

Превращение Postgres в безумный план запросов в 200 раз быстрее
17 февраля 2022 г.В Spacelift мы используем PostgreSQL (в частности, Aurora Serverless) для большинства наших основных потребностей в базе данных. Шаблоны запросов наших приложений в основном представляют собой небольшие транзакции, которые затрагивают несколько строк — типичный сценарий, который PostgreSQL обрабатывает без особых усилий.
Мы также используем Datadog в качестве решения для мониторинга. Их агент имеет удобную функцию для создания метрик на основе периодически выполняемых SQL-запросов, что позволяет нам создавать интеллектуальные и высококонтекстные мониторы и оповещения. Иногда такие запросы могут быть медленными и преобладать во времени обработки базы данных. После подключения мониторинга базы данных Datadog мы выявили много медленных запросов и переместили большинство из них в отдельный кластер Redshift. Там они выполняются один раз в день на периодическом снимке базы данных.
Однако некоторые из этих запросов должны выполняться с более частым интервалом, поскольку они могут обнаруживать условия, вызывающие предупреждение. Мы не могли перенести эти запросы в Redshift из-за устаревших данных. Aurora Serverless также не поддерживает реплики чтения для переноса на них аналитических запросов, так что тут тоже не повезло. Таким образом, нам приходилось оптимизировать, добавлять индексы, оптимизировать и еще раз оптимизировать, пока мы не сократили использование базы данных этими запросами, создающими метрику, на 1-2 порядка.
В этой статье будет показана одна такая история оптимизации, которая интересна тем, что и планы запроса до, и после будут выглядеть несколько нелепо (с точки зрения затрат). Более того, он показывает, как оценка количества строк в PostgreSQL может быть очень неправильной. В этом случае знание предметной области поможет нам обмануть PostgreSQL в другом плане запросов, который будет намного быстрее, без добавления каких-либо дополнительных индексов.
Концепции
Spacelift — это платформа CI/CD, специализирующаяся на [инфраструктуре как коде] (https://spacelift.io/blog/infrastructure-as-code). Пользователи создают запуски (выполнения, например, Terraform), которые будут выполняться в рабочих пулах. Существует общедоступный общий рабочий пул, управляемый Spacelift, и частные рабочие пулы, которые пользователи могут размещать для себя.
Каждый запуск принадлежит стеку, который можно рассматривать как единую среду, управляющую набором ресурсов инфраструктуры. Если вы знакомы с Terraform или CloudFormation, один стек сопоставляется с одним файлом состояния Terraform или корневым стеком CloudFormation соответственно.
Прогон может иметь один из многих типов: отслеживаемый, предлагаемый и другие. Этот тип определяет, как будет выглядеть общий рабочий процесс.
Запрос
Предполагается, что запрос уведомляет нас, когда общедоступный пул рабочих процессов не может обработать спрос — пользовательские прогоны слишком долго ждут, чтобы их обработал рабочий.
```sql
SELECT COUNT(*) как "количество",
COALESCE(MAX(ИЗВЛЕКАТЬ(ЭПОХА ИЗ возраста(сейчас(), run.created_at)))::bigint, 0) AS "max_age"
ОТ пробегов
ПРИСОЕДИНЯЙТЕСЬ к стекам ON run.stack_id = stacks.id
ПРИСОЕДИНЯЙТЕСЬ к worker_pools ON worker_pools.id = stacks.worker_pool_id
ПРИСОЕДИНЯЙТЕСЬ к аккаунтам ON stacks.account_id = account.id
ГДЕ worker_pools.is_public = true
AND запускает.type IN (1, 4)
И запускает.состояние = 1
И run.worker_id IS NULL
И account.max_public_parallelism / 2 > (ВЫБЕРИТЕ СЧЕТЧИК (*)
ИЗ аккаунтов account_other
ПРИСОЕДИНЯЙТЕСЬ к стекам stacks_other ON account_other.id = stacks_other.account_id
JOIN запускает run_other ON stacks_other.id = run_other.stack_id
ГДЕ account_other.id = account.id
И (stacks_other.worker_pool_id IS NULL ИЛИ
stacks_other.worker_pool_id = worker_pools.id)
И run_other.worker_id НЕ NULL)
Это большой запрос! Что тут происходит?
