

Hadoop в нескольких центрах обработки данных
28 марта 2023 г.Обзор фундаментальной технологии
Apache Hadoop — программно-аппаратный комплекс, позволяющий выполнять задачи, связанные с хранением и обработкой больших массивов данных. Hadoop предназначен для пакетной обработки данных с использованием вычислительной мощности более чем одной физической машины, а также для хранения наборов данных, которые не помещаются на одном узле.
Вам может понадобиться использовать Hadoop, если ваши потребности соответствуют следующим критериям:
- Необходимо принимать неструктурированные/полуструктурированные данные (JSON) и затем преобразовывать их в обычную/структурированную форму.
- Необходимо длительное хранение и обработка больших массивов данных, объемы которых не могут быть размещены в системе управления реляционными базами данных (более 100 ГБ).
- Необходима обработка данных, которую невозможно выполнить в рамках услуги/набора услуг, поскольку она не помещается в ОЗУ или требует хранения больших промежуточных результатов.
- Необходимо передавать большие наборы данных (сотни миллионов строк, сотни гигабайт) между сервисами/кластерами — используя Hadoop в качестве интеграционной шины.
- Необходимы многоэтапные операции обработки данных (ETL), которые невозможно реализовать в рамках одного сервиса или которые требуют использования логики на языках, запрещенных для интеграции в сервисы (Python).
- Специальная аналитика данных, хранящихся в Hadoop.

Примеры задач, реализованных в настоящее время в Hadoop:
- Промежуточное хранение данных, извлеченных из мастер-систем, для дальнейшего использования в СХД (ETL, интеграционная шина).
- Расчет математических моделей и прогнозов.
- Хранение данных о поведении пользователей в табличной форме.
Предварительные требования для Hadoop в нескольких центрах обработки данных:
Как правило, Hadoop размещается в одном дата-центре, но что, если нам требуется высокая доступность такого сервиса, как Hadoop, которая позволила бы ему выдержать отключение одного из центров обработки данных? Или, что не исключено, возможно, вам просто не хватает стоек в одном дата-центре, и вам необходимо увеличить как данные, так и ресурсы ресурсов. Мы стояли перед выбором — размещать потребителей на разных Hadoop в разных дата-центрах (ЦОДах) или делать что-то особенное.
Мы решили сделать что-то особенное, и поэтому родилась концепция, которую мы разработали, протестировали и внедрили — мультицентр обработки данных Hadoop (HMDC).
Мультицентр обработки данных Hadoop
Как следует из названия, он располагается в нескольких центрах обработки данных. Это решение обеспечивает устойчивость кластера к потере емкости в любом отдельном центре обработки данных и эффективно распределяет ресурсы между потребителями. HMDC предоставляет потребителям две основные услуги: распределенную файловую систему HDFS и диспетчер ресурсов YARN, который также действует как планировщик задач.
Эта технология позволяет создать гораздо более отказоустойчивый кластер Hadoop, хотя и имеет определенные особенности, краткий обзор которых приведен ниже.
В каждом центре обработки данных есть один главный узел и набор рабочих подчиненных узлов. На главных узлах установлены следующие компоненты:
- HDFS NameNode — отвечает за метаданные нашей HDFS, где находится каждый блок данных и к какому файлу он принадлежит.
- YARN ResourceManager — наша точка входа для запуска задач в YARN, отвечающая за распределение задач между подчиненными узлами.
