
Как модели искусственного интеллекта считаются концепциями на изображениях и текстах
9 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
2 концепции в предварительных данных и количественная частота
3 Сравнение производительности предварительного подготовки и «нулевого выстрела» и 3.1 Экспериментальная установка
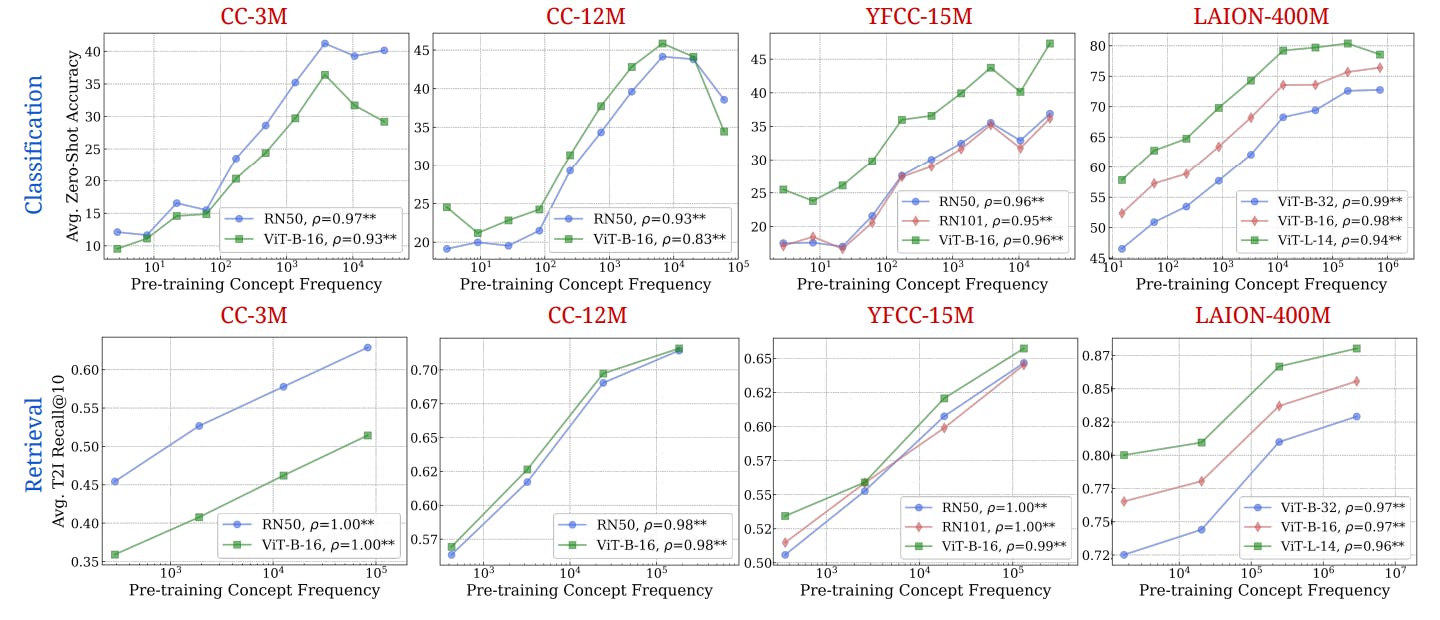
3.2
4 Тестирование стресса Концепция тенденции масштабирования частоты и 4.1.
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
5 Дополнительные идеи от частот концепции предварительного подготовки
6 Проверка хвоста: пусть он виляет!
7 Связанная работа
8 Выводы и открытые проблемы, подтверждения и ссылки
Часть я
Приложение
A. Частота концепции является прогнозирующей производительности в разных стратегиях
B. Частота концепции является прогнозирующей производительности в результате получения метриков извлечения
C. Частота концепции является прогнозирующей производительности для моделей T2I
D. Концепция частота является прогнозирующей производительности в разных концепциях только из изображений и текстовых областей
E. Экспериментальные детали
F. Почему и как мы используем Ram ++?
G. Подробная информация о результатах степени смещения
H. T2I Модели: оценка
I. Результаты классификации: пусть это виляет!
2 концепции в предварительных данных и количественная частота
В этом разделе мы описываем нашу методологию получения частот концепции в рамках наборов данных предварительного подготовки. Сначала мы определяем наши концепции, а затем опишем алгоритмы для извлечения их частот из изображений
![Figure 1: Concept Extraction and Frequency Estimation Pipeline. (left) We compile 4, 029 concepts from 17 classification, 2 retrieval, and 8 image generation prompt datasets. (right) We construct efficient indices for both text-search (using standard unigram indexing (1)) and image-search (using RAM++ [59] (2)); intersecting hits from both gives us (3) the image-text matched frequencies per concept.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-x1832pn.png)
и текстовые подписи предварительных наборов данных. Наконец, мы обсудим, как их агрегировать для расчета соответствующих частот концепции концепции изображения. Схематический обзор наших методов см. В рис. 1.
