

Эффективные микросервисы: использование возможностей сжатия данных при прямом межсервисном взаимодействии.
3 января 2024 г.:::совет В этой статье рассматриваются тонкости архитектуры микросервисов с особым акцентом на ее жизненно важный компонент - передачу данных в контексте беспрокси-подхода. . Мы исследуем нюансы, преимущества и проблемы применения этого метода, где прямое взаимодействие между сервисами играет ключевую роль. Обсуждение распространяется на то, как практики DevOps и правильный стратегический выбор могут существенно укрепить эту архитектуру. Кроме того, мы пройдемся по сфере Cloud-Native DevOps, изучая конкретные практики и инструменты, которые необходимы в облачных средах, на таких платформах, как AWS, . >Azure или Google Cloud. Целью данного исследования является пролить свет на то, как можно эффективно внедрить и оптимизировать архитектуру без прокси-серверов на различных облачных платформах.
:::
В современных облачных микросервисных архитектурах эффективный обмен данными имеет решающее значение, особенно потому, что мы часто работаем в средах, где используются традиционные прокси-серверы, такие как Nginx. не оптимальное решение. Эта необходимость возникает из-за различных факторов, приводящих к переходу к беспрокси-подходу в конкретных сценариях:
* Ограничения ресурсов. В средах с ограниченными вычислительными ресурсами накладные расходы прокси-серверов могут быть непомерно высокими. * Требования к высокой производительности. Прямая связь между службами может снизить задержку, что крайне важно для высокопроизводительных приложений. * Безопасность и соответствие. Определенные нормативные требования или требования безопасности могут диктовать прямые соединения между службами. * Упрощенная архитектура. Для некоторых приложений упрощенная настройка без дополнительных уровней прокси-сервера является более управляемой и эффективной. * Особые потребности в обработке данных: когда требуются уникальные методы обработки или сжатия данных, которые прокси-серверы не могут адекватно обеспечить.
Понимание вариантов использования подхода без прокси, особенно в контексте сжатия данных, становится важным для оптимизации эффективности и производительности микросервисов.
<блок-цитата>"Сжимать или не сжимать, вот в чем вопрос: благороднее ли в байтах страдать. Пинги и лаги возмутительных размеров файлов, Или ополчиться против моря передачи данных, А противодействуя, сжимайте их."
Проблемы передачи данных в сети.
Передача данных стала неотъемлемой частью повседневной жизни, сродни воздуху, которым мы дышим . Ее ценность по-настоящему ценится только тогда, когда ее не хватает. Как ИТ-специалисты, мы несем ответственность за этот «цифровой воздух», обеспечивая его чистоту и непрерывный поток. Мы должны сосредоточиться на поддержании качества и скорости передачи данных так же, как экологи борются за чистый воздух в городах. Наша задача выходит за рамки простого поддержания постоянного потока данных; мы также должны обеспечить его эффективность и безопасность в сложных сетевых экосистемах микросервисов. Являясь мостом, соединяющим точки архитектуры микросервисов, сеть также является сложной местностью, где данные сталкиваются с многочисленными препятствиями, которые могут повлиять на производительность, < Strong>эффективность и безопасность.
- ==Большие объемы данных==: Обмен большими объемами между микросервисами может привести к проблемам с производительностью и скоростью передачи данных.
- ==Задержка сети==: Задержки передачи данных могут повлиять на производительность системы в зависимости от расстояния между серверами и качества сети.
- ==Потеря данных==: всегда существует риск потери информации из-за сбоев сети или ошибок во время передачи данных.
- ==Затраты на передачу данных==: Лучшие сервисы, такие как AWS, Microsoft Azure, >GCP, IBM Cloud и т. д. предлагают модель ценообразования с оплатой по мере использования, при которой высокий уровень использования данных напрямую влияет на цену.
- ==Безопасность данных==. Сжатие данных не повышает безопасность данных. Однако это косвенно влияет на некоторые аспекты, связанные с безопасностью. Окно возможных атак также сокращается за счет сокращения времени передачи данных. Обработка распаковки требует дополнительных ресурсов, что усложняет задачу потенциальному злоумышленнику, пытающемуся проанализировать трафик данных.
- Передавайте меньше данных для экономии сетевого трафика.
- Время передачи данных может быть сокращено для ускорения общей работы системы.
- Эффективному обмену информацией способствует возможность одновременной передачи больших объемов данных. Чем более однородны данные, тем большее сжатие вы получите.
- Повысьте производительность системы в часы пик одновременных запросов.
- Повысьте эффективность использования сетевых ресурсов, что приведет к повышению эффективности.
- Необходимость обработки сжатых данных как на стороне клиента, так и на стороне сервера может привести к небольшому снижению производительности.
- Потеря данных во время сжатия и распаковки может произойти, если процесс настроен неправильно.
- Потенциальные проблемы совместимости данных при использовании разных алгоритмов сжатия.
- Для работы со сжатыми данными требуется дополнительная настройка.
- Требуются дополнительные знания в области отладки данных.
- service-db — это микросервис, имеющий доступ к DataBase *.
- service-mapper – это микросервис, не использующий базы данных, основная функция которого – сопоставление, обогащение и пересылка данных во внешние приложения.
- Проект: Gradle - Kotlin (или Maven, если хотите)
- Язык: Котлин.
- Ява: 21
- Spring Boot: последняя версия <ли>
- Артефакт: service-db/service-mapper <ли>
- Spring Data JPA (для сервисной базы данных)
- База данных H2 (для service-db)
- Spring Boot DevTools (необязательно для автоматической перезагрузки).
- db.microservice.url это URL-адрес микросервиса
- user.end.point — конечная точка для пользовательских операций.
- @Id и @jakarta.persistence.Id — аннотации используются для указания первичного ключа сущности.
- @GeneratedValue(strategy = GenerationType.IDENTITY) — аннотация указывает, что база данных автоматически генерирует уникальный идентификатор для каждого объекта в качестве первичного ключа.
- Входные данные преобразуются в строковый формат JSON с помощью ObjectMapper. Это сделано для представления данных в виде строки, которую затем можно сжать. Создается объект
- ByteArrayOutputStream, который будет использоваться для хранения сжатых данных.
- Создается объект GZIPOutputStream, который окружает ByteArrayOutputStream и предоставляет функциональные возможности для сжатия данных.
- Строка JSON преобразуется в массив байтов с использованием кодировки UTF-8.
- Массив байтов записывается в GZIPOutputStream. Во время этого процесса данные сжимаются и сохраняются в ByteArrayOutputStream.
- Результирующий сжатый массив байтов возвращается из функции.
- fun fetchDataCompressed(): этот метод использует RestTemplate для создания запроса GET к составному URL-адресу, который представляет собой комбинацию dbMicroServiceUrl и endPoint с добавленным к нему параметром /compressed. . Он ожидает ответа, содержащего сжатый массив ByteArray. Метод возвращает ResponseEntity
, включая сжатые данные и детали ответа HTTP. - fun decompress(compressedData: ByteArray): этот метод принимает сжатый ByteArray и выполняет распаковку. Он создает ByteArrayInputStream из сжатых данных, который затем упаковывается в GZIPInputStream, который используется для чтения и распаковки сжатого содержимого. Результатом является ByteArray исходных распакованных данных.
- fun ConvertToUserDto(decompressedData: ByteArray): после распаковки этот метод преобразует байты в список объектов UserDto. ObjectMapper считывает распакованные данные и сопоставляет их со списком объектов UserDto, используя параметризованный тип, предоставляемый TypeReference.
- Добавить CompressDataSnappyService:
- Добавьте функции в UserDecompressionService:
- Добавить в контроллер:
- Используйте массовый API для быстрого создания объектов в сервисной базе данных.
- Получить несжатые данные из service-db для эталонного сравнения.
- Получить сжатые данные из service-db.
- Убедитесь, что данные были получены правильно.
- Убедитесь, что данные успешно сжаты.
- Убедитесь, что после распаковки содержимое данных соответствует исходному набору данных.
- Измерьте время, необходимое для процессов сжатия и распаковки.
- Измерьте объем трафика, передаваемого между микросервисами.
- Добавьте искусственное время задержки, которое имитирует сценарии в реальном времени.
- Добавьте задержку 75/150/300 мс.
