
Как я создал систему оповещения о комнатных растениях с помощью ksqlDB на Apache Kafka
10 февраля 2023 г.Еще в 2020 году многие люди обзавелись хобби в связи с пандемией — тем, чем они могли заниматься в полную силу, пока были ограничены карантином. Я выбрал комнатные растения.
До пандемии у меня уже было что-то вроде небольшой детской в моем доме. Честно говоря, даже тогда уход за каждым растением был огромным трудом. Посмотреть, кого из них нужно полить, убедиться, что все они получают достаточно солнечного света, поговорить с ними… #justHouseplantThings.

Войдите в Apache Kafka®. Ну, действительно, введите мое желание заняться еще одним хобби: аппаратными проектами.
Мне всегда нужен был предлог для создания проекта с использованием Raspberry Pi, и я знал, что это мой шанс. Я бы построил систему, которая могла бы следить за моими растениями и предупреждать меня только тогда, когда им нужно внимание, а не через мгновение. И я бы использовал Kafka в качестве основы.
На самом деле это оказался очень полезный проект. Это решило очень реальную проблему, которая у меня была, и дало мне возможность совместить мою одержимость комнатными растениями с моим зудящим желанием, наконец, использовать Kafka дома. Все это было аккуратно упаковано в простой и доступный аппаратный проект, который каждый мог реализовать самостоятельно.
Если вы похожи на меня, и у вас есть проблема с комнатными растениями, которую можно решить, только автоматизировав свой дом, или даже если вы совсем не похожи на меня, но все же хотите заняться крутым проектом, этот пост в блоге для вас. .
Засучим рукава и запачкаем руки!
Посев семян
Сначала я решил выяснить, чего хочу добиться от этого проекта. На первом этапе системы возможность отслеживать уровень влажности моих растений и получать оповещения о них была бы очень полезна — в конце концов, самой трудоемкой частью ухода за моими растениями было решение, о каких из них нужно заботиться. Если бы эта система могла справиться с этим процессом принятия решений, я бы сэкономил кучу времени!
На высоком уровне это базовая система, которую я себе представлял:
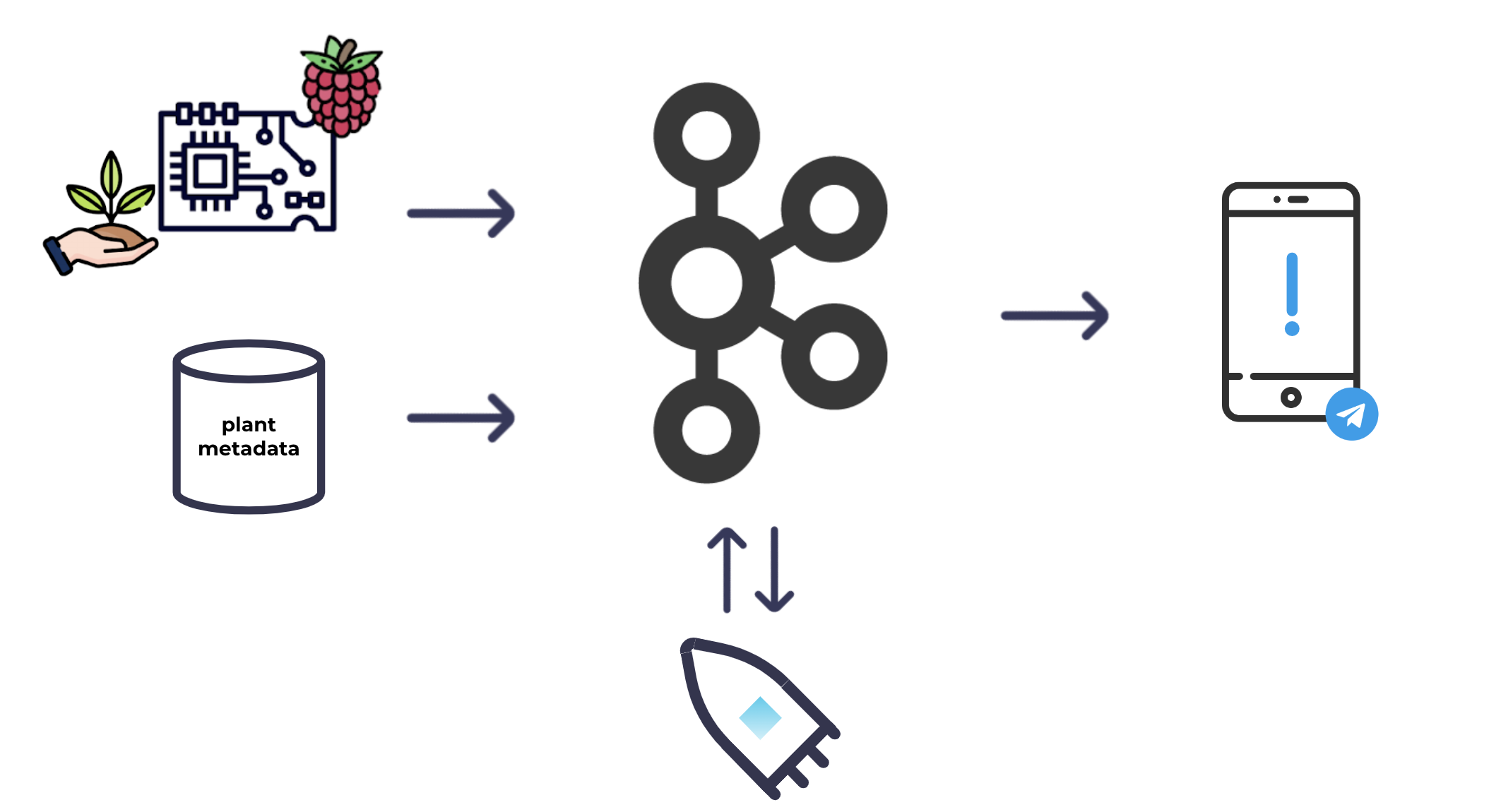
Я бы поместил несколько датчиков влажности в почву и подключил их к Raspberry Pi; Тогда я мог бы регулярно снимать показания влажности и закидывать их в Кафку. В дополнение к показаниям влажности мне также нужны были некоторые метаданные для каждого растения, чтобы решить, какие растения нужно поливать. Я бы также ввел метаданные в Kafka. Имея оба набора данных в Kafka, я мог затем использовать потоковую обработку, чтобы комбинировать и обогащать наборы данных друг с другом и вычислять, какие растения нужно поливать. Оттуда я мог вызвать оповещение.
Установив набор основных требований, я приступил к этапу сборки и оборудования.
Выслеживание вещей
