

Изучение мира распределенных систем: руководство для начинающих по теореме CAP
13 апреля 2023 г.Когда вы начинаете исследовать мир распределенных систем, вы начинаете видеть название «теорема CAP», которое звучит то тут, то там. Знакомы ли вы с общей концепцией, нужно освежить свои знания за ночь. перед собеседованием по проектированию системы или совершенно новым для вас, эта статья призвана помочь вам. Прежде чем углубляться в саму теорему, давайте сначала рассмотрим некоторые основные понятия, чтобы обеспечить некоторый контекст.
* Распределенная система — это система, компоненты которой расположены на разных сетевых компьютерах, которые общаются и координируют свои действия, передавая сообщения друг другу — Википедия
В общем случае под распределенной системой понимается набор узлов, которые взаимодействуют друг с другом по сети с использованием различных протоколов и подходов, таких как вызовы RPC или системы обмена сообщениями, для достижения общей цели.
Рассмотрим, например, приложение для доставки еды, которое позволяет вам заказывать еду из разных ресторанов. Зачем нужна такая система? Почему нельзя просто положиться на один сервер? Есть несколько факторов, которые следует учитывать, но два ключевых понятия – масштабируемость и надежность.
* Масштабируемость — это термин, описывающий способность системы справляться с возросшей нагрузкой. (источник)
Это означает, что, с одной стороны, это способность справляться с возросшей нагрузкой за счет добавления дополнительных ресурсов в систему, а с другой стороны, это позволяет сократить используемые ресурсы, чтобы сократить расходы, когда они не требуются.
Здесь я должен упомянуть, что существует два типа масштабирования - вертикальное и горизонтальное.
Вертикальное масштабирование относится к системным манипуляциям с ресурсами на одном компьютере. Принимая во внимание, что горизонтальное масштабирование относится к добавлению большего количества узлов, которые имеют ту же функциональность, что и узел, предназначенный для нагрузки.
В распределенных системах мы больше склоняемся к горизонтальному масштабированию. Чтобы проиллюстрировать пример использования этого принципа, мы можем обратиться к вышеупомянутому сервису доставки еды. Вы начинаете с того, что замечаете тот факт, что нагрузка не распределяется пропорционально в течение дня (вероятно, у вас меньше всего заказов в 4 утра, а часом пик, вероятно, будет обед или ужин).
Допустим, вам нужно только X количества ресурсов ночью и 20X в час пик. Вы точно не захотите ночью платить за 20-кратные ресурсы, и наоборот, вы не сможете обрабатывать запросы в час пик, имея только Х-ресурсы, которых достаточно ночью. Чтобы решить эту проблему, вы должны масштабировать свои ресурсы в соответствии с нагрузкой, что при горизонтальном масштабировании означает добавление или удаление узлов службы.
* Надежность определяется как вероятность того, что компонент системы будет выполнять требуемую функцию в течение заданного периода времени при использовании в рабочих условиях (Источник).
Проще говоря, это способность продолжать работать, даже сталкиваясь с различного рода сбоями. В качестве примера представьте, что вы размещаетесь в одном центре обработки данных, который по какой-то физической причине имеет проблемы с подключением. В этом случае вы не сможете работать в целом. Чтобы избежать такой проблемы, вы, вероятно, хотели бы размещаться в нескольких центрах обработки данных. Могут быть разные типы ошибок и способы их устранения, но общая цель — обеспечить работу вашей системы так, как ожидается для конечного пользователя, даже во время сбоев.
Понимание этих концепций, вариантов использования и примеров, связанных с ними, позволяет нам понять, что подавляющее большинство современных сервисов должно существовать как распределенная система. Мы рассмотрели преимущества распределенных систем, но как насчет ограничений? Идея CAP определяет эти ограничения.
Теорема CAP
Теорема CAP была изобретена ученым-компьютерщиком Эриком Брюэром в 1998 году и представлена им на «Симпозиуме по принципам распределенных вычислений» позднее в 2000 году – Википедия.
Чтобы понять теорему и формулировку в целом, нам сначала нужно взглянуть на три компонента аббревиатуры CAP.
Последовательность
В реплицированной системе согласованность означает, что при выполнении операции чтения на любом узле всегда будут возвращаться одни и те же данные. Например, если у вас есть три узла в вашей базе данных — x, y и z — и операция записи выполняется на узле x, не должно быть временного промежутка между тем, когда эта запись влияет на результат чтения с узла x, и когда она влияет на результат чтения. результаты чтения с узлов y и z.
