

Начало работы с распределенным SQL
11 января 2023 г.распределенная база данных SQL позволяет масштабировать операции чтения и записи путем добавления узлов в кластер, сохраняя при этом все преимущества реляционных баз данных. Ключевой особенностью распределенной базы данных SQL является то, что она делает кластер похожим на единую логическую базу данных. Приложениям не нужно знать количество узлов или реализовывать логику сегментирования.
Расширение MariaDB
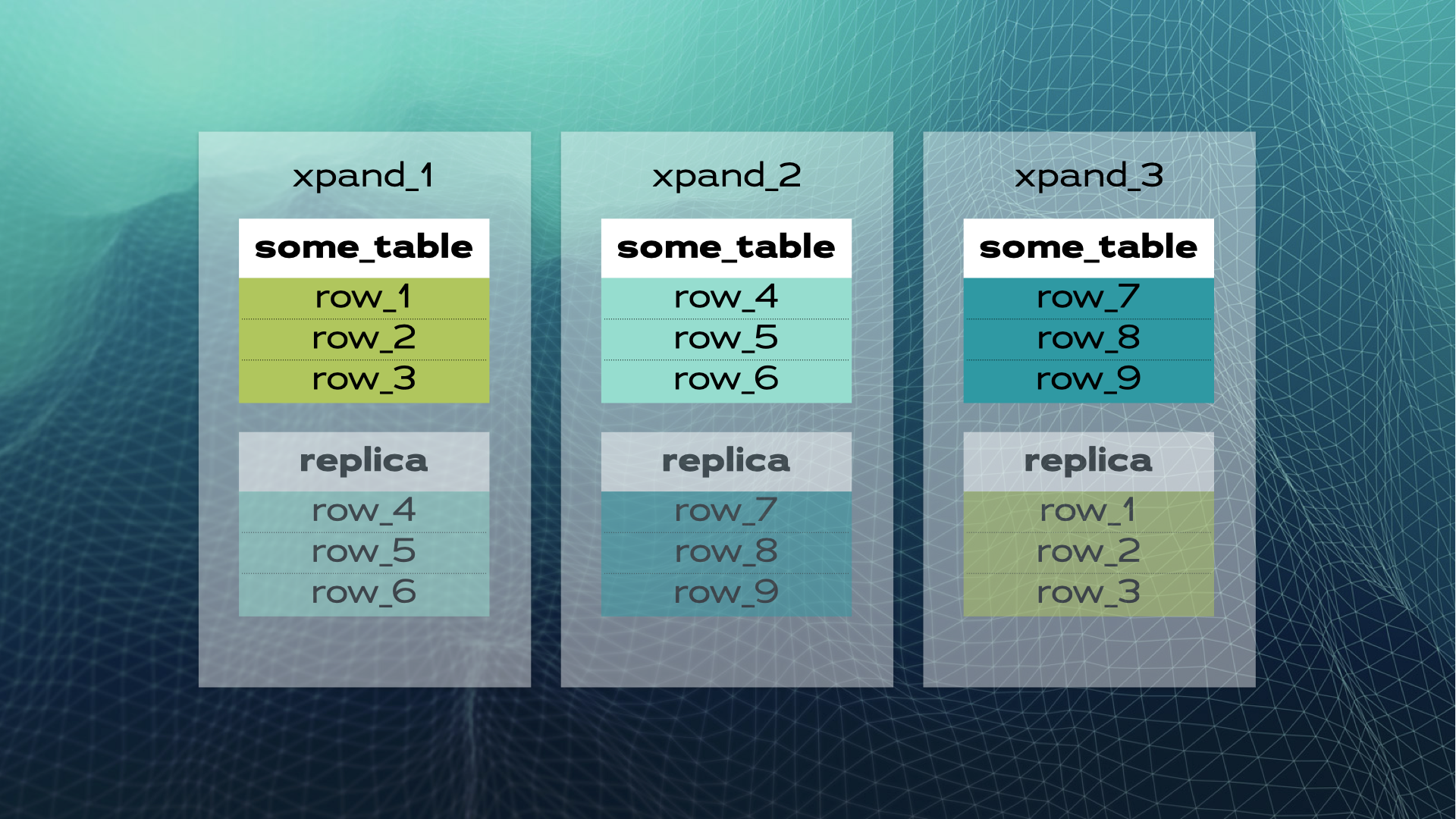
MariaDB Xpand — это распределенная база данных SQL, совместимая с MariaDB, в которой таблицы SQL автоматически секционируются на основе хэша подмножество столбцов (первичный ключ по умолчанию). Каждый раздел формирует срез данных, который размещается в узле. Когда происходит запись, вычисляется хэш, и операция перенаправляется на правильный узел. MariaDB Xpand перебалансирует данные, когда узел выходит из строя, добавляется новый узел или обнаруживается горячая точка. Все это происходит автоматически и прозрачно для приложения.
