

Как создать парсер LinkedIn бесплатно?
17 апреля 2022 г.LinkedIn полна полезных данных. От высокопоставленных потенциальных клиентов и квалифицированных кандидатов до огромных списков вакансий и возможностей для бизнеса.
Ко всей этой информации можно получить доступ вручную, поскольку она общедоступна для всех пользователей и не пользователей. Но что, если мы хотим получить доступ к этим данным в большем масштабе?
Сегодня мы хотим показать вам, как вы можете использовать возможности веб-скрапинга для извлечения данных из списков вакансий LinkedIn.
Законно ли собирать данные LinkedIn?
Да, парсинг страниц LinkedIn является законным, как показано в деле LinkedIn vs. HiQ 2019 года.
Однако LinkedIn подала апелляцию на это решение в Верховный суд США (SCOTUS), не получив ответа, насколько нам известно. Пока мы не получим ответ от SCOTUS, «решение 9-го судебного округа остается в силе».
Мы будем следить за этим случаем и обновлять эту статью, как только что-то изменится, и мы рекомендуем вам сделать то же самое.
Очистка объявлений о вакансиях LinkedIn с помощью JavaScript
Хотя парсинг LinkedIn является законным, мы ясно понимаем, что сам LinkedIn не хочет парсинга, поэтому мы хотим быть уважительными при создании нашего бота.
В этом проекте мы будем избегать использования безголового браузера для входа в учетную запись и доступа к тому, что считается личными данными. Вместо этого мы сосредоточимся на очистке общедоступных данных LinkedIn, что не требует от нас нарушения какого-либо экрана входа в систему.
Мы перейдем на общедоступную страницу со списком вакансий LinkedIn и используем Axios и Cheerio для загрузки и анализа HTML, чтобы извлечь название должности, компанию, местоположение и URL-адрес списка.

1. Установите Node.js, Axios и Cheerio
Если вы еще этого не сделали, вам потребуется скачать и установить Node.js и NPM. Последний поможет нам установить остальные наши зависимости. Поскольку мы создаем наш проект на Mac M1, мы выбрали версию ARM64.
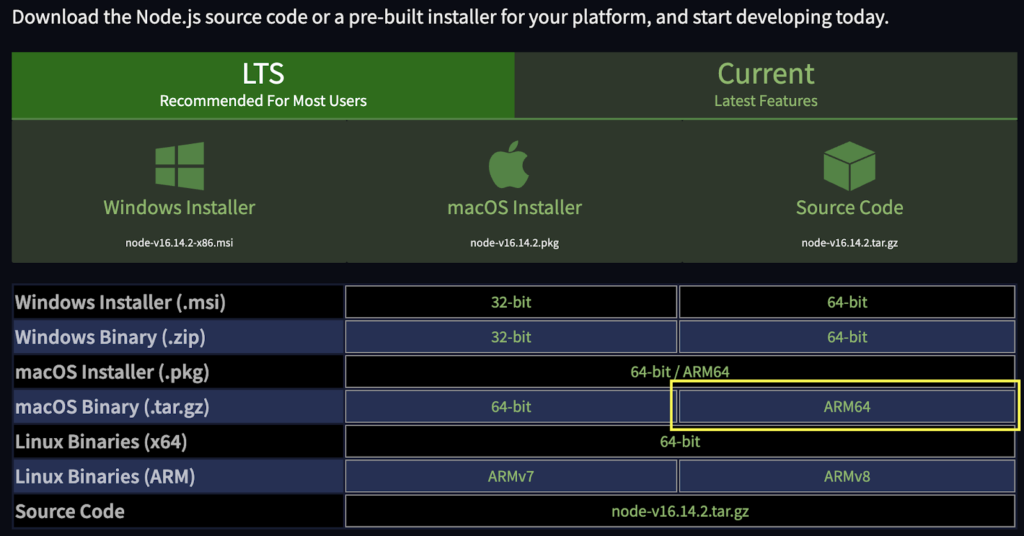
После их установки давайте создадим папку для нашего проекта под названием «Linkedin-scraper-project» и откроем ее в VScode (или в предпочитаемом вами редакторе). Откройте терминал и создайте новый проект, используя npm init -y.
Примечание. Если вы хотите убедиться, что установка прошла успешно, вы можете использовать node -v и npm -v.
Теперь мы готовы установить наши зависимости, используя следующие команды:
- Axios:
npm install axios
- Cheerio:
npm install cheerio
Или мы можем установить оба с помощью одной команды: npm install axios cheerio.
Чтобы начать работу, давайте создадим внутри нашей папки файл index.js и импортируем наши зависимости вверху:
const axios = require('axios');
const cheerio = require('cheerio');
2. Используйте Chrome DevTools, чтобы понять структуру сайта LinkedIn
Прежде чем писать что-либо еще, нам нужно составить план доступа к данным. Для этого мы откроем https://www.linkedin.com/ в нашем браузере и посмотрим, что мы получим.
