Этот вариант использования хранилища данных имеет масштаб. Пользователь — China Unicom, один из крупнейших в мире поставщиков телекоммуникационных услуг. Используя Apache Doris, они развертывают несколько петабайтных кластеров на десятках компьютеров для поддержки 15 миллиардов ежедневных дополнений журналов из более чем 30 направлений бизнеса. Такая гигантская система анализа журналов является частью их управления кибербезопасностью. Для мониторинга в реальном времени, отслеживания угроз и оповещения им требуется система анализа журналов, которая может автоматически собирать, хранить, анализировать и визуализировать журналы и записи событий.
С архитектурной точки зрения система должна иметь возможность проводить анализ журналов различных форматов в режиме реального времени и, конечно же, быть масштабируемой для поддержки огромного и постоянно растущего размера данных. Остальная часть статьи посвящена тому, как выглядит их архитектура обработки журналов и как с ее помощью они реализуют стабильный прием данных, недорогое хранение и быстрые запросы.
Архитектура системы
Это обзор их конвейера данных. Журналы собираются в хранилище данных и проходят несколько уровни обработки.
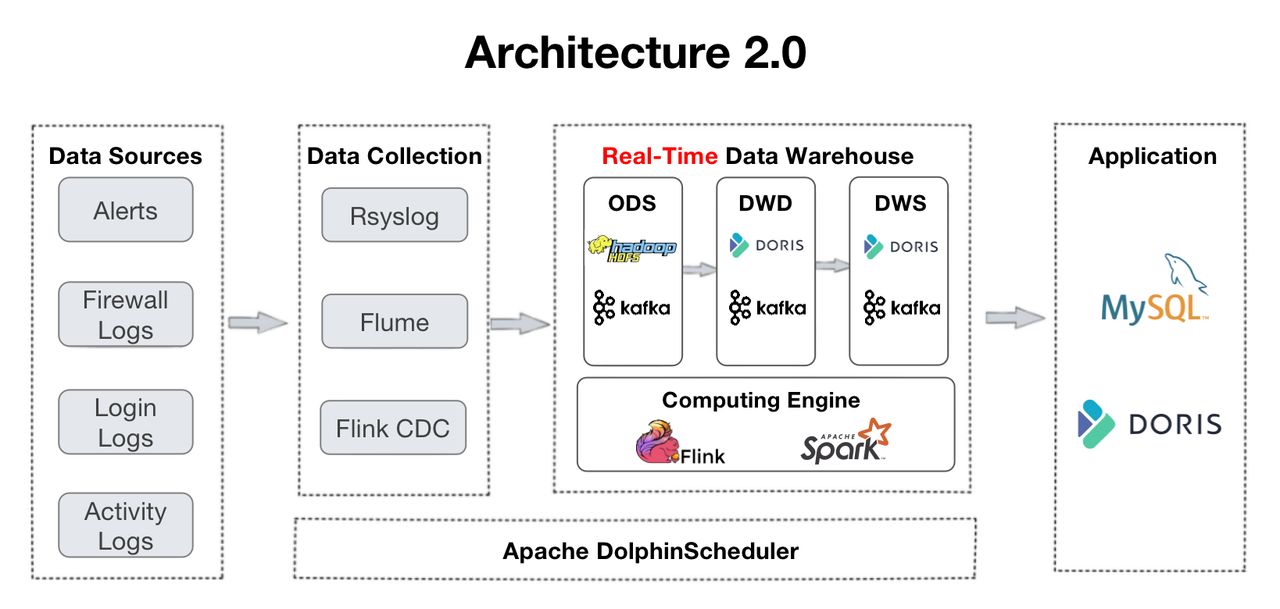
* ODS: исходные журналы и оповещения из всех источников собираются в Apache Kafka. При этом их копии будут храниться в HDFS для проверки или воспроизведения данных.
* DWD: здесь находятся таблицы фактов. Apache Flink очищает, стандартизирует, заполняет, деидентифицирует данные и записывает их обратно в Kafka. Эти таблицы фактов также будут помещены в Apache Doris, чтобы Doris могла отслеживать определенный элемент или использовать их для создания информационных панелей и отчетов. Поскольку журналы не прочь дублировать, таблицы фактов будут организованы в Ducate Key. модель Apache Doris.
* DWS: этот уровень объединяет данные из DWD и закладывает основу для запросов и анализа.
* ADS: на этом уровне Apache Doris автоматически агрегирует данные с помощью модели агрегатного ключа и автоматически обновляет данные с помощью модели уникального ключа.
