

Gemini — семейство высокопроизводительных мультимодальных моделей: Приложение
25 декабря 2023 г.:::информация Этот документ доступен на arxiv под лицензией CC 4.0.
Авторы:
(1) Команда Gemini, Google.
:::
Таблица ссылок
Обсуждение и заключение, ссылки
9. Приложение
9.1. Цепочка размышлений по сравнению с тестом MMLU
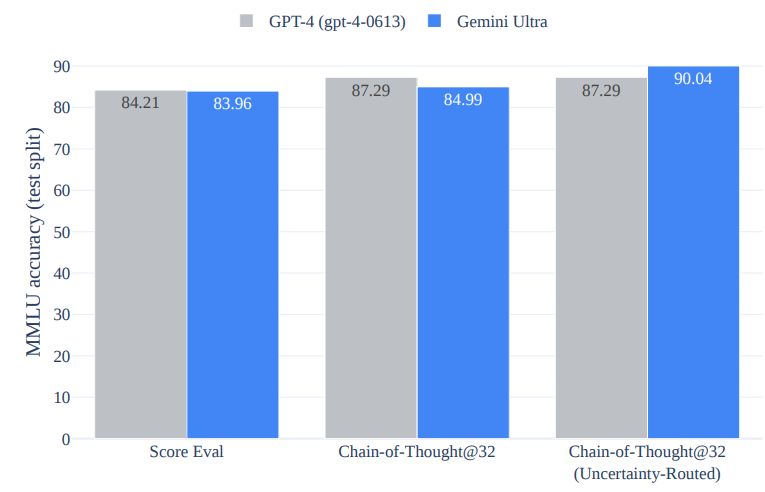
Мы сравниваем несколько подходов к MMLU и обсуждаем их результаты в этом разделе. Мы предложили новый подход, в котором модель создает k выборок цепочки мыслей, выбирает большинство голосов, если уверенность модели превышает пороговое значение, и в противном случае подчиняется жадному выбору выборки. Пороги оптимизируются для каждой модели на основе их производительности при разделении проверки. Предлагаемый подход называется цепочкой мыслей, ориентированной на неопределенность. Интуиция, лежащая в основе этого подхода, заключается в том, что выборки цепочки мыслей могут ухудшить производительность по сравнению с решением максимального правдоподобия, когда модель явно несовместима. На рисунке 7 мы сравниваем преимущества предлагаемого подхода как для Gemini Ultra, так и для GPT-4. Мы обнаруживаем, что Gemini Ultra получает больше преимуществ от этого подхода по сравнению с использованием только образцов цепочки мыслей. Производительность GPT-4 улучшается с 84,2% при жадной выборке до 87,3% при использовании цепочки мыслей с неопределенностью и 32 выборками, но он уже достигает этих результатов за счет использования 32 выборок цепочки мыслей. Напротив, Gemini Ultra значительно улучшает свою производительность с 84,0% при жадной выборке до 90,0% при использовании цепочки мыслей с неопределенностью и 32 выборками, а незначительно улучшается до 85,0% при использовании только 32 выборок по цепочке мыслей. .
9.2. Возможности и задачи сравнительного анализа
Мы используем более 50 тестов в качестве целостного инструмента для оценки моделей Gemini по тексту, изображениям, аудио и видео. Мы предоставляем подробный список задач сравнительного анализа для шести различных способностей понимания и создания текста: фактология, длинный контекст, математика/наука, рассуждение, обобщение и многоязычие. Мы также перечисляем тесты, используемые для задач распознавания изображений, видео и звука.