Определение концепций.Мы определяем «концепции» как конкретные объекты или категории классов, которые мы стремимся проанализировать в предварительных наборах данных. Для задач классификации с нулевым выстрелом эти концепции являются названиями классов, такие как 1 000 классов в ImageNet [35] (например, «Tench», «Goldfish», «Stingray»). Для задач поиска и генерации изображений концепции идентифицируются как все существительные, присутствующие в подписях тестовых наборов или подсказок генерации соответственно. Например, в заголовке «человек носит шляпу», мы извлекаем «человека» и «шляпу» как соответствующие понятия. Кроме того, мы отфильтровываем существительные, которые присутствуют в менее чем пяти образцах оценки нижестоящих по течению, чтобы удалить неоднозначные или не относящиеся к делу концепции. Во всех наших экспериментах мы сопоставляем список из 4, 029 концепций, полученных из 17 классификации, 2 поиска и 8 наборов данных по производству изображений (см. Подробности см. Вкладку 1).
Концепция частота из текстовых подписей.Чтобы включить эффективные поиски концепции, мы предварительно индекс всех подписей из предварительных наборов данных, т. Е. Сопоставляем отображение из концепций в подписи. Сначала мы используем частично-речевую теги, чтобы изолировать общие и правильные существительные, и впоследствии лемматизируем их для стандартизации форм слов [65] со SPACY [58]. Эти лемматизированные существительные затем каталогизируются в инвертированных словари Unigram, причем каждое существительное является ключом, и все индексы в образцах предварительных данных, содержащих существительное, являются его значениями. Чтобы определить частоту концепции, особенно тех, которые состоят из нескольких слов, мы изучаем индивидуальные Unigrams концепции в этих словари. Для выражений с несколькими словами, пересекая списки индексов выборки, соответствующие каждой Unigram, мы идентифицируем образцы, которые содержат все части концепции. Частота концепции в текстовых подписях является подсчетом этих пересекающихся индексов выборки. Наш алгоритм оценки частоты, следовательно, позволяет масштабируемому поиску O (1) по количеству подписей для любой заданной концепции в подписках предварительных наборов данных.
Частота концепции из изображений.В отличие от текстовых подписей, мы не имеем конечного словаря для предварительных изображений предварительного индекса, и, таким образом, не можем выполнить поиск концепции O (1). Вместо этого мы собираем все концепции 4, 029 вниз по течению и проверяем их присутствие в изображениях, используя предварительную модель тега. Мы протестировали различные детекторы объектов с открытыми вокабуляциями, модели сопоставления текста изображений и модели с несколькими веществами. Мы обнаружили, что RAM ++ [59]-модель тега с открытым набором, которая помечает изображения на основе предопределенного списка концепций в многопользовательской манере-лучше всего. Этот подход генерирует список предварительных изображений, каждая из которых отмечена тем, присутствуют ли концепции нижестоящих направлений или нет, из которых мы можем вычислить частоты концепции. Мы предоставляем качественные примеры вместе с абляциями выбора дизайна в Appx. Фон
Сопоставленные концептуальные частоты изображения.Наконец, мы объединяем частоты, полученные из поиска текста и изображений для расчетаСоответствующие частоты текста изображения.Это включает в себя выявление предварительной подготовки

Образцы, где как изображение, так и связанная с ним подпись соответствует концепции. Пересекая списки из наших изображений и текстовых поисков, мы определяем количество образцов, которые соответствуют обоим модальностям, предлагая всеобъемлющее представление о представлении концепции по всему набору данных. Мы отмечаем, что этот шаг необходим, так как мы наблюдали значительное смещение текста изображения между концепциями в наборах данных предварительного подготовки (см. Вкладку 3), следовательно, подписи могут не отражать то, что присутствует на изображении и наоборот. Такое поведение также было упомянуто в предыдущей работе, исследующей стратегии курирования данных предварительного подготовки [76, 75, 124, 83]. Мы предоставляем более подробный анализ о смещении текста изображения в гл. 5
Авторы:
(1) Вишаал Удандарао, Центр ИИ Тубингена, Университет Табингингена, Кембриджский университет и равный вклад;
(2) Ameya Prabhu, Центр AI Tubingen, Университет Табингинга, Оксфордский университет и равный вклад;
(3) Адхирадж Гош, Центр ИИ Тубинген, Университет Тубингена;
(4) Яш Шарма, Центр ИИ Тубинген, Университет Тубингена;
(5) Филипп Х.С. Торр, Оксфордский университет;
(6) Адель Биби, Оксфордский университет;
(7) Сэмюэль Албани, Кембриджский университет и равные консультирование, приказ, определенный с помощью монеты;
(8) Матиас Бетге, Центр ИИ Тубинген, Университет Тубингена и равные консультирование, Орден определяется с помощью переворачивания монеты.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)