
Улучшение подготовки данных с помощью ИИ для бизнес-аналитики
7 ноября 2023 г.В мире анализа данных и бизнес-аналитики группы обработки данных также называются «== фиолетовые команды==», которые создают решения, необходимые бизнес-пользователям (красный) и работают с инженерными командами (синий), по сути, создают инфраструктуру для данных.
Команды BI преимущественно работают над созданием потоков или конвейеров, которые предоставляют отчеты и необходимые информационные панели для использования бизнес-пользователями.
Существует множество инструментов нового поколения, которые помогают группам обработки данных создавать решения для конечных пользователей, например Mode, Superset и Lightdash или лидеры отрасли, работавшие в сфере «аналитики данных» для некоторое время, например Tableau или PowerBI.
Аналитики, создающие эти решения, должны подготовить свои данные из различных источников, гарантируя, что данные очищены для запросов. Набор инструментов или преобразований, предназначенных для выполнения этапа очистки в рабочем процессе, называемого «Подготовка данных».

С появлением больших языковых моделей обсуждение ИИ стало общей тенденцией в разработке программного обеспечения. Но что, если я скажу: используя методы ИИ, ориентированные на данные, мы могли бы автоматизировать этап очистки данных? Позволяет вам экспортировать более чистую версию набора данных с минимальными усилиями!
В этом блоге мы обсудим, как с помощью Data-centric AI вы можете легко подготовить данные для инструментов BI, чтобы обеспечить надежные выводы из последующего анализа данных.
Рабочий процесс аналитика данных
Несколько лет назад аналитикам данных приходилось вручную собирать, очищать и анализировать данные. Этот процесс занимал много времени и ограничивал их возможности получать ценную информацию.

Сегодня среда анализа данных претерпела значительные изменения с появлением таких инструментов подготовки данных, как Alteryx, Таблица и т. д.
Эти эффективные инструменты упростили рабочий процесс, позволяя аналитикам легко интегрировать данные из нескольких источников, автоматизировать задачи очистки данных и создавать визуально привлекательные и содержательные представления данных.

Анализ данных после ручной подготовки
Данные, подготовленные с помощью этих инструментов, анализируются с помощью инструментов BI для выявления конкретных бизнес-запросов.
Например, рассмотрим этот набор данных о запросах клиентов в банке, где клиенты регистрируют проблемы, с которыми они сталкиваются. на портале обслуживания клиентов, который затем маркируется человеком или автоматизированным менеджером задач.
Представьте себе, что бизнес-аналитик должен определить количество запросов клиентов, поступивших по определенной категории проблем. Ниже приведен результат, который он/она увидит: категория beneficiary_not_allowed, показывающая 111 проблемы клиентов.
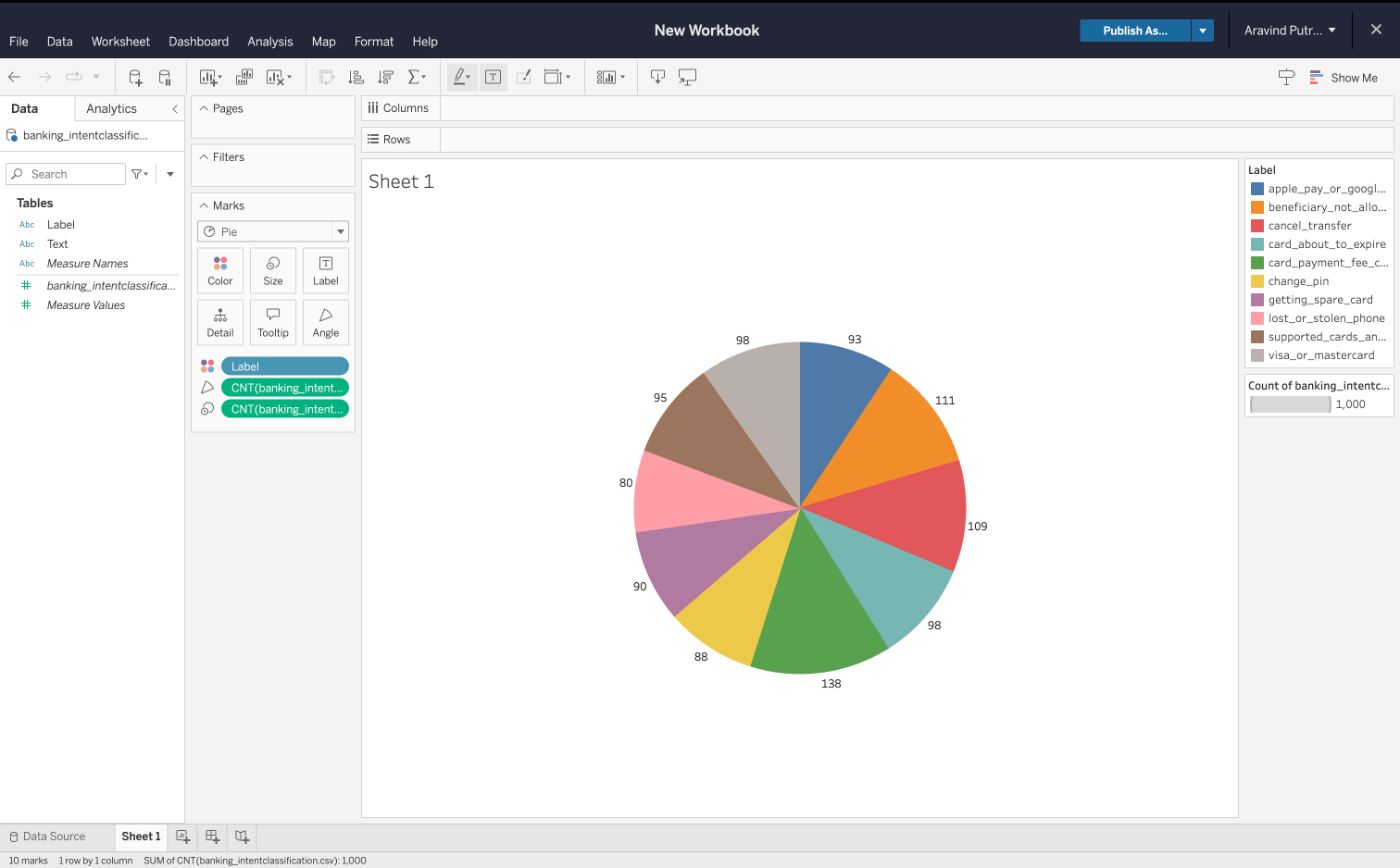
Аналогично, если аналитик хочет узнать, сколько случаев проблем связано со словом ATM, быстрый анализ вернется под визуальным представлением. Обратите внимание на количество проблем в категории change_pin.