Примечание. Если вы вошли в систему автоматически, сначала выйдите из своей учетной записи, а затем перейдите на домашнюю страницу LikedIn, чтобы продолжить.

LinkedIn немедленно предоставляет нам форму поиска, которую мы можем использовать, чтобы получить доступ к именно той вакансии, которую мы ищем, и сузить наш поиск до местоположения. Давайте посмотрим на работу разработчика электронной почты в качестве примера.
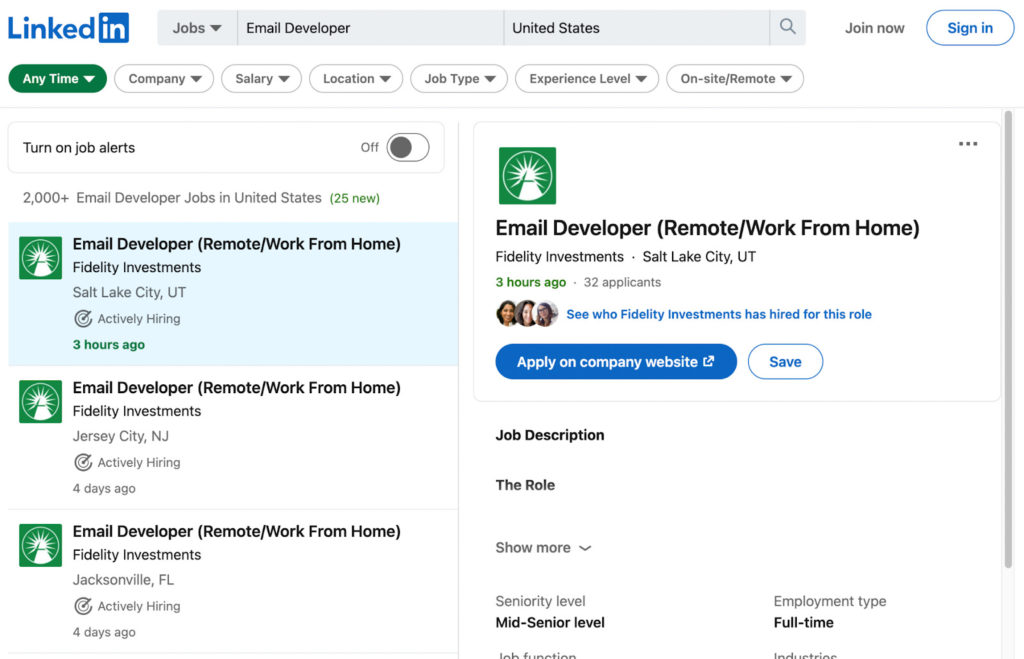
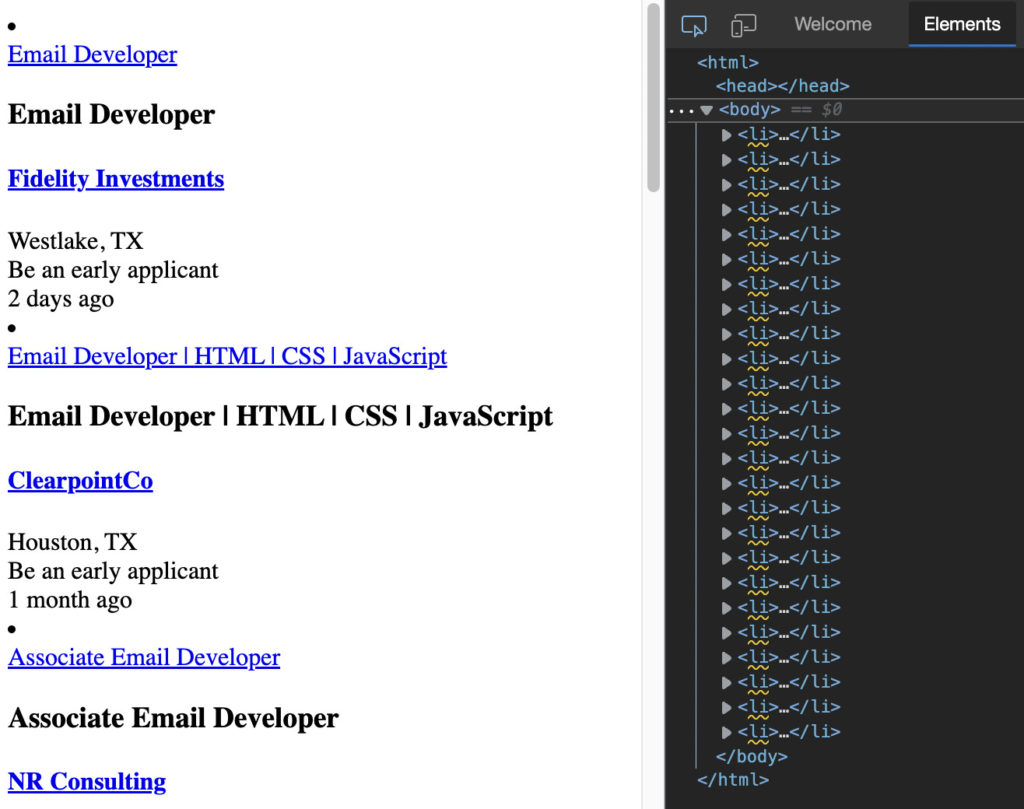
На первый взгляд кажется, что каждая работа находится внутри отдельной карточки, на которую мы должны нацеливаться, чтобы извлечь всю необходимую нам информацию.