Доступность
Доступность, с другой стороны, гарантирует, что система работает должным образом и что на любой запрос будет получен ответ без ошибок. Это не обязательно означает отсутствие каких-либо логических ошибок или внутренних сбоев, а скорее отсутствие ответов об ошибках, вызванных сбоями связи между узлами в базе данных.
Допуск разделения
Наконец, устойчивость к разделению относится к способности системы продолжать обработку запросов, даже если узел выходит из строя или его соединение с сетью теряется. Разделение сети — это то, что должно произойти в реальном мире, особенно по мере того, как системы становятся более сложными и распределенными. На самом деле, чем сложнее становится ваша система, тем чаще случаются сбои в сети.
Утверждение теоремы
Любое распределенное хранилище может предоставлять не более двух свойств из списка согласованности, доступности и устойчивости к разделам. В результате любое распределенное хранилище может быть согласованным и доступным (CA), согласованным и устойчивым к разделам (CP) или доступным и устойчивым к разделам (AP).
Доказательство теоремы CAP
Давайте подойдем к нашему доказательству с противоречием: предположим, что распределенное хранилище может быть непротиворечивым, доступным и терпимым к разделам. одновременно. У нас есть хранилище с набором реплик из трех узлов. Сетевое соединение между узлом 3 и другими узлами разорвано
(partitioned), а узел 1 получает запрос на запись. Пока мы предполагаем, что наша система устойчива к разделам, это не должно быть проблемой, и узел 3 должен по-прежнему иметь возможность работать и выполнять операции чтения.
Однако мы предполагаем, что наша система и непротиворечива, и доступна, но наш ответ не может быть непротиворечивым, потому что мы не получили последний запрос на запись, обработанный узлом 1, и если мы ответим пользователю некоторыми данными, он выиграет. не быть последними данными в системе, что означает, что наша система не согласована.
С другой стороны, если мы хотим подождать, пока сетевой раздел не будет решен, и мы сможем получить последние данные от узла 1 и стать непротиворечивыми, мы не достигнем доступности, которую, как мы предполагаем, достигла наша система. Это означает, что наша система не может быть устойчивой к разделам, согласованной и доступной одновременно.
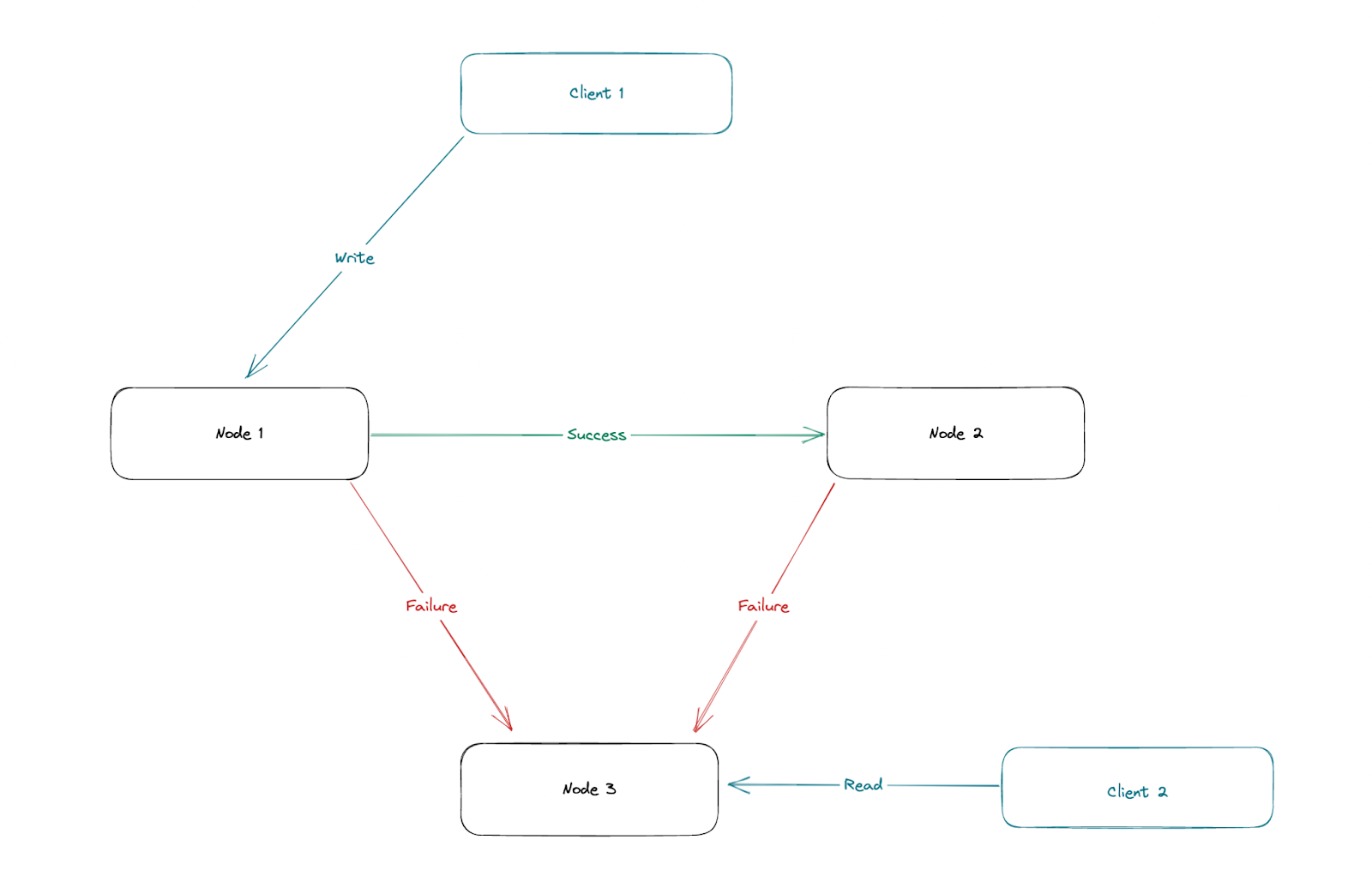
Теперь нам нужно доказать, что система действительно может быть CA, CP или AP. Для всех трех ситуаций мы будем рассматривать одну и ту же схему.
ЦП
Для системы CP, предполагая, что она непротиворечива и устойчива к разделам, мы все еще можем продолжать работу, несмотря на сбой сети на узле 3. Однако для поддержания согласованности узел 3 не будет доступен для чтения до его подключения. восстановлен, и он получил последние данные.