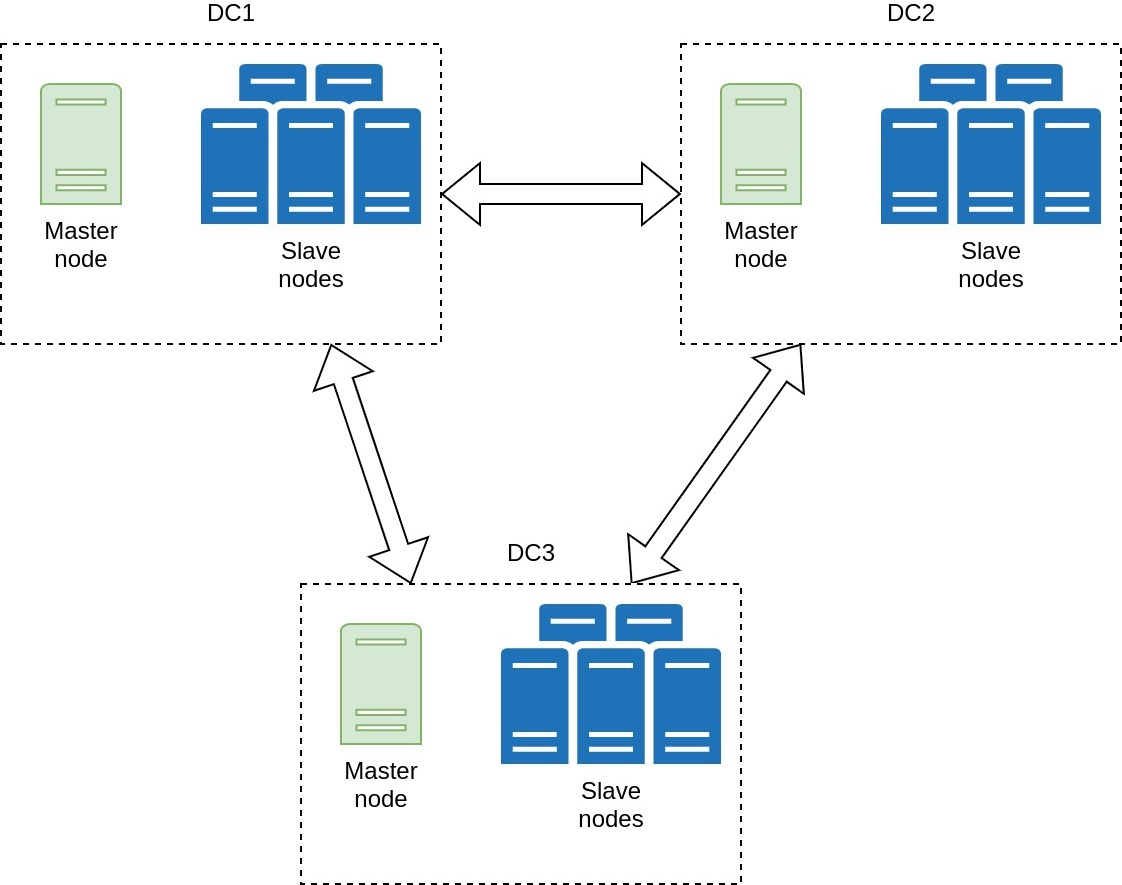
Обе службы работают в режиме High-Availability по принципу Active-Standby. То есть в любой момент времени одна Мастер-нода обслуживает клиентские запросы. Если она становится недоступной, другая Мастер-нода переходит в режим «Активный» и начинает обслуживать клиентские запросы. Таким образом, мы можем пережить сбой центра обработки данных (DC-1) без потери функциональности.
К другим преимуществам этой "растянутой" архитектуры относятся:
- Поставщики данных поддерживают загрузку только в один кластер.
- Репликация с коэффициентом 3, данные хранятся в каждом центре обработки данных (ЦОД).
- Легкое переключение между контроллерами домена во время сбоя DC-1.
- Добавление новых ресурсов практически «по запросу».
- Миграция клиентов с одного контроллера домена на другой вызывает проблемы и занимает всего несколько минут.
- Задачи YARN определенной очереди (клиента) выполняются только в одном контроллере домена, и данные считываются только в этом контроллере домена. В результате мы генерируем междисциплинарный трафик только во время записи.
