

Как ограниченное и совместное декодирование улучшает мультимодальные речевые модели
19 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 подхода
2.1 Архитектура
2.2 Multimodal Trancing Paneletuning
2.3 Учебное обучение программы с эффективным характеристиком параметров
3 эксперименты
4 Результаты
4.1 Оценка моделей речи.
4.2 Обобщение между инструкциями
4.3 Стратегии повышения производительности
5 Связанная работа
6 Заключение, ограничения, заявление о этике и ссылки
Приложение
A.1 Audio Encoder перед тренировкой
A.2 Гиперпараметры
A.3 Задачи
4.3 Стратегии повышения производительности
Мы также оцениваем стратегии для улучшения производительности модели с несколькими задачами, особенно для невидимых задач и классов. Во-первых, мы использовали противоположные декодировании [40] для задач, которые имеют предварительно определенную набор конечных результатов. Затем мы также изучаем совместное декодирование вывода задачи с гипотезами ASR аудио для определенных задач понимания сложного разговорного языка.
4.3.1 Ограниченное декодирование
Работа в [40] ввела метод модели-агностической для обеспечения соблюдения доменных знаний и ограничений во время генерации текста. Опираясь на этот предыдущий подход, мы исследовали применение ограничений декодирования к модели речи для улучшения обобщения к невидимым задачам классификации речи. Вместо того, чтобы позволить модели свободно генерироваться в ответ на подсказку, декодирование ограничено выводом из предварительно определенного словаря имен классов. Например, в задаче классификации намерений модель будет ограничена только для создания только этих ярлыков намерения, таких как «play_radio», «datetime_query» или «cooking_recipe». Ограничивая выходное пространство, модель с большей вероятностью будет производить желаемую метку класса, а не несвязанный текст.
Мы тщательно оцениваем производительность модели по тесным задачам, таким как разнообразный набор задач классификации, которые имеют предварительно определенный набор конечных меток классов. Чтобы понять влияние подсказок обучения, мы делим это исследование на две части: (1), где мы предоставляем только этикетки класса в подсказке и (2), где мы предоставляем сопутствующее описание каждой метки класса в подсказке. Мы гарантируем, что ни одна из этих классов не было замечено во время тренировок, и, следовательно, все это новые задачи для модели. Кроме того, мы оцениваем эффективность использования ограниченного декодирования в каждой из этих двух частей, поскольку этикетки класса известны нам заранее. Обратите внимание, что задача SL может считаться более сложной задачей, поскольку модель должна правильно классифицировать метку слота, а также определить соответствующее значение слота из речи. Следовательно, мы сообщаем как метрику SLU-F1, а также метрику SD-F1 (обнаружение метки слота) для SL. Результаты этого исследования представлены в таблице 7.
Мы отмечаем, что включение описаний в подсказку имеет противоречивые результаты, которые можно объяснить качеством и субъективностью описаний, представленных в подсказке, тем более что эти описания не были замечены во время обучения. Тем не менее, мы видим, что ограниченное декодирование улучшается по результатам во всех случаях, и наиболее значительные успехи наблюдаются только тогда, когда описания предоставляются с ограниченным декодированием. Это указывает на то, что предоставление описаний действительно направляет модель к лучшему пониманию семантики задачи, но только ограниченное декодирование способно объективно обрезать шум, введенный каким -либо предвзятостью. Это явление дополнительно выявляется в задаче SL, где SLU-F1 имеет более низкое абсолютное значение по сравнению с SD-F1, поскольку метрика SLU-F1 включает как метку слота, так и значение слота, тогда как ограниченное декодирование может применяться только к метке слота (следовательно, более высокий SD-F1). Аналогичным образом, для совершенно невидимой задачи классификации доменов (DC), где цель состоит в том, чтобы классифицировать содержание аудио на пять доменов, таких как здравоохранение, технология и т. Д., Мы наблюдаем сильную производительность 62% точности с ограниченным декодированием.
4.3.2 Совместное декодирование
Некоторые задачи SLU требуют, чтобы модель понимала семантику аудио или выполнить операцию по содержанию аудио. Например, задача KWE о извлечении важных ключевых слов из гипотезы ASR звука. Поскольку это многоэтапный процесс рассуждения для модели, мы черпаем вдохновение в существующей работе [41] по подсказке цепочки мыслей (COT). Мы обучаем нашу модель сначала декодировать гипотезу ASR аудио, а затем вывод задачи. Подсказки, используемые для совместного выявления гипотезы ASR и вывода задачи, описаны в таблице 8. Для репрезентативного набора задач SLU, включая IC, KWE и ER, мы перерабатываем модели Task-FT, добавив небольшую часть таких многоэтапных примеров, а также примеры с одной задачей. Мы сравниваем результаты с совместным декодированием с гипотезой ASR в таблице 9.

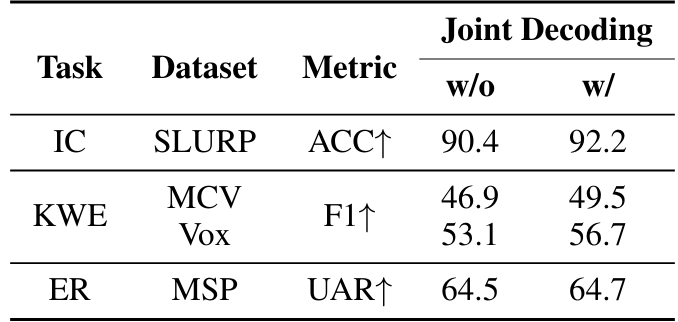
Результаты в таблице демонстрируют, что дополнение данных обучения с помощью сложных целей помогает повысить производительность для всех трех задач. Улучшенная производительность может быть связана с возможностью самостоятельного прихода к уже декодированной гипотезе ASR в декодере нашей мультимодальной модели. Кроме того, такие многоэтапные примеры обучения выявляют истинные мультимодальные возможности модели для успешного выполнения комбинации задач. Кроме того, такая парадигма может помочь сохранить важную задержку вывода, используя один вызов большой многомодальной модели для получения как транскрипта, так и вывода задачи. Более подробный анализ понимания преимуществ совместного декодирования будет проводиться в будущей работе.
Авторы:
(1) Nilaksh Das, AWS AI Labs, Amazon и равный вклад;
(2) Saket Dingliwal, AWS AI Labs, Amazon (skdin@amazon.com);
(3) Шрикант Ронанки, AWS AI Labs, Amazon;
(4) Рохит Патури, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Цзе Юань, AWS AI Labs, Amazon;
(8) Дхануш Бекал, AWS AI Labs, Amazon;
(9) Син Ниу, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Карел Мунднич, AWS AI Labs, Amazon;
(13) Моника Сункара, AWS AI Labs, Amazon;
(14) Даниэль Гарсия-Ромеро, AWS AI Labs, Amazon;
(15) Кю Дж. Хан, AWS AI Labs, Amazon;
(16) Катрин Кирххофф, AWS AI Labs, Amazon.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)