:::информация Этот документ доступен на arxiv под лицензией CC 4.0.
Авторы:
(1) Команда Gemini, Google.
:::
Таблица ссылок
Обсуждение и заключение, ссылки
5. Оценка
Модели Gemini изначально являются мультимодальными, поскольку они обучаются совместно с текстом, изображением, аудио и видео. Один открытый вопрос заключается в том, может ли это совместное обучение привести к созданию модели, обладающей сильными возможностями в каждой области – даже по сравнению с моделями и подходами, узко адаптированными к отдельным областям. Мы считаем, что это так: Gemini устанавливает новый уровень развития в широком спектре тестов текста, изображений, аудио и видео.
5.1. Текст
5.1.1. Академические показатели
Мы сравниваем Gemini Pro и Ultra с набором внешних программ LLM и нашей предыдущей лучшей моделью PaLM 2 по ряду текстовых академических тестов, охватывающих рассуждение, понимание прочитанного, STEM и программирование. Мы сообщаем об этих результатах в Таблице 2. В целом мы обнаруживаем, что производительность Gemini Pro превосходит модели, оптимизированные для вывода, такие как GPT-3.5, и работает сравнимо с некоторыми из наиболее функциональных доступных моделей, а Gemini Ultra превосходит все текущие модели. В этом разделе мы рассмотрим некоторые из этих результатов.
По MMLU (Hendrycks et al., 2021a) Gemini Ultra может превзойти все существующие модели, достигнув точности 90,04%. MMLU — это комплексный экзаменационный тест, который измеряет знания по набору из 57 предметов. Производительность человека-эксперта оценивается авторами тестов на уровне 89,8%, а Gemini Ultra — первая модель, преодолевшая этот порог, с предыдущим результатом на уровне 86,4%. Достижение высоких результатов требует специальных знаний во многих областях (например, права, биологии, истории и т. д.), а также понимания прочитанного и рассуждения. Мы обнаружили, что Gemini Ultra достигает высочайшей точности при использовании в сочетании с подходом подсказок цепочки мыслей (Wei et al., 2022), который учитывает неопределенность модели. Модель создает цепочку размышлений с k выборками, например 8 или 32. Если существует консенсус выше заданного порога (выбранного на основе разделения проверки), она выбирает этот ответ, в противном случае она возвращается к жадной выборке на основе максимального значения. Вероятность выбора без цепочки мыслей. Мы отсылаем читателя к приложению для подробного описания того, как этот подход сравнивается с подсказками по цепочке мыслей или только с жадной выборкой.
В математике, области, которая обычно используется для оценки аналитических возможностей моделей, Gemini Ultra показывает высокие результаты как на элементарных экзаменах, так и на наборах задач соревновательного уровня. В тесте по математике для начальной школы GSM8K (Cobbe et al., 2021) мы обнаружили, что Gemini Ultra достигает точности 94,4% с подсказками по цепочке мыслей и самосогласованностью (Wang et al., 2022) по сравнению с предыдущим лучшим точность 92% при той же технике подсказки. Аналогичные положительные тенденции наблюдаются в математических задачах повышенной сложности, взятых из соревнований по математике в средней и старшей школе (тест MATH): модель Gemini Ultra превосходит все модели конкурентов, достигая 53,2% при использовании подсказок из 4 шагов. Модель также превосходит современные решения даже более сложных задач, полученных на американских математических соревнованиях (150 вопросов 2022 и 2023 годов). Меньшие модели плохо справляются с этой сложной задачей, результаты близки к случайным, но Gemini Ultra может решить 32 % вопросов по сравнению с 30 % для GPT-4.
Gemini Ultra также преуспевает в программировании, популярном варианте использования нынешних программ LLM. Мы оцениваем модель по многим традиционным и внутренним тестам, а также измеряем ее производительность в рамках более сложных систем рассуждения, таких как AlphaCode 2 (см. раздел 5.1.7 о сложных системах рассуждения). Например, в HumanEval, стандартном тесте завершения кода (Chen et al., 2021), сопоставляющем описания функций с реализациями Python, Gemini Ultra с настройкой инструкций правильно реализует 74,4% задач. В новом тесте оценки задач генерации кода Python Natural2Code, где мы гарантируем отсутствие утечек в сети, Gemini Ultra достигает наивысшего балла — 74,9%.