- Данные успешно сжимаются и распаковываются без потери информации.
- Сжатые данные занимают меньше места по сравнению с исходными данными.
- Время, необходимое для сжатия и распаковки, соответствует ожидаемому для данного объема данных.
- Трафик между сервисами снижается за счет сжатия данных.
- Используйте последовательную оценку.
- Запишите результаты теста в надежной среде.
- Тест считается успешным, если сжатые данные соответствуют оригиналу и имеют меньший размер.
- Командный сжатый поток ByteStream с помощью GZIP (localhost:8080/mapper/user/compressed): этот API имеет оптимизированный дизайн, позволяющий прорезать сеть как бритва. ожидается, что он возглавит группу. Он превосходит конкурентов, доставляя сжатые данные непосредственно из служебной базы данных, не тратя ресурсы ЦП на распаковку. Это наш пейс-кар, устанавливающий стандарты скорости и эффективности.
- Team Snappy Streamline (localhost:8080/mapper/user/compressed-snappy): если вам нужна чистая скорость за счет сжатия Snappy, этот гонщик не просто участвовать - он здесь, чтобы претендовать на трофей. Но нет! Если хотите, было бы справедливо предоставить энергичной команде собственный пейс-кар или маркер.
- Team Classic JSON (localhost:8080/mapper/user): почтенный ветеран, стойкий и надежный, привносящий в гонку вневременную простоту обычной передачи данных JSON. . Без наворотов сжатия или декомпрессии наш якорный объект - удерживает крепость с помощью Золотого стандарта передачи данных API.
- Team Gzip Glide (localhost:8080/mapper/user/decompressed): этот претендент использует тактичный подход, сжимая данные для путешествия, а затем разворачивая их по прибытии. с точностью gzip. Это сочетание традиций и инноваций, баланс между переносом и трансформацией.
- Team Snappy Stallion (localhost:8080/mapper/user/decompressed-snappy): действительно темная лошадка, с маневренностью и скоростью, обеспечиваемыми Google Быстрый алгоритм. Эта команда обещает по-новому взглянуть на сжатие, потенциально разрушая таблицу лидеров нетрадиционной тактикой.
- Ярлык: название протестированного тестового примера или запроса. <ли>
- Среднее: среднее время ответа всех запросов в миллисекундах. Он указывает на общую производительность системы.
- Медиана. Медианное время ответа – это среднее значение в наборе времен ответа. Это отличный показатель общей производительности, менее чувствительный к выбросам. Измеряется в миллисекундах.
- Линия 90%: Это означает, что 90% запросов выполняются быстрее, чем в этот раз. Этот показатель часто используется для измерения максимального времени ответа, с которым могут столкнуться клиенты. Измеряется в миллисекундах.
- Линия 95 % и 99 %: аналогично 90 %, но для 95 % и 99 % запросов соответственно. Эти метрики помогают нам понять, насколько хорошо система обрабатывает самые медленные запросы. Измеряется в миллисекундах.
- Мин. и макс.. Минимальное и максимальное время ответа во время теста. Измеряется в миллисекундах.
- Процент ошибок: процент ошибок во время теста.
- Пропускная способность. Пропускная способность измеряется в запросах в секунду. Он показывает, сколько запросов обрабатывается в среднем за единицу времени.
- Получено КБ/сек и отправлено КБ/сек: скорость получения и отправки данных в килобайтах в секунду.
- Процент сжатия. Чтобы рассчитать процент сжатия по формуле, вы можете использовать следующий подход:
- Gzip сжатие - 0,247 КБ.
- Быстро – 0,231 КБ.
- Чистый JSON – 0,230 КБ.
- Gzip сжатие - 1,06 КБ.
- Gzip — 1440 КБ.
- Чистый JSON – 7290 КБ.
- Gzip сжатие – 5030 КБ.
- Snappy – 9800 КБ.
- Чистый JSON – 72 560 КБ.
- Gzip сжатие – 37 440 КБ.
- Snappy – 92 170 КБ.
- Чистый JSON – 735 730 КБ.
- Очень низкая задержка: <20 мс.
- Низкая задержка: 20–50 мс.
- Умеренная задержка: 50–100 мс.
- Тестовый сценарий: 75 мс.
- Низкая задержка: 50–100 мс.
- Умеренная задержка: 100–200 мс.
- Тестовый сценарий: 150 мс.
- Умеренная задержка: 150–250 мс.
- Высокая задержка: 250–350 мс и более.
- Тестовый сценарий: 300 мс
- Определение формата данных. Если большая часть трафика состоит из JSON, XML или других текстовых форматов, могут быть эффективными стандартные алгоритмы, такие как Gzip, Brotli и Snappy. ли>
- НЕ СЖИМАЙТЕ ВСЕ. Тесты показывают, что такие API, как getOneEntityById, вообще не следует сжимать.
- Для разных значений данных могут потребоваться специализированные алгоритмы сжатия. Например, Gzip лучше подходит для больших наборов данных, но работает медленнее, чем Snappy.
- Внедрять данные. Например, непосредственно внутри сервисов, особенно для уникальных форматов данных, обеспечивая максимально эффективную обработку и минимальные изменения в существующей инфраструктуре.
- Используйте служебные классы или оболочки классов, чтобы избежать шаблонного шаблона.
- Тестирование производительности. Убедитесь, что сжатие действительно повышает производительность, не вызывая чрезмерной нагрузки на процессор.
- Мониторинг и настройка. Продолжайте мониторинг, чтобы оптимизировать правила сжатия, гарантируя, что они применяются только там, где это необходимо и эффективно.
:::совет Примечание. Понимание этих проблем имеет решающее значение для определения решений и стратегий, которые можно использовать для их преодоления, включая решающую роль, которую сжатие данных играет в этом уравнении.
:::
Понимание сжатия данных.

Что такое сжатие данных?
Сжатие данных – это метод уменьшения размера данных с целью экономии места для хранения или времени передачи. Для микросервисов это означает, что когда один сервис отправляет данные другому, вместо отправки необработанных данных он сначала сжимает данные, отправляет сжатые данные по сети, а затем принимающий сервис распаковывает их обратно в исходный формат. Это будет рабочий сценарий, на котором мы сосредоточимся.
Обсуждение значения и ограничений сжатия данных в архитектурах микросервисов
Сжатие данных уменьшает размер данных, что приводит к более быстрой передаче и повышению производительности. Однако это может привести к потере данных, несоответствию формата и проблемам с производительностью.
Преимущества использования сжатия данных:
Недостатки использования сжатия данных:
:::совет Примечание. В этой статье будут рассмотрены некоторые из этих проблем, чтобы обеспечить надежный и эффективный обмен данными между микросервисами.
:::
Типы алгоритмов сжатия данных.

При рассмотрении обмена данными между микросервисами выбор подходящего алгоритма сжатия данных имеет решающее значение для обеспечения эффективности и производительности. Давайте углубимся в наиболее распространенные типы алгоритмов сжатия данных.
| ==Алгоритмы сжатия без потерь:== | ==Алгоритмы сжатия с потерями:== | |----|----| | Эти алгоритмы сжимают данные, позволяя идеально восстановить исходные данные из сжатых данных. | Эти алгоритмы сжимают данные, удаляя ненужную или менее важную информацию, а это означает, что исходные данные не могут быть полностью восстановлены из сжатых данных. | | Примеры включают кодирование Хаффмана, Lempel-Ziv (LZ77 и LZ78) и Deflate, которые также используются в GZIP. | Примеры, обычно используемые при сжатии аудио и видео, включают JPEG для изображений и MP3 и AAC для аудио. | | Еще одним ярким примером является Snappy, который отдает приоритет скорости и эффективности, что делает его подходящим выбором для сценариев, где быстрое сжатие и распаковка данных более важно, чем достижение максимального уровня сжатия. | |
Преимущества использования алгоритмов сжатия без потерь при взаимодействии микросервисов.
Окончательный выбор зависит от конкретных потребностей проекта и характеристик данных, которыми обмениваются микросервисы.
GZIP — оптимальный выбор в качестве программного обеспечения для сжатия и распаковки данных для наших целей. Он использует алгоритм «Deflate», сочетающий в себе алгоритм LZ77 и кодирование Хаффмана. Поскольку алгоритм «Deflate» является «Алгоритмом сжатия данных без потерь», исходные данные могут быть идеально восстановлены из сжатых данных. Каждый в бизнесе хочет получать точные данные и избегать ошибок.