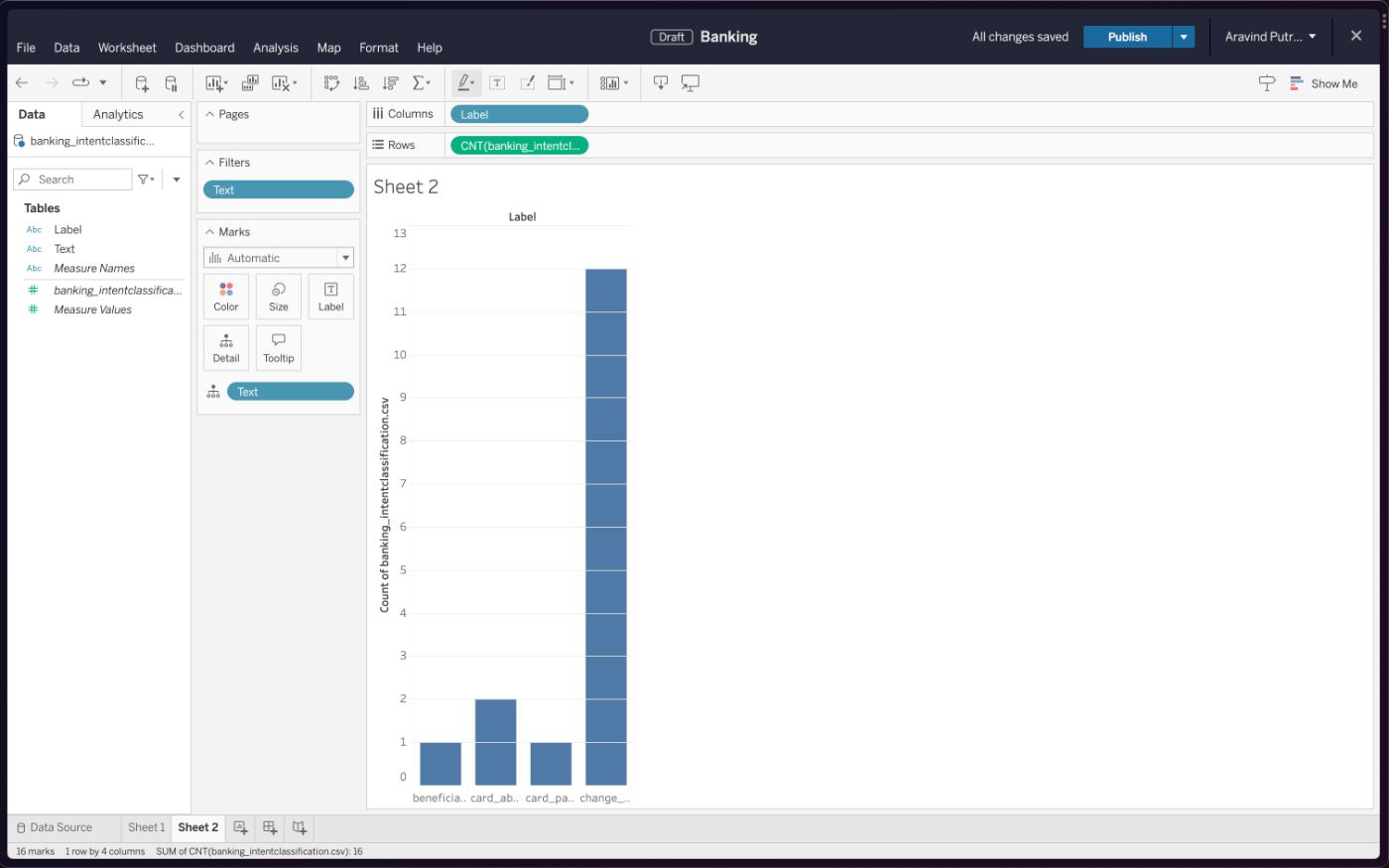
Это выглядит просто и понятно, но если вы углубитесь в набор данных, вы сможете найти классификацию клиентов. в некоторых случаях запросы неверны.
Например:
| Текст | Этикетка (согласно набору данных) | Этикетка (в идеале) | |----|----|----| | Срок действия моей карты почти истек. Как быстро я получу новый и какова его стоимость? | apple_pay_or_google_pay | card_about_to_expire |
<блок-цитата>Реальные данные по большей части беспорядочны и неструктурированы, что затрудняет вычисление значений с помощью статистики. Поскольку мы хотим, чтобы люди и машины принимали решения на основе данных, крайне важно, чтобы данные были хорошо маркированы, очищены от любых ошибочных данных и дедуплицированы.
Информационно-ориентированный искусственный интеллект
Очень важно обеспечить точность, актуальность и отсутствие дубликатов данных, используемых в анализе. Несоблюдение этого требования может привести к неверным решениям и выводам. Например, пустое поле местоположения в данных профиля пользователя или несогласованное форматирование поля местоположения могут привести к ошибкам. Поэтому поддержание качества данных имеет решающее значение для эффективной аналитики данных.
Ориентированный на данные ИИ — это дисциплина систематического проектирования данных, используемых для создания системы ИИ. Большинство данных в реальном мире неструктурированы или помечены неправильно. Качественный набор данных с правильным набором помеченных обучающих данных приводит к созданию эффективной модели, которая может предсказать лучшие результаты.
Лучшие результаты обеспечивают лучшее качество обслуживания клиентов. Чтобы узнать больше, вы можете обратиться к курсу Data-centric AI от MIT.
Представляем Cleanlab
Cleanlab – это проект с открытым исходным кодом, который помогает очищать данные и метки путем автоматического обнаружения проблем в наборе данных. Cleanlab использует уверенное обучение — на основе статьи Кертиса Норткатта об оценке неопределенности в метках наборов данных. (также соучредитель Cleanlab.ai) и других.
Cleanlab существенно улучшает рабочий процесс анализа данных за счет использования искусственного интеллекта.

