

Экспериментальная оценка Unipelt: надежный рост над тонкой настройкой и отдельными методами шкура
13 августа 2025 г.Таблица ссылок
Аннотация и 1. Введение
Предварительные
Объединение методов шкура
Эксперименты
4.1 Настройка эксперимента
4.2 Анализ отдельных методов шкура
4.3 Анализ Unipelt
4.4 Эффективность методов шкура
Связанная работа
Заключение, подтверждение и ссылки
4 эксперименты
Мы проводим обширные эксперименты с 8 задачами × 4 размера данных × 7 Методов × 5 прогонов за настройку, а также дополнительный анализ для конкретных методов, в результате чего в общей сложности стало более 1000 прогонов.
4.1 Настройка эксперимента
Настройка задачи. Мы проводим эксперименты по сравнению с общим языковым пониманием оценки (GLUE) (Wang et al., 2019), который включает в себя четыре типа задач по пониманию естественного языка, включая лингвистическую приемлемость (COLA), анализ настроений (SST-2), сходство и задачи перефразы (MRPC, STS-B, QQP) и естественный язык (MNLI, QNLI, RTE). Мы исключаем набор данных WNLI после предыдущих исследований (Houlsby et al., 2019; Devlin et al., 2019).
Настройка данных.В основном мы рассмотрим настройку с низким ресурсом, где данные обучения ограничены, а производительность различных методов сильно варьируется. Мы продемонстрировали небольшое подмножество учебного набора для каждой задачи с размером k = {100, 500, 1000}. Поскольку невозможно представить значительные пробеги в клей
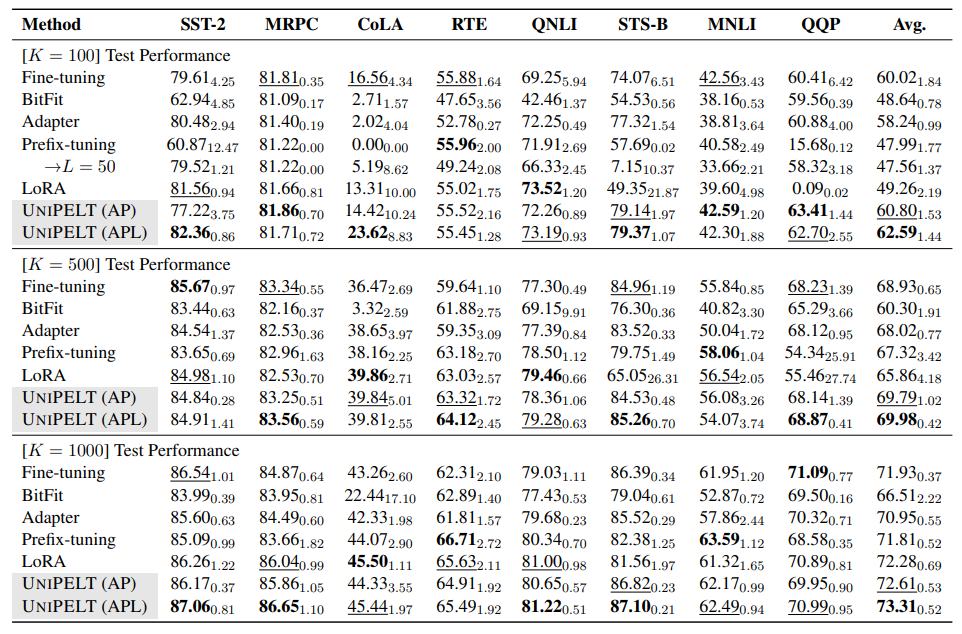
Таблица лидеров (2 материала/день), мы принимаем 1000 образцов на учебном наборе в качестве набора разработки, чтобы выбрать лучшую контрольную точку и использовать исходный набор разработки в качестве тестового набора. Чтобы уменьшить дисперсию, мы перетасываем данные с 5 случайными семенами и сообщаем об средней производительности. Кроме того, мы рассмотрим настройку с высоким разрешением, где используется весь учебный набор, и сообщается о наилучшей производительности в наборе разработки клея.
Сравнили методы.В основном мы сравниваем Unipelt с тонкой настройкой и четырьмя репрезентативными методами шкура: адаптер (Houlsby et al., 2019), префикс-настройка (Li and Liang, 2021), Bitfit (Ben Zaken et al., 2021) и Lora (Hu et al., 2021). Для полноты мы рассмотрим два варианта модели Unipelt (AP) и Unipelt (APL), которые включают в себя 2 и 3 метода шкура соответственно.