Отличительные особенности HMDC
- HDFS в HMDC использует стойку HDFS. -осведомленность по принципу «==один ЦОД – одна стойка==» Определение ближайшего кластера указано в файле
core-site.xml. HDFS развертывается в конфигурации высокой доступности с QJM и, как услуга состоит из следующих компонентов: - Узел имен HDFS
- Журнальный узел HDFS
- HDFS ZKFC
- HTTPFS
-
Узел данных HDFS
* YARN Capacity Scheduler в HMDC использует метки узлов для распределения ресурсов между диспетчерами узлов в разных центрах обработки данных. ПРЯЖА представлена следующими компонентами: * Менеджер ресурсов пряжи * Менеджер узлов YARN
Узлы данных HDFS (DN) и диспетчеры узлов YARN (NM) настраиваются на машинах, функционально сгруппированных как подчиненные узлы. Это основные рабочие машины в кластере: сумма доступных объемов выделенных жестких дисков (с учетом репликации), оперативной памяти и виртуальных ядер на этих машинах составляет общий пул ресурсов HMDC. кластер.
Службы управления — HDFS Namenode, ZKFC, YARN ResourceManager, HiveServer2 и HiveMetastore — размещаются на машинах, сгруппированных как главные узлы. В каждом центре обработки данных есть один главный узел. Конфигурация каждой службы реализована таким образом, что три главных узла обеспечивают высокую доступность службы в целом.
Основные компоненты системы
Давайте подробнее рассмотрим основные компоненты системы.
* Узел данных HDFS (DN)
HDFS Datanode — это служба, отвечающая за хранение данных на компьютерах кластера, и демон, управляющий данными. На машине он представлен как служба systemd с именем hadoop-hdfs-datanode.service и запускается от имени пользователя root, поскольку для безопасной работы ему требуется доступ к привилегированным портам.< /p>
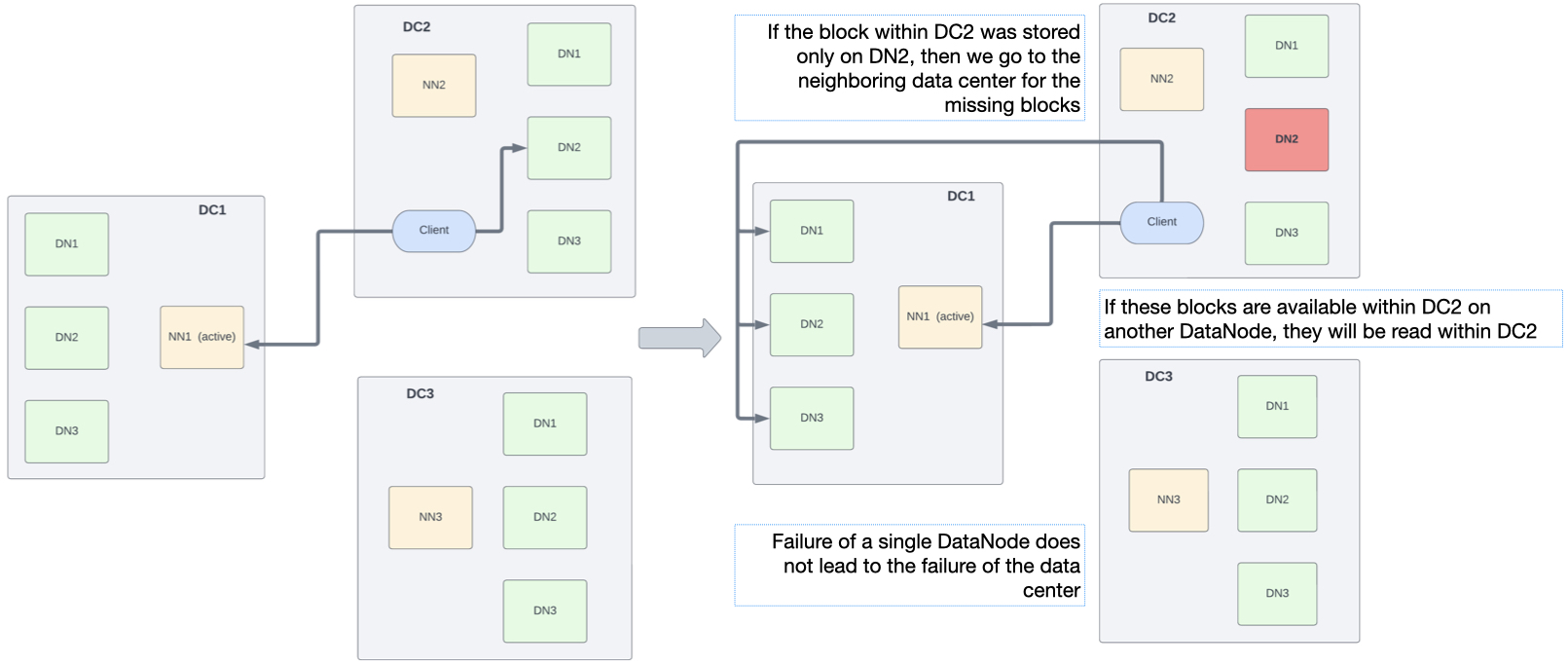
* Менеджер узлов YARN (NM)
YARN NodeManager — это демон, который управляет работой процессов приложений YARN на определенном компьютере. Когда приложение YARN принимается диспетчером ресурсов (RM), он указывает выбранному NM выделить ресурсы (память и виртуальные ядра) для контейнера, в котором будет выполняться конкретный процесс приложения (например, Spark Executor, Spark Driver, MapReduce). Преобразователь или Редуктор).