Автоматическая очистка данных с помощью Cleanlab Studio
Cleanlab Studio — это инструмент без кода, созданный на базе пакета с открытым исходным кодом Cleanlab. Он помогает подготовить данные для рабочего процесса анализа. Вы также можете импортировать данные из своих хранилищ данных, например Databricks, Snowflake или облачные хранилища объектов, такие как AWS S3.
Шаг 1:
Зарегистрируйтесь, чтобы получить доступ к Cleanlab Studio.
Вы войдете в панель управления с примерами наборов данных и проектов.
Шаг 2:
Нажмите «Загрузить набор данных», чтобы запустить мастер загрузки. Вы можете загрузить набор данных со своего компьютера, URL-адреса, API или хранилища данных, например Databricks и Snowflake.
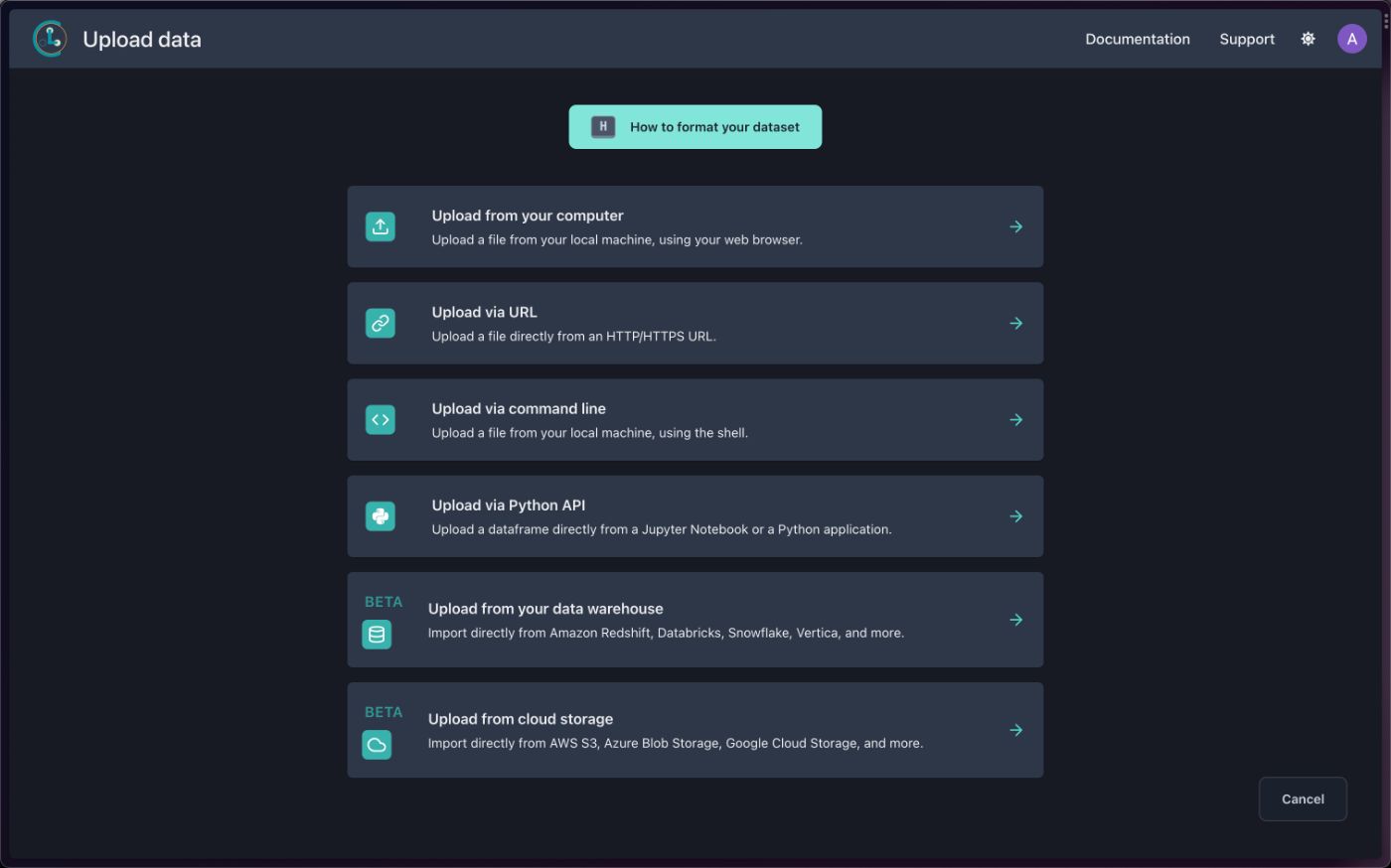
Cleanlab Studio автоматически определяет вашу схему и модальность данных, т. е. текст, изображение, голос или таблицу.