Нас интересует количество прогонов (а также возраст самого старого), которые относятся к типу «Предложено» или «Тестирование» (можно запланировать сразу — другие типы прогонов требуют эксклюзивности), находятся в состоянии «Очередь» (что означает они еще не обрабатываются) и к ним не прикреплен рабочий (все еще ждут его).
Мы хотим, чтобы запуски на учетных записях, далеких от предела параллелизма, уменьшали количество ложных срабатываний, вызванных правильным ограничением пользователей. Таким образом, для каждого запуска мы подсчитываем количество активных запусков на его учетной записи и проверяем, не превышает ли он 50% предела параллелизма, и только после этого мы считаем этот запуск надлежащим образом ожидающим.
К сожалению, этот запрос длится 20 секунд и занимает 50% времени обработки нашей базы данных. Это очень плохо.
Давайте оптимизируем!
Давайте посмотрим на план запроса. Я буду использовать https://explain.dalibo.com для визуализации планов запросов. Чтобы получить план запроса, я выполняю его с префиксом EXPLAIN (FORMAT JSON, ANALYZE)… чтобы мы также могли видеть информацию о фактическом выполнении запроса (ANALYZE).
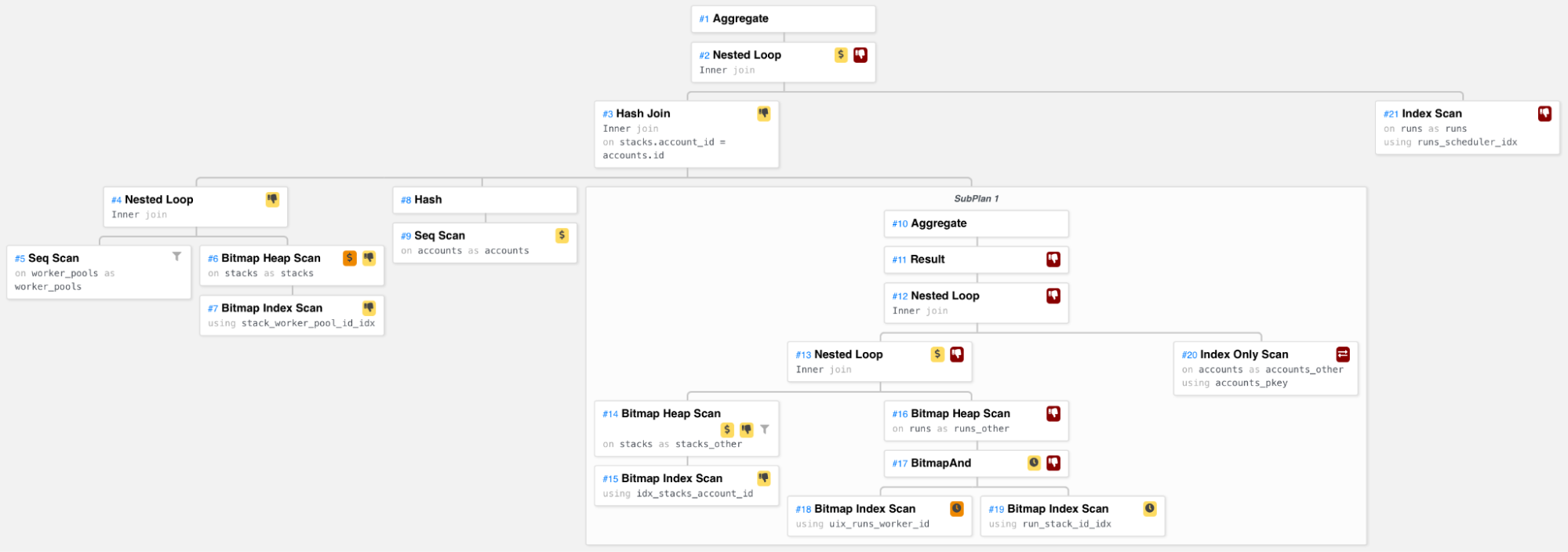
Что мы можем здесь увидеть?
С левой стороны мы присоединяемся к пулам рабочих со стеками. Мы также рассчитываем количество активных запусков для каждой учетной записи с помощью подплана. Мы выполняем трехстороннее хеш-объединение кортежей (рабочий пул, стек), учетных записей и результатов подплана на основе идентификатора учетной записи. Затем мы перебираем все эти триплеты и получаем ожидающие выполнения для каждого, наконец, подсчитывая все найденные ожидающие выполнения.