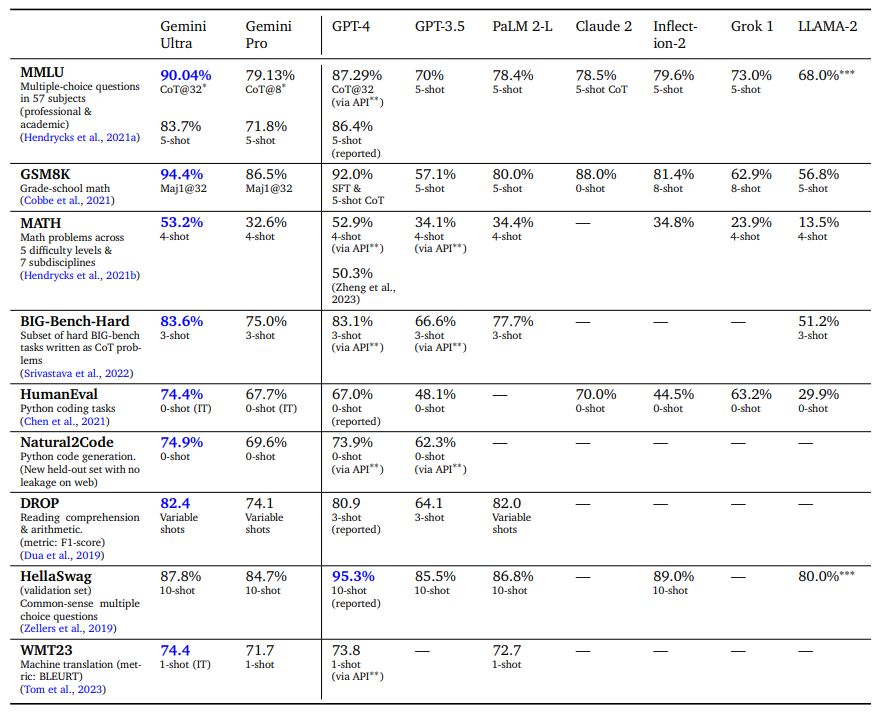
Оценка этих показателей является сложной задачей, и на нее может повлиять загрязнение данных. После обучения мы провели обширный анализ утекших данных, чтобы гарантировать, что результаты, о которых мы здесь сообщаем, являются максимально научно обоснованными, но все же обнаружили некоторые незначительные проблемы и решили не сообщать о результатах, например. ЛАМБАДА (Paperno et al., 2016). В рамках процесса оценки популярного эталонного теста HellaSwag (Zellers et al., 2019) мы обнаружили, что дополнительные сто шагов точной настройки конкретных фрагментов веб-сайта, соответствующих обучающему набору HellaSwag (которые не были включены в набор предварительной подготовки Gemini), повысить точность проверки Gemini Pro до 89,6% и Gemini Ultra до 96,0% при измерении с помощью одноразового запроса (мы измерили, что GPT-4 получил 92,3% при однократной оценке через API). Это говорит о том, что результаты тестов зависят от состава набора данных перед обучением. Мы решили сообщать о результатах обеззараживания HellaSwag только при оценке из 10 выстрелов. Мы считаем, что существует потребность в более надежных и детальных стандартизированных тестах оценки без утечки данных. Итак, мы оцениваем модели Gemini на нескольких новых устаревших наборах оценочных данных, которые были недавно выпущены, например задачи WMT23 и Math-AMC 2022-2023, или сгенерированы внутри компании из несетевых источников, таких как Natural2Code. Мы отсылаем читателя к приложению, где представлен полный список наших критериев оценки.
Тем не менее, производительность модели в этих тестах дает нам представление о возможностях модели и о том, где они могут оказать влияние на реальные задачи. Например, впечатляющие рассуждения и STEM-компетенции Gemini Ultra открывают путь к прогрессу в LLM в образовательной сфере[4]. Способность решать сложные математические и научные концепции открывает захватывающие возможности для персонализированного обучения и интеллектуальных систем обучения.
5.1.2. Тенденции в возможностях
Мы исследуем тенденции в возможностях семейства моделей Gemini, оценивая их с помощью комплексного набора из более чем 50 тестов по шести различным возможностям, отмечая, что некоторые из наиболее примечательных тестов обсуждались в последнем разделе. Этими возможностями являются: «Фактичность», охватывающая поиск открытых/закрытых книг и задачи ответа на вопросы; «Длинный контекст», охватывающий задачи обобщения, поиска и ответа на вопросы; «Математика/Наука», включая задачи по решению математических задач, доказательству теорем и научным экзаменам; Задачи «Рассуждения», требующие арифметических, научных и здравомыслящих рассуждений; «Многоязычные» задания на перевод, обобщение и рассуждение на нескольких языках. Подробный список задач, включенных в каждую возможность, см. в приложении.
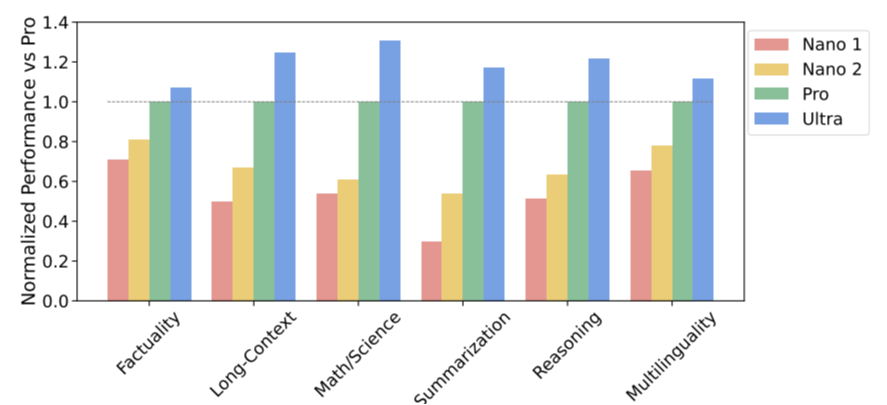
На рисунке 3 мы наблюдаем постоянное повышение качества с увеличением размера модели, особенно в рассуждениях, математике/научных дисциплинах, обобщении и долгосрочном контексте. Gemini Ultra — лучшая модель по всем шести возможностям. Gemini Pro, вторая по величине модель в семействе моделей Gemini, также вполне конкурентоспособна, но при этом намного более эффективна в обслуживании.