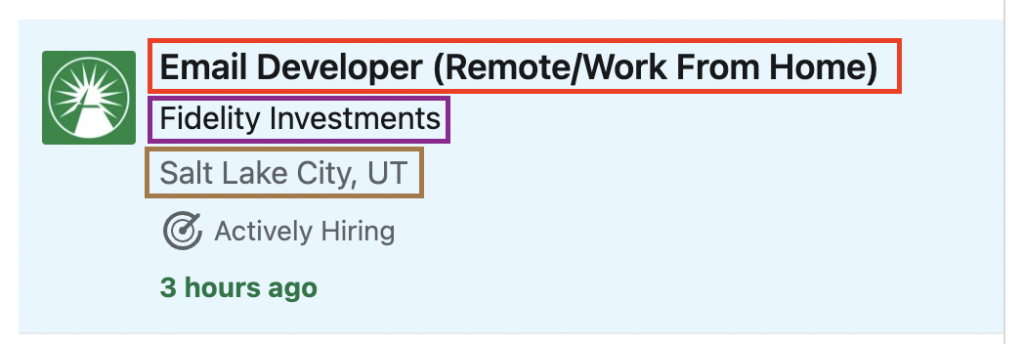
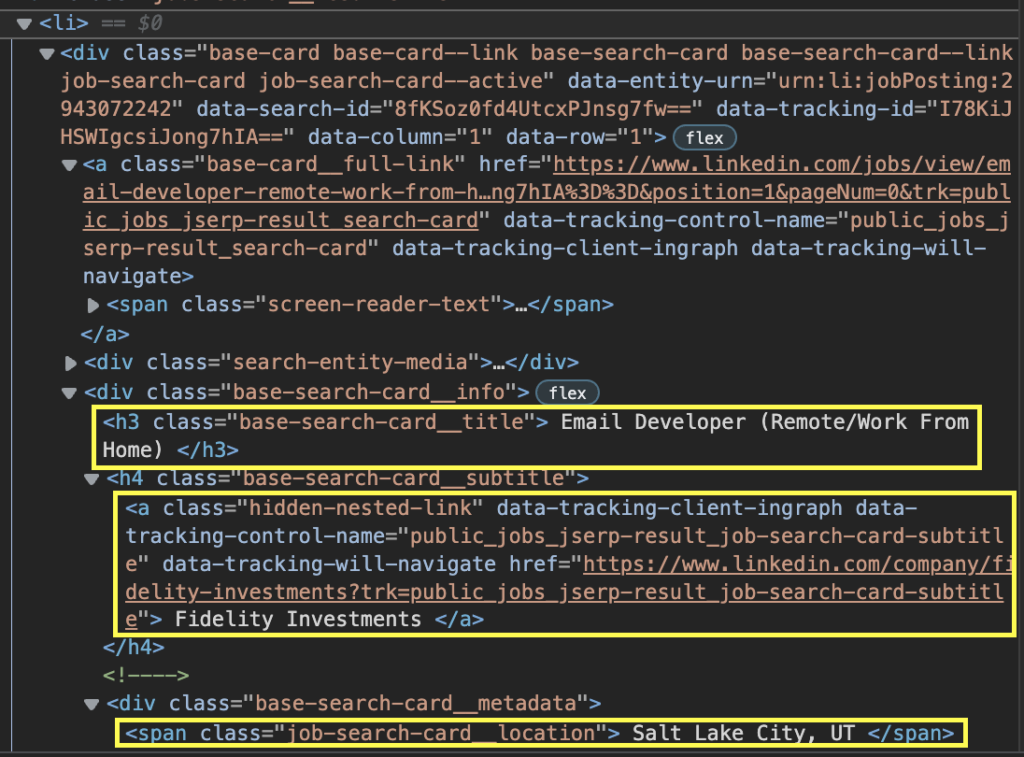
Изучив страницу, мы можем убедиться, что каждое задание находится внутри элемента <li>:

Если мы внимательно посмотрим на элемент <li> , мы сможем найти название должности, название компании, местоположение и URL-адрес листинга. Все хорошо организовано и имеет четкую структуру, которой мы можем следовать.
