

Не выбирайте между созданием автоматических тестов или реализацией новых функций: попробуйте этот инструмент вместо этого
1 марта 2023 г.Автоматизированное тестирование стало неотъемлемой частью разработки программного обеспечения.
Тем не менее, я по-прежнему очень не люблю писать тесты, и недавно я узнал, что я не одинок. Я разместил опрос на Reddit, чтобы узнать, думают ли другие разработчики, как я, и, к счастью, я я не один.
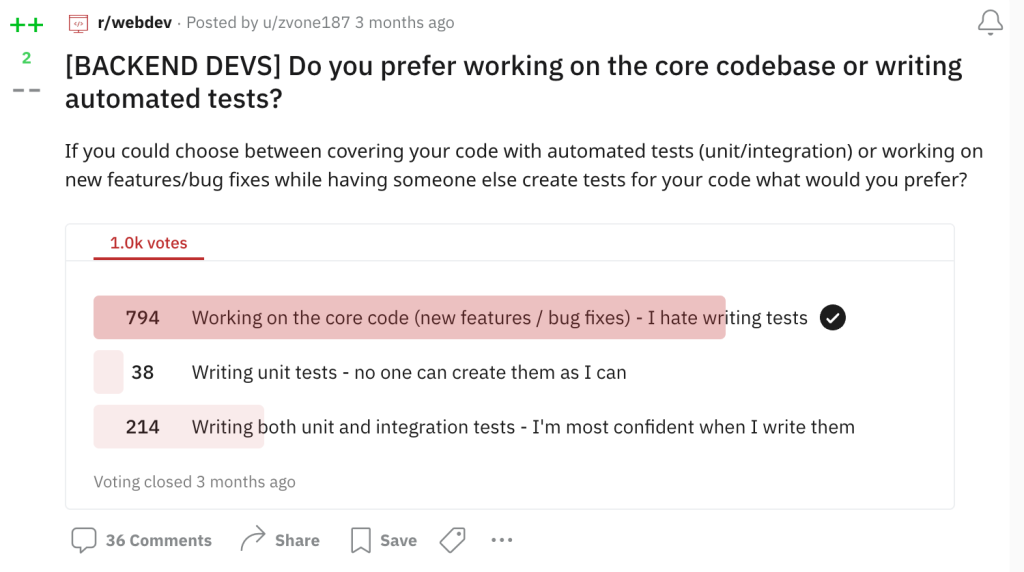
Представьте, что вы выбираете между:
- написание автоматических тестов для созданной вами функции
- или улучшение функции/начало реализации другой функции
Большинство из нас предпочли бы не писать тесты, а работать над основной кодовой базой, но мы знаем, что нас ждет катастрофа, если у нас не будет написанных тестов. Поэтому мы просто стиснем зубы и напишем их.
Все это заставило меня задуматься, действительно ли все это необходимо. Наличие тестов, безусловно, необходимо, но действительно ли нам нужно писать их вручную?
Итак, я начал работать с моим другом, и теперь, 2 месяца спустя, мы выпустили Pythagora — пакет npm с открытым исходным кодом, который создает автоматические интеграционные тесты, записывая и анализируя активность сервера без написания ни одной строки кода. В течение 1 часа после записи он может генерировать тесты с 90-процентным покрытием кода.
В этой записи блога я покажу вам, насколько проще использовать Pythagora по сравнению с традиционными способами написания тестов.
Если вы любите видео, вот короткое двухминутное видео о том, как работает Pythagora:
https://www.youtube.com/watch?v=Be9ed-JHuQg&embedable =правда
Традиционный способ написания интеграционных тестов
Представьте, что вы хотите протестировать конечную точку, которая возвращает продукты, которые пользователь просматривал ранее, но не покупал.
При тестировании такой конечной точки важно сначала настроить необходимые данные для теста. Это включает в себя наличие пользователя в базе данных вместе со связанными продуктами, которые пользователь просмотрел, но не купил.
Вы хотите, чтобы эти тесты запускались с любого компьютера (локальные компьютеры других разработчиков или промежуточные/тестовые среды), поэтому вам нужно убедиться, что данные, которые мы хотим протестировать, действительно находятся в базе данных. Поскольку мы не знаем, в каком состоянии находится база данных, обычно лучше всего настроить условия базы данных перед запуском теста (используя before >функция) и очищать состояние базы данных после каждого теста (используя функцию after ).
let userId, productIds;
before(async () => {
const products = await Product.create([
{ name: 'Product 1' },
{ name: 'Product 2' }
]);
productIds = products.map(p => p._id);
const user = await User.create({
name: 'Bruce Wayne',
email: 'bruce@wayneenterprises.com',
viewedProducts: productIds
});
userId = user._id;
});
В этом примере мы сначала создаем два новых продукта, используя метод Product.create. Затем мы создаем нового пользователя с именем «Bruce Wayne» и адресом электронной почты «bruce@wayneenterprises.com» и связываем созданные продукты с этим пользователем, добавляя продукт идентификаторы в параметре viewsProducts.
Хорошо, после завершения настройки мы можем приступить к тестированию конечной точки, которая возвращает список продуктов.
test('GET /purchased-products', async () => {
const response = await request(app)
.get(`/viewed-products/${userId}`);
expect(response.statusCode).toBe(200);
expect(response.body).toEqual([
{ name: 'Product 1' },
{ name: 'Product 2' }
]);
});
В этом примере тест отправляет запрос GET к конечной точке /purchased-products/:userId с userId, который мы создали в методе установки. И он использует функцию Jest expect, чтобы проверить, что ответ имеет код состояния 200 и что тело ответа содержит продукты, которые мы создали в методе установки.