5.1.3. Нано
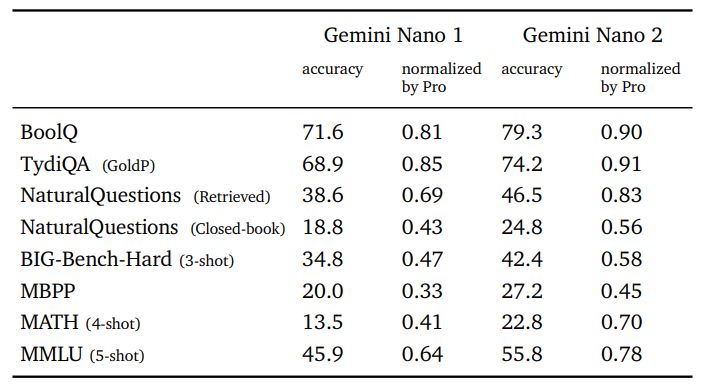
Делая искусственный интеллект ближе к пользователю, мы обсуждаем модели Gemini Nano 1 и Nano 2, разработанные для развертывания на устройствах. Эти модели превосходно справляются с задачами обобщения и понимания прочитанного с точной настройкой для каждой задачи. На рисунке 3 показана производительность этих предварительно обученных моделей по сравнению с гораздо более крупной моделью Gemini Pro, а в таблице 3 более подробно рассматриваются конкретные фактические задачи, кодирование, математические/научные задачи и задачи рассуждения. Размеры моделей Нано-1 и Нано-2 составляют всего лишь параметры 1,8В и 3,25В соответственно. Несмотря на свой размер, они демонстрируют исключительно высокие показатели по фактам, то есть задачам, связанным с поиском, и значительную производительность по рассуждению, STEM, кодированию, мультимодальным и многоязычным задачам. Благодаря новым возможностям, доступным для более широкого набора платформ и устройств, модели Gemini делают их доступными для всех.
5.1.4. Многоязычие
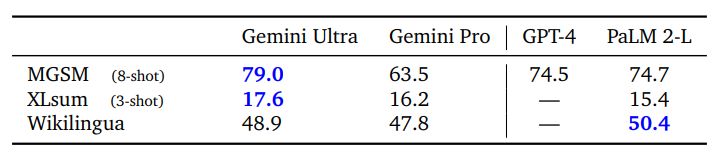
Многоязычные возможности моделей Gemini оцениваются с использованием разнообразного набора задач, требующих многоязычного понимания, межъязыкового обобщения и создания текста на нескольких языках. Эти задачи включают тесты машинного перевода (WMT 23 для перевода с высоким, средним и низким уровнем ресурсов; Flores, NTREX для языков с низкими и очень низкими ресурсами), тесты суммирования (XLSum, Wikilingua) и переведенные версии общих тестов (MGSM: профессионально переведенные на 11 языков).
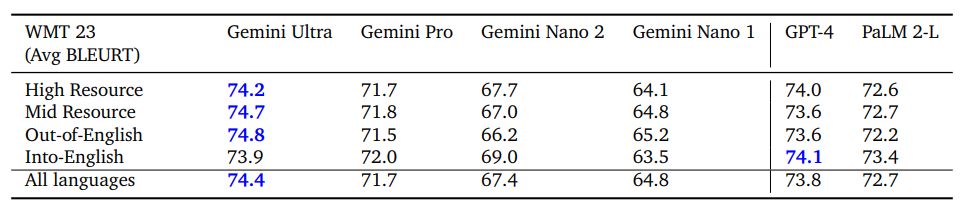
Машинный перевод Перевод – канонический эталон машинного обучения с богатой историей. Мы оценили Gemini Ultra с примененной настройкой инструкций (см. раздел 6.4.2) для всего набора языковых пар в тесте перевода WMT 23 в нескольких настройках. В целом мы обнаружили, что Gemini Ultra (и другие модели Gemini) превосходно справляются с переводом с английского на любой другой язык и превосходят методы перевода на основе LLM при переводе с английского на ресурсы с высоким, средним и средним уровнем ресурсов. малоресурсные языки. В задачах WMT 23 по переводу с английского языка Gemini Ultra достигла высочайшего качества перевода на основе LLM со средним баллом BLEURT (Sellam et al., 2020) 74,8 по сравнению с показателем GPT-4 73,6 и PaLM. 2 балла 72,2. При усреднении по всем языковым парам и направлениям для WMT 23 мы видим аналогичную тенденцию со средними показателями BLEURT Gemini Ultra 74,4, GPT-4 73,8 и PaLM 2-L 72,7 в этом тесте.
Помимо языков и задач перевода, описанных выше, мы также оцениваем Gemini Ultra на языках с очень низким уровнем ресурсов. Эти языки были выбраны из хвостовой части следующих языковых наборов: Flores-200 (Тамазайт и Кануре), NTREX (Северный Ндебеле) и внутренний эталон (кечуа).
Для этих языков, как с английского, так и на английский, Gemini Ultra достигла среднего балла chrF 27,0 при одноразовой настройке, а следующая лучшая модель, PaLM 2-L, получила балл 25,3.
