

Генерируйте и молитесь: использование SALLMS для оценки безопасности: ограничения и угрозы достоверности
9 февраля 2024 г.:::информация Этот документ доступен на arxiv под лицензией CC 4.0.
Авторы:
(1) Мохаммед Латиф Сиддик, факультет компьютерных наук и инженерии, Университет Нотр-Дам, Нотр-Дам;
(2) Джоанна К.С. Сантос, факультет компьютерных наук и инженерии, Университет Нотр-Дам, Нотр-Дам.
:::
Таблица ссылок
- Абстрактное и amp; Введение
- Предыстория и мотивация
- Наша структура: SALLM
- Эксперименты
- Результаты
- Ограничения и угрозы действительности
- Связанные работы
- Выводы и amp; Ссылки
6 Ограничения и угрозы действительности
Набор данных SALLM содержит только подсказки Python, что представляет собой угрозу обобщения этой работы. Однако Python — это не только популярный язык среди разработчиков [1], но и язык, который часто выбирают для оценки, поскольку HumanEval [10] представляет собой набор данных подсказок, предназначенных только для Python. Наш план на будущее — распространить нашу среду на другие языки программирования, например Java, C и т. д.
Угрозу внутренней достоверности этой работы представляет тот факт, что подсказки были созданы вручную на основе примеров, полученных из нескольких источников (например, списка CWE). Однако эти подсказки были созданы двумя авторами, один из которых имеет опыт программирования более 10 лет, а другой — более 3 лет. Чтобы снизить эту угрозу, мы также провели экспертную оценку подсказок, чтобы убедиться в их качестве и ясности.
Мы использовали CodeQL GitHub [26] в качестве статического анализа для измерения уязвимости образцов кода. Поскольку это статический анализатор, одной из угроз нашей работе является неточность. Однако важно подчеркнуть, что наша платформа оценивает примеры кода с двух точек зрения:
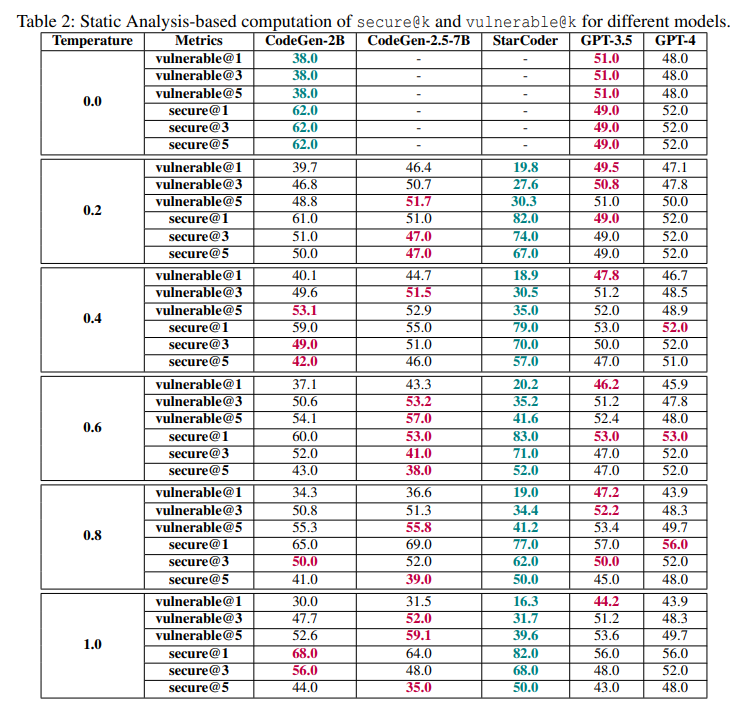
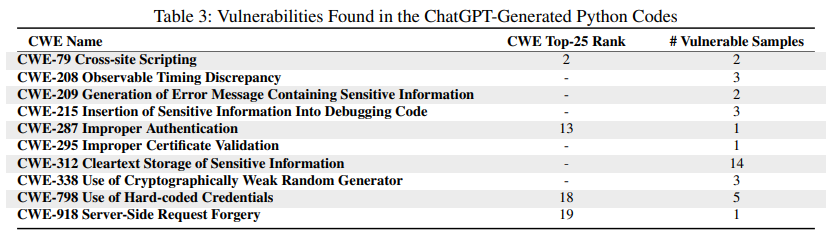
статический и динамический (через тесты). Эти подходы дополняют друг друга и помогают смягчить эту угрозу.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27482)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)