
Эффективное хранилище данных для быстрого анализа и визуализации
31 марта 2023 г.Многие приложения получают большое количество сформированных данных от пользователей или от некоторых служб, и это лишь некоторые из них:
* Торговое приложение каждую минуту получает пакеты данных об инструменте А * Приложение World Support center получает сообщения от пользователей, которые содержат некоторые ограниченные значения (перечисления), такие как страна, язык, причина и т. д. * Приложение «Карты» получает запрос на добавление ресторана на карту, где запрос может содержать информацию о том, какую еду они готовят, их рабочее время, есть ли у них предложения о работе и т. д.
В этих примерах есть одна общая черта — огромные объемы данных. Обычно, как продукт, вы хотите извлечь выгоду из этих данных и построить для них какую-то систему анализа. И в этой статье я хочу поделиться одним из способов хранения и использования этих данных для анализа.
Простой подход
Прежде чем идти дальше, давайте разберемся, почему мы не всегда можем использовать для этого тривиальный алгоритм. Тривиальный алгоритм позволит вам хранить все эти данные. И когда вы хотите создать аналитику, вы можете просто экспортировать ее в формате CSV и передать в какой-нибудь хороший инструмент.
С этим может быть несколько проблем (и многие другие, в зависимости от используемых вами инструментов):
* Создание CSV с использованием 10 строк из вашей БД — это быстро, но допустим, это 100 000 или даже больше! Создание файла с таким количеством строк из БД может занять некоторое время.
* Допустим, у нас есть неограниченное количество времени, но мы, скорее всего, получим OOM при работе с таким объемом данных! Плохо.
* Данные не поступают из одной таблицы! Вы должны использовать соединения... О, мое время... О, моя память!
Короче говоря, для большой аналитики простые инструменты экспорта не подойдут. Итак, давайте посмотрим, как мы можем решить это другим способом. И важно отметить, что неважно, какой тип анализа мы делаем, основанный на местоположении, на основе времени или что-то еще — проблемы связаны с размером данных.
Детальный снимок
Вспомним, что во вводных примерах я упомянул, что данные, которые мы получаем, поступают в форме, то есть они содержат некоторые типизированные ключи и значения, и нас интересует некоторая фиксированная размерность.
Просто чтобы дать представление о том, какой анализ мы можем проводить с формованными данными, вот несколько примеров:
* Анализ на основе таймфрейма - когда мы анализируем изменение данных в течение заданного периода времени. * Анализ на основе местоположения - когда мы анализируем изменение данных на основе границ местоположения * Анализ на основе подсчета — когда мы анализировали, сколько записей удовлетворяют заданному фильтру
В этой части я буду использовать временной анализ, но вы должны заметить, что его легко масштабировать на другие.
Итак, мы начнем с некоторых основных наблюдений:
- На диаграммах, которые видят люди, не так много точек, по меньшей мере, есть ограничение экрана.
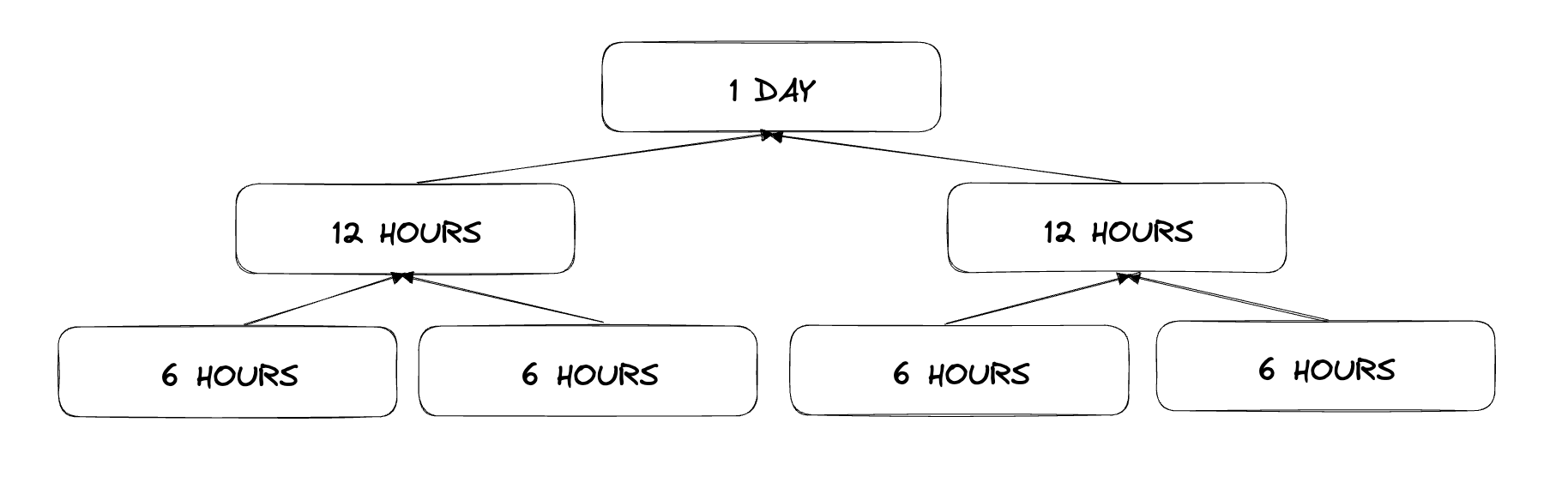
2. Таймфрейм можно построить из более мелких таймфреймов, например, один час можно представить как 30 минут плюс 30 минут
Давайте поймем, как мы можем использовать эти знания. Для простоты мы будем работать с сообщениями пользователей центра поддержки.