Подплан проходит по всем стекам в учетной записи и для каждого стека получает активные для него прогоны (те, где worker_id не равен NULL).
Давайте посмотрим на временное распределение узлов плана.
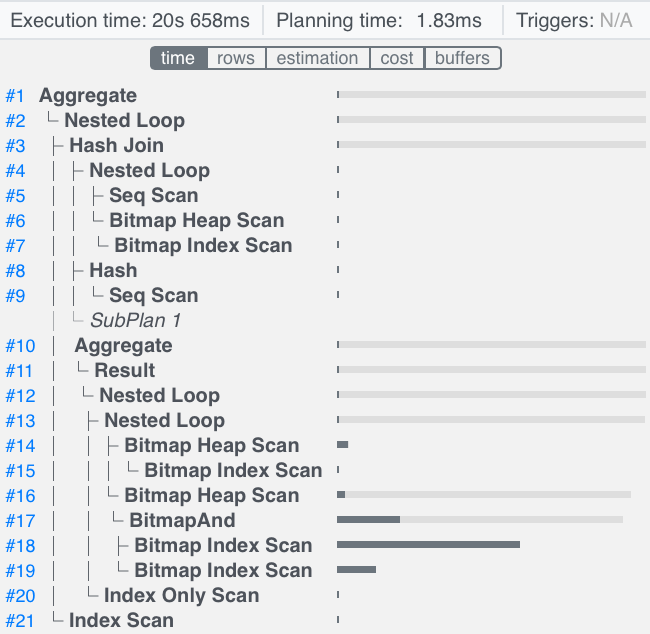
Мы видим, что наиболее затратной частью этого запроса является Сканирование растрового индекса , которое ищет прогоны, чей worker_id не равен NULL, поэтому давайте подробнее рассмотрим эту часть плана запроса.
Для каждого стека в подплане мы ищем в нем активные прогоны. Как мы это делаем?
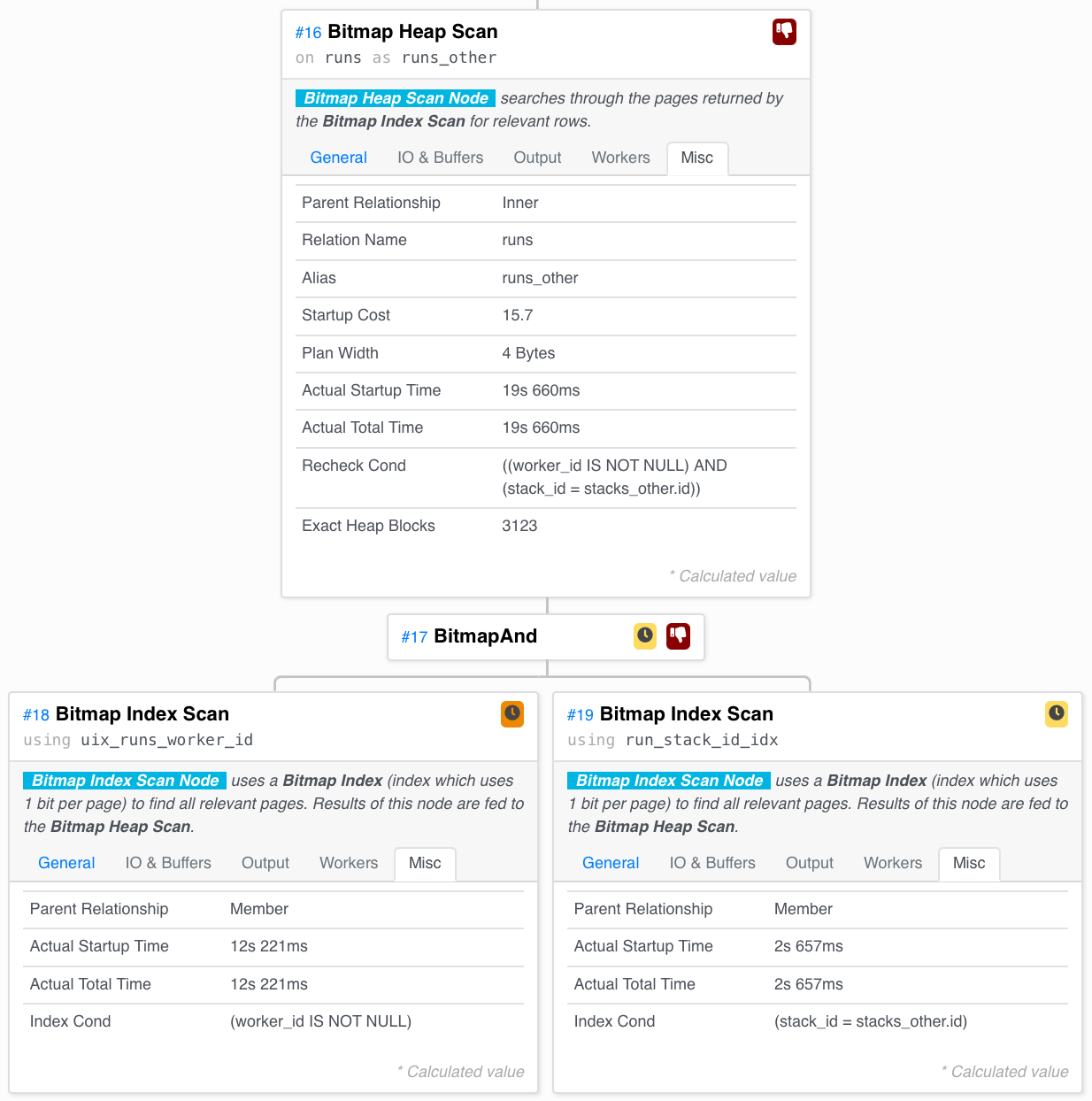
Мы сканируем индекс run_worker_id для страниц хранилища, содержащих Runs с непустым worker_id, и индекс run_stack_id для страниц, содержащих Runs для текущего стека. Затем мы И вместе — нам нужны только