Однако есть одна загвоздка. После перехода вниз по странице выясняется, что LinkedIn использует бесконечную прокрутку для заполнения страницы большим количеством вакансий вместо традиционной нумерации страниц.
Чтобы справиться с бесконечным разбиением на страницы, мы могли бы использовать безголовый браузер, такой как Puppeteer, для очистки первой партии вакансий, прокрутки страницы вниз, ожидания загрузки новых вакансий и очистки новых списков.
Но если вы обратили внимание на заголовок этого урока, мы не будем использовать безголовый браузер. Вместо этого давайте попробуем быть умнее страницы.
3. Используйте вкладку «Сеть» DevTool
Одна вещь, которую следует иметь в виду при работе с бесконечной прокруткой страниц, заключается в том, что новые данные должны откуда-то поступать. Итак, если мы можем получить доступ к источнику, мы можем получить доступ к данным.
Открыв DevTools, перейдите на вкладку «Сеть» и перезагрузите страницу:
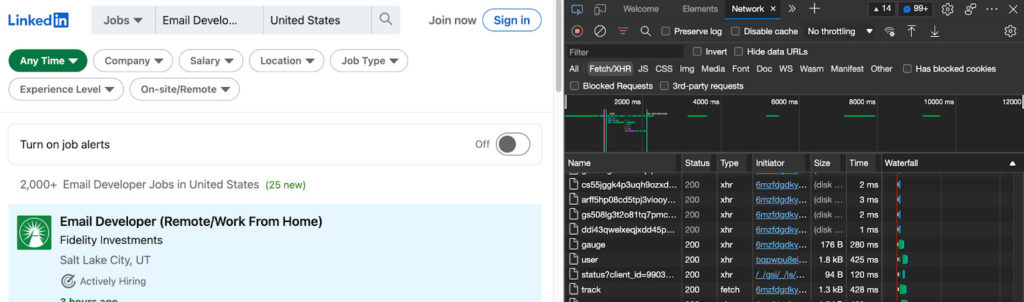
Теперь мы увидим все различные запросы, которые делает веб-сайт. Мы сосредоточимся на запросах Fetch/XHR главным образом потому, что именно здесь мы увидим получение новых данных.
После прокрутки вниз до последнего задания страница отправляет новый запрос на получение данных по URL-адресу на скриншоте ниже. Если мы имитируем этот запрос, мы получим доступ к тем же данным.
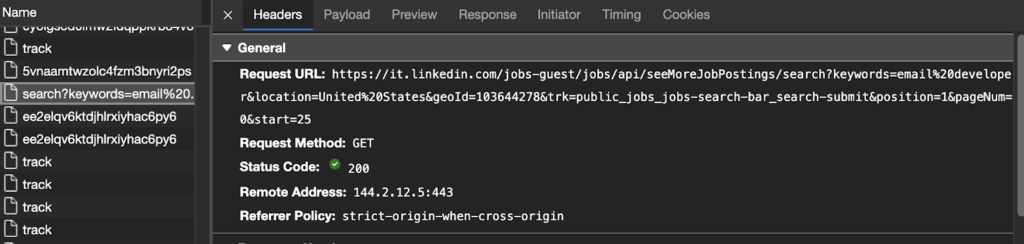
Давайте проверим это в нашем браузере, скопировав и вставив URL-адрес.
Круто, эта страница использует ту же структуру, поэтому не должно быть никаких проблем с очисткой данных. Но давайте продвинем наши эксперименты немного дальше. Этот URL содержит данные для второй страницы, но мы также хотим получить доступ к первой.
Давайте сравним URL 1 с URL 2, чтобы увидеть, как они меняются:
- URL 1:
https://it.linkedin.com/jobs/search?keywords=email%20developer&location=United%20States&geoId=103644278&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum=0
- URL 2:
https://it.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=email%20developer&location=United%20States&geoId=103644278&trk=public_jobs_jobs-search-bar_search-submit&position=1&pageNum =0&начало=25
В этих URL много чего происходит. Однако больше всего нас волнует его конечный бит. Давайте попробуем URL 2, но с параметром start=0 в нашем браузере, чтобы посмотреть, можем ли мы получить доступ к данным.

Это сделало трюк! Первая работа на обеих страницах одинаковая.
Экспериментирование имеет решающее значение для парсинга веб-страниц, поэтому вот еще несколько вещей, которые мы попробовали, прежде чем остановиться на этом решении:
- Изменение параметра pageNum ничего не меняет на странице.