AP
Напротив, для системы AP, которая одновременно доступна и устойчива к разделам, мы можем продолжать работать даже во время сетевого раздела. Хотя узел 3 может не иметь последних данных, он все же может ответить теми данными, которые у него есть, хотя и непоследовательно. Это гарантирует, что вызовы чтения по-прежнему доступны.
Калифорния
Для системы CA нам не нужно беспокоиться о сетевых разделах, потому что мы не гарантируем работу кластера в такой ситуации. Поэтому нам нужно только убедиться, что узел 3 может без задержки ответить последними данными. Для этого узел 1, который принимает запись, гарантирует, что последняя запись будет предоставлена другим узлам кластера, прежде чем ответить модулю записи. Это можно сделать легко, поскольку у нас нет сетевых разделов, с которыми можно было бы бороться.
Заключение
Как вы уже заметили, теорема CAP — это фундаментальная концепция, показывающая компромиссы, на которые приходится идти при работе с распределенными системами. Однако, как мы видели, на самом деле вам приходится выбирать между согласованностью и доступностью, потому что сетевой раздел — это то, к чему вы должны быть готовы. Но для принятия правильного решения необходимо глубокое понимание проблемы, которую вы хотите решить, четкие требования и видение обозримого будущего, иначе последствия могут испортить всю вашу работу.
Например, если вы строите систему, связанную с финансами, крайне важно, чтобы данные были как можно более непротиворечивыми, иначе расхождения и решения, основанные на них, могут привести к огромным финансовым потерям. С другой стороны, если вы разрабатываете систему, которая будет служить страницей профиля пользователя в некоторых социальных сетях, не так важно всегда иметь последнее обновление, которое является согласованным, а доступность является предпочтительным способом проектирования системы. .
Как вы могли заметить, теорема CAP была введена еще в 2000 году, что было относительно давно и с тех пор было много критики. Действительно, подход к решению задач в распределенных системах продвинулся вперед и появилось больше понятий, позволяющих глубже взглянуть на эти понятия. Чтобы узнать больше об этом, я настоятельно рекомендую изучить теорему PACELC.
В целом, теорема CAP дает уместное представление и способ осмысления системного проектирования распределенных систем, что заставляет вас думать о компромиссах и является отличным способом начать исследовать мир распределенных систем.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27466)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)