
Оценка эффективности аудита честности в реальных системах машинного обучения
4 января 2024 г.:::информация Этот документ доступен на arxiv по лицензии CC BY 4.0 DEED.
Авторы:
(1) Эхсан Торейни, Университет Суррея, Великобритания;
(2) Марьям Мехрнежад, Лондонский университет Ройал Холлоуэй;
(3) Аад Ван Мурсел, Бирмингемский университет.
:::
Таблица ссылок
Справочная информация и сопутствующая работа
Анализ внедрения и производительности
4 Анализ внедрения и эффективности
4.1. Проверка концепции
Инструменты и платформа. Серверная часть реализована на Python v3.7.1, а интерфейсная часть — на Node.js v10.15.3. По нашим оценкам, вычисления, необходимые для создания таблицы криптограмм (в системе ML), выполняются с помощью Python. Для операций с эллиптическими кривыми используется пакет Python tinyec, а для преобразования классов Python в формат, совместимый с JSON, используется пакет Python JSONpickle. Все эксперименты проводятся на ноутбуке MacBook Pro со следующими конфигурациями: Процессор 2,7 ГГц, четырехъядерный процессор Intel Core i7 с памятью 16 ГБ под управлением MacOS Catalina v.10.15.5 для операционной системы
Набор данных тематического исследования: мы используем общедоступный набор данных из исследования панели медицинских расходов (MEPS) [21], который содержит 15830 точек данных об использовании медицинских услуг отдельными лицами. Мы разработали модель (логистическую регрессию), которая определяет, нуждается ли конкретный пациент в медицинских услугах, например в дополнительном уходе. Эта система ML присваивает балл каждому пациенту. Если показатель превышает заданный порог, пациенту требуются дополнительные медицинские услуги. В наборе данных MEPS защищенным атрибутом является «раса». Справедливая система обеспечивает
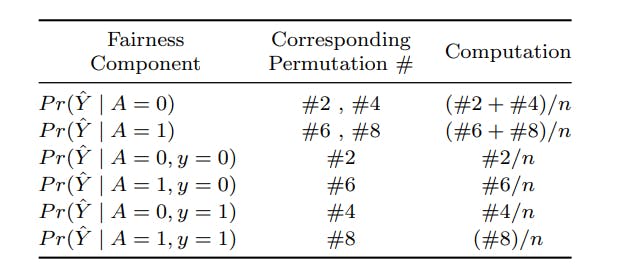
Таблица 4. Необходимые перестановки для расчета показателей справедливости системы машинного обучения
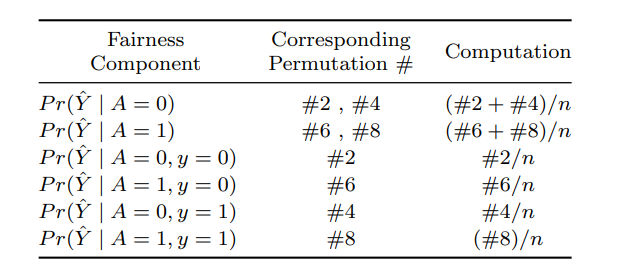
Такие услуги практически не зависят от расы пациента. Здесь привилегированной расовой группой в этом наборе данных является «белая этническая принадлежность». Мы использовали 50% набора данных в качестве обучающего, 30% — для проверки, а оставшиеся 20% — в качестве набора тестовых данных. Мы установили количество выборок таблицы криптограмм равным размеру тестового набора (N = 3166). В этом примере мы включаем в криптограмму три атрибута для представления двоичных значений A, Y и Y (раздел 2.1), что приводит к 8 перестановкам для каждого образца данных.