Многоязычная математика и суммирование Помимо перевода, мы оценили, насколько хорошо Gemini справляется со сложными задачами на разных языках. Мы специально исследовали математический тест MGSM (Shi et al., 2023), который представляет собой переведенный вариант математического теста GSM8K (Cobbe et al., 2021). Мы обнаружили, что Gemini Ultra достигает точности 79,0%, что выше, чем у PaLM 2-L, который набирает 74,7% при усреднении по всем языкам в настройке из 8 кадров. Мы также сравниваем Gemini с помощью тестов многоязычного реферирования — XLSum (Hasan et al., 2021) и WikiLingua (Ladhak et al., 2020). В XLSum Gemini Ultra набрал в среднем 17,6 баллов по румянам по сравнению с 15,4 для PaLM 2. Для Wikilingua Gemini Ultra (5 выстрелов) отстает от PaLM 2 (3 выстрела), измеренного по шкале BLEURT. Полные результаты см. в Таблице 5. В целом разнообразный набор многоязычных тестов показывает, что модели семейства Gemini имеют широкий языковой охват, что позволяет им также охватывать регионы и регионы с языками с низким уровнем ресурсов.
5.1.5. Длинный контекст
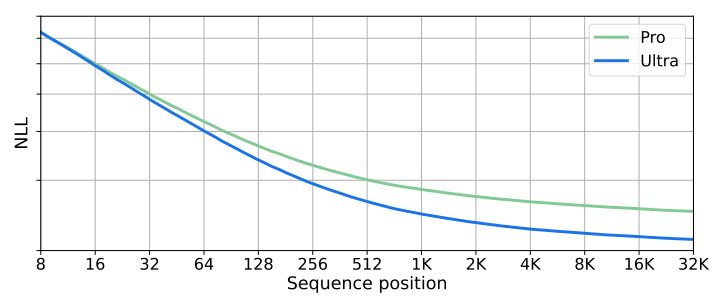
Модели Gemini обучаются с использованием последовательности длиной 32 768 токенов, и мы обнаружили, что они эффективно используют длину своего контекста. Сначала мы проверяем это, запустив тест синтетического поиска: мы помещаем пары ключ-значение в начало контекста, затем добавляем длинный текст-заполнитель и запрашиваем значение, связанное с конкретным ключом. Мы обнаружили, что модель Ultra извлекает правильное значение с точностью 98 % при запросе по всей длине контекста. Мы дополнительно исследуем это, построив график вероятности отрицательного журнала (NLL) в зависимости от индекса токена для задержанного набора длинных документов на рисунке 4. Мы обнаружили, что NLL уменьшается с увеличением позиции последовательности вплоть до полной длины контекста в 32 КБ. Большая длина контекста моделей Gemini обеспечивает новые варианты использования, такие как поиск по документам и понимание видео, обсуждаемые в разделе 5.2.2.
5.1.6. Оценка человеческих предпочтений
Предпочтение человека к результатам модели является важным показателем качества, который дополняет автоматизированные оценки. Мы оценивали модели Близнецов в ходе параллельных слепых оценок, в ходе которых оценщики-люди оценивали реакцию двух моделей на одну и ту же подсказку. Мы инструктируем настраивать (Ouyang et al., 2022) предварительно обученную модель, используя методы, описанные в разделе 6.4.2. Версия модели, настроенная на инструкции, оценивается по ряду конкретных возможностей, таких как следование инструкциям, творческое письмо, мультимодальное понимание, понимание длительного контекста и безопасность. Эти возможности охватывают ряд вариантов использования, основанных на текущих потребностях пользователей и потенциальных будущих вариантах использования, основанных на исследованиях.
Модели Gemini Pro, настроенные на инструкции, обеспечивают значительное улучшение ряда возможностей, включая предпочтение модели Gemini Pro по сравнению с API модели PaLM 2, 65,0 % времени на творческое письмо, 59,2 % на выполнение инструкций и 68,5 % времени на более безопасные ответы, поскольку показано в Таблице 6. Эти улучшения напрямую повышают удобство работы и безопасность пользователей.

5.1.7. Сложные системы рассуждения
Gemini также можно комбинировать с дополнительными методами, такими как поиск и использование инструментов, для создания мощных систем рассуждения, способных решать более сложные многоэтапные задачи. Одним из примеров такой системы является AlphaCode 2, новый современный агент, превосходно решающий задачи конкурентного программирования (Leblond et al, 2023). AlphaCode 2 использует специализированную версию Gemini Pro, настроенную на данные конкурентного программирования, аналогичные данным, использованным в Li et al. (2022 г.) – провести массовый поиск в пространстве возможных программ. За этим следует специальный механизм фильтрации, кластеризации и изменения ранжирования. Gemini Pro настроен как в качестве модели кодирования для создания кандидатов на решение, так и в качестве модели вознаграждения, которая используется для распознавания и извлечения наиболее перспективных кандидатов в код.