• Фактичность: мы используем 5 тестов: BoolQ (Кларк и др., 2019), NaturalQuestions-Closed (Квятковски и др., 2019), NaturalQuestions-Retrived (Квятковский и др., 2019), RealtimeQA (Kasai et al., 2022), TydiQA-noContext и TydiQA-goldP (Clark et al., 2020).
• Длинный контекст: Мы используем 6 тестов: NarrativeQA (Kočiský et al., 2018), Scrolls-Qasper, Scrolls-Quality (Shaham et al., 2022), XLsum (En), XLSum (не -английский язык) (Hasan et al., 2021) и еще один внутренний тест.
• Математика/естественные науки: мы используем 8 тестов: GSM8k (с CoT) (Cobbe et al., 2021), MATH pass@1 Хендрика (Hendrycks et al., 2021b), MMLU (Hendrycks et al., 2021b). ., 2021a), задачи Math-StackExchange, Math-AMC 2022-2023 и три других внутренних теста.
• Обоснование: мы используем 7 тестов: BigBench Hard (с CoT) (Srivastava et al., 2022; Suzgun et al., 2022), CLRS (Veličković et al., 2022), Proof Writer ( Tafjord et al., 2020), Проблемы рассуждения-Ферми (Kalyan et al., 2021), Lambada (Paperno et al., 2016), HellaSwag (Zellers et al., 2019), DROP (Dua et al., 2019) .
• Суммирование: мы используем 5 тестов: XL Sum (английский), XL Sum (неанглийские языки) (Hasan et al., 2021), WikiLingua (неанглийские языки), WikiLingua (английский). (Ладхак и др., 2020), XSum (Нараян и др., 2018).
• Многоязычность. Мы используем 10 тестов: XLSum (неанглийские языки) (Хасан и др., 2021 г.), WMT22 (Кочми и др., 2022 г.), WMT23 (Том и др., 2023 г.). , FRMT (Riley et al., 2023), WikiLingua (неанглийские языки) (Ladhak et al., 2020), TydiQA (без контекста), TydiQA (GoldP) (Clark et al., 2020), MGSM (Shi et al., 2020), MGSM (Shi et al., 2020). al., 2023), транслированные MMLU (Hendrycks et al., 2021a), NTREX (Federmann et al., 2022), FLORES-200 (Team et al., 2022).