Множественные записи могут быть отправлены параллельно нескольким узлам. Чтения перенаправляются на узлы, содержащие срезы с данными, и могут выполняться параллельно, сводя к минимуму задержку. Эта архитектура способна обрабатывать большие объемы данных и поддерживать высокий уровень производительности, превосходящий нераспределенные базы данных. Запрос отправляется к данным вместо данных к запросу.
На следующей диаграмме показан пример кластера базы данных MariaDB Xpand с тремя узлами. Каждый фрагмент показан другим цветом. На диаграмме также показано, как реплики автоматически поддерживаются для обеспечения высокой доступности:
В процессе масштабирования добавляется новый узел (xpand_4 на следующем рисунке). MariaDB автоматически перебалансирует данные, чтобы увеличить общую производительность системы:
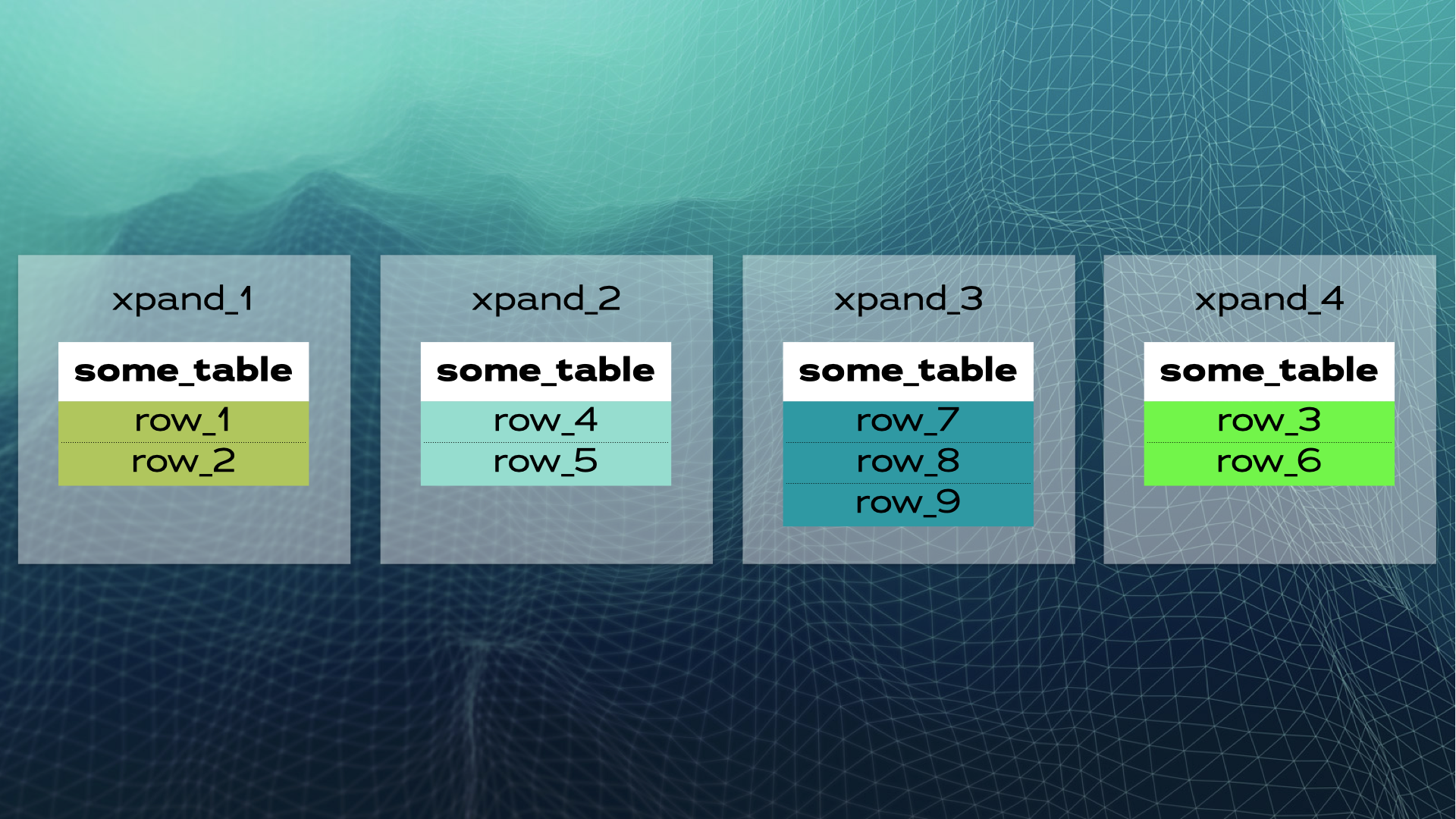
Распределенный SQL — лучшая альтернатива ручному сегментированию базы данных. Он освобождает инженеров DevOps и администраторов баз данных от утомительных операций управления, таких как повторная балансировка данных. Это также освобождает разработчиков от необходимости реализовывать и поддерживать пользовательскую логику сегментирования, которая увеличивает сложность запросов (особенно с соединениями между узлами). Разработчик может просто написать запрос SQL, как если бы это была база данных с одним узлом.
Начало работы с Docker