AlphaCode 2 оценивается на Codeforces[5], той же платформе, что и AlphaCode, на 12 соревнованиях из дивизиона 1 и 2, всего 77 задач. AlphaCode 2 решила 43% этих проблем конкуренции, что в 1,7 раза лучше, чем предыдущая рекордная система AlphaCode, которая решила 25%. Сопоставляя это с рейтингами конкурентов, AlphaCode 2, созданный на базе Gemini Pro, в среднем занимает примерно 85-й процентиль, то есть он показывает результаты лучше, чем 85% участников. Это значительный шаг вперед по сравнению с AlphaCode, который обогнал только 50 % конкурентов.
Составление мощных предварительно обученных моделей с механизмами поиска и рассуждения — это интересное направление в направлении более общих агентов; Еще одним ключевым ингредиентом является глубокое понимание ряда модальностей, которые мы обсудим в следующем разделе.
5.2. Мультимодальный
Модели Gemini изначально мультимодальны. Эти модели демонстрируют уникальную способность плавно сочетать свои возможности в различных модальностях (например, извлечение информации и пространственную компоновку из таблицы, диаграммы или рисунка) с сильными логическими способностями языковой модели (например, ее современным состоянием). производительность в математике и кодировании), как показано в примерах на рисунках 5 и 12. Модели также демонстрируют высокую производительность в распознавании мелких деталей во входных данных, агрегировании контекста в пространстве и времени и применении этих возможностей к временной последовательности видео. кадры и/или аудиовходы.
В разделах ниже представлена более подробная оценка модели в различных модальностях (изображение, видео и аудио), а также качественные примеры возможностей модели по созданию изображений и способности комбинировать информацию из разных модальностей.
5.2.1. Понимание изображений
Мы оцениваем модель по четырем различным возможностям: распознавание объектов высокого уровня с использованием субтитров или задач на ответы на вопросы, таких как VQAv2; детальная транскрипция с использованием таких задач, как TextVQA и DocVQA, требующих от модели распознавания деталей низкого уровня; понимание диаграмм, требующее пространственного понимания макета ввода с использованием задач ChartQA и InfographicVQA; и мультимодальное рассуждение с использованием таких задач, как Ai2D, MathVista и MMMU. Для нулевой оценки качества модели предлагается предоставить краткие ответы, соответствующие конкретному эталону. Все числа получены с использованием жадной выборки и без использования внешних инструментов оптического распознавания символов.
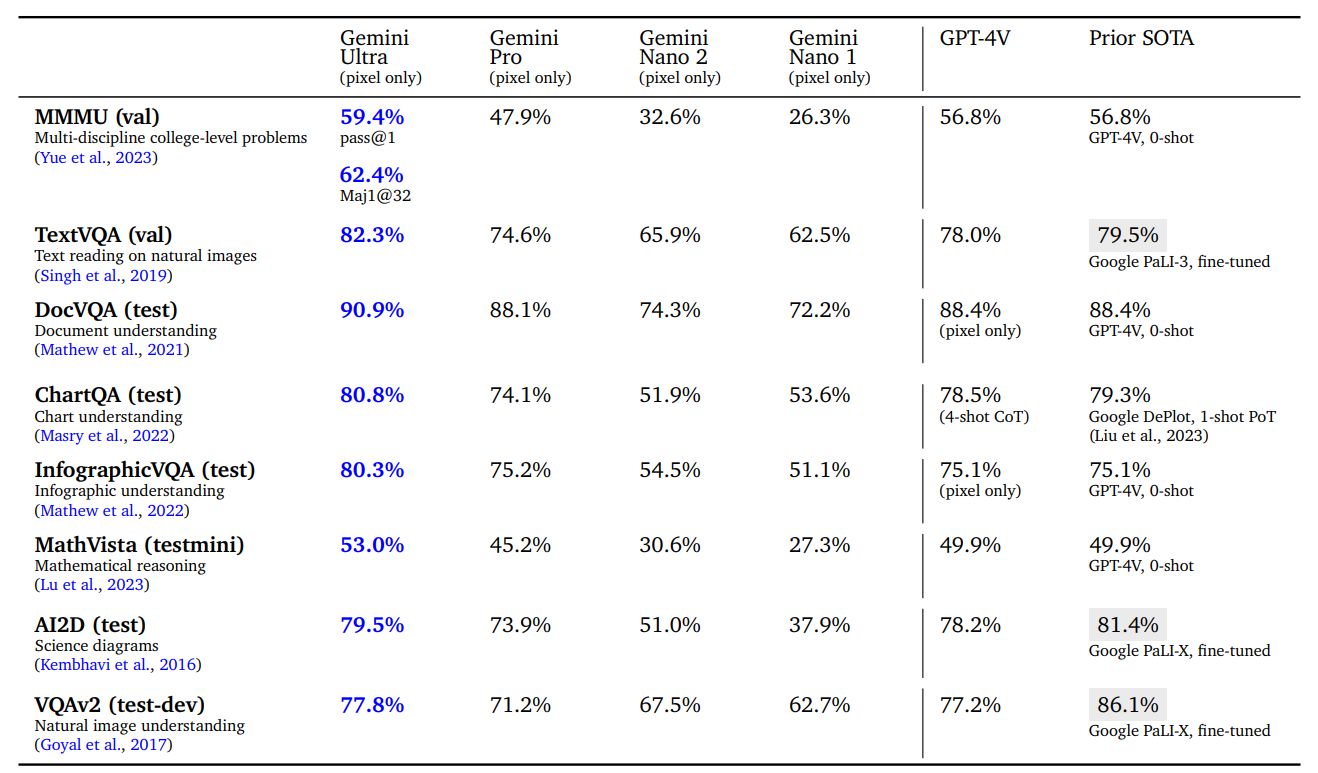
В Таблице 7 мы обнаружили, что Gemini Ultra является современным решением по широкому спектру тестов распознавания изображений. Он обеспечивает высокую производительность при выполнении широкого набора задач, таких как ответы на вопросы о естественных изображениях и отсканированных документах, а также понимание инфографики, диаграмм. и научные диаграммы. По сравнению с публично опубликованными результатами других моделей (в первую очередь GPT-4V), Gemini значительно лучше в оценке с нулевым выстрелом. Он также превосходит несколько существующих моделей, специально настроенных на обучающих наборах бенчмарка для большинства задач. Возможности моделей Gemini приводят к значительному улучшению современных академических показателей, таких как MathVista (+3,1%)[6] или InfographicVQA (+5,2%).
