

Скрытие задержки распределения памяти в LLM, служа с ваттенцией
13 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
2.1 Модели больших языков
2.2 Фрагментация и Pagegataturation
3 проблемы с моделью Pagegatatturetion и 3.1 требуют переписывания ядра внимания
3.2 Добавляет избыточность в рамки порции и 3,3 накладных расходов
4 понимания систем обслуживания LLM
5 Vattument: проектирование системы и 5.1 Обзор дизайна
5.2 Использование поддержки CUDA низкого уровня
5.3 Служение LLMS с ваттенцией
6 -й ваттиция: оптимизация и 6,1 смягчения внутренней фрагментации
6.2 Скрытие задержки распределения памяти
7 Оценка
7.1 Портативность и производительность для предпочтений
7.2 Портативность и производительность для декодов
7.3 Эффективность распределения физической памяти
7.4 Анализ фрагментации памяти
8 Связанная работа
9 Заключение и ссылки
6.2 Скрытие задержки распределения памяти
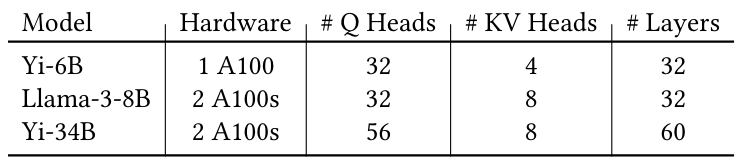
Структура порции вызывает API Step API на каждой итерации. Задержка шага зависит от того, сколько новых страниц необходимо составить на карту в виртуальных тензорах kv-cache. Рассмотрим, например, что для YI-34B должен быть расширен kv-кэш из одного запроса, который имеет 60 слоев. Это требует 120 вызовов для Vmemmap, каждый из которых занимает около 9 микросекунд. Следовательно, увеличение кв-кэша одного запроса на одну страницу добавит около 1 миллисекундной задержки в соответствующую итерацию и будет расти пропорционально количеству физической памяти, которую необходимо сопоставить. Мы предлагаем следующие оптимизации, чтобы скрыть задержку распределения:
6.2.1 Перекрывающееся распределение памяти с помощью вычислительного.Мы используем предсказуемость спроса на память, чтобы перекрывать распределение памяти с вычислением. В частности, обратите внимание, что каждая итерация производит один выходной токен для каждого запроса декодирования. Следовательно, спрос на память на итерацию декодирования известен заранее. Кроме того, на этапе декодирования запрос требует не более одной новой страницы. Vattument отслеживает текущую длину контекста и сколько страниц физической памяти уже отображается для каждого запроса. Используя эту информацию, она определяет, когда запрос понадобится новая страница, и использует фоновый поток для распределения новой страницы при выполнении предыдущей итерации. Например, учтите, что запрос R1 потребует новой страницы в итерации i. Когда структура порции вызывает API Step API в итерации I-1, Vattument запускает фоновый поток, который отображает страницы физической памяти для итерации i. Поскольку задержка итерации обычно находится в диапазоне 10S-100-х миллисекунд, фоновый поток имеет достаточно времени, чтобы подготовить сопоставления физических памяти для итерации, прежде чем он начнет выполнять. Таким образом, ваттенция скрывает задержку API CUDA, отображая физические страницы в тензорах KV-кэша из критического пути. Обратите внимание, что в каждой итерации STEP API по -прежнему необходимо обеспечить, чтобы физические страницы, необходимые для текущей итерации, фактически отображаются. Если нет, необходимые страницы синхронно отображаются.
6.2.2 Отложенная мелиорация + стремление.Мы наблюдаем, что во многих случаях можно избежать выделения физической памяти для нового запроса. Учтите, что запрос R1 завершен на итерации I и новый запрос R2 присоединяется к запущенной партии в итерации I+1. Чтобы избежать распределения новых страниц на R2 с нуля, Vattument просто определяет мелиорацию страниц R1 и назначает R1 Requd на R2. Таким образом, R2 использует те же тензоры для своего kv-кэша, который использовал R1, которые уже поддерживаются физическими страницами. Следовательно, новые страницы для R2 требуются только в том случае, если его длина контекста больше, чем у R1.
Мы дополнительно оптимизируем распределение памяти путем активного отображения физических страниц, прежде чем они будут необходимы. Мы делаем это, используя один из kv-кв. Когда появится новый запрос, мы можем выделить этот Requd без картирования
любые физические страницы. Затем мы выбираем новый Reqid, который будет выделен дальше, и отобразить для него физические страницы. В большинстве случаев эти нетерпеливые оптимизации устраняют необходимость распределения новых физических страниц даже для предварительной фазы новых запросов. Наконец, мы запускаем мелиорацию памяти только тогда, когда количество страниц физической памяти, кэшируемых в ваттенции, падает ниже определенного порога (например, менее 10% памяти графического процессора). Мы делегируем как отложенную мелиорацию, так и стремление распределения в фоновую нить, которую порождает Step API.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Авторы:
(1) Рамья Прабху, Microsoft Research India;
(2) Аджай Наяк, Индийский институт науки и участвовал в этой работе в качестве стажера в Microsoft Research India;
(3) Джаяшри Мохан, Microsoft Research India;
(4) Рамачандран Рамджи, Microsoft Research India;
(5) Ашиш Панвар, Microsoft Research India.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)