* Узел имен HDFS (NN)
HDFS NameNode — это основной управляющий сервис HDFS. В кластере HMDC одновременно работают три NN, но в любой момент времени может быть активен только один. Две другие NN в это время находятся в состоянии ожидания (иногда их называют резервными NN или SbNN).
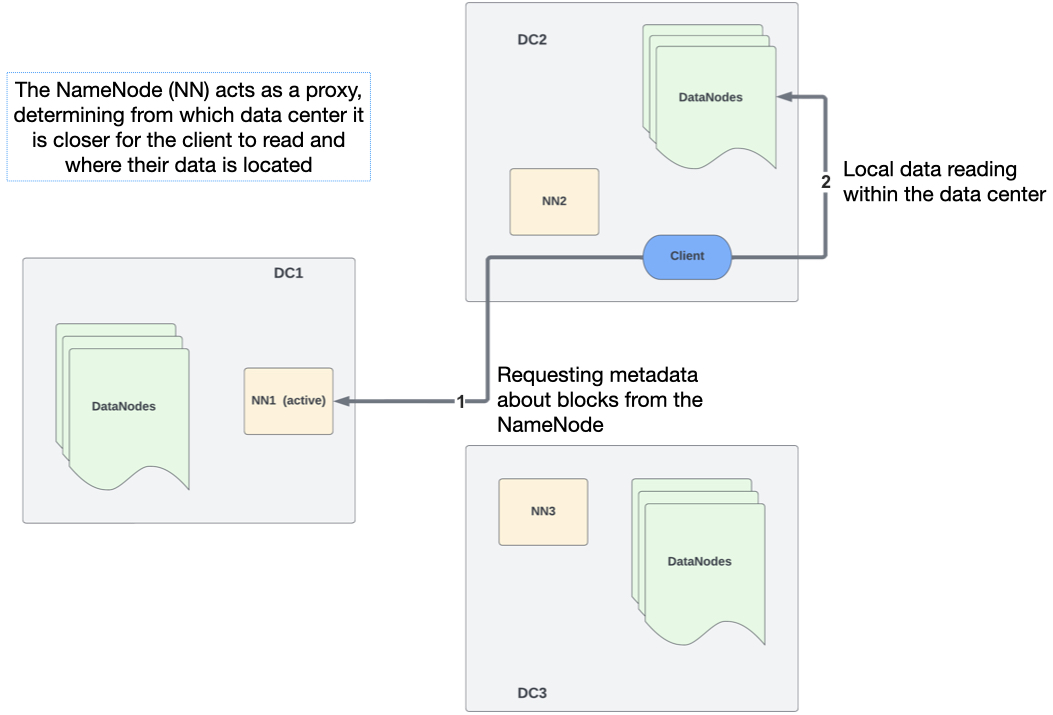
* Журнальный узел HDFS (JN)
HDFS JournalNode — это демон, отвечающий за синхронизацию изменений пространства имен HDFS между узлами имен. На каждом главном узле запущена служба systemd с именем hadoop-hdfs-journalnode, и вместе они поддерживают распределенный журнал QJM. Активный NN сообщает об изменениях в пространстве имен HDFS посредством правок, которые несут информацию о завершенных транзакциях в HDFS.