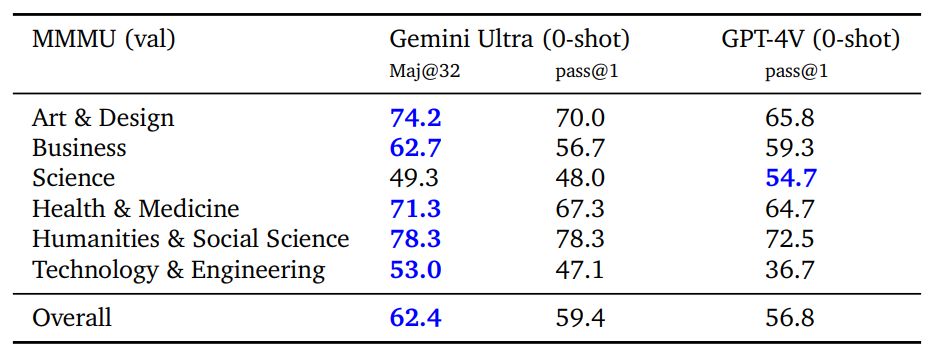
MMMU (Yue et al., 2023) — это недавно выпущенный тест для оценки, который состоит из вопросов об изображениях по 6 дисциплинам с несколькими предметами в каждой дисциплине, которые требуют знаний на уровне колледжа для решения этих вопросов. Gemini Ultra достигает наилучшего результата в этом тесте, опережая современный результат более чем на 5 процентных пунктов, и превосходит предыдущий лучший результат в 5 из 6 дисциплин (см. Таблицу 8), демонстрируя тем самым свои возможности мультимодального рассуждения.< /п>
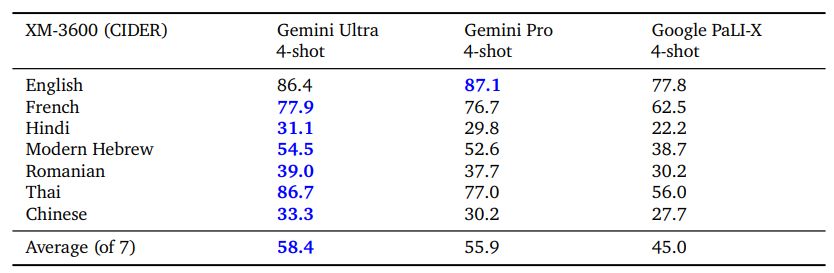
Модели Gemini также способны одновременно работать в разных модальностях и на разнообразном наборе глобальных языков как для задач понимания изображений (например, изображений, содержащих текст на исландском языке), так и для задач генерации (например, создания описаний изображений для широкого спектра языков). Мы оцениваем производительность создания описаний изображений на выбранном подмножестве языков в тесте Crossmodal3600 (XM-3600) в четырехэтапной настройке с использованием протокола оценки Flamingo (Alayrac et al., 2022) без какой-либо тонкой настройки все модели. Как показано в таблице 9, модели Gemini значительно превосходят существующую лучшую модель Google PaLI-X.