• Изображение и видео. Мы используем 9 тестов для понимания изображений: MMMU (Юэ и др., 2023), TextVQA (Сингх и др., 2019), DocVQA (Мэтью и др., 2021), ChartQA (Масри и др., 2022 г.), InfographicVQA (Мэтью и др., 2022 г.), MathVista (Лу и др., 2023 г.), AI2D (Кембхави и др., 2016 г.), VQAv2 (Гоял и др., 2017 г.), XM3600 (Thapliyal et al., 2022) для понимания многоязычных изображений и 6 тестов для понимания видео: VaTEX (Wang et al., 2019) для субтитров на двух разных языках, YouCook2 (Zhou et al., 2018), NextQA (Сяо и др., 2021), ActivityNet-QA (Ю и др., 2019) и тест на восприятие MCQA (Pătrăucean и др., 2023).
• Аудио. Мы используем 5 тестов, включая задачи автоматического распознавания речи (ASR), такие как FLEURS (Conneau et al., 2023), VoxPopuli (Wang et al., 2021), Multi-lingual Librispeech (Pratap). и др., 2020) и задачи автоматического перевода речи, такие как CoVoST 2 (Wang et al., 2020).
9.3. Качественные примеры
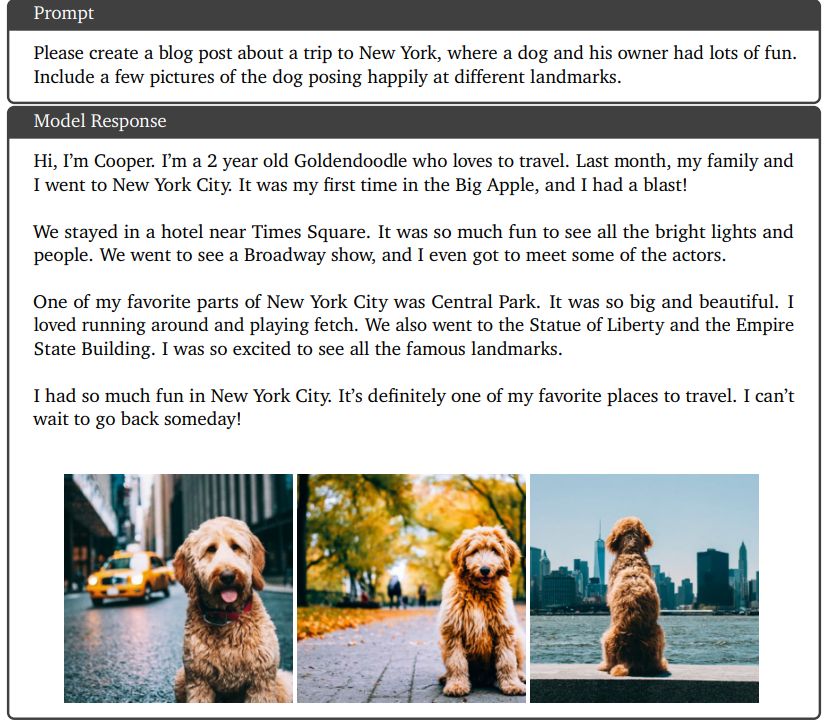
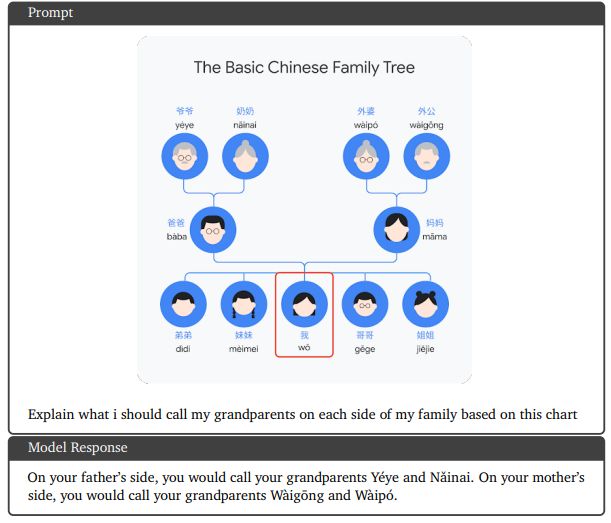
В этом разделе приведены примеры качественных показателей, основанные на использовании модели Gemini Ultra. Некоторые наглядные примеры мультимодального рассуждения для задач понимания изображений вместо диаграмм, естественных изображений и мемов показаны на рисунках 8, 9, 11, 13, 14 и 15. На рисунке 10 показан пример возможностей генерации изображений Gemini Ultra, где пользователь генерирует чередующаяся последовательность изображений и текста для оформления сообщения в блоге. Помимо английского, на рисунке 16 показана способность модели понимать изображения в многоязычной среде. Модели Gemini также демонстрируют высокие результаты в понимании и рассуждении мультимодальных изображений в математике, как показано на рисунках 12, 18 и 19. Рисунок 20 представляет собой пример сложного мультимодального рассуждения, демонстрирующий, как модель объединяет возможности понимания сложных изображений, генерации кода и выполнения инструкций. для конкретной пользовательской задачи. На рисунке 17 мы видим еще один пример модели, способной генерировать рабочий код и следовать сложным инструкциям пользователя. Наконец, на рисунке 21 показан пример способности Gemini Ultra понимать видео, анализируя набор кадров, связанных во времени.
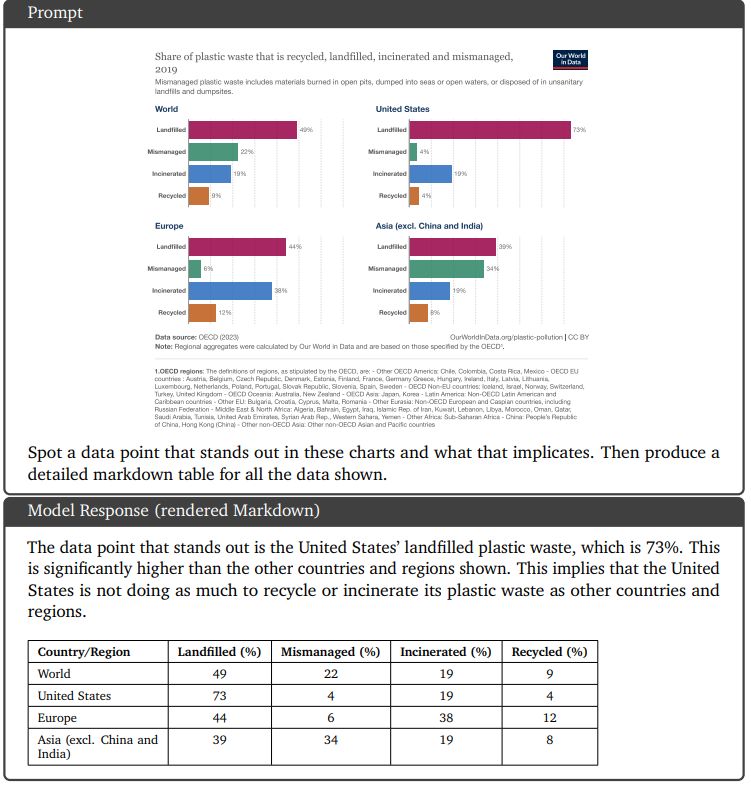
9.3.1. Понимание диаграмм и анализ данных
9.3.2. Мультимодальный ответ на вопрос