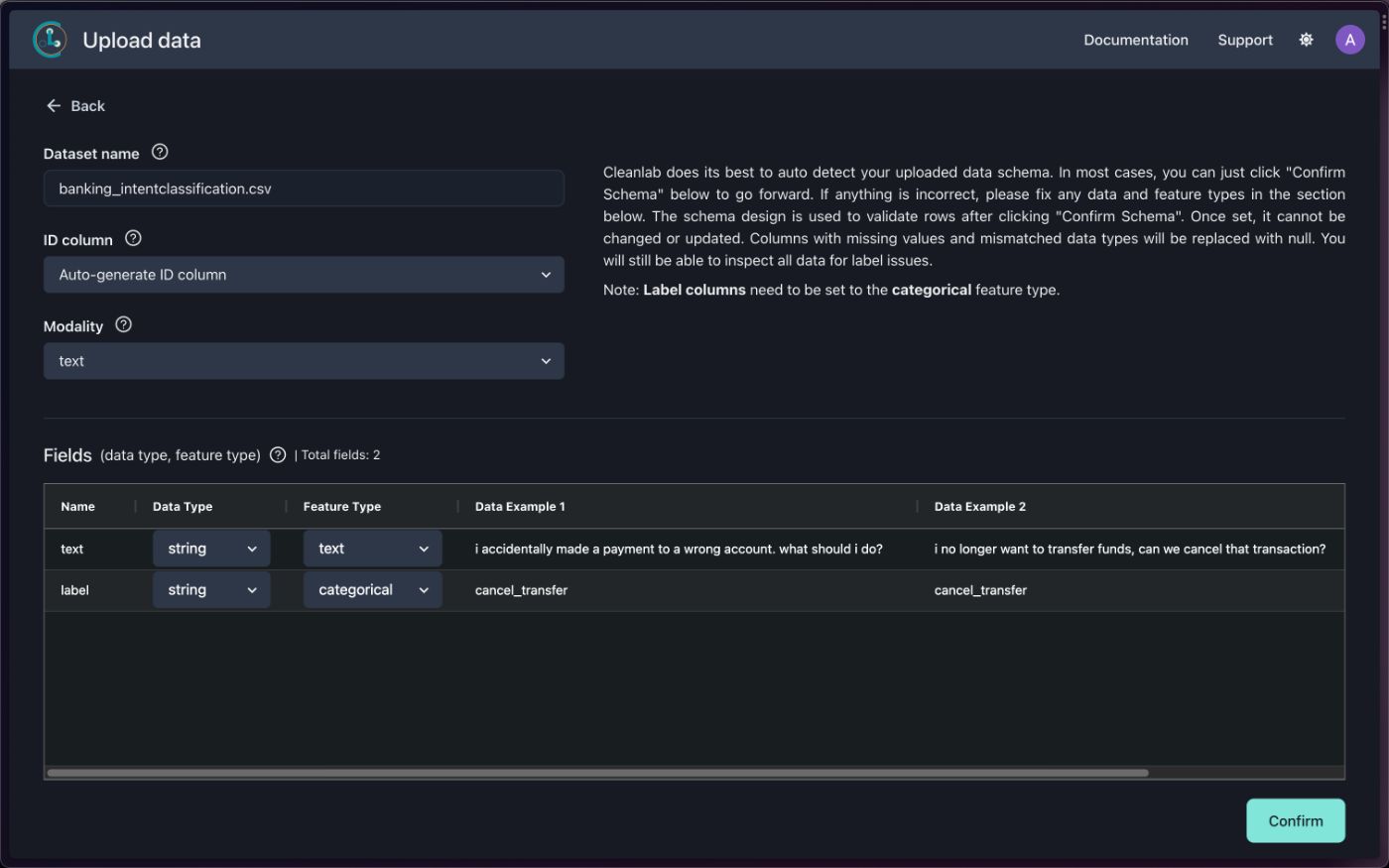
Как только вы подтвердите данные, вам будет показан экран с загруженным набором данных и связанными с ним ошибками (если таковые имеются!), возникшими при загрузке данных.
==Примечание. Загрузка некоторых наборов данных может занять несколько минут. Cleanlab сообщит вам по электронной почте, как только набор данных будет полностью загружен в Cleanlab Studio.==
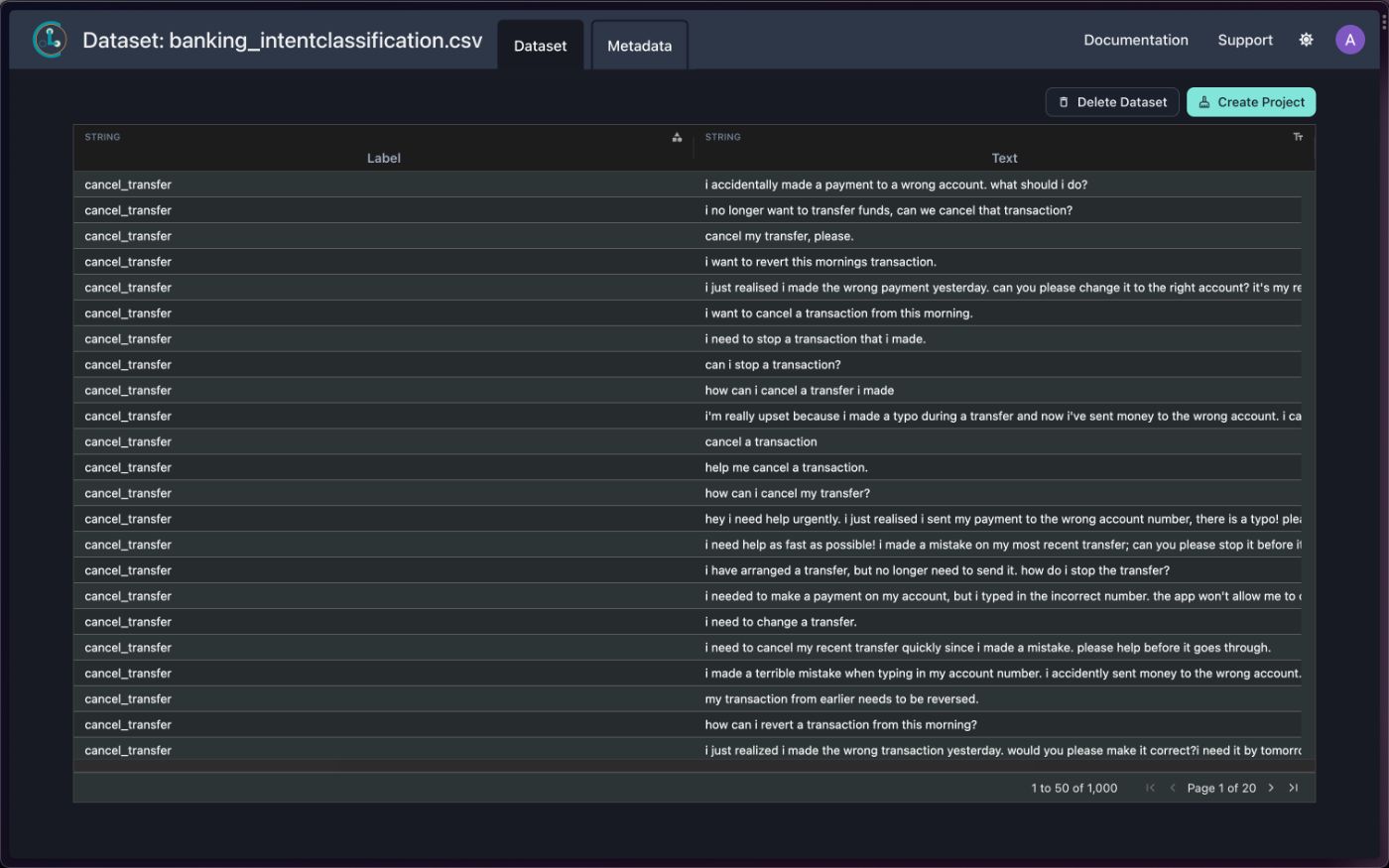
Шаг 3:
В зависимости от типа набора данных вы можете использовать конкретную задачу машинного обучения для выявления проблем с данными. В настоящее время Cleanlab Studio поддерживает несколько задач классификации машинного обучения, связанных с текстовыми, табличными и графическими данными.
