Нельзя слишком рано инвестировать в команду обработки данных. Это то, чему мы научились как небольшая, но растущая команда. Мы вложили средства в группу данных на раннем этапе, чтобы мы могли определять тенденции использования продукта, получать бизнес-аналитику и определять области для улучшения нашего продукта.
Если ваш стартап находится на ранней стадии, начните создавать команду по стратегии работы с данными и архитектуру как можно скорее. Вам не нужно добиваться больших успехов — команда, состоящая из одного человека, может существенно повлиять на ваш успех по мере вашего роста.
Сначала наймите универсального специалиста
Когда дело доходит до запуска вашей команды по работе с данными, у вас может возникнуть соблазн нанять эксперта из самого крупного бренда, на который вы способны. Наш совет: найдите кого-нибудь с опытом работы на ранних стадиях стартапа, который также работал с масштабными данными.
Есть замечательные люди с блестящим умом, работающие в больших корпоративных группах данных, но эти большие команды часто имеют своих сотрудников, специализирующихся на определенных частях их платформы данных. Это имеет смысл, когда у вас в команде 10 инженеров по данным или когда у вас есть большая команда специалистов по машинному обучению, работающих над алгоритмами ценообразования. Но когда у вас есть только одна роль данных для всей организации, вам нужен кто-то, кто может делать все понемногу.
Важно сначала нанять универсала, который может анализировать данные, разрабатывать бизнес-гипотезы и создавать масштабируемую архитектуру данных с нуля. Вам нужен кто-то, готовый создать команду по обработке данных с нуля, желательно тот, кто сможет нанять остальную часть вашей команды, как только вы будете к этому готовы.
Этот первый наем должен быть кем-то, у кого есть опыт создания (или, по крайней мере, работы) команды данных на ранней стадии стартапа. Они должны уметь быстро создавать ценность и обладать деловой хваткой, чтобы задавать правильные вопросы. Они должны уметь подходить к данным по принципу 80/20, чтобы получать немедленные результаты, вместо того, чтобы углубляться в самые сложные проблемы, с которыми вы сталкиваетесь.
Что касается инженерии данных, обычно нанимают консультанта или подрядчика для помощи в настройке вашей архитектуры. Мы решили дополнить нашу первую работу консультантом. Таким образом, у нас есть лучшее из обоих миров — эксперт по обработке данных с частичной занятостью и специалист широкого профиля, который может поддерживать архитектуру данных на ежедневной основе. Мы заложили прочный фундамент, а также сохранили свои знания.
Небольшая группа данных может ответить на большие вопросы
Даже если вы не можете сразу нанять сотрудников на все должности, которые вам нужны в вашей команде по работе с данными в долгосрочной перспективе, вы можете многое сделать, имея только одного или двух нужных людей. Главное думать с точки зрения масштабируемости и эффективности. Что помогает вашей команде данных делать больше с меньшими затратами? И как это будет работать, когда ваша команда станет больше?
Масштабируемый анализ чрезвычайно важен для небольшой группы данных. Заранее продумывая, как ваши процессы и рабочие процессы будут функционировать по мере роста вашей команды, вы сэкономите время и создадите ценные решения для некоторых наиболее трудоемких проблем ваших сотрудников.
Например, мы сразу поняли, что наша команда по продажам не имеет представления об использовании продукта потенциальными клиентами, и это будет часто всплывать. Поэтому мы создали для наших торговых представителей рабочее место, чтобы они могли сами получать данные. Работа нашей команды по работе с данными заключается в обеспечении принятия решений на основе данных. Когда мы увидели возможность единовременного вложения данных, которая может привести к экономии сотен часов продаж, мы воспользовались ею.
Небольшая группа данных также должна быть сосредоточена на предотвращении проблем в будущем. Если на данный момент у вас есть только команда по работе с данными, состоящая из одного человека, сосредоточьте их внимание на ваших самых серьезных проблемах, а также выделите время для поддержки и масштабирования вашей архитектуры данных, чтобы сократить технический долг.
Инструменты, которые использует наша команда по работе с данными
С самого начала нашей целью было продумывать каждое решение.
Как и все стартапы, мы хотели получить немедленную окупаемость инвестиций. Мы используем централизованное хранилище данных, которое является нашим единственным источником достоверной информации. Ничто так не вредит командам по работе с данными, как наличие фрагментированных или ненадежных данных. Мы можем консолидировать наши данные благодаря автоматизации и интеграции.
Это помогает нам предоставлять ценную информацию всей компании с низким уровнем подъема.