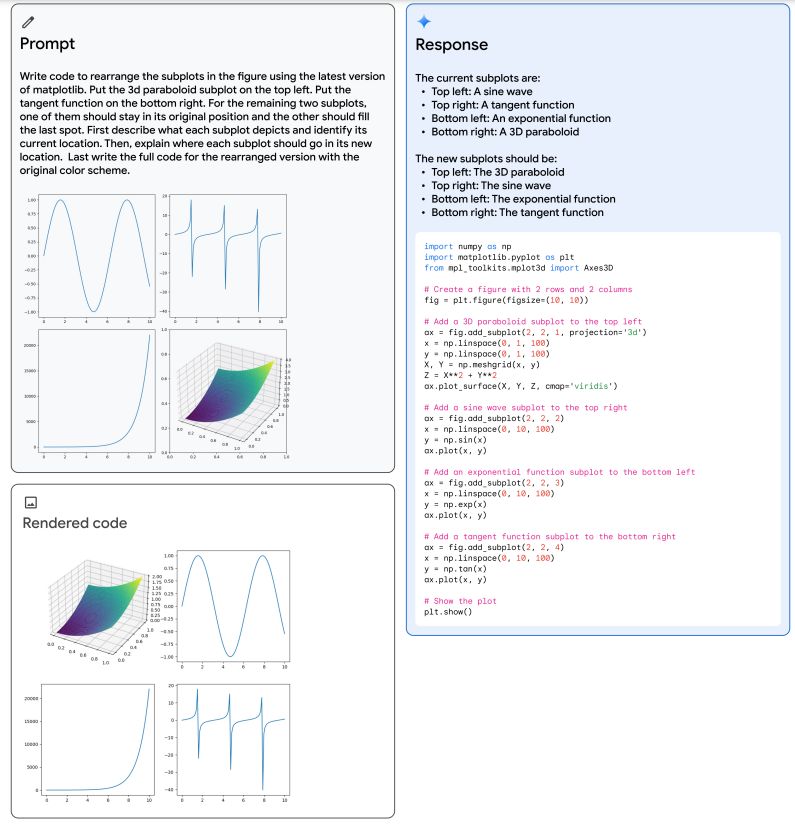
Качественная оценка на рисунке 5 иллюстрирует пример возможностей мультимодального рассуждения Gemini Ultra. Модель необходима для решения задачи генерации кода matplotlib, который будет переупорядочивать набор подграфиков, предоставленных пользователем. Выходные данные модели показывают, что она успешно решает эту задачу, сочетая множество возможностей понимания пользовательского графика, вывода кода, необходимого для его создания, следования инструкциям пользователя по размещению подграфиков в желаемых положениях и абстрактных рассуждений о выходном графике. Это подчеркивает природную мультимодальность Gemini Ultra и ускользает от его более сложных способностей к рассуждению через чередующиеся последовательности изображений и текста. Мы отсылаем читателя к приложению для более качественных примеров.
5.2.2. Понимание видео
Понимание видеовхода — важный шаг на пути к созданию полезного универсального агента. Мы измеряем способность понимания видео по нескольким установленным критериям, которые не учитываются при обучении. Эти задачи позволяют оценить, способна ли модель понимать и анализировать связанную во времени последовательность кадров. Для каждой видеозадачи мы отбираем 16 равноотстоящих друг от друга кадров из каждого видеоклипа и передаем их моделям Gemini. Что касается наборов видеоданных YouTube (все наборы данных, кроме NextQA и теста восприятия), мы оцениваем модели Gemini на видео, которые все еще были общедоступны в ноябре 2023 года.
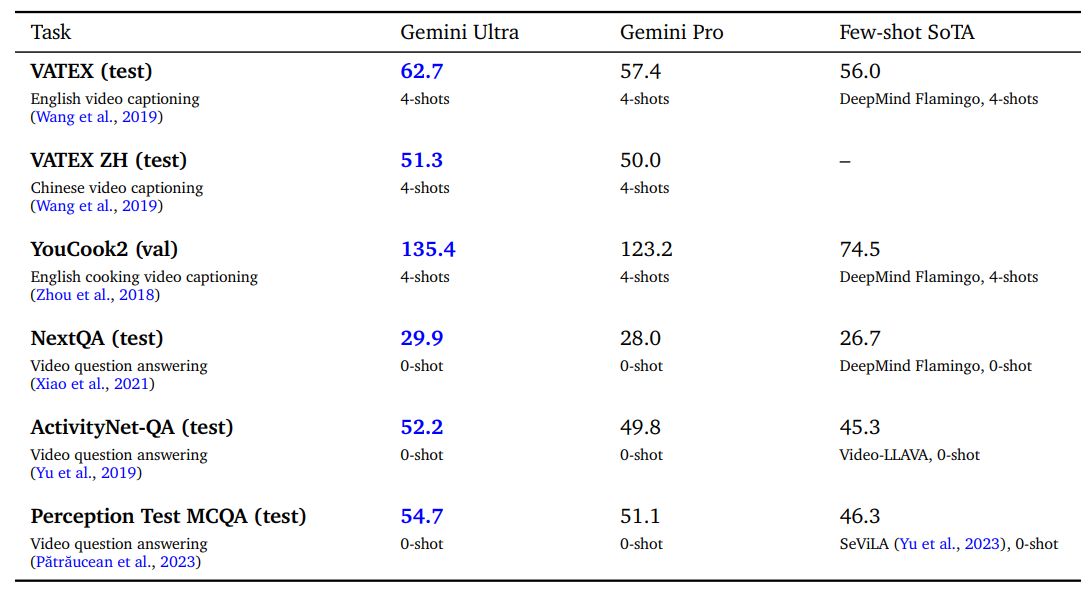
Gemini Ultra достигает самых современных результатов в различных задачах создания титров к видео, а также в задачах с ответами на вопросы с нулевым кадром, как показано в Таблице 10. Это демонстрирует его способность четкого временного рассуждения в нескольких кадрах. На рисунке 21 в приложении представлен качественный пример понимания видео механики удара футболиста по мячу и рассуждений о том, что игрок может улучшить его игру.
5.2.3. Генерация изображений
Gemini может выводить изображения в исходном виде, без необходимости полагаться на промежуточное описание на естественном языке, которое может ограничить способность модели выражать изображения. Это дает уникальную возможность модели генерировать изображения с подсказками, используя чередующиеся последовательности изображений и текста в режиме нескольких кадров. Например, пользователь может предложить модели разработать изображения и текст для публикации в блоге или веб-сайта (см. рис. 10 в приложении).
