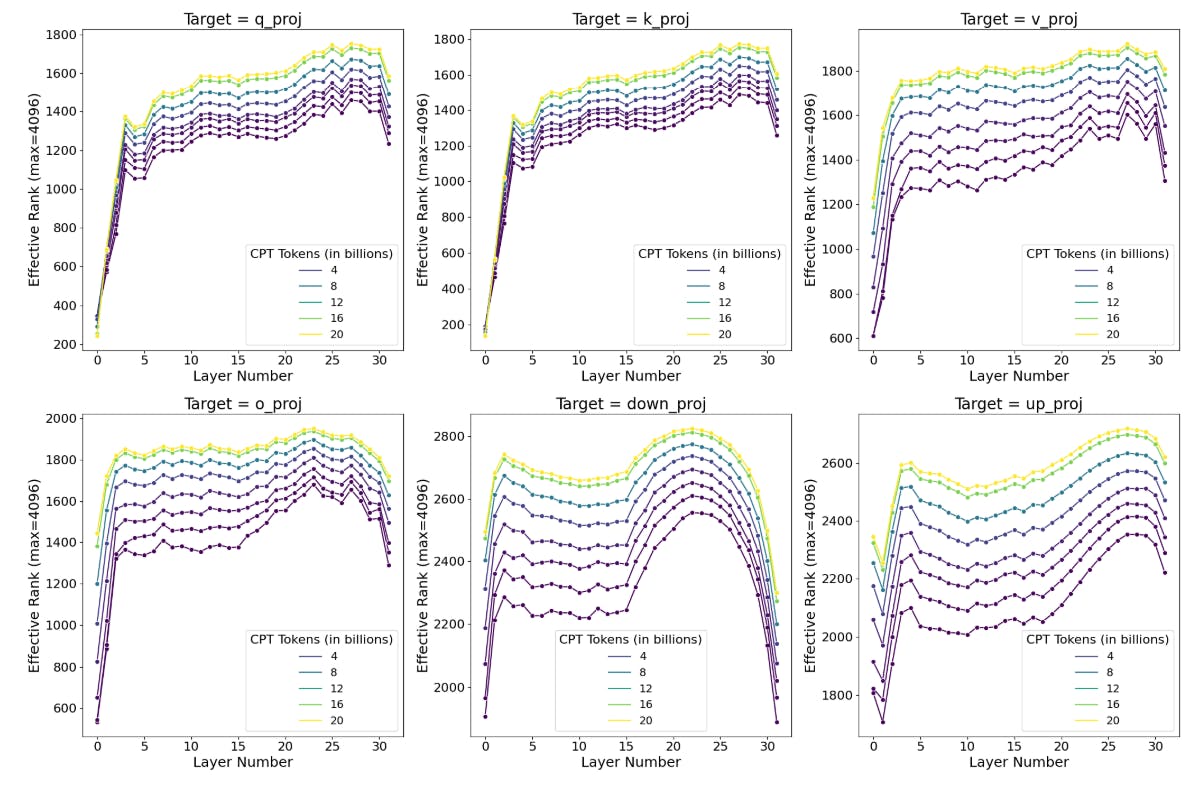
Далее мы спрашиваем, когда во время тренировки возмущение становится высоким рангом, и варьируется ли оно между типами модулей и слоями. Мы оцениваем ранг, необходимый для объяснения 90% дисперсии в матрице. Результаты показаны на рисунке 7. Мы обнаруживаем, что: (1) самая ранняя контрольная точка в 0,25B токенах CPT демонстрирует ∆-матрицы с рангом, который в 10-100 раз больше, чем типичные ранги LORA; (2) ранг ∆ увеличивается при обучении по большему количеству данных; (3) модули MLP имеют более высокие ранги по сравнению с модулями внимания; (4) Первые и последние слои, по -видимому, ниже ранга по сравнению со средними слоями.
4.6 Практические выводы для оптимальной настройки LORA
Хотя оптимизация гиперпараметров Lora не закрывает пробелы с полным созданием, некоторые варианты гиперпараматора значительно более эффективны, чем другие, как мы выделяем ниже.