:::информация Вердикт: Gzip универсален и практичен, поэтому он широко используется для сжатия текстовых файлов и признан как алгоритмом сжатия без потерь, так и инструментом сжатия текста.
:::
Приступаем к действию: развертывание архитектуры микросервисов.
:::предупреждение Вы можете пропустить раздел «Создание микросервиса» и сразу перейти к тестовым примерам или сводной части.
:::
Теперь, когда мы изучили основные понятия, пришло время приступить к творчеству.
Мы рассмотрим два регулярных звена в сложной сети микросервисных архитектур, где сотни взаимосвязанных сервисов сплетают сложную сеть. Эти два изолированных от обширной экосистемы отдельных микросервиса будут служить в качестве наших координаторов, позволяя нам анализировать и глубоко понимать конкретный исследовательский случай.
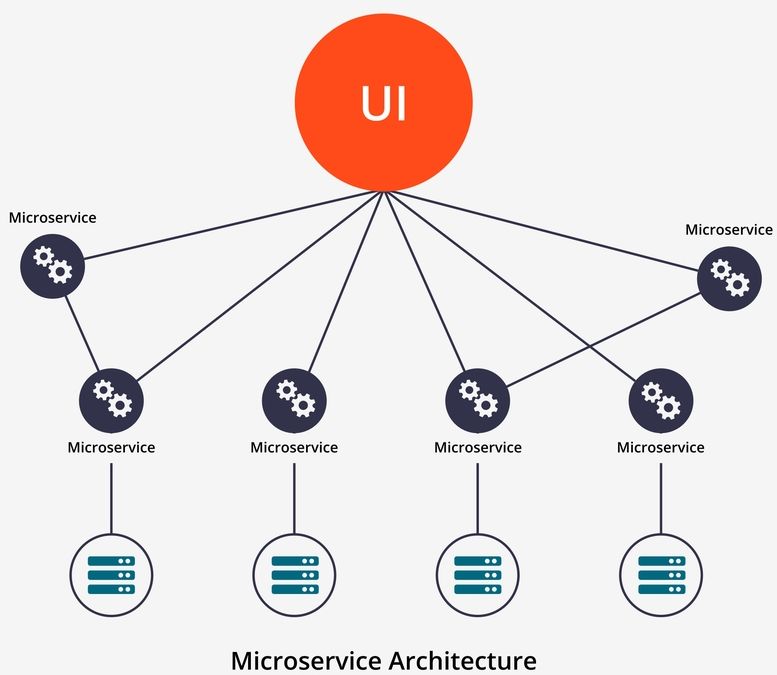
Как уже упоминалось, мы создаем два независимых микросервиса Spring Boot Kotlin:
:::совет Подсказка: для нашего учебного примера в качестве базы данных Java SQL была выбрана база данных Data BaseH2. Уникальная особенность H2 заключается в том, что он существует только во время работы приложения и не требует отдельной установки. Это легкий, быстрый и удобный вариант для целей разработки и тестирования. Обратите внимание, что все данные базы данных будут удалены при перезапуске приложения, поскольку они являются временными.
:::
Быстрое создание структуры проекта
Для создания коротких проектов используйте утилиту start.spring.io. Начнем.
Метаданные проекта:
<ли>Группа: com.compression
Имя: service-db / service-mapper
<ли>Зависимости:
<ли>Spring Web (оба)
:::совет Подсказка: важно внимательно следить за своими зависимостями и устанавливать только то, что необходимо для ваших нужд.
:::
Я уже сделал для вас две конфигурации: ==service-db== / ==service-mapper= =
Загрузите проекты и разархивируйте их.
Конфигурация в проекте.
Когда вам удастся разархивировать и индексировать файлы, вам следует добавить код в файлы application.properties.
По умолчанию нам необходимо настроить параметры источника данных в service-db.
# DataSource Configuration
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
# JPA/Hibernate Configuration
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
# H2 Database Console Configuration
spring.h2.console.enabled=true
# Server Configuration
server.port=8081
server.servlet.context-path=/db
application.properties в сервис-сопоставителе:
# Server Configuration
server.port=8080
server.servlet.context-path=/mapper
# Microservice Configuration
db.microservice.url=http://localhost:8081/db/
user.end.point=user
:::совет Подсказка: Эти переменные используются для подключения к микросервису service-db:
:::
Процесс разработки и проектирование решения: построение потока данных.
Наш проект будет следовать определенной стандартной структуре.
src
└── main
└── kotlin
└── com
└── example
└── myproject
├── config
│ └── AppConfig.kt
├── controller
│ └── MyController.kt
├── repository
│ └── MyRepository.kt
├── service
│ └── MyService.kt
├── dto
│ └── MyUserDto.kt
└── entity
└── MyEntity.kt
В нашем курсе мы будем реализовывать следующие пункты:
| ==реализация сервисной базы данных== | ==реализация сервис-сопоставителя== | |----|----| | Пользовательская сущность. | Пользовательский DTO. | | Сервис для сжатия данных. | Служба декомпрессии - Логика декомпрессии данных. | | Put/GET Контроллеры для сохранения/получения объекта в/из базы данных. | GET Контроллер — получение необработанных/сжатых данных из service-db. |
Давайте напишем
Подобно тому, как я делаю набросок чертежа перед постройкой ракеты, мы начинаем кодирование с формирования DTO/Entity в качестве первого шага.
класс данных UserEntity в service-db и UserDto в service-mapper:
# service-db
@Entity
data class UserEntity(
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Id
@jakarta.persistence.Id
val id: Long,
val name: String,
val creativeDateTime: LocalDateTime? = LocalDateTime.now(),
)
# service-mapper
data class UserDto(
val id: Long,
val name: String,
val creativeDateTime: LocalDateTime,
)
:::совет ПРИМЕЧАНИЕ. Для service-db в нашем проекте мы будем использовать следующие декораторы в Entity для обработки уникальной идентификации каждого объекта. Используя эти аннотации, база данных будет автоматически управлять назначением уникальных идентификаторов при создании новых объектов, упрощая процесс управления объектами.
:::
Service-db: репозиторий и контроллер.
Давайте переключим внимание на сервисную базу данных и создадим классический дуэт, включающий Репозиторий и Контроллер.
package com.compress.servicedb.repository
@Repository
interface UserRepository : CrudRepository<UserDto, Long>
@RestController
@RequestMapping("/user")
class EntityController(
private val repository: UserRepository
) {
@GetMapping
fun getAll(): MutableIterable<UserDto> = repository.findAll()
@PostMapping
fun create(@RequestBody user: UserDto) = repository.save(user)
@PostMapping("/bulk")
fun createBulk(@RequestBody users: List<UserDto>): MutableIterable<UserDto> = repository.saveAll(users)
}
Проверьте с помощью Почтальона, все ли ясно, и соответственно выполните следующие шаги.
POST: localhost:8081/db/user/bulk
POST: localhost:8081/db/user/
GET: localhost:8081/db/user
:::совет ПРИМЕЧАНИЕ. Нам необходимо убедиться, что наши службы настроены и эффективно взаимодействуют. Наш текущий метод получения данных из сервисной базы данных является элементарным, но служит нашим первым тестом. Как только у нас будет достаточно данных, мы сможем измерить объем и скорость поиска, чтобы установить базовый уровень для будущих сравнений.
:::
Сопоставитель сервисов: сервис и контроллер.
Давайте перейдем к service-mapper и создадим Контроллер и Сервис.
Услуга:
package com.compress.servicemapper.service
@Service
class UserService(
val restTemplate: RestTemplate,
@Value("${db.microservice.url}") val dbMicroServiceUrl: String,
@Value("${user.end.point}") val endPoint: String
) {
fun fetchData(): List<UserDto> {
val responseType = object : ParameterizedTypeReference<List<UserDto>>() {}
return restTemplate.exchange("$dbMicroServiceUrl/$endPoint", HttpMethod.GET, null, responseType).body ?: emptyList()
}
}
Контроллер:
package com.compress.servicemapper.controller
@RestController
@RequestMapping("/user")
class DataMapperController(
val userTransformService: UserService
) {
@GetMapping
fun getAll(): ResponseEntity<List<UserDto>> {
val originalData = userTransformService.fetchData()
return ResponseEntity.ok(originalData)
}
}
Конфигурация RestTemplate:
В сопоставителе сервисов мы настраиваем RestTemplate для облегчения взаимодействия между различными частями нашего приложения. Это делается путем создания класса конфигурации с аннотацией @Configuration, содержащего определение компонента для нашего RestTemplate.
