

Gemini — семейство высокофункциональных мультимодальных моделей: краткое содержание и введение
25 декабря 2023 г.:::информация Этот документ доступен на arxiv под лицензией CC 4.0.
Авторы:
(1) Команда Gemini, Google.
:::
Таблица ссылок
Обсуждение и заключение, ссылки
:::совет В этом отчете представлено новое семейство мультимодальных моделей Gemini, которые демонстрируют замечательные возможности в области понимания изображений, аудио, видео и текста. Семейство Gemini состоит из размеров Ultra, Pro и Nano, подходящих для приложений, начиная от сложных логических задач и заканчивая сценариями использования с ограниченной памятью на устройстве. Оценка по широкому спектру тестов показывает, что наша самая мощная модель Gemini Ultra превосходит современное состояние в 30 из 32 из этих тестов, в частности, будучи первой моделью, достигшей результатов, сравнимых с человеческим экспертом, по хорошо изученному экзаменационному тесту MMLU. и улучшение состояния дел по каждому из 20 мультимодальных показателей, которые мы рассмотрели. Мы считаем, что новые возможности моделей Gemini в области кросс-модального рассуждения и понимания языка откроют широкий спектр вариантов использования, и обсуждаем наш подход к их ответственному развертыванию по отношению к пользователям.
:::
1. Введение
Мы представляем Gemini — семейство многофункциональных мультимодальных моделей, разработанных в Google. Мы совместно обучали Gemini работе с изображениями, аудио, видео и текстовыми данными, чтобы создать модель, обладающую как широкими универсальными возможностями во всех модальностях, так и передовыми возможностями понимания и рассуждения в каждой соответствующей области.
Gemini 1.0, наша первая версия, выпускается в трех размерах: Ultra для очень сложных задач, Pro для повышения производительности и возможности масштабного развертывания и Nano для приложений на устройстве. Каждый размер специально разработан с учетом различных вычислительных ограничений и требований приложений. Мы оцениваем производительность моделей Gemini с помощью комплексного набора внутренних и внешних тестов, охватывающих широкий спектр языковых, программных, логических и мультимодальных задач.
Gemini продвигает самые современные достижения в крупномасштабном языковом моделировании (Anil et al., 2023; Brown et al., 2020; Chowdhery et al., 2023; Hoffmann et al., 2022; OpenAI, 2023a; Radford et al., 2023; al., 2019; Rae et al., 2021), понимание изображений (Alayrac et al., 2022; Chen et al., 2022; Досовицкий и др., 2020; OpenAI, 2023b; Reed et al., 2022; Yu et. al., 2022a), обработка звука (Radford et al., 2023; Zhang et al., 2023) и понимание видео (Alayrac et al., 2022; Chen et al., 2023). Он также основан на работе над моделями последовательностей (Sutskever et al., 2014), долгой истории работы в области глубокого обучения на основе нейронных сетей (LeCun et al., 2015) и распределенных систем машинного обучения (Barham et al., 2022; Брэдбери и др., 2018; Дин и др., 2012), которые позволяют проводить широкомасштабное обучение.
Наша самая мощная модель Gemini Ultra достигает новых современных результатов в 30 из 32 тестов, о которых мы сообщаем, включая 10 из 12 популярных тестов текста и рассуждений, 9 из 9 тестов понимания изображений, 6 из 6 тестов понимания видео. и 5 из 5 тестов распознавания речи и перевода речи. Gemini Ultra — первая модель, добившаяся экспертных результатов по MMLU (Hendrycks et al., 2021a) — выдающемуся эталонному тестированию знаний и рассуждений с помощью набора экзаменов — с оценкой выше 90%. Помимо текста, Gemini Ultra добивается заметных успехов в решении сложных задач мультимодального рассуждения. Например, в недавнем тесте MMMU (Yue et al., 2023), который включает в себя вопросы об изображениях для выполнения междисциплинарных задач, требующих знаний предмета на уровне колледжа и продуманного рассуждения, Gemini Ultra достигает нового современного результата. составил 62,4%, превзойдя предыдущую лучшую модель более чем на 5 процентных пунктов. Это обеспечивает единый прирост производительности при тестировании ответов на вопросы по видео и понимании звука.