4.2 Анализ отдельных методов шкура
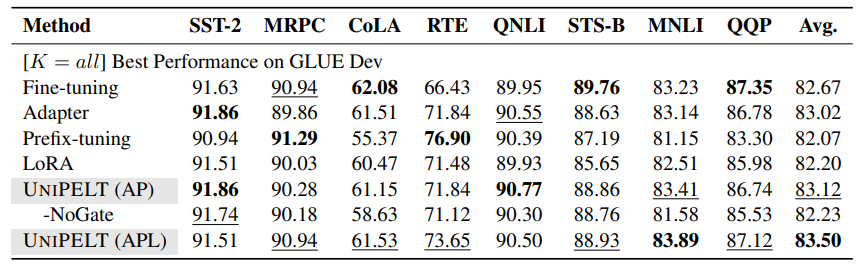
В таблице 1 мы показываем производительность различных методов на эталоне клея с различными размерами учебных данных. Результаты по наборам разработок, как правило, соответствуют тестовым наборам и предоставляются в приложении. D. Хотя средняя производительность различных методов по 8 задачам иногда похожа, различия между задачами довольно значительны в определенных настройках и могут составлять 5 ~ 9 баллов по конкретной задаче (например, STS-B и MNLI, K = 500) даже при исключении случаев, когда некоторые методы не учатся эффективно (например, предварительное точко
Затем мы будем анализировать и изучить каждый отдельный метод PELT.

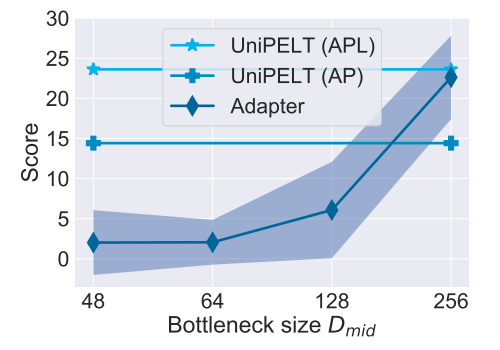

С другой стороны, существуют определенные задачи (например, STS-B), которые адаптер в значительной степени превосходит конкурентные методы, такие как префикс-настройка и Лора, независимо от размера учебных данных, что предполагает, что можно предположить адаптер по сравнению с другими методами шкура в рамках определенных сценариев.
Анализ префикса настройки.Настройка префикса работает плохо с k = {100, 500} и становится на одном уровне с точной настройкой, когда K достигает 1000. Мы также наблюдаем, что префикс-настройка не может эффективно учиться на определенных задачах, когда учебные данные ограничены (например, k = 100 на SST-2 и K = 500 на QQP), приводя к неустойчивому производительности и (или) большим вариациям. Подобные явления наблюдались в одновременном исследовании (Gu et al., 2021) на нескольких выстрелах.
Чтобы убедиться, что плохая производительность префиксунтирования не связана с его меньшим количеством обучения (на основе его настройки по умолчанию), мы дополнительно увеличиваем длину префикса до L = 50, что его обучаемые параметры сопоставимы с адаптером и переоценивают префикс-настройку на всех 8 задачах с k = 100. и QQP), хотя его производительность значительно улучшается по 3 задачам, он также работает значительно хуже для другой задачи (STS-B), что предполагает, что нестабильность обучения в режиме с низким разрешением по-прежнему является проблемой для префикса настройки даже с более обучаемыми параметрами. [5] Кроме того, префикс-настройка (L = 50) все еще отстает от адаптера или Unipelt (AP) на 3 из 4 задач. Кроме того, средняя производительность префикс-настройки (L = 50) по 8 задачам даже немного хуже, чем при L = 10, что указывает на то, что увеличение длины префикса может не быть панацеей для всех сценариев. Большой L также приводит к значительному замедлению обучения/вывода из-за дорогостоящего многоуровневого внимания. В более широком смысле, такие результаты показывают, что использование более обучаемых параметров не гарантирует лучшую производительность.
С другой стороны, префикс-настройка хорошо выполняет определенные задачи, такие как вывод естественного языка (RTE и MNLI) с различными размерами учебных данных, что предполагает, что в некоторых случаях следует также предпочитать префикс-настройку.
Анализ BitFit & Lora.Настройка только условия смещения модели не приводит к очень удовлетворительным результатам в наших экспериментах - BitFit никогда не выполняет наилучшие и, как правило, выполняет худшие в различных настройках данных и задачи. Поэтому мы не рассматриваем BitFit в следующих экспериментах и исключаем BitFit как подмодуль Unipelt. Что касается LORA, есть несколько настройки, где LORA не может эффективно учиться, например, STS-B и QQP (k = {100, 500}), что приводит к высокой дисперсии между прогонами. Кроме того, Лора выступает
довольно конкурентоспособно, несмотря на использование меньшего количества обучаемых параметров, чем такие методы, как адаптер, особенно когда k = 1000, достижение лучших или 2 -го лучшего производительности по 4 из 8 задач.