На рис. 6 показан пример генерации изображения в режиме «1 кадр». Модель Gemini Ultra предлагается с одним примером чередующегося изображения и текста, где пользователь предоставляет два цвета (синий и желтый) и изображения, предлагающие создать из пряжи милого синего кота или синей собаки с желтым ухом. Затем модели дают два новых цвета (розовый и зеленый) и просят предложить две идеи о том, что можно создать, используя эти цвета. Модель успешно генерирует чередующуюся последовательность изображений и текста с предложениями создать из пряжи симпатичный зеленый авокадо с розовыми косточками или зеленого кролика с розовыми ушками.

5.2.4. Понимание звука
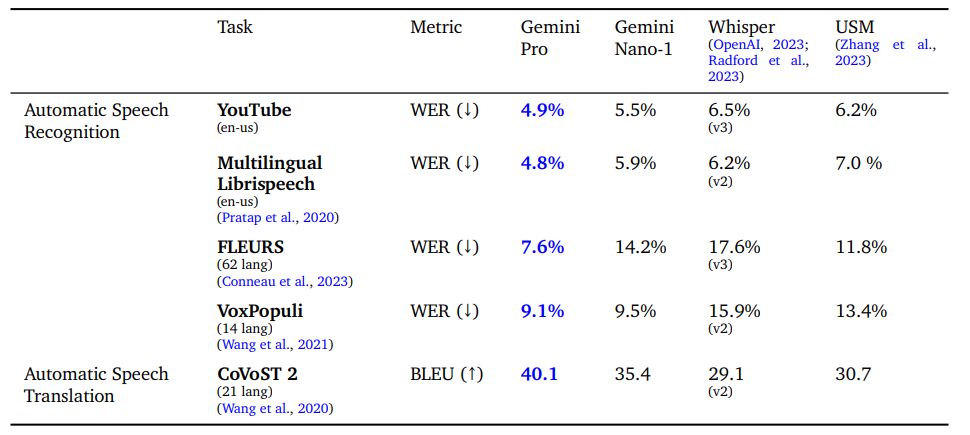
Мы оцениваем модели Gemini Nano-1 и Gemini Pro с помощью различных общедоступных тестов и сравниваем их с универсальной речевой моделью (USM) (Zhang et al., 2023) и Whisper (large-v2 (Radford et al., 2023) или big-v3 (OpenAI, 2023), как указано). Эти тесты включают задачи автоматического распознавания речи (ASR), такие как FLEURS (Conneau et al., 2023), VoxPopuli (Wang et al., 2021), Multi-lingual Librispeech (Pratap et al., 2020), а также задача перевода речи CoVoST 2, переводящая разные языки на английский (Wang et al., 2020). Мы также сообщаем о внутреннем наборе тестов YouTube. Задачи ASR сообщают о показателе частоты ошибок в словах (WER), где чем меньше число, тем лучше. Задания по переводу сообщают о балле BiLingual Evaluation Understudy (BLEU), где чем выше число, тем лучше. Сообщается о FLEURS на 62 языках, языки которых совпадают с данными обучения. Четыре сегментированных языка (мандаринский, японский, корейский и тайский)
В таблице 11 показано, что наша модель Gemini Pro значительно превосходит модели USM и Whisper по всем задачам ASR и AST, как для английских, так и для многоязычных наборов тестов. Обратите внимание, что FLEURS имеет большое преимущество по сравнению с USM и Whisper, поскольку наша модель также обучена с использованием набора обучающих данных FLEURS. Однако обучение той же модели без набора данных FLEURS приводит к WER 15,8, что по-прежнему превосходит Whisper. Модель Gemini Nano-1 также превосходит USM и Whisper на всех наборах данных, кроме FLEURS. Обратите внимание, что мы еще не оценивали качество звука Gemini Ultra, хотя ожидаем более высоких характеристик за счет увеличения размера модели.
В Таблице 12 показан дальнейший анализ ошибок с помощью USM и Gemini Pro. Мы обнаружили, что Gemini Pro дает более понятные ответы, особенно на редкие слова и имена собственные.

5.2.5. Комбинация модальностей
Мультимодальные демонстрации часто включают в себя комбинацию текста, чередующегося с одной модальностью, обычно изображениями. Мы демонстрируем способность обрабатывать последовательность аудио и изображений в исходном виде.
Рассмотрим сценарий приготовления омлета, в котором мы подсказываем модели последовательность звуков и изображений. В Таблице 13 показано пошаговое взаимодействие с моделью, предоставление изображений и устные вопросы о следующих шагах приготовления омлета. Мы отмечаем, что текст ответа модели достаточно точен и показывает, что модель обрабатывает мелкие детали изображения, чтобы оценить, когда омлет полностью готов. Смотрите демо на сайте.

[4] См. демоверсии на веб-сайте https://deepmind.google/gemini.
[5] http://codeforces.com/
[6] MathVista — это комплексный тест для математических рассуждений, состоящий из 28 ранее опубликованных мультимодальных наборов данных и трех недавно созданных наборов данных. Наши результаты MathVista были получены путем запуска сценария оценки авторов MathVista.