Как и многие уважающие себя инженеры, я начал работу над аппаратным обеспечением с тонны поиска в Google. Я знал, что все элементы существуют для того, чтобы сделать этот проект успешным, но, поскольку я впервые работал с физическими компонентами, я хотел убедиться, что точно знаю, во что ввязываюсь.
Основная цель системы мониторинга заключалась в том, чтобы сообщить мне, когда растения нужно поливать, поэтому, очевидно, мне нужен был какой-то датчик влажности. Я узнал, что датчики влажности почвы бывают разных форм и размеров, доступны в виде аналоговых или цифровых компонентов и различаются по способу измерения влажности. В конце концов, я остановился на этих емкостных датчиках I2C. Они казались отличным вариантом для тех, кто только начинает работать с аппаратным обеспечением: как емкостные датчики они прослужат дольше, чем резистивные, им не требуется аналого-цифровое преобразование, и они будут более или менее легко подключаемыми. играть. Кроме того, они предлагали бесплатное измерение температуры.
Кроме того: для тех, кому любопытно, I2C означает Inter-Integrated Circuit. Каждый из этих датчиков обменивается данными по уникальному адресу; поэтому, чтобы получать данные с каждого датчика, мне нужно установить и отслеживать уникальный адрес для каждого датчика, который я использую, — об этом нужно помнить на будущее.
Выбор датчиков был самой большой частью моей физической подготовки. Все, что оставалось сделать в плане аппаратного обеспечения, — это заполучить Raspberry Pi и несколько единиц оборудования. Затем я смог приступить к созданию системы.
Я использовал следующие компоненты:
- Raspberry Pi 4, модель B
- Макетная плата половинного размера
- Емкостные датчики влажности почвы
- Комплект соединителя шага JST
- 4-жильный ленточный провод
- Обжимные клещи, клещи для зачистки проводов, припой, паяльник (все это я нашел в своем гараже)

От земли вверх…
Хотя я хотел, чтобы этот проект был простым и удобным для новичков, я также хотел бросить себе вызов и сделать как можно больше проводки и пайки. Чтобы почтить память тех, кто был до меня, я отправился в это сборочное путешествие с проводами, обжимным инструментом и мечтой. . Первым шагом было подготовить достаточно ленточных проводов для подключения четырех датчиков к макетной плате, а также для подключения макетной платы к моему Raspberry Pi. Чтобы обеспечить расстояние между компонентами в установке, я подготовил 24-дюймовые отрезки. Каждый провод нужно было зачистить, обжать и подключить либо к разъему JST (для проводов, соединяющих датчики с макетной платой), либо к розетке (для подключения к самой Raspberry Pi). Но, конечно, если вы хотите сэкономить время, усилия и слезы, я бы порекомендовал вам не обжимать провода самостоятельно, а вместо этого заранее приобрести готовые провода.