Давайте разделим всю временную шкалу на сегменты детализации. У нас получится что-то похожее на картинку ниже. Затем, когда приходит сообщение, мы можем легко сказать, в каких сегментах детализации оно появится.
В приведенном ниже примере мы получили сообщение в 3:24. Таким образом, он попадет в 4-й сегмент 1H, 2-й сегмент 3H и 1-й сегмент 6H.

Давайте создадим для этого упрощенную модель кода на C#.
namespace SupportCenter
{
public enum Country
{
USA,
Canada,
UK,
// ...
}
public enum Platform
{
Web,
iOS,
Android,
// ...
}
// There can be put other relevant enums
public class UserMessage
{
public int Id { get; set; }
public Country Country { get; set; }
public Platform Platform { get; set; }
public DateTime TimeOfSubmission { get; set; }
public string UserData { get; set; }
public DateTime ThirtyMinutesGranularity { get; set; }
public DateTime HourGranularity { get; set; }
// Other granularity fields can go here
public UserMessage(
Country country,
Platform platform,
DateTime timeOfSubmission,
string userData)
{
Country = country;
Platform = platform;
TimeOfSubmission = timeOfSubmission;
UserData = userData;
ThirtyMinutesGranularity = GetGranularityStartTime(timeOfSubmission, TimeSpan.FromMinutes(30));
HourGranularity = GetGranularityStartTime(timeOfSubmission, TimeSpan.FromHours(1));
// ...
}
private DateTime GetGranularityStartTime(DateTime timeOfSubmission, TimeSpan granularity)
{
long granularityTicks = granularity.Ticks;
long submissionTimeTicks = timeOfSubmission.Ticks;
return new DateTime(submissionTimeTicks - submissionTimeTicks % granularityTicks, DateTimeKind.Utc);
}
}
Удивительно, теперь мы знаем, к каким окнам детализации относится каждое сообщение (ради простоты использования мы идентифицируем каждую корзину детализации по ее началу, а не номеру)
Но как понять, какую степень детализации использовать?
Давайте воспользуемся первым наблюдением, что нам не нужно много точек данных на графике. Так что, если нам дан какой-то таймфрейм, который мы хотим отобразить для визуального анализа, нам нужно иметь не более 500 пунктов, но и не менее 100 пунктов. Кроме того, нам нужно выровнять по минимальной детализации. В этой статье мы будем использовать 1H.
В таблице ниже я определяю, какую степень детализации использовать, если пользователь просматривает график в заданном временном интервале.
Правило простое. Начиная с 1H, найдите минимальные/максимальные таймфреймы, которые он может покрыть как
1H * 100 < 1H-мин-таймфрейм < 1H * 500 < 1H-max-timeframe, то вы можете найти другую степень детализации, которая подойдет для этой формулы.
| Отображаемая детализация | Мин таймфрейм | Максимальный таймфрейм | |----|----|----| | 0,5 ч | 2D | 10D | | 2ч | 10D | 1М | | … | … | … | | 1 Вт | 4М | 1Г |
Давайте напишем функцию, которая даст нам детализацию по временным рамкам.
public static TimeSpan GetGranularityForTimeFrame(int from, int to)
{
var duration = to - from;
if (duration < 10 * Time.SEC_IN_DAY)
{
return TimeSpan.FromMinutes(30);
}
if (duration < Time.SEC_IN_MONTH)
{
return TimeSpan.FromHours(2);
}
// And so on
}
Нам также нужно найти первый и последний блоки детализации, которые будут охватывать от и до. Это легко сделать с помощью GetGranularityStartTime, который мы определили ранее.
И что со всем этим делать?
Зная все это, теперь мы можем создать новую таблицу в базе данных (HitsTable) для хранения количества попаданий кортежа (granularity_block, , granularity). Обращение происходит при создании сообщения.
public static int[] GetDataPoints(int from, int to)
{
var granularity = GetGranularityForTimeFrame(from, to);
var query_first_block = GetGranularityStartTime(from, granularity);
var query_last_block = GetGranularityStartTime(to, granularity);
// Some pseudocode here to show that you can use some ORM to query hits table
return HitsTable
.queryWhere(granularity_block >= query_first_block)
.queryWhere(granularity_block <= query_last_block)
.queryWhere(granularity = granularity)
.groupBy(granularity_block)
.value();
}
Нефиксированные размеры
В дополнение, это довольно просто расширить для работы с более чем одним параметром фильтров. Для этого в таблице попаданий также должны быть поля, по которым вы хотите разрешить фильтрацию. Он будет преобразован в (granularity_block, granularity, country, platform, …). Здесь важно знать, что для этого потребуется хранить намного больше данных.
Обзор
В этой статье мы изучили один из подходов к хранению данных, чтобы у него не было проблем с оперативной памятью при загрузке данных из БД (но мы пожертвовали для этого местом на жестком диске). Однако он работает быстро, чтобы получить точки данных для визуализации на заданных диаграммах.
:::информация Ведущее изображение, созданное со стабильной диффузией.
Подсказка: Проиллюстрируйте произвольную базу данных.
:::
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27430)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)