Вот код:
@Configuration
class RestTemplateConfig {
@Bean
fun restTemplate(): RestTemplate {
return RestTemplateBuilder().build()
}
}
@Configuration — это аннотация Spring, указывающая, что класс имеет определения @Bean. Компоненты — это объекты, которыми управляет контейнер Spring IoC (Inversion of Control). В данном случае наш bean-компонент RestTemplate определен в классе RestTemplateConfig.
Аннотация @Bean в Spring идентифицирует метод, создающий компонент для контейнера Spring. В нашем примере метод restTemplate создает новый экземпляр RestTemplate, используемый для операций HTTP в Spring. Эта конфигурация позволяет один раз определить RestTemplate и внедрить его в необходимые компоненты, что делает ваш код более чистым и простым в обслуживании.
Без этой конфигурации вы все равно можете использовать RestTemplate, но вам нужно будет создавать его экземпляр в каждом месте, где вы его используете. Это может привести к дублированию кода.
Почтальон готов начать. Убедитесь, что вы создали несколько пользователей в service-db. В результате вы получите тех же пользователей в service-db.
localhost:8080/mapper/user
Ограничение сжатия.
Пришло время реализовать сжатие в сервисной базе данных. Сердцем нашего сжатия будет CompressDataService. Взгляните на код:
@Service
class CompressDataService(
private val objectMapper: ObjectMapper
) {
fun compress(data: Iterable<UserEntity>): ByteArray {
val jsonString = objectMapper.writeValueAsString(data)
val byteArrayOutputStream = ByteArrayOutputStream()
GZIPOutputStream(byteArrayOutputStream).use { gzipOutputStream ->
val bytes = jsonString.toByteArray(StandardCharsets.UTF_8)
gzipOutputStream.write(bytes)
}
return byteArrayOutputStream.toByteArray()
}
}
Пошаговое объяснение:
Функция сжатия принимает коллекцию объектов UserEntity в качестве входных данных и возвращает байтовый массив. Основная цель этой функции — сжать данные для экономии места во время передачи или хранилище. Вот что происходит внутри функции:
Таким образом, функция сжатия преобразует набор объектов в сжатый байтовый массив, экономя место при передаче или хранении данных.
Контроллер настолько банален, что не нуждается в комментариях.
@RestController
@RequestMapping("/user")
class CompressedDataController(
private val repository: UserRepository,
private val compressDataService: CompressDataService,
) {
@GetMapping("/compressed")
fun fetchCompressedData(): ByteArray {
val data: Iterable<UserDto> = repository.findAll()
return compressDataService.compress(data)
}
}
Проверьте себя, пожалуйста. Вы получите что-то особенное. Если вы молодой подающий надежды инженер, возможно, вы впервые увидите такой ответ. Это ByteArray, детка.
GET: localhost:8081/db/user/compressed
:::информация Проверьте звук: Объем передачи данных на этом этапе значительно ниже. По мере роста объема данных аналогичного типа эффективность сжатия увеличивается, что приводит к повышению степени сжатия.
:::
Реализация декомпрессии.
Пришло время распаковать наши данные в сопоставителе сервисов. Для этого мы создадим новый контроллер и сердце этого микросервиса: сервис распаковки. Давайте откроем наши сердца.
import java.io.ByteArrayInputStream
import java.util.zip.GZIPInputStream
@Service
class UserDecompressionService(
@Value("${db.microservice.url}") val dbMicroServiceUrl: String,
@Value("${user.end.point}") val endPoint: String,
val restTemplate: RestTemplate,
private var objectMapper: ObjectMapper
) {
fun fetchDataCompressed(): ResponseEntity<ByteArray> {
return restTemplate.getForEntity("$dbMicroServiceUrl$endPoint/compressed", ByteArray::class.java)
}
fun decompress(compressedData: ByteArray): ByteArray {
ByteArrayInputStream(compressedData).use { bis ->
GZIPInputStream(bis).use { gzip ->
return gzip.readBytes()
}
}
}
fun convertToUserDto(decompressedData: ByteArray): List<UserDto> {
return objectMapper.readValue(decompressedData, object : TypeReference<List<UserDto>>() {})
}
Пошаговое объяснение.
Вместе эти методы создают рабочий процесс внутри службы для извлечения сжатых пользовательских данных из микросервиса, их распаковки и преобразования в список объектов UserDto, которые можно использовать в другом месте. в приложении. Это позволяет другим приложениям использовать эту службу для получения пользовательских данных в удобном формате, абстрагируя при этом детали поиска и преобразования данных.
Контроллер: добавьте эту функцию. Здесь мы видим то, что описано выше в сервисе.
@GetMapping("/decompress")
fun transformData(): ResponseEntity<List<UserDto>> {
val compressedData = userDecompressionService.fetchDataCompressed()
return try {
val decompressedData = userDecompressionService.decompress(compressedData.body!!)
val users = userDecompressionService.convertToUserDto(decompressedData)
ResponseEntity.ok(users)
} catch (e: Exception) {
ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).build()
}
Пожалуйста, проверьте с помощью Postman, что все в порядке ==200 OK==. Вы должны получать распакованные данные один к одному, например, из service-db.
localhost:8080/mapper/user/decompress
Мы добились значительного прогресса в разработке двух наших микросервисов и сейчас находимся на важной вехе, похожей на переход Рубикона. Наши первоначальные усилия привели нас к созданию проекта всемирно известного приложения. Этот шаблон лежит в основе преобразующих платформ, таких как потоковый сервис Netflix и экосистема электронной коммерции Amazon. Эти платформы используют надежные облачные системы для предоставления бесперебойных, масштабируемых и отказоустойчивых услуг по всему миру.
Снэппи, прыгай на подножку.
Для нашего теста у нас есть широкий выбор алгоритмов сжатия, и было бы полезно добавить еще одного актера. Как упоминалось ранее, Snappy Compression утверждает, что иногда оно может быть более эффективным, и мы планируем проверить эту теорию. Как?
Добавляем в Gradle зависимости в двух микросервисах:
реализация ("org.xerial.snappy:snappy-java:1.1.10.5")
Служебная база данных:
class CompressDataSnappyService(
private val objectMapper: ObjectMapper
) {
fun compressSnappy(data: Iterable<UserEntity>): ByteArray {
val jsonString = objectMapper.writeValueAsString(data)
return Snappy.compress(jsonString.toByteArray(StandardCharsets.UTF_8))
}
2. Контроллер:
@RestController
@RequestMapping("/user")
class UserCompressedSnappyController(
private val repository: UserRepository,
private val compressDataService: CompressDataSnappyService,
) {
@GetMapping("/compressed-snappy")
fun fetchCompressedData(): ByteArray {
val data: Iterable<UserEntity> = repository.findAll()
return compressDataService.compressSnappy(data)
}
}
Сопоставление сервисов:
fun decompressSnappy(compressedData: ByteArray): ByteArray {
return Snappy.uncompress(compressedData)
}
fun fetchDataCompressedSnappy(): ResponseEntity<ByteArray> {
return restTemplate.getForEntity("$dbMicroServiceUrl$endPoint/compressed-snappy", ByteArray::class.java)
}
@GetMapping("/decompressed-snappy")
fun transformDataSnappy(): ResponseEntity<List<UserDto>> {
val compressedData = userDecompressionService.fetchDataCompressedSnappy()
return try {
val decompressedData = userDecompressionService.decompressSnappy(compressedData.body!!)
val users = userDecompressionService.convertToUserDto(decompressedData)
ResponseEntity.ok(users)
} catch (e: Exception) {
ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).build()
}
}
Исходный ==service-db== / ==service-mapper== можно скачать с ==GitHub== ==.==
Тестовые примеры: байтовый отпечаток до & После

Позвольте мне представить мои сценарии тестирования и мое видение возможности использования этого подхода во всем мире.