Кроме того: учитывая количество комнатных растений, которыми я владею, четыре датчика могут показаться сколь угодно малыми для использования в моей настройке мониторинга. Как указывалось ранее, поскольку эти датчики являются устройствами I2C, любая информация, которую они передают, будет отправляться с использованием уникального адреса. Тем не менее, датчики влажности почвы, которые я купил, поставляются с одним и тем же адресом по умолчанию, что проблематично для таких установок, когда вы хотите использовать несколько одинаковых устройств. Есть два основных способа обойти это. Первый вариант зависит от самого устройства. У моего конкретного датчика было две перемычки адреса I2C сзади, и пайка любой их комбинации означала, что я мог изменить адрес I2C в диапазоне от 0x36 до 0x39. Всего у меня может быть четыре уникальных адреса, следовательно, четыре датчика, которые я использую в окончательной настройке. Если на устройствах отсутствуют физические средства для изменения адресов, второй вариант — перенаправить информацию и настроить прокси-адреса с помощью мультиплекса. Учитывая, что я новичок в аппаратном обеспечении, я чувствовал, что это выходит за рамки этого конкретного проекта.
Подготовив провода для подключения датчиков к Raspberry Pi, я убедился, что все настроено правильно, с помощью тестировать скрипт Python для сбора показаний с одного датчика. Для большей уверенности я таким же образом протестировал оставшиеся три датчика. И именно на этом этапе я из первых рук узнал, как перекрещенные провода влияют на электронные компоненты… и насколько сложно устранить эти проблемы.
Когда проводка наконец-то пришла в рабочее состояние, я смог подключить все датчики к Raspberry Pi. Все датчики должны быть подключены к одним и тем же контактам (GND, 3V3, SDA и SCL) на Raspberry Pi. Каждый датчик имеет уникальный адрес I2C, поэтому, хотя все они обмениваются данными по одним и тем же проводам, я все равно могу получать данные от определенных датчиков, используя их адрес. Все, что мне нужно было сделать, это подключить каждый датчик к макетной плате, а затем подключить макетную плату к Raspberry Pi. Для этого я использовал немного остатков проволоки и соединил столбики макетной платы с помощью припоя. Затем я припаял разъемы JST непосредственно к макетной плате, чтобы можно было легко подключить датчики.
Подключив макетную плату к Raspberry Pi, вставив датчики в четыре растения и подтвердив с помощью тестового сценария, что я могу считывать данные со всех датчиков, я мог начать работу по созданию данных в Kafka.
Настоящие данные о тимьяне
С настройкой Raspberry Pi и всеми датчиками влажности, работающими должным образом, пришло время подключить Kafka, чтобы начать потоковую передачу данных.
Как и следовало ожидать, мне понадобился кластер Kafka, прежде чем я мог записывать какие-либо данные в Kafka. Желая сделать программный компонент этого проекта как можно более легким и простым в настройке, я решил использовать Confluent Cloud в качестве поставщика Kafka. Это означало, что мне не нужно было настраивать какую-либо инфраструктуру или управлять ею, а мой кластер Kafka был готов в течение нескольких минут после его настройки.
Также стоит отметить, почему я решил использовать Kafka для этого проекта, особенно учитывая, что MQTT является более или менее стандартом де-факто для потоковой передачи данных IoT с датчиков. И Kafka, и MQTT созданы для обмена сообщениями в стиле pub/sub, поэтому в этом отношении они похожи. Но если вы планируете создать проект потоковой передачи данных, такой как этот, MQTT не подойдет. Вам нужна другая технология, такая как Kafka, для обработки потоковой передачи, сохранения данных и любых последующих интеграций. Суть в том, что MQTT и Kafka очень хорошо работают вместе. В дополнение к Kafka я определенно мог бы использовать MQTT для IoT-компонента моего проекта. Вместо этого я решил работать напрямую с производителем Python над Raspberry Pi. Тем не менее, если вы хотите использовать MQTT и Kafka для любого проекта, вдохновленного IoT, будьте уверены, что вы все еще можете передавать свои данные MQTT в Kafka с помощью MQTT. Коннектор источника Kafka.