В зависимости от классификации это может быть один из K классов или один из N из K классов. В этом наборе данных каждый запрос клиента относится к определенной категории. Это будет «мультиклассовая» классификация.
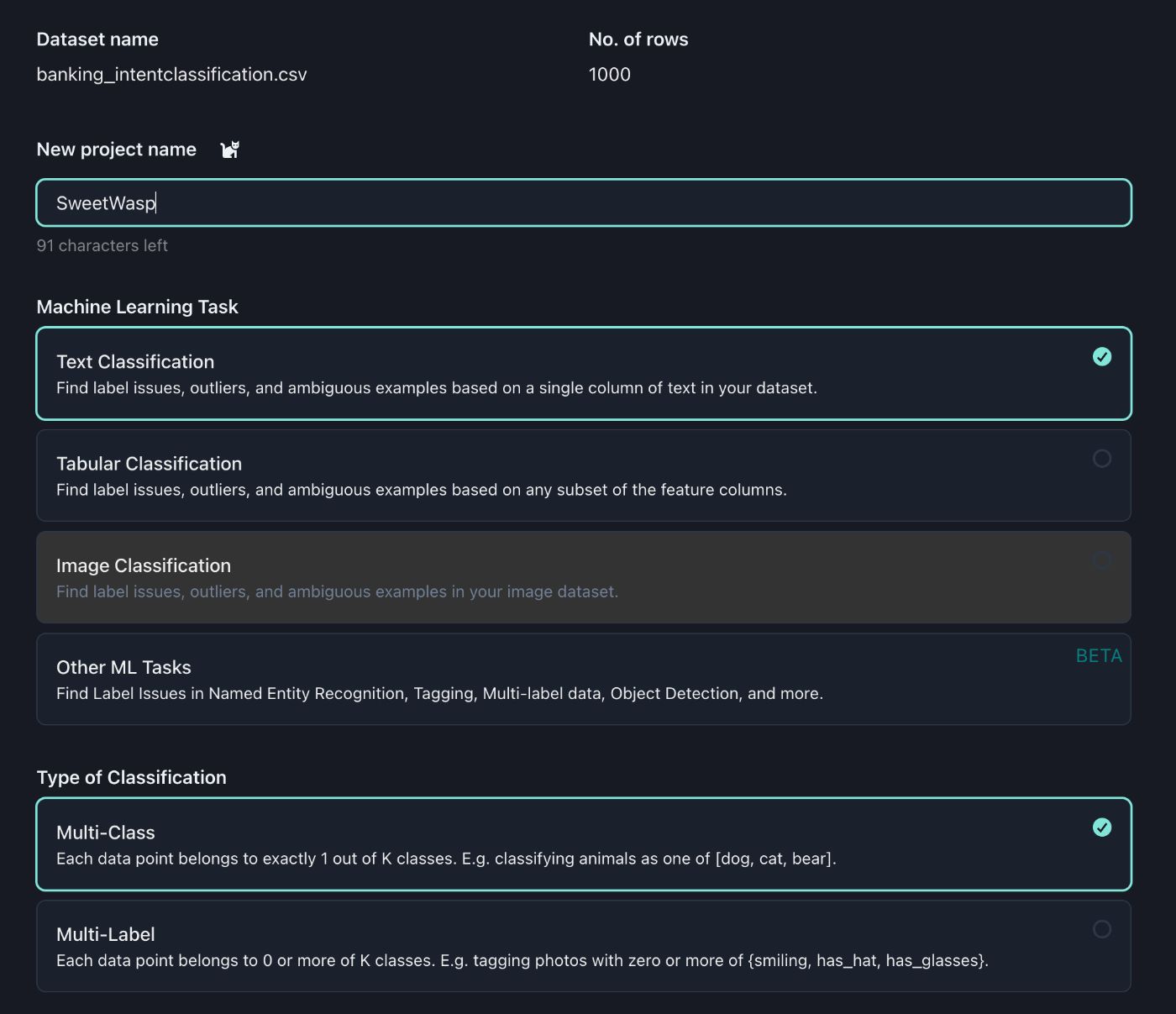
Студия Cleanlab автоматически определит выбранный столбец текста и меток. При необходимости вы можете это исправить.