- Параметр start увеличивается на 25 для каждого нового URL. Мы выяснили это, прокрутив страницу вниз и сравнив запросы на выборку, отправленные самим сайтом.
- Изменение параметра start на 1 (например, start=2, start=3 и т. д.) изменит результирующую страницу, скрывая предыдущие списки вакансий за пределами страницы, а это не то, что нам нужно.
- Текущая последняя страница –
start=975. При достижении 1000 он переходит на страницу 404.
Имея наш первоначальный URL, мы можем перейти к следующему шагу.
4. Анализ LinkedIn с помощью Axios и Cheerio
Мы немного изменим наш первоначальный URL-адрес, чтобы получить доступ к американской версии сайта.
const axios = require('axios');
const cheerio = require('cheerio');
const { html } = require('cheerio/lib/static');
let url = 'https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=email%2Bdeveloper&location=United%2BStates&geoId=103644278&trk=public_jobs_jobs-search-bar_search-submit¤tJobId=2931031787&position=1&umpageNum =0&начало=0'
аксиос(url)
.then (ответ => {
const html = response.data;
console.log(html)
Чтобы проверить, работает ли наш запрос Axios, мы используем console.log() в нашей переменной html.
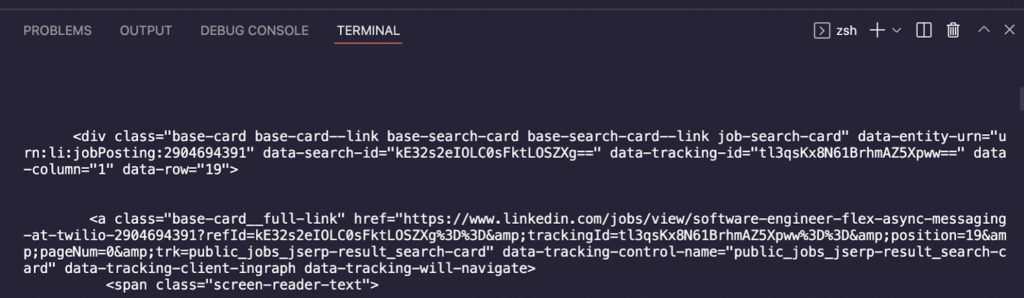
Отлично, мы смогли загрузить необработанный HTML-код и теперь можем передать его в Cheerio для синтаксического анализа. Замените метод console.log() следующим фрагментом, чтобы создать объект Cheerio, который мы можем затем запросить для извлечения наших целевых данных.
| const $ = cheerio.load(html); |
5. Выберите селекторы
Cheerio использует реализацию JQuery для выбора элементов, поэтому, если вы уже знакомы с синтаксисом JQuery, вы окажетесь как дома.
Чтобы выбрать правильные селекторы, давайте вернемся к открытому URL-адресу и отметим атрибуты, которые мы можем использовать. Мы уже знаем, что все данные, которые нам нужны, находятся внутри отдельных элементов <li>, поэтому давайте сначала нацелимся на них и сохраним их в константе.
| const jobs = $('li'); |
Со всеми списками, хранящимися внутри заданий, теперь мы можем идти один за другим и извлекать определенные биты данных, которые мы ищем. Мы можем протестировать наши селекторы прямо в DevTools, чтобы избежать отправки ненужных запросов на сервер.
Если мы проверим название должности, то увидим, что оно находится внутри элемента <h3> с классом base-search-card__title.

Давайте перейдем на вкладку «Консоль» в DevTools и воспользуемся методом document.querySelectorAll() и передаем его '.base-search-card__title', где точка означает класс, в качестве аргумента, чтобы выбрать все элементы с этим классом. .

Он возвращает NodeList из 25, что соответствует количеству заданий на странице. Мы можем сделать то же самое для остальных наших целей. Вот наши цели:
- Должность: «h3.base-search-card__title».
- Компания: «h4.base-search-card__subtitle»
- Местоположение: «span.job-search-card__location»
- URL: «a.base-card__full-link»
6. Перебор списка узлов с помощью .each()
Теперь, когда наши селекторы определены, мы можем выполнить итерацию по списку, хранящемуся в переменной jobs, чтобы извлечь все сведения о работе с помощью метода .each() .
| jobs.each((index, element) => {`` const jobTitle = $(element).find('h3.base-search-card__title').text()`` console.log(jobTitle)` ` }) |
Спорим, вы поняли, насколько важно для нас все тестировать, поэтому, прежде чем пытаться получить каждый элемент, мы начнем с извлечения только названия должности и входа в нашу консоль. Введите node index.js в терминале, чтобы запустить его.