9.3.3. Генерация чередующихся изображений и текста
9.3.4. Понимание и рассуждение изображений

9.3.5. Геометрические рассуждения

9.3.6. Поиск информации об объектах

9.3.7. Мультимодальное мышление, основанное на визуальных подсказках

9.3.8. Мультимодальное понимание юмора

9.4. Здравый смысл в многоязычной среде
9.4.1. Рассуждения и генерация кода

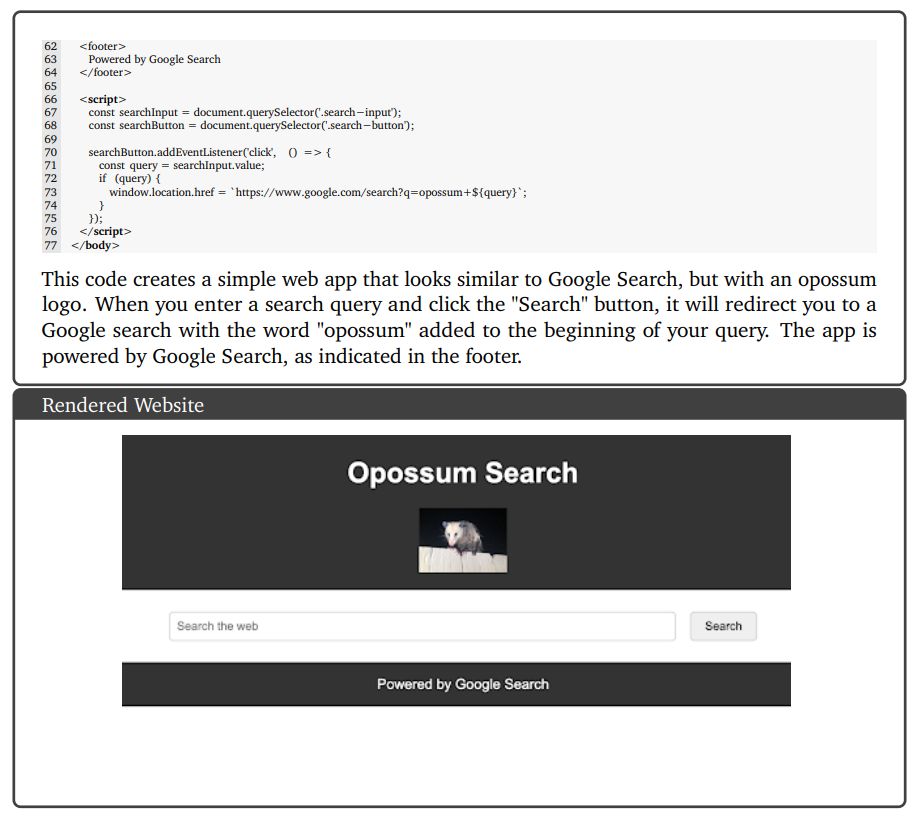
9.4.2. Математика: исчисление

9.5. Многоэтапное рассуждение и математика
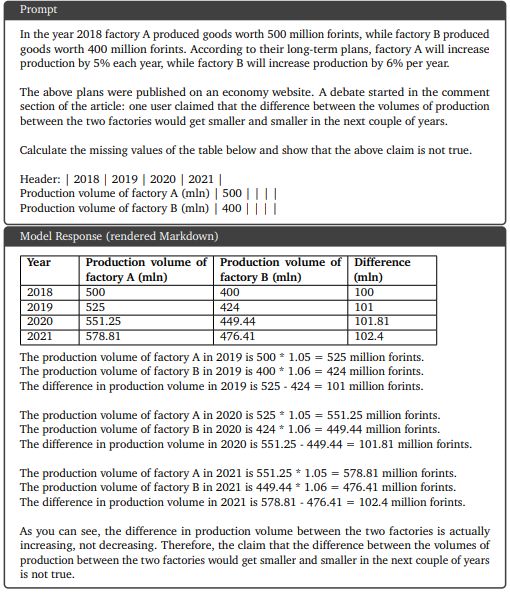
9.5.1. Сложное понимание изображений, генерация кода и выполнение инструкций
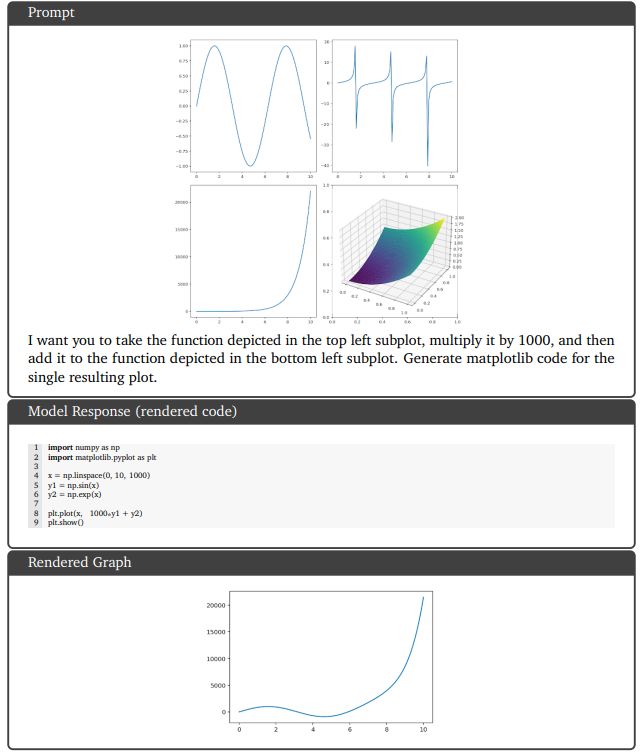
9.5.2. Видео понимание и рассуждение

Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27257)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)