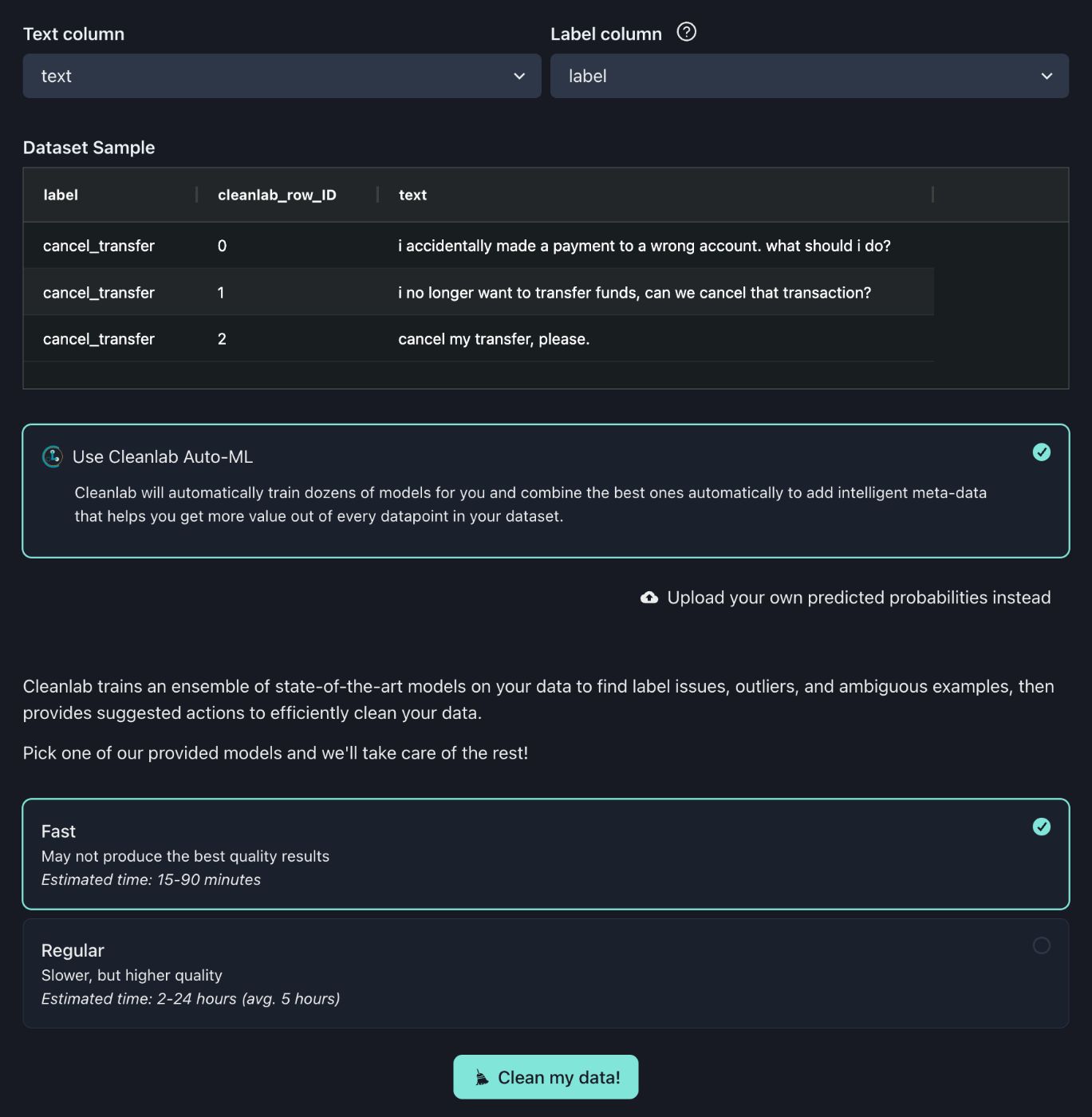
Использование быстрых моделей может не дать наилучших результатов; в интересах времени можно выбрать «Быстрый».
Нажмите «==Очистить мои данные!==»
Шаг 4:
Cleanlab Studio запускает набор моделей на основе набора данных и представляет обзор проблемы!
Как указывалось ранее, в наборе данных были неправильно классифицированы данные и выбросы, которые при анализе могли не повысить ценность общего процесса принятия решений.
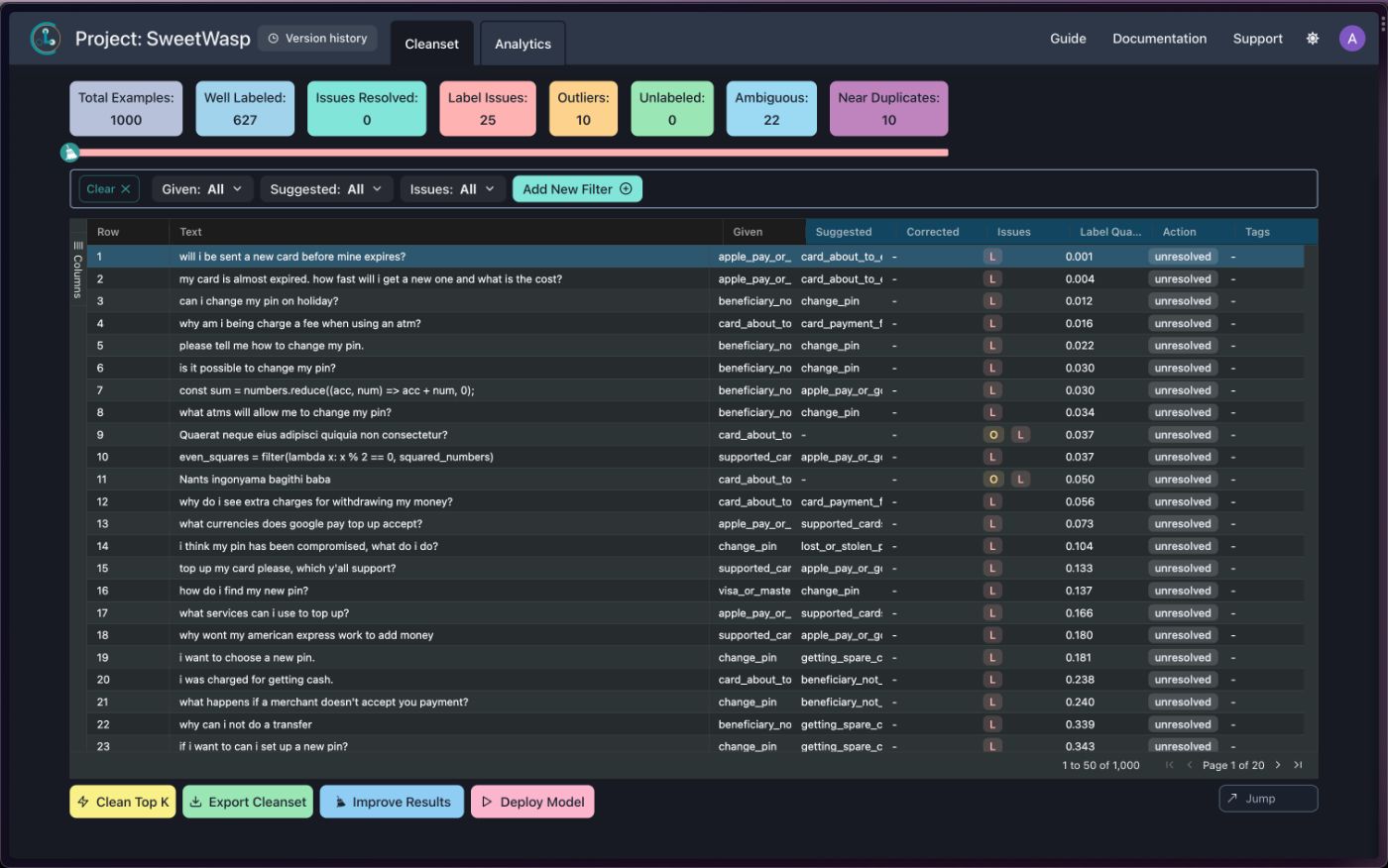
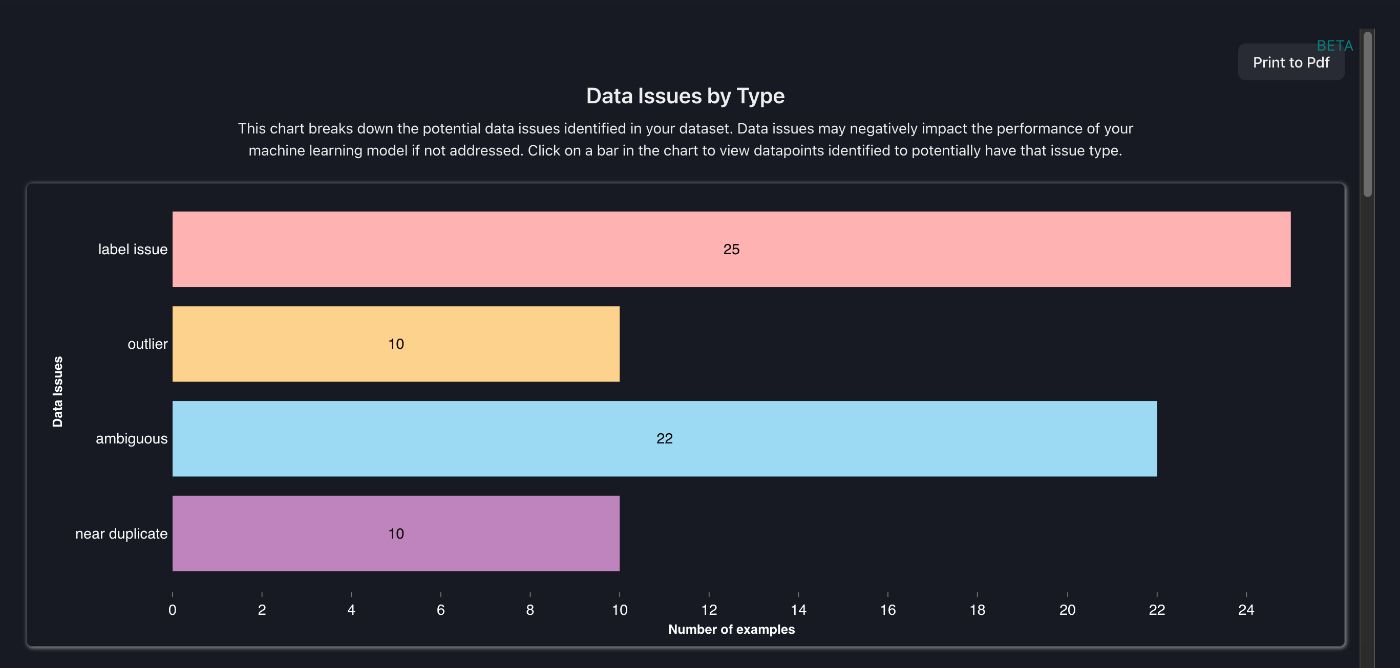
Вы также можете просмотреть метааналитику проблем, выявленных Cleanlab Studio в наборе данных, переключившись на аналитическое представление вверху.