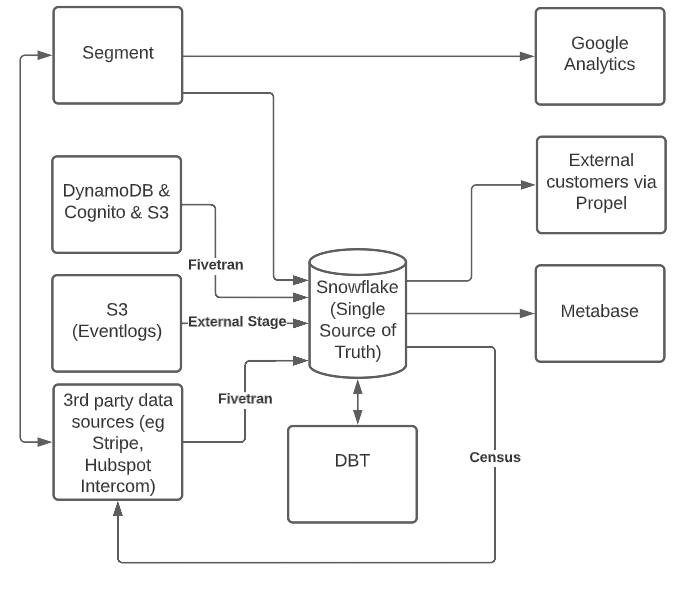
Мы передаем все наши данные с помощью инструментов ELT, таких как Segment (который также является нашим инструментом сбора данных), Fivetran и внешние этапы Snowflake.
Мы используем dbt, чтобы преобразовать все необработанные данные в более удобный формат. Например, наша таблица dim_user имеет около 20 внутренних таблиц, которые содержат много важной информации о наших клиентах, например, сколько уведомлений они отправляют и какой у них тарифный план. Делая это настолько доступным, наши пользователи, не являющиеся техническими специалистами, могут быстро получать информацию о бизнесе. Мы можем быстро посмотреть на неплатящих или самообслуживающихся клиентов, которые отправляют много уведомлений, чтобы определить перспективы деловых контрактов. Наша команда по работе с клиентами также создала отчеты, чтобы следить за состоянием наших клиентов по контрактам. Мы также используем dbt для очистки наших данных от конфиденциальной информации.
Мы используем Census для отправки данных нашего хранилища обратно в такие места, как HubSpot и Courier. Это позволяет нашим командам по продажам и маркетингу получать доступ к этой информации на платформе, которую они используют ежедневно.
Метабаза — это наш инструмент BI. Это позволяет нам создавать информационные панели, писать SQL-запросы и предоставлять формат самообслуживания для нетехнических пользователей. Мы обнаружили, что создание таких информационных панелей самообслуживания позволяет пользователям отвечать на множество своих собственных вопросов. Они быстро раскручиваются без больших предварительных вложений, как команды, использующие Looker или Tableau.
Например, у нас есть тире KPI, которое показывает основные показатели в компании. Мы также можем отслеживать, как работают отдельные рабочие области, и определять рабочие области, на которые мы можем ориентироваться для нашей команды по продажам. Мы также внедрили процесс принятия решений на основе данных в процесс разработки наших продуктов, тщательно изучив использование продуктов нашими клиентами. Одним из примеров является то, что мы обнаружили, что многие наши пользователи создавали свой собственный экземпляр Courier вместо того, чтобы присоединяться к существующему экземпляру Courier своего коллеги. Используя это понимание, наша команда разработчиков вернулась к чертежной доске, чтобы создать страницу, отображающую рабочие области Courier, созданные в том же домене корпоративной электронной почты, чтобы вы могли легко запросить доступ.
Мы также используем Propel для повышения эффективности нашей аналитики в приложении, чтобы обеспечить видимость для наших конечных пользователей. Одним из способов использования Propel является предоставление аналитики шаблонов для наших клиентов бизнес-уровня. Propel позволяет нашим инженерам легко накладывать визуализации GraphQL поверх наших метрик с нашего склада.
Наша группа данных снова развивается
Сейчас мы вступаем в период роста, поэтому, естественно, мы снова развиваем наш подход к данным. Наша текущая цель — дать возможность нашим специалистам по обработке и анализу данных накапливать экспертные знания в предметной области, сохраняя при этом централизованные стандарты данных.
Наша текущая структура централизована, старший инженер-аналитик подчиняется руководителю отдела данных. Это работает сейчас, поскольку мы все еще находимся на ранних этапах создания команды данных. Но когда команда расширится, мы перейдем на гибридную модель.
Специалисты по данным будут охватывать определенные области бизнеса (например, команду разработчиков), но они по-прежнему будут отчитываться перед руководителем отдела данных. Это позволит специалистам по данным накапливать экспертные знания в предметной области, сохраняя при этом централизованные стандарты данных по мере того, как мы продолжаем расти. Поскольку отдел данных всегда будет меняться и расти вместе с остальной частью организации, вам нужны стандарты, которые будут масштабироваться вместе с бизнесом.
Если вы хотите узнать больше о том, как мы подходим к стандартизации данных, ознакомьтесь с записью в нашем блоге на странице как Courier стал соответствовать требованиям HIPAA.