Отсеивание данных
Прежде чем привести какие-либо данные в действие, я сделал шаг назад, чтобы решить, как я хочу структурировать сообщения в моей теме Kafka. Специально для таких хакерских проектов, как этот, легко начать загружать данные в тему Kafka, не беспокоясь ни о чем, но важно знать, как вы будете структурировать свои данные по темам, какой ключ вы будете использовать и данные. вводит в поля.
Итак, начнем с тем. Как они будут выглядеть? Датчики могли регистрировать влажность и температуру — следует ли записывать эти показания в одну тему или в несколько? Поскольку показания влажности и температуры считывались датчиком растения одновременно, я сохранил их вместе в одном сообщении Kafka. Вместе эти две части информации составили показания растений для целей этого проекта. Все это было бы в одной теме для чтения.
В дополнение к данным датчика мне нужна тема для хранения метаданных комнатных растений, включая тип растения, за которым следит датчик, а также границы его температуры и влажности. Эта информация будет использоваться на этапе обработки данных, чтобы определить, когда показания должны вызвать предупреждение.
Я создал две темы: комнатные растения-показания и комнатные растения-метаданные. Сколько разделов я должен использовать? Для обеих тем я решил использовать количество разделов по умолчанию в Confluent Cloud, которое на момент написания статьи составляло шесть. Это был правильный номер? Ну да и нет. В этом случае из-за небольшого объема данных, с которыми я имею дело, шесть разделов на тему могут быть излишними, но в случае, если я позже расширим этот проект на большее количество заводов, будет хорошо иметь шесть разделов. .
Помимо разделов, еще одним важным параметром конфигурации, на который следует обратить внимание, является сжатие журнала, которое я включил в теме комнатных растений. В отличие от потока событий «чтения», тема «метаданные» содержит справочные данные или метаданные. Сохраняя его в сжатой теме, вы гарантируете, что данные никогда не устареют, и у вас всегда будет доступ к последнему известному значению для данного ключа (ключ, если вы помните, является уникальным идентификатором для каждого комнатного растения).
Основываясь на вышеизложенном, я написал две схемы Avro как для показаний, так и для метаданных комнатного растения (здесь они сокращены для удобства чтения).
Схема чтения
{
"doc": "Houseplant reading taken from sensors.",
"fields": [
{"name": "plant_id", "type": "int"},
{"name": "timestamp", "logicalType": "timestamp-millis", "type": "long"},
{"name": "moisture", "type": "float"},
{"name": "temperature", "type": "float"}
],
"name": "reading",
"namespace": "com.houseplants",
"type": "record"
}
Схема метаданных комнатного растения
{
"doc": "Houseplant metadata.",
"fields": [
{"name": "plant_id", "type": "int"},
{"name": "scientific_name", "type": "string"},
{"name": "common_name", "type": "string"},
{"name": "given_name", "type": "string"},
{"name": "temperature_threshold_low", "type": "float"},
{"name": "temperature_threshold_high", "type": "float"},
{"name": "moisture_threshold_low", "type": "float"},
{"name": "moisture_threshold_high", "type": "float"}
],
"name": "houseplant",
"namespace": "com.houseplants",
"type": "record"
}
Если вы использовали Kafka раньше, вы знаете, что наличие тем и знание того, как выглядят значения ваших сообщений, — это только первый шаг. Не менее важно знать, какой ключ будет у каждого сообщения. Что касается показаний и метаданных, я спросил себя, каким будет экземпляр каждого из этих наборов данных, поскольку именно экземпляр объекта должен формировать основу ключа в Kafka. Поскольку показания берутся для каждого растения, а метаданные назначаются для каждого растения, экземпляр объекта обоих наборов данных был отдельным растением. Я решил, что логическим ключом обеих тем будет завод. Я бы присвоил числовой идентификатор каждому растению и сделал бы этот номер ключом как к сообщениям о показаниях, так и к сообщениям метаданных.
Так что с немного самодовольным чувством удовлетворения, которое приходит от осознания того, что я все делаю правильно, я мог обратить свое внимание на потоковую передачу данных с моих датчиков в темы Kafka.
Обработка сообщений
Я хотел начать отправлять данные с датчиков в Kafka. Первым шагом была установка библиотеки Python confluent-kafka на Raspberry Pi. Оттуда я написал скрипт Python для захвата показаний моих датчиков и создания данные в Кафке.
Вы бы поверили, если бы я сказал вам, что это было так просто? С помощью всего пары строк кода данные моего датчика записывались и сохранялись в теме Kafka для использования в последующей аналитике. У меня до сих пор кружится голова при одной мысли об этом.