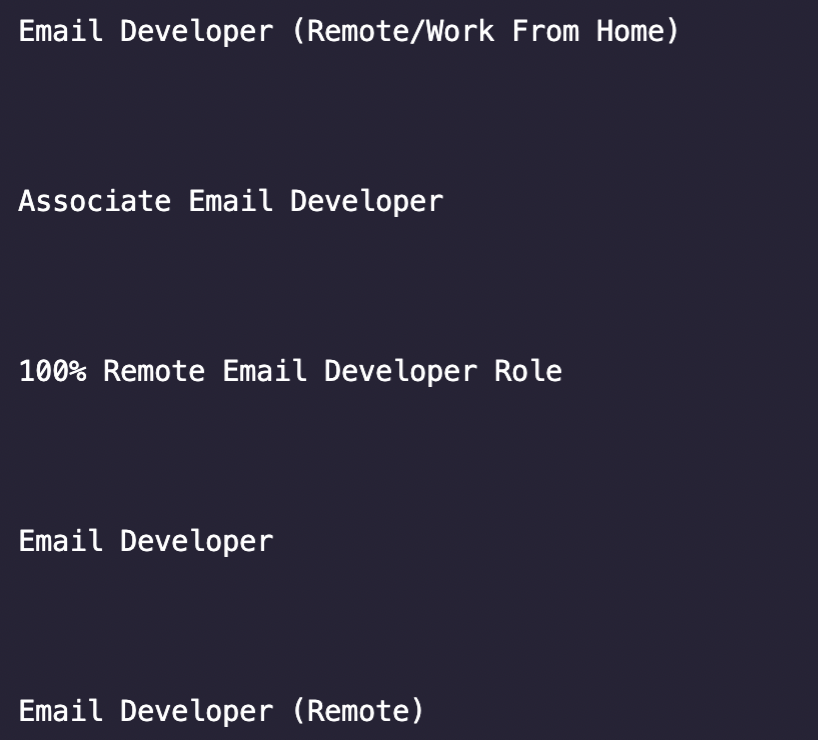
Хм... кажется, что вокруг заголовка много пробелов, и он также извлекается нашим методом .text() . Не беспокойтесь, мы можем использовать метод .trim(), чтобы очистить его.
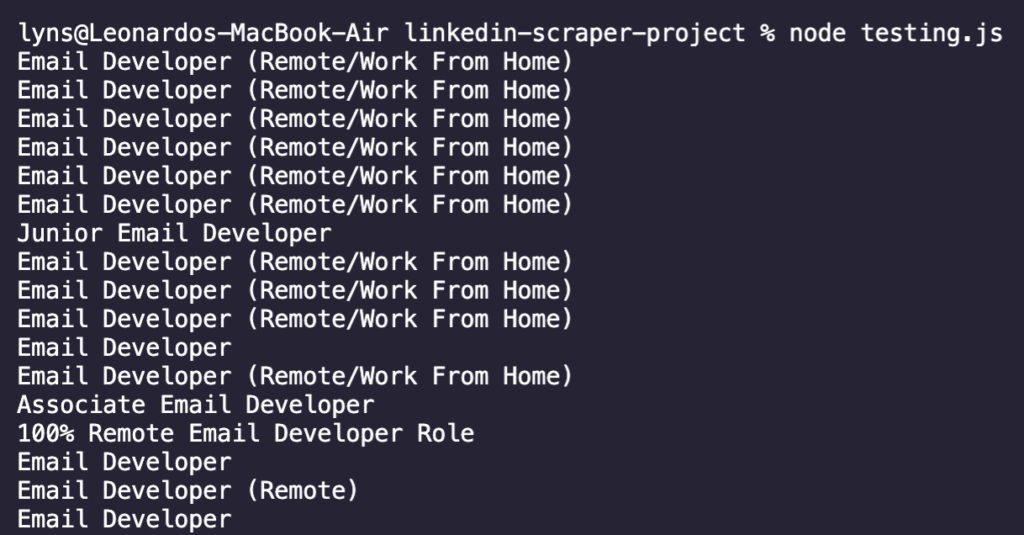
Намного лучше! Теперь мы знаем, что можно безопасно добавлять остальные селекторы в наш скрипт.
const company = $(элемент).find('h4.base-search-card__subtitle').text().trim()
const location = $(элемент).find('span.job-search-card__location').text().trim()
const link = $(элемент).find('a.base-card__full-link').attr('href')
Для ссылки на задание нас на самом деле интересует не текст внутри элемента, а значение атрибута href — другими словами, сам URL. Для этого мы можем просто вызвать метод .attr() и передать ему в качестве аргумента атрибут, из которого мы хотим получить значение.