Шаг 5:
Интересная часть Cleanlab Studio — это не просто экспорт очищенного набора данных, но и предоставление проблемно-ориентированного представления ваших данных. Отсутствующее средство подготовки данных, о котором аналитики данных и пользователи бизнес-аналитики мечтали уже много лет.
Вы можете отсортировать каждую проблему с помощью действий с помощью клавиатуры, предусмотренных в Cleanlab Studio, ИЛИ экспортировать «Экспорт набора очистки», нажав кнопку ниже.
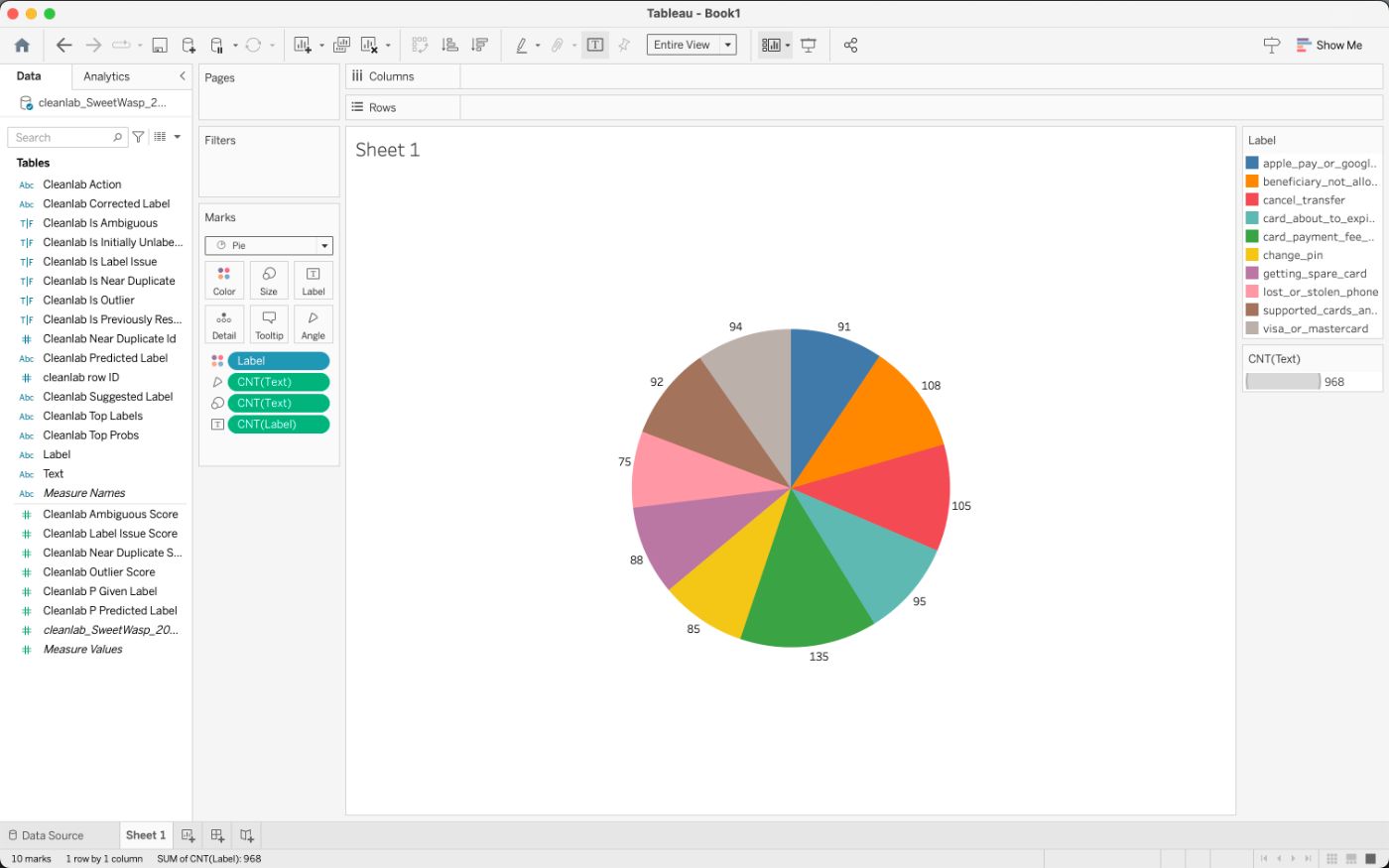
Анализ данных после подготовки данных с помощью искусственного интеллекта
Давайте рассмотрим тот же анализ данных с очищенным набором данных.