Лучший способ начать работу с распределенным SQL — попробовать его. Docker делает этот процесс чрезвычайно простым. Чтобы развернуть экземпляр MariaDB Xpand с одним узлом, подходящий для тестирования и экспериментов с использованием Docker, выполните следующее:
docker run --rm -p3306:3306 --ulimit memlock=-1 --name xpand mariadb/xpand-single
Вы можете подключиться к базе данных, как если бы это был одноузловой сервер MariaDB. См. этот веб-сайт, чтобы узнать, как подключиться с нескольких языков программирования (Java, JavaScript/NodeJS, Python, C++). Вы также можете подключаться из клиентов SQL, таких как DBeaver, DataGrip или любых расширений IDE для баз данных SQL.
После того, как вы опробовали свое приложение с экземпляром Xpand с одним узлом, лучший способ проверить его масштабируемость и другие расширенные функции (например, автоматическое масштабирование и столбцовое индексирование для аналитики) — пройти через SkySQL, облачный сервис, предлагающий бесплатный уровень (кредитная карта не требуется).
Кроме того, существует множество онлайн-ресурсов, где можно узнать больше о распределенном SQL и MariaDB Xpand:
* Распределенный SQL для чайников (бесплатная книга) * Начало работы с распределенным SQL (refcard) * документация MariaDB Xpand * MariaDB Xpand для распределенного SQL (видео-анимация) * Вывод распределенного SQL на новый уровень с помощью столбцового индексирования (обсуждение) * Что такое распределенный SQL? (вебинар) * Distributed SQL Essentials (refcard)< /p>
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27740)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)