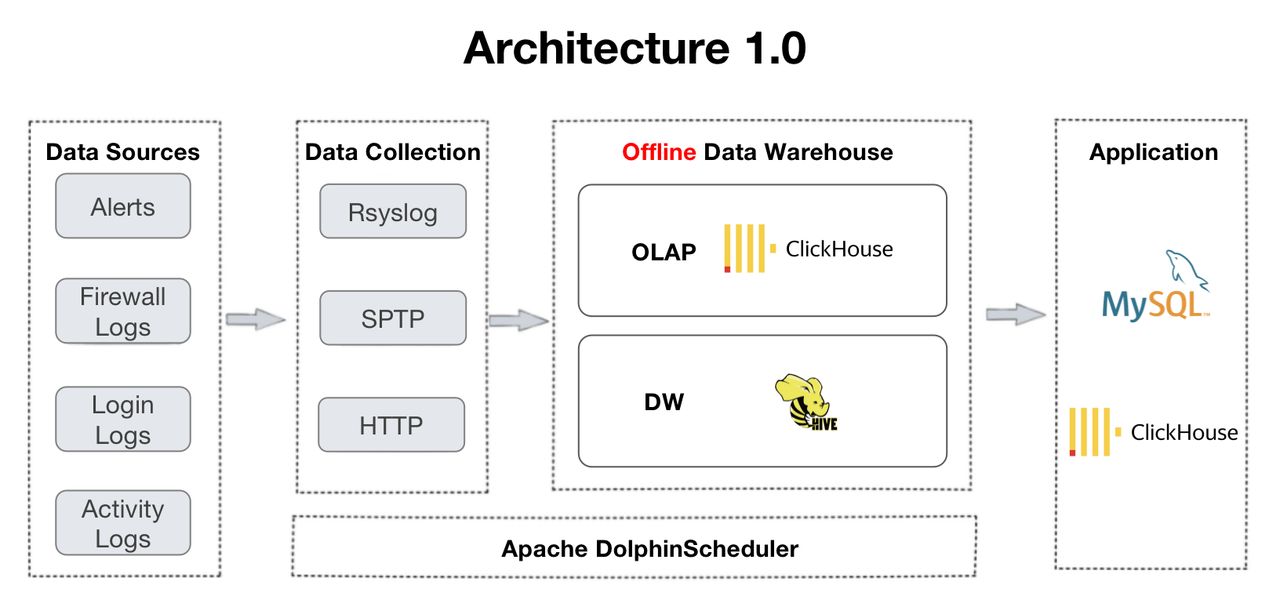
Архитектура 2.0 является развитием архитектуры 1.0, которая поддерживается ClickHouse и Apache Hive. Переход возник из-за потребностей пользователя в обработке данных в реальном времени и запросах на объединение нескольких таблиц. В ходе работы с ClickHouse они обнаружили неадекватную поддержку параллелизма и многотабличных соединений, что проявляется в частых тайм-аутах в информационной панели и ошибках OOM в распределенных соединениях.
Теперь давайте посмотрим на их практику приема, хранения и запросов данных с помощью Архитектуры 2.0.
Реальная практика
Стабильная обработка 15 миллиардов журналов в день
В случае пользователя, его бизнес производит 15 миллиардов журналов каждый день. Быстро и стабильно принять такой объем данных — настоящая проблема. При использовании Apache Doris рекомендуется использовать Flink-Doris-Connector. Он был разработан сообществом Apache Doris для крупномасштабной записи данных. Компонент требует простой настройки. Он реализует потоковую загрузку и может достигать скорости записи 200 000–300 000 журналов в секунду, не прерывая рабочие нагрузки по анализу данных.
Извлеченный урок заключается в том, что при использовании Flink для высокочастотной записи вам необходимо найти правильную конфигурацию параметров для вашего случая, чтобы избежать накопления версий данных. В данном случае пользователь произвел следующие оптимизации:
* Flink Checkpoint: они увеличивают интервал между контрольными точками с 15 до 60 секунд, чтобы уменьшить частоту записи и количество транзакций, обрабатываемых Doris за единицу времени. Это может снизить нагрузку на запись данных и избежать создания слишком большого количества версий данных.
* Предварительное агрегирование данных. Для данных с одинаковым идентификатором, но взятых из разных таблиц, Flink предварительно агрегирует их на основе идентификатора первичного ключа и создает плоскую таблицу, чтобы избежать чрезмерного потребления ресурсов. путем записи данных из нескольких источников.
* Doris Compaction. Хитрость здесь заключается в поиске правильных параметров серверной части Doris (BE) для выделения нужного количества ресурсов ЦП для уплотнения данных, установке соответствующего количества разделов данных, сегментов и реплик (также планшеты с большим количеством данных принесут огромные накладные расходы) и наберите max_tablet_version_num, чтобы избежать накопления версий.