Похоже, что существуют расхождения в числах между категориями cancel_transfer и visa_or_mastercard. Хотя это небольшой набор данных, важно отметить, что такие исправления данных могут привести к существенно отличающимся оценкам и потенциальным бизнес-решениям в более крупном масштабе.
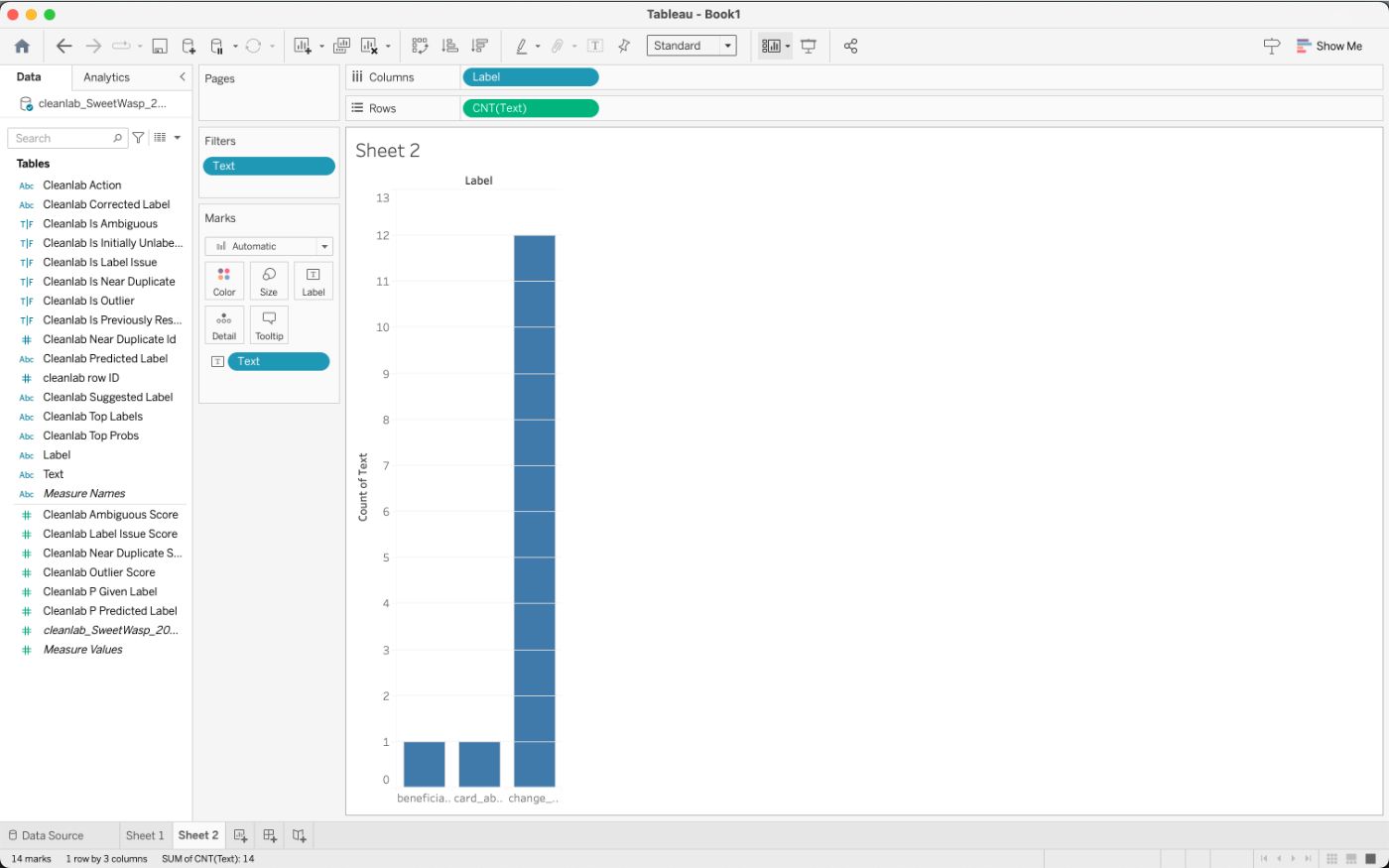
Аналогично, вы можете обнаружить, что запросы клиентов по некоторым категориям исчезают, если проблемы отмечены соответствующим образом.
Если вы аналитик данных или являетесь частью сообщества бизнес-аналитики, Cleanlab Studio может революционизировать ваш рабочий процесс подготовки данных. Попробуйте Cleanlab Studio сегодня и испытайте возможности очистки данных с помощью искусственного интеллекта для более надежного и точного анализа данных.
Заключение
Cleanlab Studio — это инструмент для подготовки данных без программирования, используемый тысячами инженеров, аналитиков и специалистов по обработке данных в компаниях из списка Fortune 500. Эта инновационная платформа была впервые использована в Массачусетском технологическом институте для обучения более надежных и точных моделей машинного обучения с использованием реальных ошибочных данных. Вы можете присоединиться к нашему сообществу Slack для получения дополнительной информации.
Оригинал