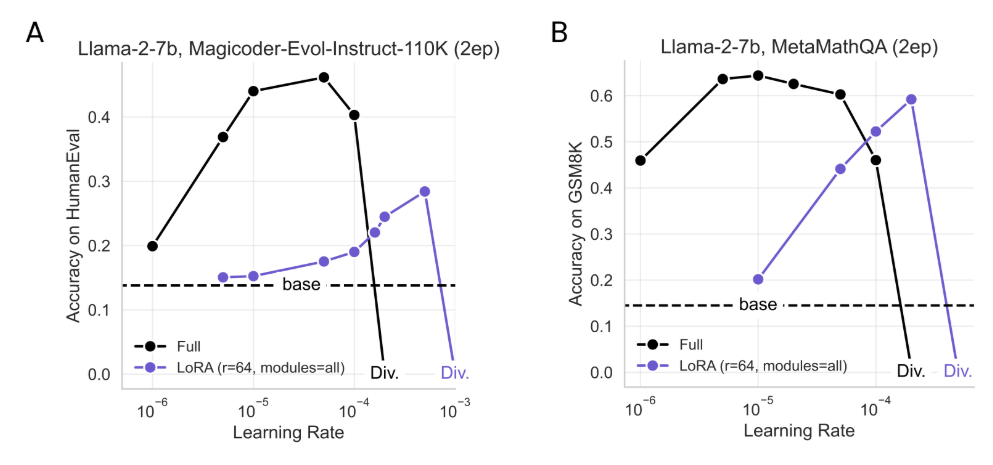
4.6.1 Лора очень чувствительна к ставкам обучения

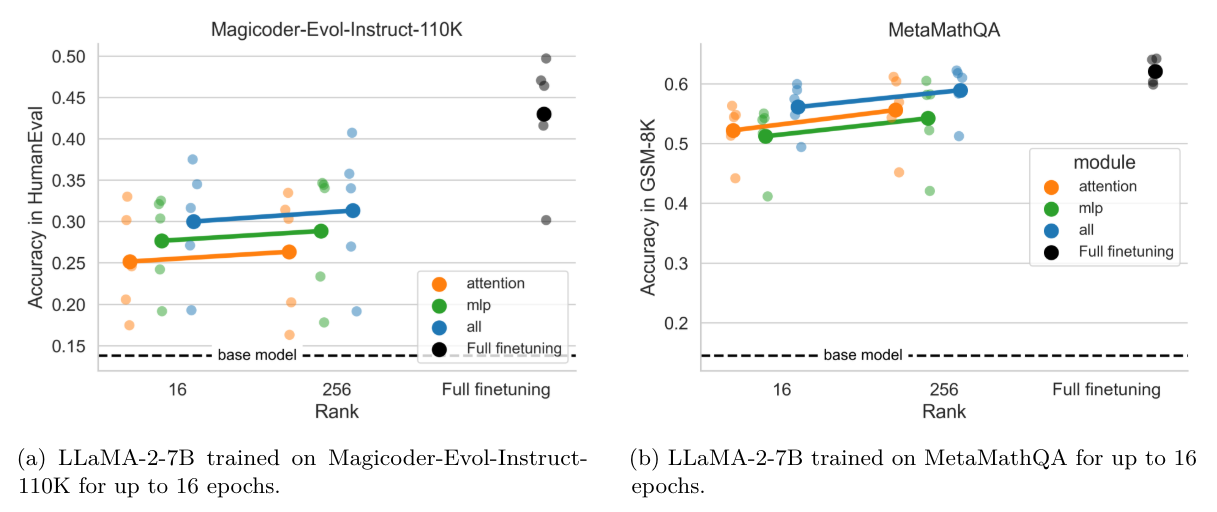
4.6.2 Выбор целевых модулей значит больше, чем ранга
С лучшими показателями обучения, на рис. 9 мы приступаем к анализу эффекта ранга (r = 16, 256) и целевых модулей. Мы находим, что «все»> «MLP»> «Внимание» и что, хотя эффекты ранга более тонкие, r = 256> r = 16. Поэтому мы заключаем, что нацеливание на модули «все» с относительно низким рангом (например, R = 16) обеспечивает хороший компромисс между производительностью и точностью.
В целом, мы рекомендуем использовать LORA для IFT, а не CPT; определение самого высокого уровня обучения, которая обеспечивает стабильную подготовку; нацеливание на «все» модули и выбор ранга в соответствии с ограничениями памяти, причем 16 - хороший выбор; Изучение обучения как минимум для четырех эпох.
Авторы:
(1) Дэн Бидерман, Колумбийский университет и Databricks Mosaic AI (db3236@columbia.edu);
(2) Хосе Гонсалес Ортис, DataBricks Mosaic AI (j.gonzalez@databricks.com);
(3) Джейкоб Портес, DataBricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, DataBricks Mosaic AI (mansheej.paul@databricks.com);
(5) Филип Грингард, Колумбийский университет (pg2118@columbia.edu);
(6) Коннор Дженнингс, DataBricks Mosaic AI (connor.jennings@databricks.com);
(7) Даниэль Кинг, DataBricks Mosaic AI (daniel.king@databricks.com);
(8) Сэм Хейвенс, DataBricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, DataBricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Джонатан Франкл, DataBricks Mosaic AI (jfrankle@databricks.com);
(11) Коди Блакни, DataBricks Mosaic AI (Cody.blakeney);
(12) Джон П. Каннингем, Колумбийский университет (jpc2181@columbia.edu).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)