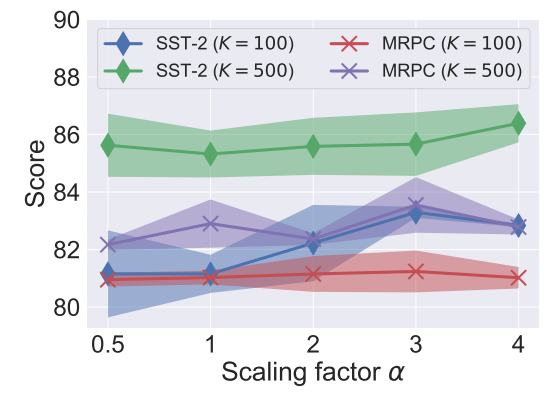
Поскольку у Лоры есть масштабирующий коэффициент α, который можно рассматривать как статическую функцию стробирования в рамках нашей формулировки, мы дополнительно исследуем его важность, оценивая Лору с различным α. Как показано на рис. 3, Лора весьма чувствителен к коэффициенту масштабирования, и, по -видимому, нет единого оптимального значения, которое хорошо работает для множества задач и настройки данных. Такие результаты показывают, что стробирование имеет решающее значение и мотивирует нас использовать более мелкозернистый и динамический контроль для Unipelt. Кроме того, мы наблюдаем, что увеличение α последовательно приводит к более быстрой сходимости, возможно, потому, что обучаемые параметры получат более крупные обновления градиента с большим α.
4.3 Анализ Unipelt
Затем мы перейдем к предлагаемой нами рамки Unipelt, которая включает в себя несколько существующих методов шкура в качестве подмодулей.
Производительность с низким ресурсом.В целом, Unipelt (APL) и Unipelt (AP) последовательно достигают лучших и второго лучшего среднего показателя как на наборах разработки, так и в тестовых наборах независимо от количества образцов обучения. Прибыль, как правило, на 1 ~ 4% над подмодулем, который выполняет лучшее (при использовании индивидуально). Такие результаты демонстрируют преимущества нашего гибридного подхода в отношении эффективности модели и обобщения.
На уровне за задание Unipelt (APL) и Unipelt (AP) выполняют лучшее или второе лучшее 7/6/7 из 8 задач при обучении с образцами 100/500/1000, и никогда не выполняют худшее в любой установке. При сравнении двух вариантов Unipelt (APL) превосходит Unipelt (AP) 4/6/8 из 8 задач при обучении с образцами 100/500/1000. Такие результаты указывают на то, что Unipelt довольно надежный и надежно выполняет различные сценарии. Улучшения Unipelt по сравнению с его подмодулями, как правило, больше, если иметь меньше тренировочных образцов, что позволяет предположить, что Unipelt особенно хорошо работает в режиме с низким ресурсом. В частности, в задачах, где другие методы PELT не могут эффективно учиться, такие как COLA и QQP (K = 100), Unipelt удается достичь производительности лучше, чем тонкая настройка.
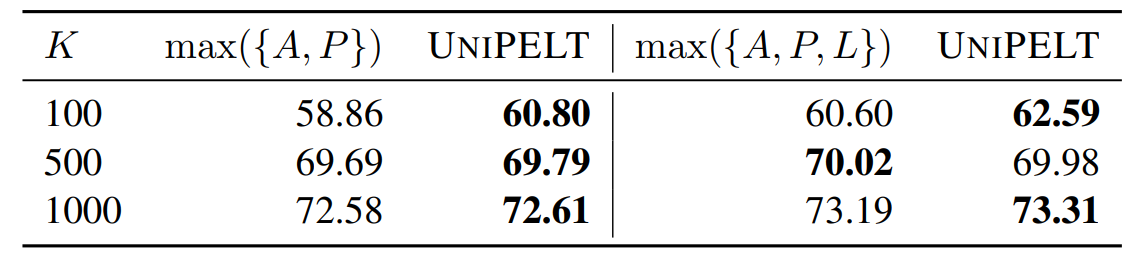
Unipelt против верхней границы.В таблице 2 мы показываем сравнение Unipelt и верхней границы, которые принимают наилучшие результаты его подмодулей по каждой задаче. Мы отмечаем, что как Unipelt (AP), так и Unipelt (APL) работают так же или даже лучше, чем их верхняя граница, что говорит о том, что Unipelt успешно учится использовать различные подмодули и поддерживает (почти) оптимальную производительность при различных настройках. Тот факт, что Unipelt может превзойти верхнюю границу, также намекает на то, что смесь методов шкура (с участием различных частей PLM) может быть по своей природе более эффективной, чем отдельные методы (с ограниченным объемом архитектуры PLM).
