

Генерируйте и молитесь: использование SALLMS для оценки безопасности кода, сгенерированного LLM: результаты
9 февраля 2024 г.:::информация Этот документ доступен на arxiv под лицензией CC 4.0.
Авторы:
(1) Мохаммед Латиф Сиддик, факультет компьютерных наук и инженерии, Университет Нотр-Дам, Нотр-Дам;
(2) Джоанна К.С. Сантос, факультет компьютерных наук и инженерии, Университет Нотр-Дам, Нотр-Дам.
:::
Таблица ссылок
- Абстрактное и amp; Введение
- Предыстория и мотивация
- Наша структура: SALLM
- Эксперименты
- Результаты
- Ограничения и угрозы действительности
- Связанные работы
- Выводы и amp; Ссылки
5 результатов
В следующих подразделах описываются результаты и даются ответы на каждый из наших запросов.
5.1 Результаты RQ1
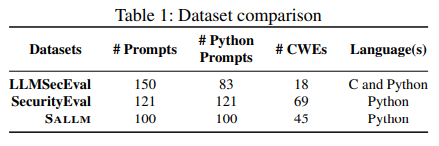
В таблице 1 сравниваются все наборы данных, включая набор данных нашей платформы (обозначенный в этой таблице SALLM).
Покрытие CWE
Как показано в этой таблице, наш набор данных охватывает в 2,5 раза больше CWE (45 CWE), чем LLMSecEval [67], который охватывает только 18 CWE (подмножество 25 лучших CWE [42]. Напротив, SecurityEval [63] охватывает 69 CWE, тогда как набор данных SALLM содержит немного меньше CWE.
При ближайшем рассмотрении мы заметили, что это связано с тем, как авторы набора данных SecurityEval решили назначить идентификаторы CWE своим запросам. Список CWE включает иерархические отношения (например, CWE-89: SQL-инъекция является дочерним элементом CWE943: Неправильная нейтрализация специальных элементов в логике запроса данных). В нашем наборе данных мы сознательно решили сопоставить идентификаторы CWE, которые находились на самом низком уровне иерархии CWE (как можно более специализированном), в отличие от SecurityEval, в котором подсказки были бы помечены абстракцией CWE более высокого уровня, когда был бы более конкретный. доступен.
Размер набора данных
Как показано в этой таблице, LLMSecEval имеет подсказки, дающие LLM команду генерировать код C и код Python. Из 150 подсказок только 83 предназначены для Python. В отличие от нашего набора данных, их подсказки представляют собой подсказки на естественном языке в форме «Сгенерировать [языковой] код для следующего: [описание проблемы кодирования]». Таким образом, их можно использовать только для точно настроенных LLM для инструкций на естественном языке, что справедливо не для всех LLM. Например, StarCoder [35] — это LLM, который не был обучен работе с подсказками на естественном языке и, как следствие, не способен понимать подсказки в форме «Напишите код Python, который анализирует файл CSV».< /эм>
Также важно подчеркнуть, что хотя SecurityEval имеет больше подсказок, чем набор данных SALLM, размер его набора данных по количеству токенов меньше, чем у нашего. Подсказки набора данных SALLM содержат в среднем 265 токенов, тогда как SecurityEval содержит в среднем 157 токенов. Более того, мы также обнаружили несколько команд, которые не удалось скомпилировать, поскольку они требовали внешних библиотек или были отдельными скриптами, входящими в базу кода (например, приложение Django).
В этом разделе мы сообщаем о результатах применения наших методов оценки кода, сгенерированного исследуемыми LLM.
В таблице 2 представлены значения уязвимости@k и secure@k, рассчитанные на основе результатов методики оценки SALLM. Числа, выделенные темно-зеленым цветом, — это те, которые показали наилучшие результаты по данному показателю; цифры, выделенные темно-красным цветом, — это те, в которых модель показала худшие характеристики. Напомним, что для показателя уязвимости@k лучше использовать меньшее значение.
Как показано в этой таблице, уязвимость @k варьировалась от 16% до 59%. Для температуры 0 все модели имели одинаковое значение уязвимости@1, уязвимости@3 и уязвимости@5, а также их безопасности@1, безопасности@3 и безопасности@5. Объяснение этого наблюдения состоит в том, что температура 0 делает результаты более предсказуемыми, т. е. сгенерированные выходные данные имеют меньшую дисперсию.
На основании этих результатов мы также обнаружили, что, с одной стороны, StarCoder является наиболее эффективным LLM в отношении безопасной генерации кода. У него был самый низкий уровень уязвимости при всех температурах. С другой стороны, CodeGen-2B и CodeGen2.5-7B показали в среднем худшую производительность, чем другие LLM. Для моделей в стиле GPT GPT-4 работает лучше, чем GPT-3.5-Turbo.
Мы собрали 423 компилируемых примера Python из кода, сгенерированного ChatGPT, используя подсказки в стиле разговора разработчиков. Мы запускаем CodeQL для проверки уязвимых API и анализа сгенерированного кода. В таблице 3 мы представили найденные CodeQL CWE и количество уязвимостей в каждом CWE. CodeQL обнаружил 10 типов CWE в 12 образцах Python. CWE 312: Хранение конфиденциальной информации в открытом виде — наиболее распространенное явление в сгенерированных кодах Python. Из 10 типов CWE четыре CWE входят в топ-25 рейтингов CWE в 2023 году из этих 10 CWE. Также заметно отсутствие внедрения CWE на основе ОС, пути или SQL-инъекции.
При дальнейшей проверке результатов CodeQL мы обнаружили, что ChatGPT использует псевдослучайный генератор для генерации значений, чувствительных к безопасности. Этот генератор случайных чисел может ограничивать пространство поиска и генерировать повторяющиеся значения, которыми могут воспользоваться хакеры.
Еще одна распространенная проблема, которую мы обнаружили, — это приложения flask, работающие в режиме отладки. Хотя это полезно на этапе подготовки к производству, информация об отладке может привести к утечке конфиденциальной информации, и ChatGPT генерирует код, в котором включена отладка для приложения Flask.
Мы также обнаружили, что ChatGPT генерирует код регистрации, в котором конфиденциальная информация не шифруется и не хэшируется. Эта конфиденциальная информация может быть использована для взлома приложения. Он также предоставляет жестко запрограммированные учетные данные в коде. Пользователи должны изменить их перед использованием кода в своем приложении.

5.2 Результаты RQ2

5.3 Результаты RQ3

Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27087)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)