Сжатие данных — это не просто магия программирования; это искусство и наука, которые позволяют нам достигать большего с меньшими затратами. Но как мы можем измерить истинное величие этого вида искусства? Как мы можем гарантировать, что наши методы работают и работают хорошо?
Введите понятие «Базовое сравнение» или «Эталонное сравнение». Проще говоря, мы создаем отправную точку - базовую линию - наши несжатые данные во всем их первоначальном, неотредактированном великолепии. Это состояние необработанных данных станет нашей отправной точкой для сравнения и оценки.
Шаги:
-
<ли>
Подготовка данных:
<ли>Создайте данные для четырех сценариев: ==1/100/1000/10000== пользователей.
<сильный>2. Передача данных:
<сильный>3. Проверка результатов:
<сильный>4. Тестирование в реальной жизни:
Ожидаемые результаты:
Постусловия:
Критерии успеха:
Тестовая среда.
В нашей демонстрации мы будем использовать ==Apache JMete====r== , надежный инструмент тестирования, позволяющий моделировать взаимодействие микросервисов и измерять преимущества сжатия данных. JMeter идеально подходит для таких целей, поскольку он может моделировать нагрузки и тестировать производительность сервисов. У него есть документация, множество плагинов и отличная поддержка. Мы стремимся продемонстрировать, как сжатие данных оптимизирует трафик и эффективность связи между сервисами.
Во всех случаях мы будем использовать загрузчик производительности, поскольку каждый из 1000 пользователей создаст один запрос. Равно 1000 запросов на получение 1/100/1000/10000 пользователей.
Это даст нам большое поле для статистических данных и позволит протестировать наше приложение на производительность.
Начнем гонку

По мере того как мы приближаемся к трассе тестирования, наши соперники выстраиваются в очередь, двигатели набирают обороты, каждый из которых представляет уникальный подход к передаче данных в Гран-при производительности микросервисов. Давайте представим наши команды Формулы-1:
Каждый API, представляющий собой уникальную формулу технического мастерства, готов выйти на трассу, доказав свой характер. Пока флаг развевается, следите внимательно: в этой гонке речь идет не только о чистой скорости , но и о стратегии, управлении ресурсами и выносливости на облачной арене, где на счету каждая миллисекунда.
Что мы измеряем:
Примеры: количество запросов, выполненных в ходе теста. Из таблицы результатов я исключаю данные о 1000 пробах, так как они постоянны.
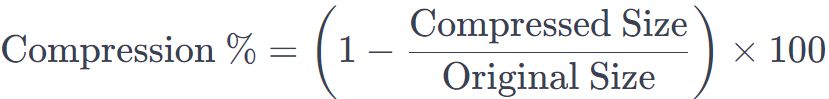
Результат показывает процентное уменьшение размера из-за сжатия.
Основная цель.
Что касается наиболее показательных процентилей (% Line), то внимание обычно уделяется 99% процентилям, поскольку они отражают время ответа на самые медленные запросы. Эти значения помогают определить, соответствуют ли характеристики производительности системы требованиям к производительности и насколько устойчива система при высоких нагрузках.
Константы во время теста.
==Затраты на одного== пользователя:
==100== Стоимость пользователей:
==1.000== Стоимость пользователей:
==10.000== затраты пользователя:
3…2…1…ДАВАЙ!

Гонка №1 - В идеальном мире.
Первая гонка будет проходить в лабораторных условиях - оба микросервиса работают на одном процессоре через разные порты. Это симуляция Условий нулевой задержки. Я верю, что однажды мы достигнем бесшовного потока данных, но пока человечество работает над этим, у нас всегда будет работа по оптимизации.
Итак, четыре этапа и получение 1/100/1000/10000 пользователей.
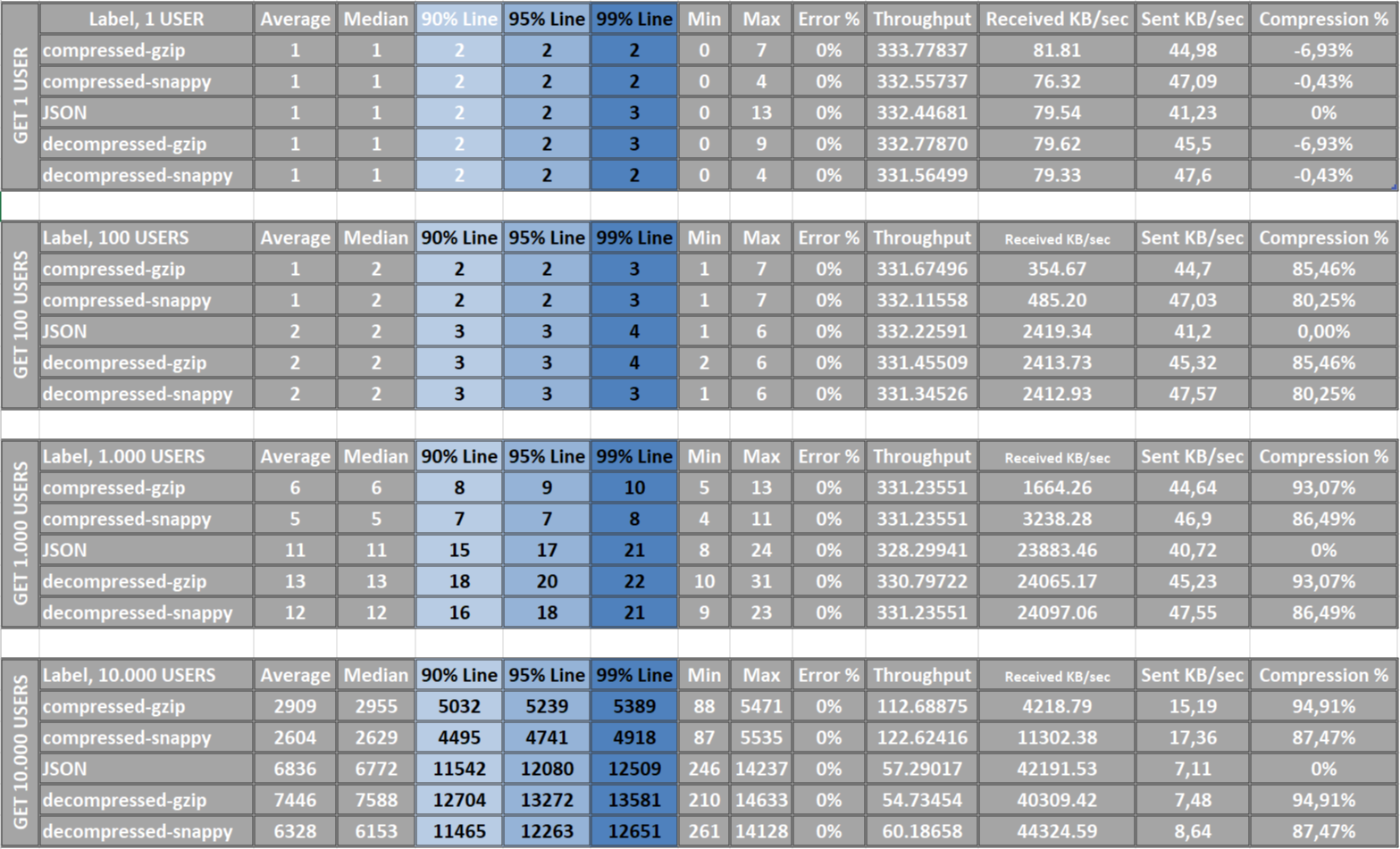
:::информация Чистые сжатые данные не учитываются; вместо этого мы наблюдаем за ним, чтобы определить свое местоположение.
Примечание. Все таблицы в формате CSV можно загрузить с помощью эта общедоступная ссылка.