В совокупности эти меры обеспечивают стабильность ежедневного приема. Пользователь стал свидетелем стабильной производительности и низких показателей уплотнения в серверной части Doris. Кроме того, сочетание предварительной обработки данных в Flink и модели уникального ключа< /a> в Doris может обеспечить более быстрое обновление данных.
Стратегии хранения, позволяющие сократить расходы на 50 %
Размер и скорость создания журналов также влияют на объем хранилища. Среди огромных данных журнала только часть имеет высокую информационную ценность, поэтому хранение должно быть дифференцированным. У пользователя есть три стратегии хранения для снижения затрат.
* Алгоритм сжатия ZSTD (ZStandard): для таблиц размером более 1 ТБ укажите метод сжатия «ZSTD». При создании таблицы будет реализована степень сжатия 10:1.
* Многоуровневое хранение горячих и холодных данных: поддерживается новая функция Дорис. Пользователь устанавливает период «перезарядки» данных в 7 дней. Это означает, что данные за последние семь дней (а именно «горячие» данные) будут храниться на SSD. Со временем горячие данные «остывают» (старше семи дней) и автоматически перемещаются на жесткий диск, что обходится дешевле. По мере того, как данные становятся еще «холоднее», они будут перемещаться в объектное хранилище для гораздо более низких затрат на хранение. Кроме того, в объектном хранилище данные будут храниться только в одной копии вместо трех. Это еще больше снижает затраты и накладные расходы, связанные с избыточностью. хранилище.
* Дифференцированные номера реплик для разных разделов данных: пользователь разделил свои данные по временному диапазону. Принцип заключается в том, чтобы иметь больше реплик для новых разделов данных и меньше для старых. В их случае часто обращаются к данным за последние 3 месяца, поэтому у них есть 2 реплики для этого раздела. Данные возрастом 3–6 месяцев имеют две реплики, а данные шестимесячной давности имеют одну копию.
Благодаря этим трем стратегиям пользователи сократили расходы на хранение данных на 50 %.
Стратегии дифференцированных запросов в зависимости от размера данных
Некоторые журналы необходимо немедленно отслеживать и находить, например журналы аномальных событий или сбоев. Чтобы обеспечить ответ на эти запросы в режиме реального времени, у пользователя есть разные стратегии запросов для разных размеров данных:
* Менее 100 ГБ: пользователь использует функцию динамического разделения Doris. Маленькие таблицы будут секционированы по дате, а большие таблицы — по часам. Это позволит избежать искажения данных. Чтобы дополнительно обеспечить баланс данных внутри раздела, они используют идентификатор снежинки в качестве поля группирования. Они также установили начальное смещение в 20 дней, что означает, что данные за последние 20 дней будут сохранены. Таким образом они находят точку баланса между накопившимися данными и аналитическими потребностями.
* 100G~1T: эти таблицы имеют материализованные представления, которые представляют собой предварительно вычисленные наборы результатов, хранящиеся в Doris. Таким образом, запросы к этим таблицам будут выполняться гораздо быстрее и менее ресурсозатратно. Синтаксис DDL материализованных представлений в Doris такой же, как в PostgreSQL и Oracle.
* Более 100 Т: эти таблицы помещаются в модель агрегатных ключей Apache Doris и предварительно агрегируются. Таким образом, мы обеспечиваем выполнение запросов к 2 миллиардам записей журнала за 1–2 секунды.
Эти стратегии позволили сократить время ответа на запросы. Например, раньше запрос определенного элемента данных занимал несколько минут, но теперь его можно выполнить за миллисекунды. Кроме того, для больших таблиц, содержащих 10 миллиардов записей данных, все запросы по различным измерениям можно выполнять в несколько секунд.
Текущие планы
Пользователь сейчас тестирует недавно добавленный инвертированный индекс в Apache Doris. Он предназначен для ускорения полнотекстового поиска строк, а также запросов эквивалентности и диапазона чисел и даты и времени. Они также предоставили ценные отзывы о логике автоматического группирования в Doris: в настоящее время Doris определяет количество сегментов для раздела на основе размера данных предыдущего раздела. Проблема для пользователя заключается в том, что большая часть новых данных поступает в дневное время, но мало — ночью. Таким образом, в их случае Дорис создает слишком много сегментов для ночных данных, но слишком мало для дневных, что является противоположностью того, что им нужно. Они надеются добавить новую логику автоматического группирования, в которой Дорис сможет определить количество сегментов на основе размера и распределения данных предыдущего дня. Они пришли в сообщество Apache Doris, и сейчас мы работаем над этой оптимизацией.
Также опубликовано здесь.