

Эффективные многоязычные токенизаторы для сутры: сокращение потребления токенов
26 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 Связанная работа
3 подход сутры
3.1 Что такое сутра?
3.2 Архитектура
3.3 Данные обучения
4 тренинги многоязычных токенизаторов
5 многоязычных MMLU
5.1 Массивное многозадачное понимание языка
5.2 Расширение MMLU на несколько языков и 5.3 последовательная производительность между языками
5.4 по сравнению с ведущими моделями для многоязычной производительности
6 Количественная оценка запросов в реальном времени
7 Обсуждение и заключение, а также ссылки
4 тренинги многоязычных токенизаторов
Токенизация, критический шаг в трубопроводе NLP, включает преобразование текста в последовательность токенов, где каждый токен представляет собой подвод или слово. Хотя английские специфические токенизаторы могут генерировать текст на неанглийских языках, они не отражают языковые нюансы, и они очень неэффективны на других языках, особенно на нереманизированных языках. Более конкретно для индийских языков, таких как хинди, гуджарати или тамильский, мы отмечаем, что токенизаторы от ведущих LLM, такие как Llama-2, Mistral и GPT-4, потребляют токены с 4,5 до 8 раз по сравнению с английским языком, как показано в таблице 4.
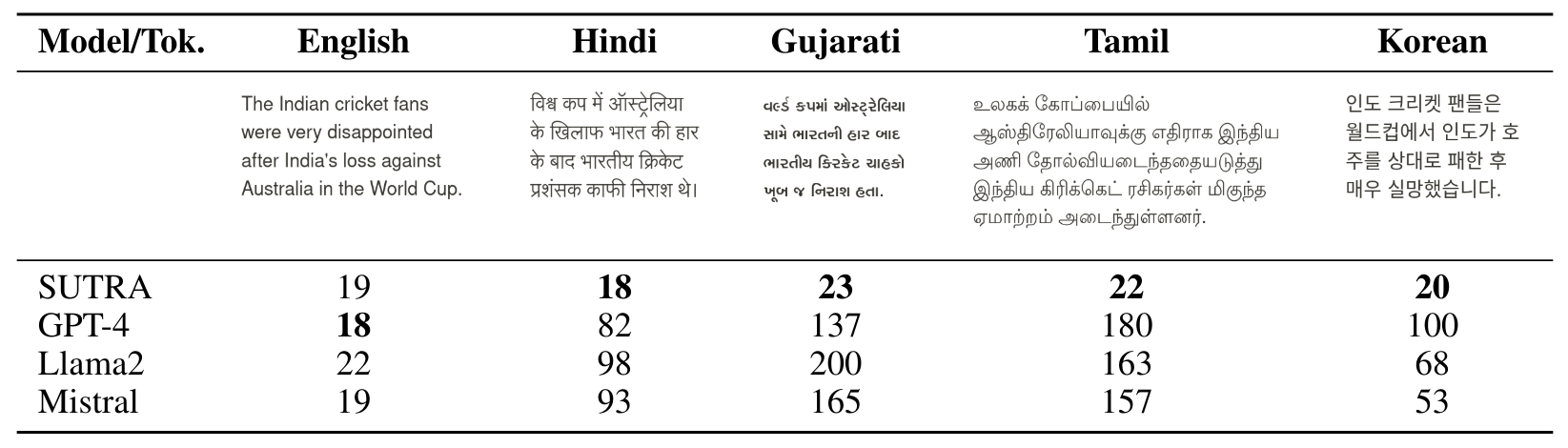
Ключевым шагом в добавлении языковых навыков является уменьшение среднего числа токенов, на которое разделено слово (также известное как плодородие токена) с помощью языковой модели на неанглийском тексте. Это делает вывод эффективным, а также семантически значимым. Мы тренируем токенизатор предметов предложения из большого корпуса многоязычного набора данных 500K+ документов, который затем объединяется с предварительно обученным английским токенизатором для увеличения размера словарного запаса. Текст, генерируемый нашими токенизаторами, приводит к снижению токенов, потребляемых на языках на 80% до 200%, что имеет решающее значение для снижения стоимости вывода при развертывании этих моделей для чувствительных к затратам.
Авторы:
(1) Абхиджит Бендейл, две платформы (abhijit@two.ai);
(2) Майкл Сапенза, две платформы (michael@two.ai);
(3) Стивен Рипплингер, две платформы (steven@two.ai);
(4) Саймон Гиббс, две платформы (simon@two.ai);
(5) Jaewon Lee, две платформы (jaewon@two.ai);
(6) Пранав Мистри, две платформы (pranav@two.ai).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)