7. Поместите ваши данные в массив для форматирования
Прямо сейчас наш скрипт будет входить в нашу консоль с множеством неорганизованных строк, что очень затруднит нам его использование. Хорошая новость заключается в том, что мы можем использовать простой метод, чтобы поместить наши данные в пустой массив и автоматически все аккуратно отформатировать.
Во-первых, мы создадим пустой массив перед тем, как Axios вызовет задания LinkedIn:
linkedinJobs = [];
Затем мы добавим следующий фрагмент кода сразу после ссылки const:
| ` linkedinJobs.push({ 'Название': jobTitle,'Компания': company, 'Location': location,'Link': link, }) ``
И зарегистрируйте Linkedinjobs в консоли.
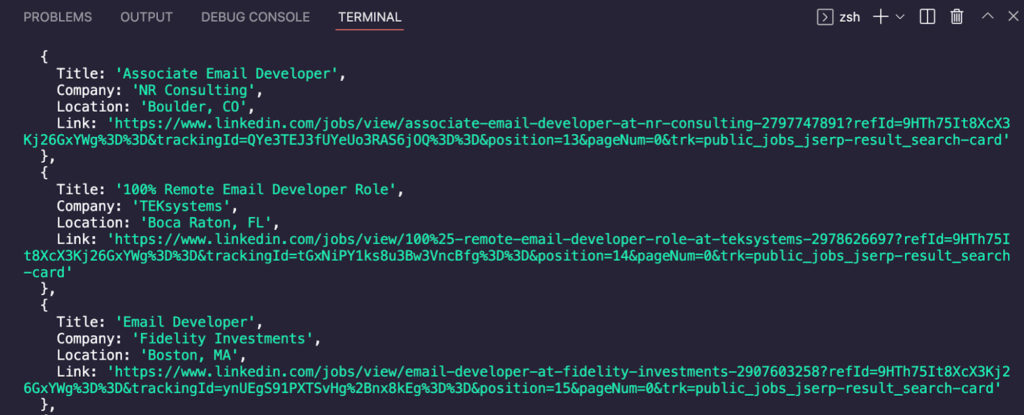
Как это выглядит сейчас? Все наши данные идеально помечены и отформатированы, и мы готовы экспортировать их в файл JSON или CSV.
Тем не менее, это не все данные, которые нам нужны. Наш следующий шаг — перейти к остальным страницам и повторить тот же процесс.
8. Очистка всех страниц с помощью цикла for
Существует много способов перейти на следующую страницу, но с учетом наших текущих знаний о веб-сайте самым простым способом будет увеличить начальный параметр в URL-адресе на 25, чтобы отображались следующие 25 заданий, пока не закончатся результаты и не появится ` for loop идеально выполняет эту функцию.
Чтобы освежить вашу память, вот синтаксис цикла for:
для (оператор 1; оператор 2; оператор 3) {
//блок кода для выполнения
Давайте сначала создадим эту часть, добавив наши пользовательские операторы:
for (пусть pageNumber = 0; pageNumber < 1000; pageNumber += 25) {
- Нашей начальной точкой будет 0, так как это первое значение, которое мы хотим передать в параметр
`start.
- Поскольку мы знаем, что при достижении 1000 результатов больше не будет, мы хотим, чтобы код выполнялся до тех пор, пока
`pageNumberменьше 1000.
- Наконец, после каждой итерации кода мы хотим увеличить
pageNumberна 25, фактически переходя на следующую страницу.
Прежде чем переместить остальную часть кода внутрь цикла, нам нужно добавить нашу переменную pageNumber в URL:
| let url = `https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=email%2Bdeveloper&location=United%2BStates&geoId=103644278&trk=public_jobs_jobs-search-bar_search-submit¤tJobId=2931031787&position=2931031787&position=2931031787 1&pageNum=0&start=${pageNumber}` |
И теперь мы добавляем остальную часть нашего кода в цикл, теперь используя переменную pageNumber в качестве значения параметра start.
9. Запишите свои данные в файл CSV
Это был долгий процесс, но мы почти закончили с нашим скребком. Тем не менее, хранение всего этого журнала данных на нашей консоли — не совсем лучший способ его хранения.
Чтобы срезать углы, мы будем использовать пакет Objects-to-CSV. У них есть действительно подробная документация, если вы хотите углубиться в пакет, но, говоря простым языком, он преобразует наш массив объектов JavaScript (linkedinJobs) в формат CSV, который мы можем сохранить на нашей машине.
Во-первых, мы установим пакет с помощью npm install objects-to-csv и добавим его в начало нашего проекта.
| const ObjectsToCsv = require('objects-to-csv'); |
Теперь мы можем добавить использование пакета сразу после закрытия нашего метода job.each():
| const csv = new ObjectsToCsv(linkedinJobs)`` csv.toDisk('./linkedInJobs.csv', { append: true }) |
«Ключи в первом объекте массива будут использоваться как имена столбцов», поэтому важно сделать их описательными при использовании метода .push().