:::
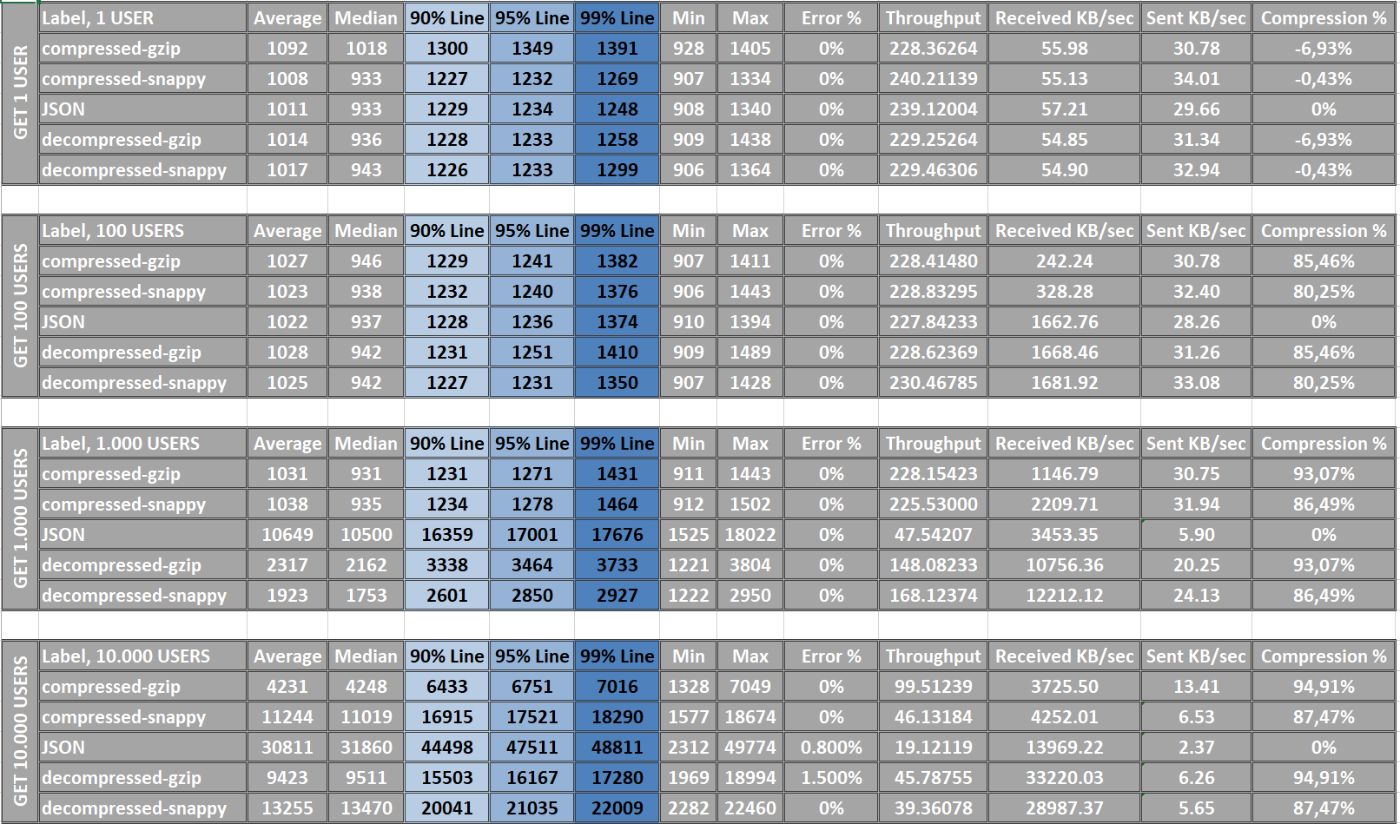
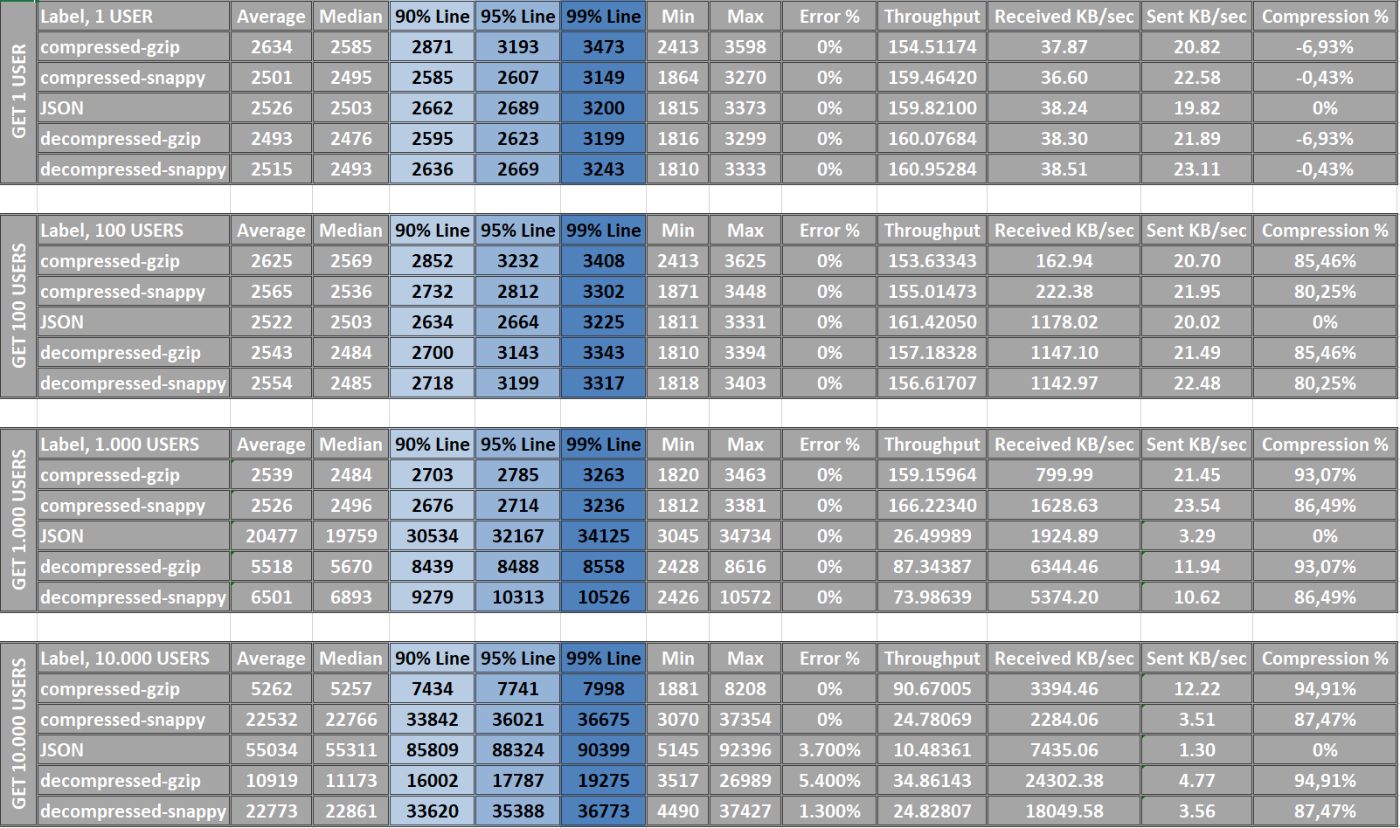
Итог: В ходе нашего анализа мы заметили, что наша система может треснуть как орешки 1, 100 и 1000 пользователей, но начинают возникать задержки, когда мы увеличиваем нагрузку до strong>10 000 пользователей. Вот почему мы должны использовать постраничные запросы. JSON — самый быстрый формат ответа, но другие команды быстро его догоняют. Синтетическая победа достаётся JSON/Snappy. Однако наиболее важным фактором является не обязательно скорость, а сколько трафика мы можем сэкономить. Победитель в этом отношении может оказаться иным, чем мы думали изначально.
Еще один важный вывод: для небольших запросов, таких как получение только одного пользователя, мы наблюдаем отрицательную степень сжатия. Это означает, что использование сжатия не дает никаких преимуществ, поскольку данные становятся более объемными и требуют больше вычислительной мощности для сжатия и распаковки. Поэтому важно всегда помнить об этом случае и проводить тщательное тестирование, чтобы обеспечить оптимальную производительность.