страницы, присутствующие в обоих этих сканах. Наконец, мы сканируем актуальные прогоны со страниц и берем только те, которые удовлетворяют предикатам (страницы, найденные индексом, могут содержать как релевантные, так и нерелевантные прогоны).
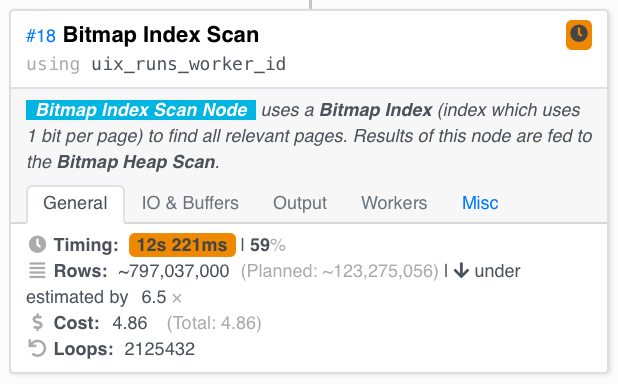
На другой вкладке левого сканирования индекса мы видим корень проблемы. Мы выполнили 531358 циклов, и мы рассчитывали просканировать 120 мл за всю обработку запроса, но мы просканировали 800 мл. Это намного больше.
Но позже при сканировании кучи страниц, объединенных И, мы видим сильное завышение.
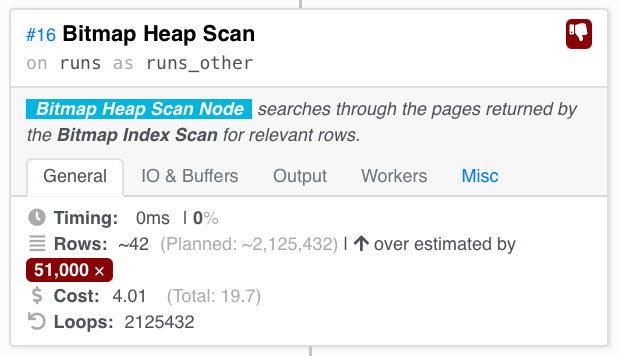
Мы рассчитывали просканировать 2 миллиона строк, но в целом просканировали 42 – это означает, что в данный момент в большинстве стеков не выполнялось ни одного запуска.