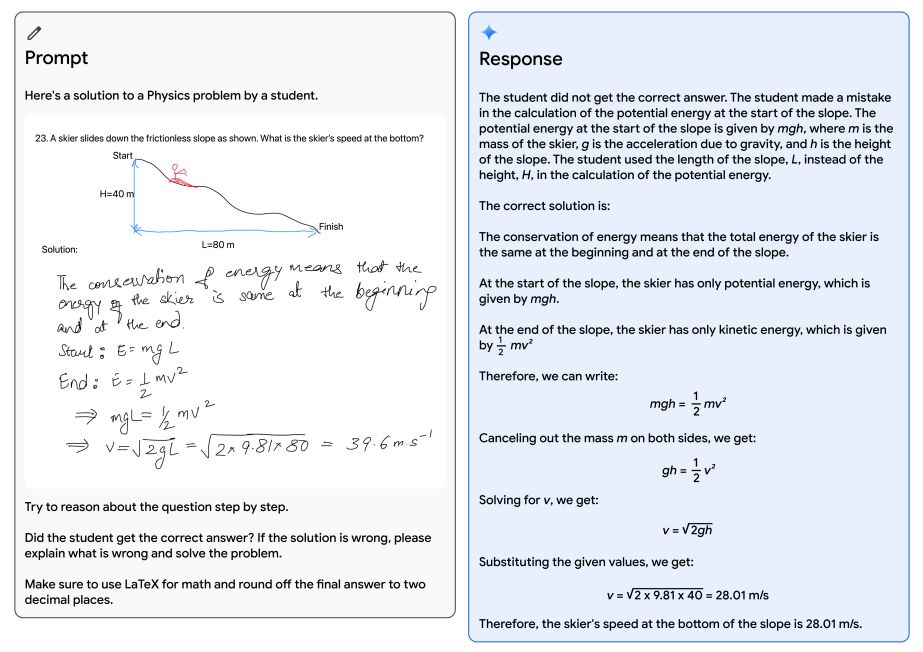
Качественная оценка демонстрирует впечатляющие возможности кроссмодального рассуждения, позволяя модели понимать и рассуждать на основе входной последовательности аудио, изображений и текста (см. рисунок 5 и таблицу 13). В качестве примера рассмотрим образовательную среду, изображенную на рисунке 1. Учитель нарисовал физическую задачу о лыжнике, спускающемся со склона, а ученик нашел ее решение. Используя возможности мультимодального рассуждения Gemini, модель способна понимать беспорядочный почерк, правильно понимать формулировку задачи, преобразовывать как задачу, так и решение в математический набор, определять конкретный этап рассуждения, на котором ученик ошибся при решении задачи, а затем дать проработанное правильное решение проблемы. Это открывает захватывающие образовательные возможности, и мы считаем, что новые мультимодальные и логические возможности моделей Gemini найдут широкое применение во многих областях.
Возможности рассуждения больших языковых моделей обещают создать универсальные агенты, способные решать более сложные многоэтапные задачи. Команда AlphaCode создала AlphaCode 2 (Leblond et al, 2023), новый агент на базе Gemini, который сочетает в себе возможности рассуждения Gemini с поиском и использованием инструментов, чтобы преуспеть в решении задач конкурентного программирования. AlphaCode 2 входит в число 15 % лучших участников на платформе конкурентного программирования Codeforces, что является значительным улучшением по сравнению с его современной предшественницей, входящей в число 50 % лучших (Li et al., 2022).
Параллельно мы расширяем границы эффективности с Gemini Nano, серией небольших моделей, предназначенных для развертывания на устройстве. Эти модели превосходно справляются с задачами на устройстве, такими как обобщение, понимание прочитанного, завершение текста, и демонстрируют впечатляющие возможности в рассуждениях, STEM, кодировании, мультимодальных и многоязычных задачах относительно их размеров.
В следующих разделах мы сначала даем обзор архитектуры модели, инфраструктуры обучения и набора обучающих данных. Затем мы представляем подробные оценки семейства моделей Gemini, охватывающие хорошо изученные тесты и оценки человеческих предпочтений по тексту, коду, изображениям, аудио и видео, которые включают как производительность на английском языке, так и многоязычные возможности. Мы также обсуждаем наш подход к ответственному развертыванию, [2] включая наш процесс оценки воздействия, разработку типовых политик, оценок и смягчения вреда перед принятием решения о развертывании. Наконец, мы обсудим более широкие последствия Gemini, его ограничения и потенциальные применения, открывающие путь к новой эре исследований и инноваций в области искусственного интеллекта.
[2] Мы планируем обновить этот отчет, добавив более подробную информацию до того, как модель Gemini Ultra станет общедоступной.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27664)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)