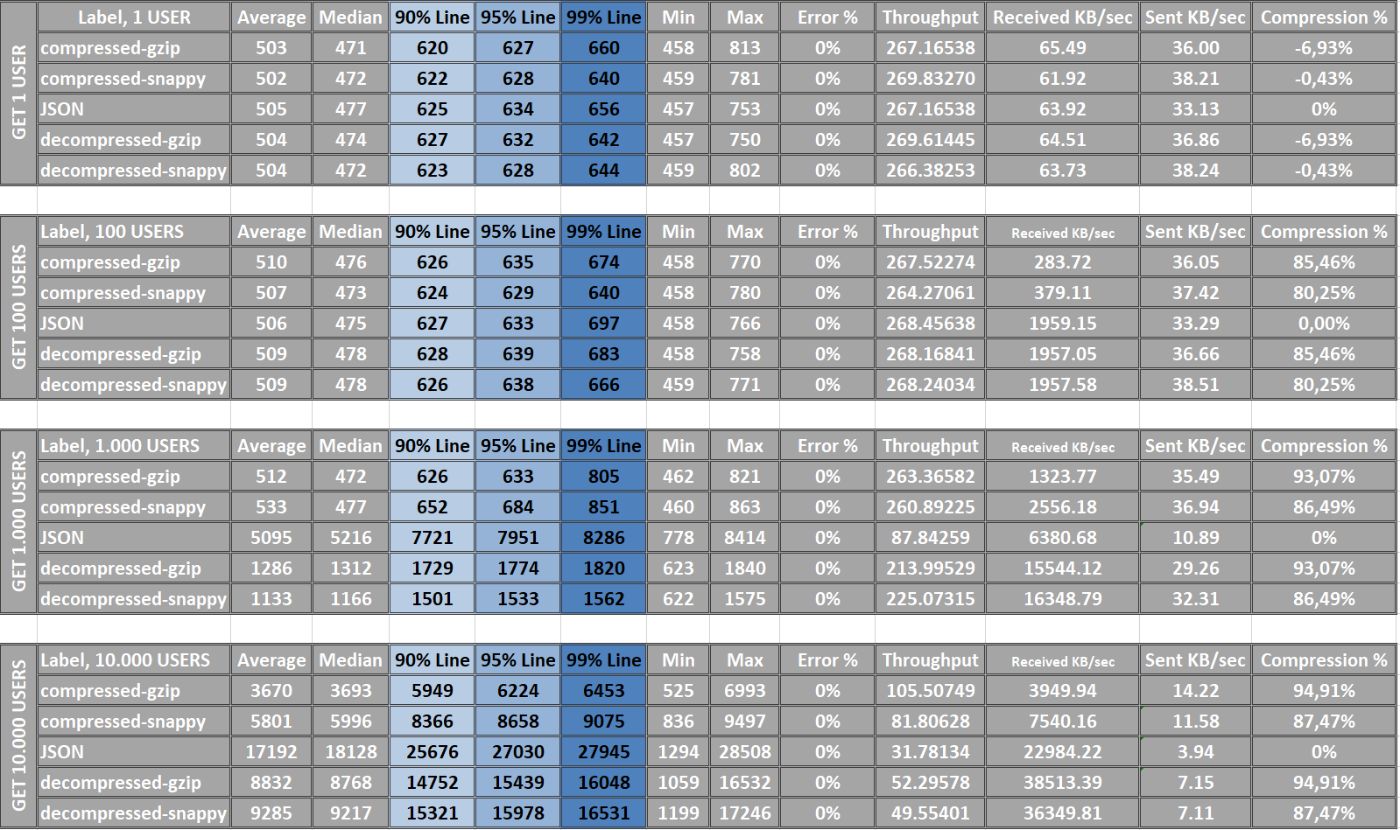
Гонка №2 - Локальный пинг (в пределах одной страны или региона).
Локальный пинг обычно самый низкий, поскольку данные передаются на короткие расстояния и на них меньше всего влияют задержки на маршрутизаторах и коммутаторах.
Гонка №3 Пинг между странами одного континента.
Задержка увеличивается, когда трафик пересекает большие расстояния и проходит через большее количество маршрутизаторов и сетевых узлов.
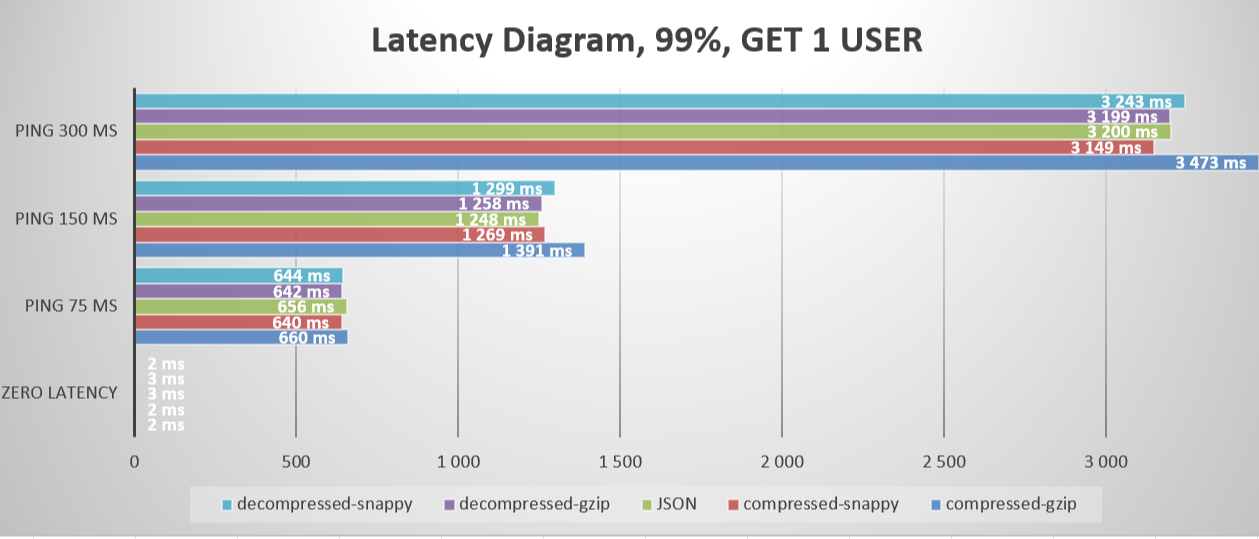
Межконтинентальный пинг гонки №4 (международные запросы):
Межконтинентальные запросы обычно имеют самую высокую задержку из-за прохождения данных по подводным кабелям и межконтинентальным соединениям, что значительно увеличивает пройденное расстояние и количество промежуточных узлов.
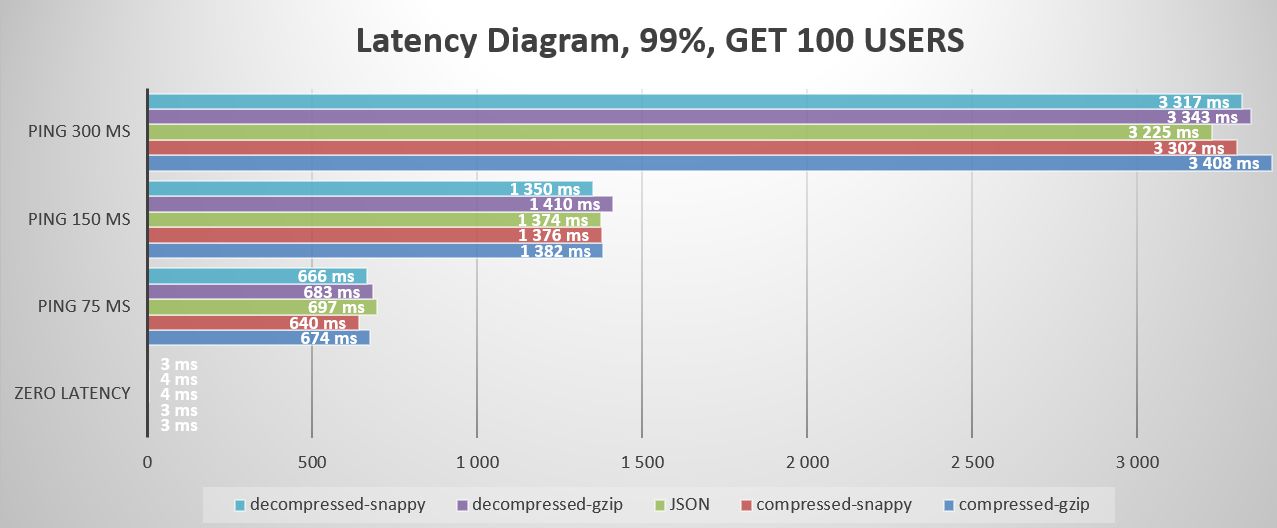
Краткий обзор задержек:
После установки задержки в сети мы можем наблюдать, как формируется результат сжатия данных. Важно помнить, что во время передачи на данные могут повлиять несколько факторов: дрожание, регулирование, потери, потеря пакетов, ограничение пропускной способности, перегрузка, резкие скачки задержки, проблемы с маршрутизацией и DNS и т. д. и т. д. р>
В случаях более длительной задержки преимущества использования сильно сжатых данных становятся более очевидными. GZIP оказывается явным победителем в этом сценарии. С другой стороны, Snappy, предлагающий идеально сбалансированное решение, хорошо работает при малом времени задержки, но уступает GZIP при среднем и высоком времени задержки. К сожалению, JSON ==fail== не позволяет эффективно обрабатывать случаи задержек и искажает реальность.