4.2 Производительность
В этом разделе представлено время выполнения каждой точки данных для каждой из основных вычислительных задач на каждом этапе протокола. Напомним, что этап I выполнялся до обучения и тестирования системы ML. Этот этап можно разрабатывать (и хранить отдельно) параллельно с реализацией модели, чтобы снизить проблемы с производительностью этапа I. В нашей реализации выходные данные этого этапа (таблица криптограмм) сохраняются в отдельном файле в формате JSON. формате и может быть получен в начале этапа II
Фаза II начинается после обучения, тестирования и проверки модели ML. На этом этапе выходные данные модели ML используются для создания таблицы аудита справедливости на основе таблицы криптограмм, а также ZKP для получения информации о перестановке. Результаты этого этапа передаются в Службу аудита справедливости в формате JSON для этапа III. На этом этапе сначала проверяются ЗКП, а затем суммирование криптограмм определяет количество перестановок для каждой из чувствительных групп. Получив эти цифры, служба аудита сможет рассчитать справедливость системы ML
По нашим оценкам (где N = 3166) генерация пары открытого/закрытого ключей завершается в среднем за 60 миллисекунд (мс) со стандартным отклонением 6 мс. Время выполнения ZKP закрытого ключа было примерно таким же (в среднем 60 мс при стандартном отклонении 6 мс). Генерация реконструированного открытого ключа заняла около 450 мс со стандартным отклонением 8 мс. Самым вычислительно затратным этапом на этапе I был ZKP 1 из 8 для каждой из перестановок. Этот этап занял больше времени, чем остальные, потому что, во-первых, алгоритм сложнее, а во-вторых, его нужно повторить 8 раз (для каждой из перестановок отдельно) для каждой строки таблицы криптограмм. Вычисление 1 из 8 ZKP занимает 1,7 секунды для каждой выборки данных со стандартным отклонением 0,1 секунды. В целом этап I занял около 14 секунд со стандартным отклонением 1 секунда для каждого образца данных в тестовом наборе. В наших экспериментах (где N = 3166 образцов) общее выполнение этапа I заняло примерно 12 часов 54 минуты.
Фаза II состоит из создания контрольной таблицы и генерации ZKP для знания перестановки. Таблица аудита справедливости получается из таблицы криптограмм (поскольку она сопоставляет кодировку с соответствующим номером перестановки в таблице криптограмм). Время, затраченное на такой вывод, незначительно (всего: 1 мс). Генерация ZKP для знания перестановки выполнялась в среднем менее 60 мс со стандартным отклонением 3 мс для каждой выборки данных. Прохождение обоих этапов заняло менее 3 минут. Таблица аудита справедливости отправляется в Службу аудита справедливости для этапа III.
Проверка ZKP на последнем этапе (Фаза III) является вычислительно дорогостоящей операцией. ZKP для владения закрытым ключом занимал в среднем около 260 мс со стандартным отклонением 2 мс. Проверка 1 из 8 ZKP для каждой точки данных занимала в среднем примерно 2,5 секунды со стандартным отклонением 20 мс. Проверка ЗКП на знание перестановки выполнена за 100мс со стандартным отклонением 5мс. Суммирование криптограмм после проверки заняло в общей сложности 450 мс для N = 3166 элементов. В нашем эксперименте прохождение этапов фазы III в общей сложности заняло около 2 часов 30 минут.
Таким образом, экспериментальная установка для нашей архитектуры, где мы вычислили необходимые криптограммы и ZKP для N = 3166 точек данных в реальном наборе данных, общее время составило около 15 часов для спецификации ноутбука, приведенной ранее. Основная часть времени уходит на расчеты, необходимые для этапа I (12 часов 54 минуты). Однако, как мы отмечали ранее, этап I может быть выполнен до настройки модели ML, он хранится в отдельном файле JSON и будет загружен в начале этапа II (после завершения обучения и проверки модели ML). Другая основная вычислительная работа, которую можно выполнить только после получения результатов системы ML, находится на этапе III. В нашем примере фактическое вычисление справедливости занимает два с половиной часа. Подводя итог, можно сказать, что создание и обработка криптограмм требует значительных вычислительных усилий для реалистичных наборов данных и для показателей справедливости, требующих трех атрибутов. Далее мы анализируем, как производительность масштабируется в зависимости от количества точек данных, а также от количества атрибутов, представленных в криптограммах.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27175)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)