В целом, в основном этот подзапрос очень дорогой:
```sql
ВЫБЕРИТЕ КОЛИЧЕСТВО(*)
ИЗ аккаунтов account_other
ПРИСОЕДИНЯЙТЕСЬ к стекам stacks_other ON account_other.id = stacks_other.account_id
JOIN запускает run_other ON stacks_other.id = run_other.stack_id
ГДЕ account_other.id = account.id
И (stacks_other.worker_pool_id IS NULL ИЛИ
stacks_other.worker_pool_id = worker_pools.id)
И run_other.worker_id НЕ NULL
Теперь приходит знание предметной области. Есть ли что-то, что, как мы знаем, оптимизатор, кажется, не…? Да!
Только незначительная часть прогонов в базе данных активна в любой момент времени. Большинство стеков остаются бездействующими большую часть времени. Всякий раз, когда пользователь делает фиксацию, только затронутые стеки будут выполнять запуски. Очевидно, будут стеки, которые постоянно используются, но большинство из них не будет. Более того, интенсивные пользователи обычно используют частные пулы рабочих. Публичный общий рабочий пул в основном используется небольшими пользователями, так что это еще одна причина, по которой здесь не так много прогонов.
Прямо сейчас мы перебираем все существующие стеки, подключенные к общедоступному пулу воркеров, и получаем соответствующие прогоны для каждого. Как насчет того, чтобы мы перевернули это? Мы знаем, что активных прогонов не больше, чем публичных рабочих — на порядок меньше, чем стеков. Общее количество активных прогонов (не только тех, что находятся в общедоступном пуле рабочих) также намного меньше, максимум столько же, сколько рабочих в целом (и, поскольку количество частных рабочих является основным параметром, на котором мы в настоящее время основываем наши цены уровня Enterprise, время обработки запроса, линейно коррелирующее с количеством рабочих, в порядке). Таким образом, мы могли бы получить все активные прогоны и отфильтровать только те, чей стек использует общедоступный пул рабочих процессов.
Единственная проблема в том, что мы работаем с довольно непрозрачным оптимизатором запросов, и PostgreSQL не может дать ему никаких подсказок — например, принудительно применить стратегию объединения. Поэтому нам придется сделать это по-другому. Мы создадим запрос, который сканирует активные прогоны, а затем использует другой подзапрос, чтобы отфильтровать их только те, которые относятся к соответствующему стеку. Тогда нам придется надеяться, что запрос достаточно непрозрачен, чтобы Postgres не перемудрил с ним.
```sql
ВЫБЕРИТЕ КОЛИЧЕСТВО(*)
FROM работает runs_other
ГДЕ (ВЫБЕРИТЕ СЧЕТ(*)
ИЗ стеков
ГДЕ stacks.id = run_other.stack_id
И stacks.account_id = account.id
И stacks.worker_pool_id = worker_pools.id)> 0
И run_other.worker_id НЕ NULL
Этот запрос делает именно то, что мы описали. Сканируйте активные прогоны, фильтруйте только те, у которых больше 0 стеков в текущей учетной записи и которые подключены к общедоступному пулу рабочих. Для каждого запуска будет либо 1, либо 0 таких стеков.