:::совет Имейте в виду, что доступ к этим диаграммам можно получить по предоставленной ссылке. для облегчения анализа.
:::
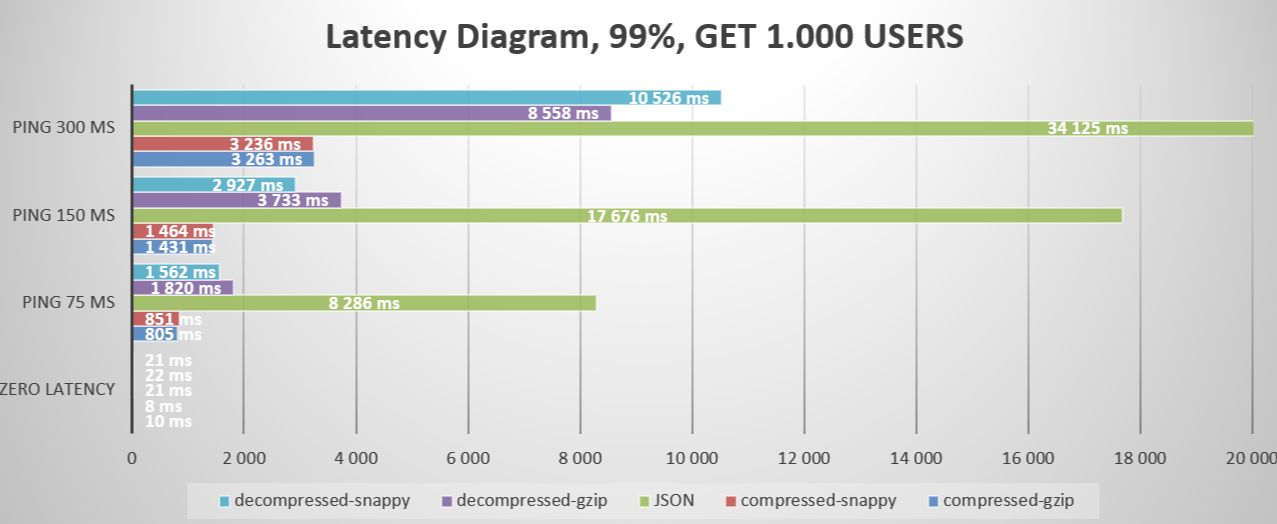
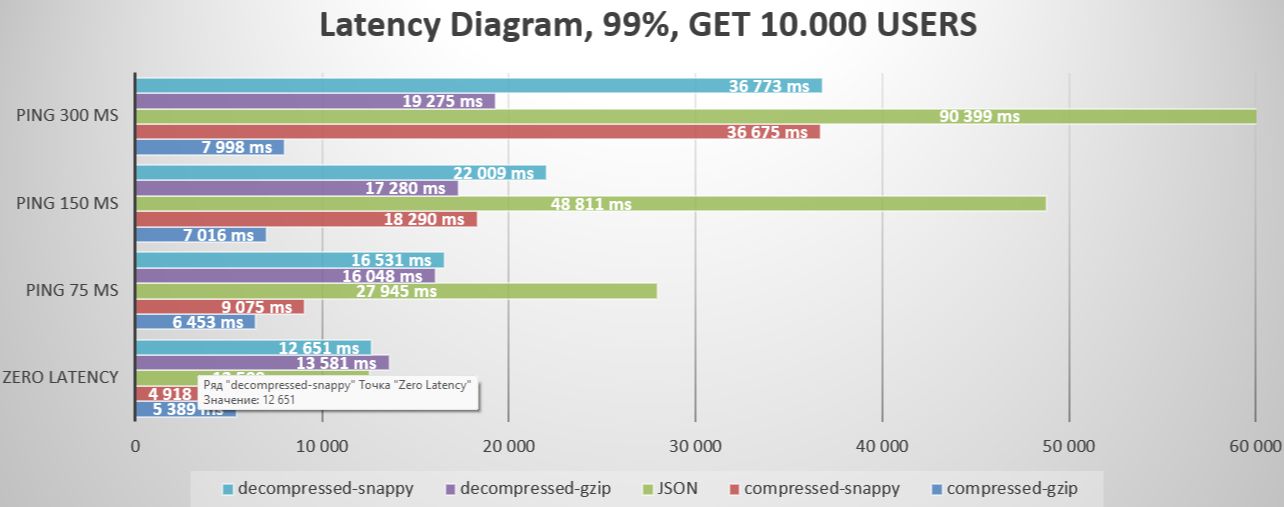
:::информация Напоминание: надеюсь, вы помните, что в некоторых случаях помимо результата по времени вы получаете степень сжатия 80-95%.
:::
Основные выводы.

* Добавление искусственной задержки в тесты подчеркивает важность географической близости микросервисов. Методы сжатия данных в региональных моделях размещения в облачных системах могут быть менее эффективными, за исключением случаев, когда вы используете модель оплаты по мере использования. Однако у этой модели есть несколько потенциальных недостатков, в том числе Уязвимость к региональным сбоям в работе, Ограниченный географический охват, Зависимость от одного поставщика услуг, Проблемы масштабирования, высокие затраты и даже правовые и нормативные ограничения. * Реальная задержка, имитирующая условия реальной сети, показывает, что с увеличением задержки преимущества сжатия данных становятся еще более очевидными, что делает традиционные запросы JSON API менее предпочтительными из-за их более высокая чувствительность к задержкам. Это подчеркивает необходимость использования методов сжатия данных в сочетании с географическим распределением серверов для оптимизации обмена данными и минимизации влияния задержек в сети. *Достижение идеальной системы требует тщательного подхода к выбору алгоритмов сжатия. Научившись динамически переключать алгоритмы сжатия на основе метаданных запроса и анализируя данные ответа, вы повысите эффективность своего бизнеса, снизите затраты и улучшите качество обслуживания пользователей.
Выбор стратегии.

Для эффективного выявления и оптимизации трафика между микросервисами в беспрокси приложениях необходима стратегия, сочетающая инструменты мониторинга, анализа трафика и сжатия данных. Вот шаги для разработки такой стратегии:
Мониторинг и анализ трафика
Определите наиболее часто используемые API и API, генерирующие наибольший трафик. Для этого необходимы инструменты мониторинга и анализа трафика.
* Prometheus и Grafana: используйте Prometheus для сбора показателей и Grafana для визуализации. Отслеживайте такие показатели, как частота вызовов API, объем данных и время ответа. * Elasticsearch, Logstash и Kibana (ELK Stack): этот стек может собирать, анализировать и визуализировать журналы. чтобы определить наиболее активные и ресурсоемкие API.
Выбор стратегии сжатия
После определения сильно загруженных API вы можете выбрать подходящую стратегию сжатия.
Реализация сжатия
В среде без прокси-сервера акцент смещается на сжатие на уровне приложения.
Тестирование и оптимизация
Постоянное улучшение
Технологии и требования меняются, поэтому крайне важно регулярно пересматривать и обновлять стратегию сжатия.
Этот подход позволит вам эффективно определять и оптимизировать трафик между микросервисами в средах без прокси-серверов, повышая производительность и снижая затраты на передачу данных.
* Олег Сипяхин в LinkedIn * Оригинал ==service-db== / ==service-mapper== можно скачать с ==GitHub====.== * Интернет-отчет Excel с диаграммами
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27521)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)