С показаниями датчиков в Kafka мне теперь понадобились метаданные комнатных растений, чтобы проводить любой последующий анализ. В типичных конвейерах данных такого рода данные будут находиться в реляционной базе данных или каком-либо другом хранилище данных и будут приниматься с помощью Kafka Connect и множества доступных для него соединителей.
Вместо того, чтобы создавать собственную внешнюю базу данных, я решил использовать Kafka в качестве уровня постоянного хранилища для своих метаданных. Имея метаданные всего для нескольких растений, я вручную записал данные прямо в Kafka, используя другой скрипт Python< /а>.
Корень проблемы
Мои данные находятся в Kafka; теперь пришло время действительно испачкать руки. Но сначала давайте вернемся к тому, чего я хотел достичь с помощью этого проекта. Общая цель состоит в том, чтобы отправить предупреждение, когда мои растения имеют низкие показания влажности, которые указывают на то, что их необходимо полить. Я могу использовать потоковую обработку, чтобы обогатить данные показаний метаданными, а затем вычислить новый поток данных для управления оповещениями.
Я решил использовать ksqlDB для этапа обработки данных этого конвейера, чтобы обрабатывать данные с минимальным кодированием. В сочетании с Confluent Cloud ksqlDB легко настроить и использовать — вы просто предоставляете контекст приложения и пишете простой SQL, чтобы начать загрузку и обработку данных.
Определение входных данных
Прежде чем приступить к обработке данных, мне нужно было объявить свои наборы данных в приложении ksqlDB, чтобы с ними можно было работать. Для этого мне сначала нужно было решить, какой из двух первоклассных объектов ksqlDB мои данные должны быть представлены как TABLE или STREAM, а затем использовать CREATE , чтобы указать на существующие темы Kafka.
Данные о показаниях комнатных растений представлены в ksqlDB как STREAM — в основном точно так же, как тема Kafka (последовательность неизменяемых событий только для добавления), но также со схемой. Довольно удобно, что я уже спроектировал и объявил схему ранее, и ksqlDB может получить ее непосредственно из реестра схем:
CREATE STREAM houseplant_readings (
id STRING KEY
) WITH (
kafka_topic='houseplant-readings',
format='AVRO',
partitions=4
);
С потоком, созданным по теме Kafka, мы можем использовать стандартный SQL для запроса и фильтрации для изучения данных с помощью простого оператора, подобного этому:
SELECT
plant_id,
moisture
FROM HOUSEPLANT_READINGS
EMIT CHANGES;
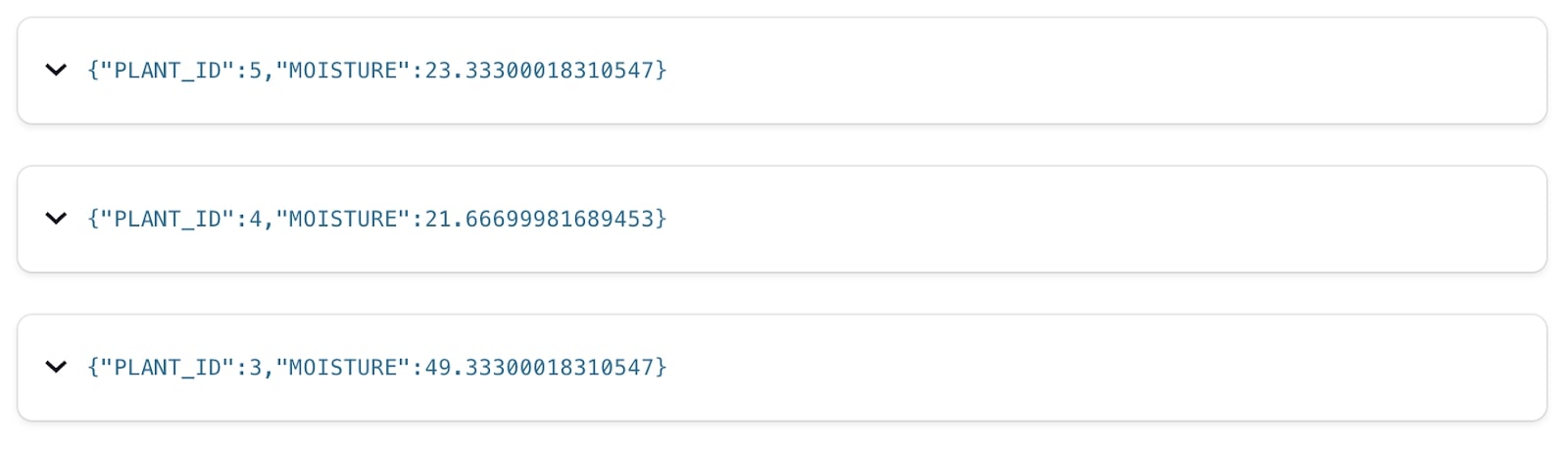
Метаданные комнатных растений требуют чуть большего внимания. Хотя он хранится как тема Kafka (точно так же, как и данные чтения), логически это другой тип данных — его состояние. У каждого растения есть имя, местонахождение и так далее. Мы сохраняем его в сжатом топике Kafka и представляем в ksqlDB как TABLE. Таблица, как и в обычной СУБД, сообщает нам текущее состояние данного ключа. Обратите внимание, что хотя ksqlDB берет здесь саму схему из реестра схем, нам нужно явно объявить, какое поле представляет первичный ключ таблицы.