* HDFS ZKFC
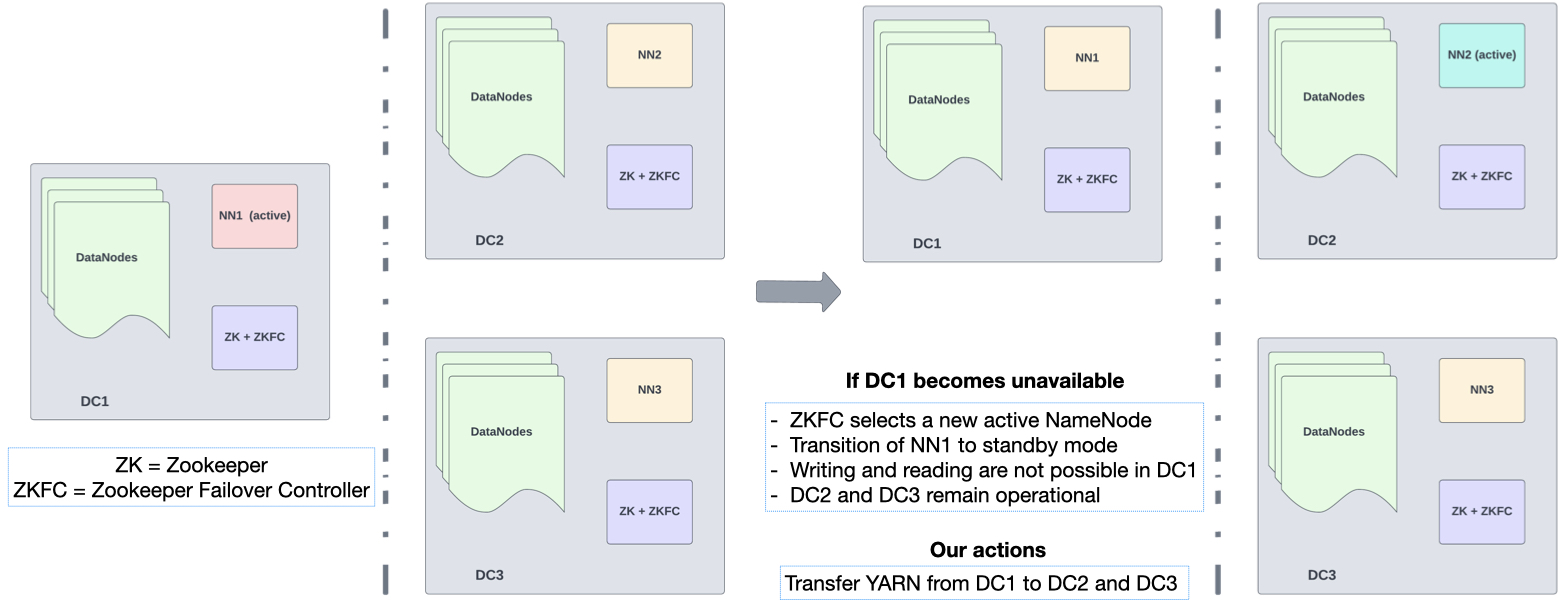
Чтобы обеспечить автоматическое обнаружение сбоев компонентов высокой доступности (HA) HDFS и автоматический переход на другой ресурс, кворум Zookeeper и ZKFailoverController (ZKFC) работают на главных узлах HMDC. ZKFC — это процесс, представленный службой systemd hadoop-hdfs-zkfc.service, выступающей в роли клиента Zookeeper и обеспечивающей:
* Мониторинг состояния NN с помощью зондов проверки работоспособности.
* Управление сессиями в Zookeeper: ZKFC сохраняет активную сессию в Zookeeper, если NN исправен. Кроме того, если NN активен, он содержит znode.