Производительность с высоким ресурсом.В таблице 3 мы перечисляем производительность различных методов, когда используются все обучающие образцы. Unipelt снова достигает лучшей общей производительности. Прибыль не так значительна, как в условиях с низким ресурсом, что несколько ожидается, поскольку существующие методы шкура обычно работают наравне с тонкой настройкой, учитывая обильные данные обучения, и потенциал улучшения не так высок. Тем не менее, производительность Unipelt по -прежнему является лучшим или вторым лучшим по всем 8 задачам, и, как правило, сравнимо с лучшим подмодулем, используемым индивидуально для каждой задачи. Кроме того, простое сочетание нескольких методов шкура без стробирования не очень хорошо работает в условиях с высоким разрешением-хотя Unipelt-Nogate никогда не выполняет худшее в каждой задаче, его средняя производительность является неудовлетворительной (-0,89 против Unipelt).
4.4 Эффективность методов шкура
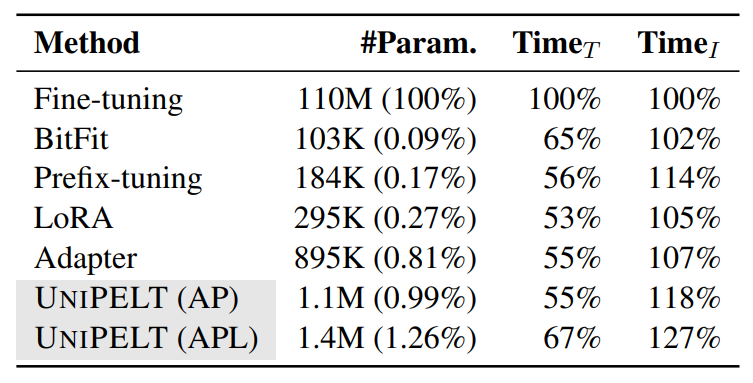
Мы сравниваем эффективность методов PELT и перечислим в таблице 4 их количество обучаемых параметров и времени обучения/вывода относительно тонкой настройки.
Эффективность параметра.Поскольку обучаемые параметры в методах шкура практически незначительны, объединение нескольких методов не приводит к значительным потерям в эффективности параметров. Unipelt по-прежнему имеет несколько обучаемых параметров по сравнению с тонкой настройкой (0,99%~ 1,26%). Параметры могут быть дополнительно уменьшены, если кто-то использует более эффективные варианты параметров (например, Karimi Mahabadi et al. (2021a)), которые можно легко поменять на ванильной версии, используемой в нашей текущей структуре. Кроме того, обратите внимание, что более обучаемые параметры не всегда приводят к лучшей производительности, как показано в наших экспериментах и предыдущих исследованиях (He et al., 2021; Pfeiffer et al., 2021).
Обучение и эффективность вывода.Из-за эффективности параметров все методы PELT обучаются на 30% ~ 50% быстрее, чем тонкая настройка, и включение нескольких методов PELT в Unipelt не страдает от более медленных тренировок. С другой стороны, время вывода методов шкура, как правило, длиннее, поскольку они включают в себя больше провалов. Unipelt имеет немного больший вывод накладных расходов (4% ~ 11% по сравнению с самым медленным подмодулем), который, по нашему мнению, является незначительным, поскольку более крупные модели, которые могут достигать аналогичного повышения производительности (например, Bertlarge), нуждаются в 300% времени вывода (Wolf et al., 2020).
Авторы:
(1) Юнинг Мао, Университет Иллинойса Урбана-Шампейн и работа была выполнена во время стажировки в Meta AI (yuningm2@illinois.edu);
(2) Ламберт Матиас, Meta AI (mathiasl@fb.com);
(3) Rui Hou, Meta AI (rayhou@fb.com);
(4) Amjad Almahairi, Meta AI (aalmah@fb.com);
(5) Хао Ма, Мета Ай (haom@fb.com);
(6) Цзявей Хан, Университет Иллинойса Урбана-Шампейн (hanj@illinois.edu);
(7) Wen-tau Yih, Meta AI (scottyih@fb.com);
(8) Мадиан Хабса, Meta AI (mkhabsa@fb.com).
Эта статья есть
[4] Хотя эти гиперпараметры могут привести к различиям в обучении параметров, мы сохраняем их для анализа, поскольку они используются официальной реализацией. Кроме того, мы наблюдаем, что более обучаемые параметры не гарантируют лучших результатов.
[5] Настройка других гиперпараметров, таких как уровень обучения, также не облегчает проблему.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)