CREATE TABLE houseplant_metadata (
id INTEGER PRIMARY KEY
) WITH (
kafka_topic='houseplant-metadata',
format='AVRO',
partitions=4
);
Дополнить данные
Поскольку оба набора данных зарегистрированы в моем приложении ksqlDB, следующим шагом будет обогащение houseplant_readings метаданными, содержащимися в таблице roomplants. Это создает новый поток (подкрепленный темой Kafka) как с чтением, так и с метаданными для связанного растения:
Запрос на обогащение будет выглядеть примерно так:
CREATE STREAM houseplant_readings_enriched WITH (
kafka_topic='houseplant-readings-enriched',
format='AVRO',
partitions=4
) AS
SELECT
r.id AS plant_id,
r.timestamp AS ts,
r.moisture AS moisture,
r.temperature AS temperature,
h.scientific_name AS scientific_name,
h.common_name AS common_name,
h.given_name AS given_name,
h.temperature_low AS temperature_low,
h.temperature_high AS temperature_high,
h.moisture_low AS moisture_low,
h.moisture_high AS moisture_high
FROM houseplant_readings AS r
LEFT OUTER JOIN houseplants AS h
ON houseplant_readings.id = houseplants.id
PARTITION BY r.id EMIT CHANGES;
И вывод этого запроса будет примерно таким:

Создание оповещений о потоке событий
Вспоминая начало этой статьи, вы помните, что весь смысл всего этого заключался в том, чтобы сказать мне, когда нужно полить растение. У нас есть поток показаний влажности (и температуры), и у нас есть таблица, которая сообщает нам пороговое значение, при котором уровень влажности каждого растения может указывать на то, что ему нужен полив. Но как мне определить, когда отправлять предупреждение о низком уровне влажности? И как часто я их отправляю?
Пытаясь ответить на эти вопросы, я заметил несколько особенностей своих датчиков и данных, которые они генерировали. Прежде всего, я собираю данные с пятисекундными интервалами. Если бы мне нужно было отправлять оповещения о каждом показателе низкой влажности, я бы завалил свой телефон оповещениями — это бесполезно. Я бы предпочел получать оповещения не чаще одного раза в час. Второе, что я понял, просматривая свои данные, это то, что датчики не были идеальными — я регулярно видел ложно низкие или ложно высокие показания, хотя со временем общая тенденция заключалась в том, что уровень влажности растений снижался.
Объединив эти два наблюдения, я решил, что в течение данного 1-часового периода, вероятно, будет достаточно отправить предупреждение, если я увижу 20-минутные показания низкой влажности. При одном чтении каждые 5 секунд это 720 чтений в час, и… немного подсчитав, это означает, что перед отправкой оповещения мне нужно увидеть 240 низких значений за 1 час.
Теперь мы создадим новый поток, который будет содержать не более одного события для каждого растения в течение 1 часа. Я достиг этого, написав следующий запрос:
CREATE TABLE houseplant_low_readings WITH (
kafka_topic='houseplant-low-readings',
format='AVRO',
partitions=4
) AS
SELECT
plant_id,
given_name,
common_name,
scientific_name,
CONCAT(given_name, ' the ', common_name, ' (', scientific_name, ') is looking pretty dry...') AS message,
COUNT(*) AS low_reading_count
FROM houseplant_readings_enriched
WINDOW TUMBLING (SIZE 1 HOURS, GRACE PERIOD 30 MINUTES)
WHERE moisture < moisture_low GROUP BY plant_id, given_name, common_name, scientific_name HAVING COUNT(*) > 240
EMIT FINAL;
Во-первых, вы заметите агрегацию в оконном режиме. . Этот запрос работает с неперекрывающимися окнами продолжительностью 1 час, что позволяет мне агрегировать данные по идентификатору завода в заданном окне. Довольно просто.