* Если NN исправна и никакая другая NN не владеет znode, ZKFC попытается выиграть выборы для новой активной NN.
- Zookeeper в HMDC
Серверы Zookeeper также развернуты на главных узлах, предоставляя средства для распределенной координации служб высокой доступности. Zookeeper выполняет две основные функции: * Обнаружение неисправностей в работе NN. * Обеспечение переизбрания действующего NN.
* YARN ResourceManager (RM)
YARN ResourceManager — это служба, отвечающая за управление ресурсами в кластере YARN. Он работает в конфигурации высокой доступности и представлен как служба systemd с именем hadoop-yarn-resourcemanager.service на главных узлах. Он предоставляет веб-интерфейс на порту 8088 (резервный RM всегда перенаправляется на пользовательский интерфейс активного RM). Чтобы полностью использовать ресурсы и предотвратить простои, RM реализует два механизма:
* Эластичность очереди: Каждой очереди назначаются параметры, определяющие гарантированные и максимально возможные ресурсы. Если ресурсы в очереди недоиспользованы, приложение может получить больше ресурсов, чем гарантировано, но не превышая значений, установленных вторым параметром.
* Container Preemption: чтобы гарантировать, что приложения всегда получают гарантированные ресурсы, существует механизм возврата ресурсов из уже запущенных приложений, которые используют больше своих гарантированных возможностей. Контейнеры завершаются с соответствующим кодом выхода и статусом в пользовательском интерфейсе. Когда клиент проходит аутентификацию в кластере и отправляет запрос на запуск приложения, RM вычисляет, доступны ли требуемые ресурсы, принимает приложение в очередь и выделяет ему память и виртуальные ядра.
- Высокая доступность Hive
Высокая доступность для Hive достигается за счет установки нескольких серверов Hive Metastore и Hiveserver2 в каждом из центров обработки данных соответственно. Для HA Hiveserver2 используется Zookeeper. Вы можете подключиться к Hiveserver2 с помощью JDBC. Когда serviceDiscoveryMode=zooKeeper, устанавливается соединение со случайно доступным сервером Hiveserver2.
Преимущества HMDC
Как я уже говорил в самом начале - мы стояли перед выбором: создавать независимые дата-центры, где каждый потребитель находится в своем дата-центре (в нашем случае их 3) или реализовать эту концепцию - HMDC . Стоит отметить, что несмотря на разделение потребителей по центрам обработки данных - многим потребителям нужны одни и те же данные (разделить данные невозможно).
Давайте сравним эти две парадигмы:
| | Независимые DC | ГМДС | |----|----|----| | Управление данными | ×3, сопоставление | ==В виде единого кластера== | | Ошибка данных | Возможные потери | Возможные потери | | Объем данных | ×3 - ×9 | ==×3== | | Миграция потерь постоянного тока | Несколько недель | ==Часы редактирования конфига== | | Репликация данных между контроллерами домена | Индивидуальный сервис | == Функциональность HDFS == | | Поддержка | 3 разных домена | ==Единый кластер== | | Неравенство кластеров | ==Гибкость в загрузке== | Правила размещения блоков |
Что нам дает HMDC в целом?
- В случае сбоя контроллера домена вы можете перенести пользователей, просто изменив конфигурацию.
- Эта концепция позволяет управлять данными в соответствии с парадигмой "==это единый кластер==".
- В случае ошибки при обработке данных возможна потеря данных, так как репликация не может быть выполнена.
- Объем хранимых данных распределяется по трем центрам обработки данных, по одной копии в каждом центре обработки данных. Да, это создает некоторые недостатки. Уменьшая репликацию до двух, вы рискуете увеличить нагрузку на сеть из-за извлечения данных из других центров обработки данных.
- Репликация данных между центрами обработки данных осуществляется с помощью функции HDFS.
- При необходимости и при надлежащем контроле вы можете управлять сохраненными данными, изолируя их в одном из контроллеров домена благодаря политике размещения блоков HDFS.
- Вы можете добавлять серверы и центры обработки данных к своей установке практически по требованию, когда требуется масштабируемость.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27116)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)