Кроме того, поскольку мы хотим просмотреть несколько страниц в цикле, мы не хотим, чтобы наш CSV каждый раз перезаписывался, а добавлялись новые данные ниже. Для этого все, что нам нужно сделать, это установить для append значение true. Он добавит заголовки только один раз и продолжит обновлять файл новыми данными.
10. Запустите свой код [Полный код парсера LinkedIn]
Если вы следовали инструкциям, вот как должен выглядеть ваш готовый код:
const axios = require('axios');
const cheerio = require('cheerio');
const ObjectsToCsv = require('objects-to-csv');
linkedinJobs = [];
for (пусть pageNumber = 0; pageNumber < 1000; pageNumber += 25) {
let url = `https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=email%2Bdeveloper&location=United%2BStates&geoId=103644278&trk=public_jobs_jobs-search-bar_search-submit¤tJobId=2931&031787 1&pageNum=0&start=${pageNumber}`;
аксиос(url)
.then (ответ => {
const html = response.data;
const $ = cheerio.load(html);
const jobs = $('li')
jobs.each((index, element) => {
const jobTitle = $(элемент).find('h3.base-search-card__title').text().trim()
const company = $(element).find('h4.base-search-card__subtitle').text().trim()
const location = $(элемент).find('span.job-search-card__location').text().trim()
const link = $(элемент).find('a.base-card__full-link').attr('href')
linkedinJobs.push({
'Название': jobTitle,
'Компания': компания,
'Местоположение': местоположение,
'Ссылка': ссылка,
const csv = новый ObjectsToCsv(linkedinJobs)
csv.toDisk('./linkedInJobs.csv', { append: true })
.catch(console.error);
Чтобы запустить его, перейдите в свой терминал и введите node index.js (или имя вашего файла):
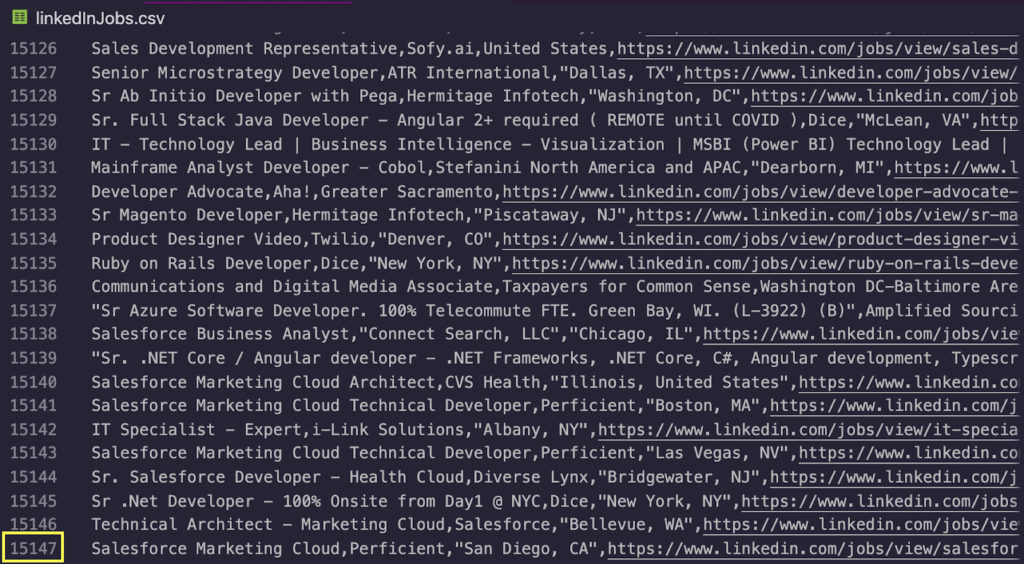
Поздравляем, более 15 000 списков вакансий были найдены за несколько секунд. Для следующих шагов экспортируйте эти данные в Excel и отфильтруйте столбец «Название» только для тех, которые содержат ключевое слово «разработчик электронной почты» или по местоположению.
Подведение итогов: вот вам вызов
Мы многое рассмотрели в этом руководстве, но есть еще несколько вещей, которые мы предлагаем вам попробовать:
- Сделайте так, чтобы скрипт отфильтровывал задания по названию, чтобы вы извлекали только те карточки, которые содержат ключевое слово «разработчик электронной почты» или «электронная почта в формате html».
- Сейчас скрипт слишком быстро просматривает страницы. Добавьте буфер между запросами, чтобы он отправлял новый запрос только через 5 секунд, это поможет вам защитить свой IP.
*Ранее опубликовано здесь.
*
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27740)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)