Я специально фильтрую и подсчитываю строки в расширенном потоке показаний, где значение показания влажности меньше нижнего порога влажности для этого растения. Если это число равно как минимум 240, я выведу результат, который станет основой для предупреждения.
Но вам может быть интересно, почему результат этого запроса находится в таблице. Ну, как мы знаем, потоки представляют собой более или менее полную историю объекта данных, тогда как таблицы отражают самое актуальное значение для данного ключа. Важно помнить, что этот запрос на самом деле представляет собой потоковое приложение с отслеживанием состояния. По мере прохождения сообщений в базовом расширенном потоке данных, если это конкретное сообщение соответствует требованиям фильтра, мы увеличиваем количество низких показаний для этого идентификатора завода в течение 1-часового окна и отслеживаем его в пределах состояния. Что меня действительно волнует в этом запросе, так это окончательный результат агрегирования — превышает ли число низких показаний 240 для данного ключа. Я хочу стол.
Кроме того: вы заметите, что последняя строка этого оператора — "EMIT FINAL". Эта фраза означает, что вместо того, чтобы потенциально выводить результат каждый раз, когда новая строка проходит через потоковое приложение, я буду ждать, пока окно не закроется, прежде чем выдавать результат.
Результатом этого запроса является то, что для заданного идентификатора завода в течение определенного часового окна я выведу не более одного предупреждающего сообщения, как и хотел.
Разветвление
В этот момент у меня была тема Kafka, заполненная ksqlDB, содержащая сообщение, когда уровень влажности растения постоянно и соответственно низкий. Но как мне получить эти данные из Kafka? Мне было бы удобнее всего получать эту информацию прямо на телефон.
Я не собирался изобретать велосипед здесь, поэтому я воспользовался этим запись в блоге, в которой описывается использование бота Telegram для чтения сообщений из темы Kafka и отправки предупреждений на телефон. Следуя процессу, описанному в блоге, я создал бота Telegram и начал разговор с этим ботом на своем телефоне, записав уникальный идентификатор этого разговора вместе с ключом API для моего бота. Имея эту информацию, я мог бы использовать API чата Telegram для отправки сообщений с моего бота на свой телефон.