Выполняя этот запрос, мы сокращаем время до 100 мс вместо исходных 20 с. Это огромное улучшение. Что говорит план запроса? (извиняюсь за длинное вертикальное фото)
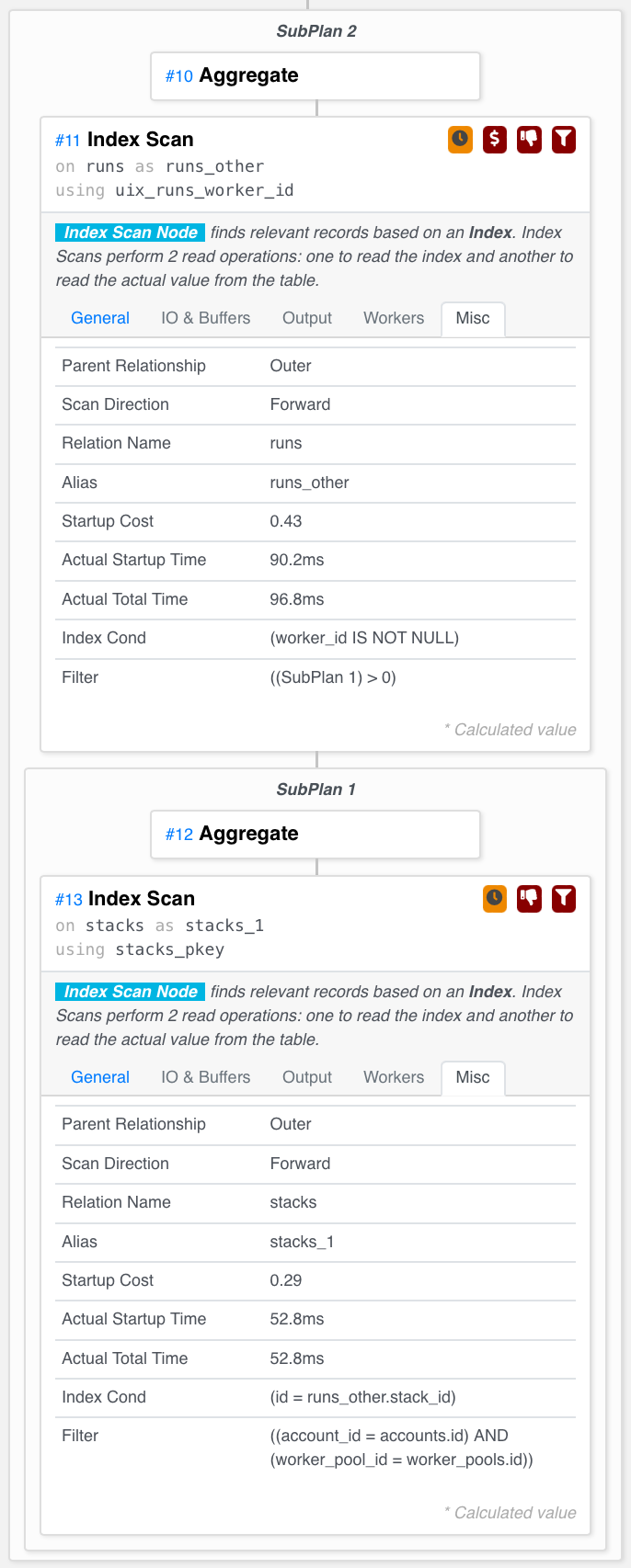
Именно то, что мы хотели! Он сканирует активные прогоны и для каждого из них проверяет (используя поиск по индексу первичного ключа — быстро!), соответствует ли стек, к которому он принадлежит.
Вот и все! Весь оптимизированный запрос теперь выглядит так:
```sql
SELECT COUNT(*) как "количество",
COALESCE(MAX(ИЗВЛЕКАТЬ(ЭПОХА ИЗ возраста(сейчас(), run.created_at)))::bigint, 0) AS "max_age"
ОТ пробегов
ПРИСОЕДИНЯЙТЕСЬ к стекам ON run.stack_id = stacks.id
ПРИСОЕДИНЯЙТЕСЬ к worker_pools ON worker_pools.id = stacks.worker_pool_id
ПРИСОЕДИНЯЙТЕСЬ к аккаунтам ON stacks.account_id = account.id
ГДЕ worker_pools.is_public = true
AND запускает.type IN (1, 4)
И запускает.состояние = 1
И run.worker_id IS NULL
И account.max_public_parallelism / 2 > (ВЫБЕРИТЕ СЧЕТЧИК (*)
FROM работает runs_other
ГДЕ (ВЫБЕРИТЕ СЧЕТ(*)
ИЗ стеков
ГДЕ stacks.id = run_other.stack_id
И stacks.account_id = account.id
И stacks.worker_pool_id = worker_pools.id)> 0
И run_other.worker_id НЕ NULL)
Резюме
Спасибо за прочтение! Мораль этой истории в том, что планы запросов не так сложно интерпретировать с помощью правильных инструментов. Используя свои знания предметной области, вы можете переписать свои запросы для существенного повышения производительности без добавления ненужных индексов или денормализации модели данных.
- Впервые опубликовано [здесь] (https://spacelift.io/blog/tricking-postgres-into-using-query-plan)*
Оригинал
🔥 Популярное на этой неделе
-
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27758)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)