Это хорошо, но как я могу получать оповещения от Кафки к своему боту в Telegram? Я мог бы вызвать отправку сообщений, написав специальный потребитель, который будет получать оповещения из темы Kafka и вручную отправлять каждое сообщение через API чата Telegram. Но это похоже на дополнительную работу. Вместо этого я решил использовать полностью управляемый HTTP Sink Connector, чтобы сделать то же самое, но без написания собственного дополнительного кода.
Через несколько минут мой Telegram-бот был готов к действию, и у меня был открыт приватный чат между мной и ботом. Используя идентификатор чата, я теперь мог использовать полностью управляемый коннектор HTTP Sink в Confluent Cloud для отправки сообщения прямо на мой телефон.
Полная конфигурация выглядела так:
{
"name": "HttpSinkConnector_Houseplants_Telegram_Bot",
"config": {
"topics": "houseplant-low-readings",
"input.data.format": "AVRO",
"connector.class": "HttpSink",
"name": "HttpSinkConnector_Houseplants_Telegram_Bot",
"kafka.auth.mode": "KAFKA_API_KEY",
"http.api.url": "https://api.telegram.org/**********/sendMessage",
"request.method": "POST",
"headers": "Content-Type: application/json",
"request.body.format": "string",
"batch.max.size": "1",
"batch.prefix": "{"chat_id":"********",",
"batch.suffix": "}",
"regex.patterns": ".*MESSAGE=(.*),LOW_READING_COUNT=(.*)}.*",
"regex.replacements": ""text":"$1"",
"regex.separator": "~",
"tasks.max": "1"
}
}
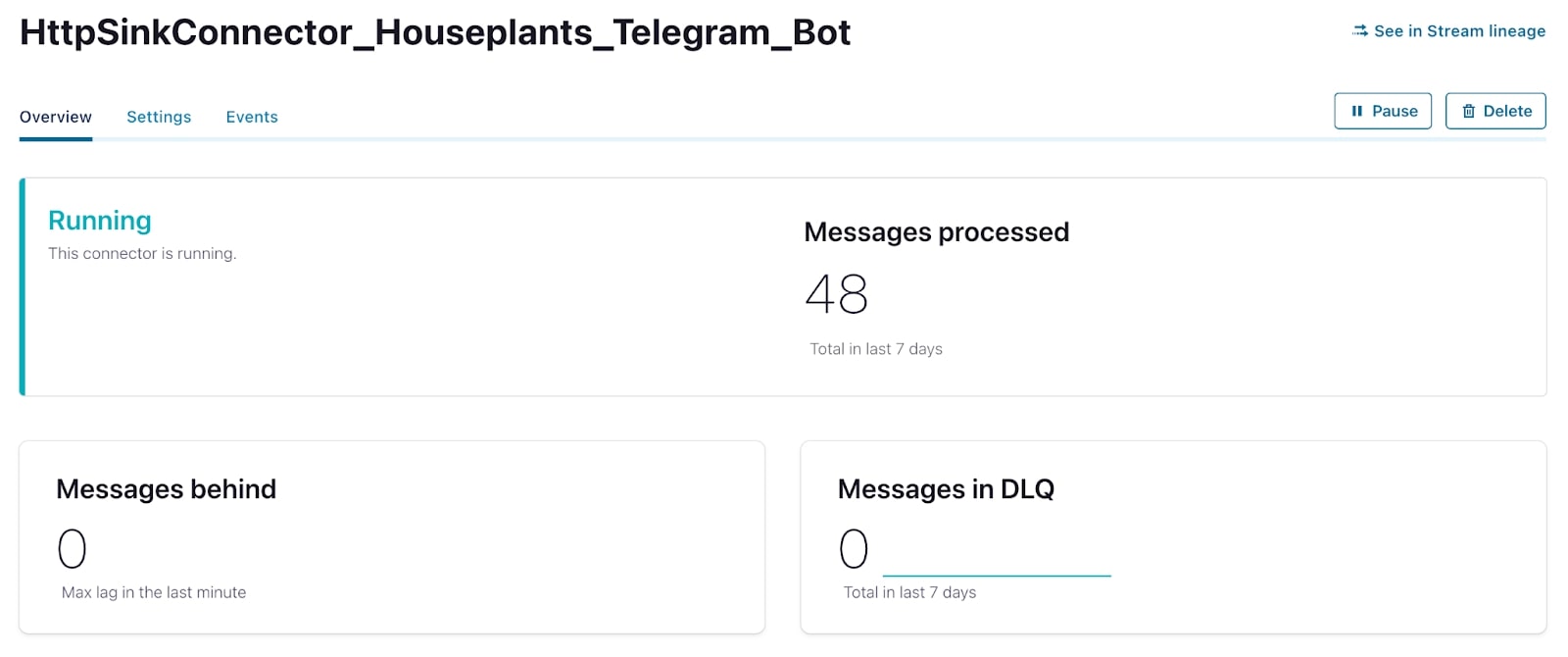
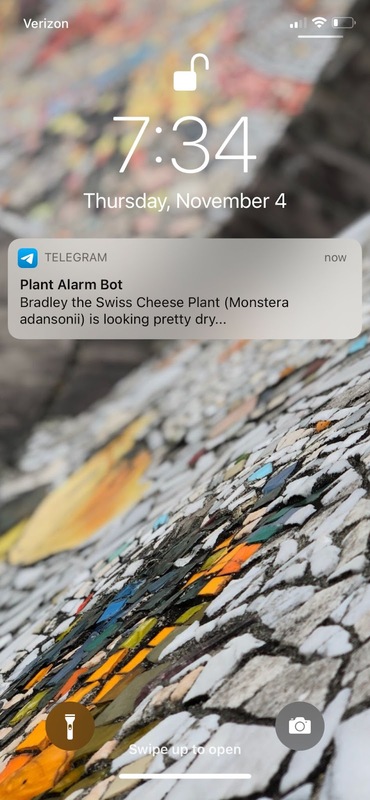
Через несколько дней после запуска коннектора я получил очень полезное сообщение о том, что мое растение нужно полить. Успех!
Открываем новую страницу
Прошло около года с тех пор, как я завершил начальный этап этого проекта. За это время я рад сообщить, что все растения, за которыми я наблюдаю, счастливы и здоровы! Мне больше не нужно тратить дополнительное время на их проверку, и я могу полагаться исключительно на оповещения, генерируемые моим конвейером потоковых данных. Насколько это круто?

Если процесс создания этого проекта вас заинтриговал, я рекомендую вам начать работу над собственным конвейером потоковой передачи данных. Являетесь ли вы опытным пользователем Kafka, который хочет бросить вызов себе, чтобы построить и внедрить конвейеры в реальном времени в свою собственную жизнь, или кем-то, кто совершенно не знаком с Kafka, я здесь, чтобы сказать вам, что такие проекты для вас.
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27360)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)