Представьте, что у вас есть разные типы пользователей и продуктов. Например, если пользователь покупает продукт несколько раз, он получает его со скидкой. Для каждого из этих различных случаев вам потребуется создать отдельную настройку и отдельный тест.
Тест, обновляющий базу данных
Еще один очень распространенный тестовый сценарий — проверка того, произошло ли обновление базы данных. Например, когда пользователь покупает продукт, мы хотим изменить его документ в базе данных, чтобы отразить это. Чтобы убедиться, что коллекция пользователей была обновлена, нам нужно запросить базу данных и внутри теста сравнить, отражает ли база данных желаемое изменение. Вот полный пример такого теста.
const request = require("supertest");
const app = require("../app");
const User = require("../models/user");
const mongoose = require("mongoose");
describe("POST /purchase", () => {
let user;
before(async () => {
await mongoose.connection.dropDatabase();
const viewedProductIds = ["productId1", "productId2"];
user = new User({
name: "testuser",
viewedProducts: viewedProductIds,
});
await user.save();
});
test("should purchase a product and update the user", async () => {
const productId = "productId2";
const response = await request(app)
.post("/purchase")
.send({ productId });
expect(response.statusCode).toBe(200);
expect(response.body).toEqual({ message: "Product purchased successfully" });
const updatedUser = await User.findOne({ name: "testuser" });
expect(updatedUser.purchasedProducts).toContain(productId);
});
});
Чтобы максимально покрыть кодовую базу сервера тестами, нам нужно закодировать тест для каждого из различных случаев для каждой из конечных точек. Это может легко масштабироваться до сотен или даже тысяч различных тестов.
Если мы подсчитали, что среднему разработчику требуется час для создания теста, становится довольно сложной задачей покрыть всю кодовую базу тестами с нуля.
Использование Пифагора
Теперь представьте, если бы вы могли создать сотни тестов, подобных этому, с настройкой базы данных, отправкой запроса и проверкой всех значений из базы данных и ответа всего за 1 час!
🏗️ Как это работает
Pythagora фиксирует запросы API (с ответами) и активность сервера во время обработки запроса. На основе этих данных он создает автоматизированные тесты, которые можно запускать в любой среде/на любом компьютере.
При захвате запроса API Pythagora сохраняет все документы базы данных, используемые во время запроса (до и после каждого запроса к базе данных).
При запуске теста Pythagora сначала подключается к временной базе данных pythagoraDb и восстанавливает все сохраненные документы. Таким образом, состояние базы данных во время теста будет таким же, как и во время захвата, поэтому тест может выполняться в любой среде, НЕ изменяя вашу локальную базу данных. Затем Pythagora отправляет запрос API, отслеживая все запросы к базе данных, и проверяет, совпадают ли ответы API и документы базы данных с теми, что были во время захвата.
Например, если запрос обновляет базу данных, то после того, как API вернет ответ, Pythagora проверит базу данных, чтобы убедиться, что она была обновлена правильно.
⚙️ Настройка
Настроить Pythagora для сервера Node.js очень просто. Просто установите пакет npm с помощью
npm install pythagora
и добавьте одну строку кода сразу после инициализации Express. Например, если вы инициализируете его с помощью const app = express();, вы добавляете следующую строку кода.
if (global.Pythagora) global.Pythagora.setApp(app);
Вот и все, теперь вы готовы начать собирать запросы.
🎥 Отслеживание запросов
Теперь вам просто нужно запустить команду pythagora и передать файл .js, который вы обычно запускаете при запуске сервера. Например, если вы запускаете свой сервер с node ./path/to/your/server.js, вы должны запускать Pythagora следующим образом:
npx pythagora --initScript ./path/to/your/server.js
Эта команда запустит ваш сервер, но с Pythagora. Теперь, чтобы заставить Pythagora создавать автоматические тесты, вам просто нужно отправить запросы API на ваш сервер.
Вы можете сделать это любым способом, которым вы обычно отправляете запросы во время разработки или тестирования. Вы можете использовать свой браузер и щелкать по интерфейсу, отправлять запросы через Postman или cURL или любым другим способом, который вы используете. к.
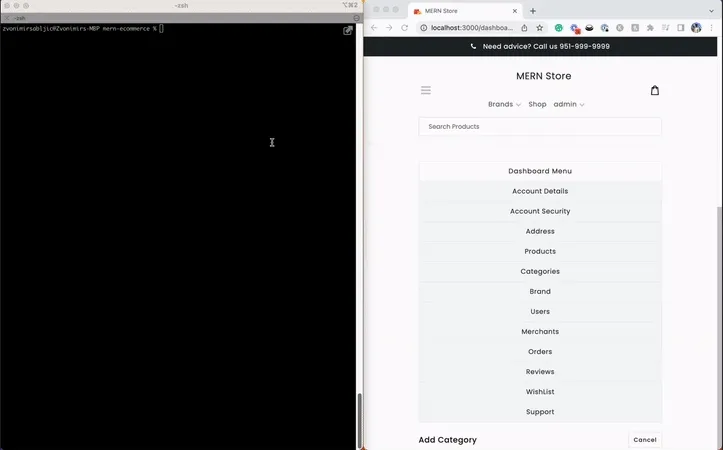
Pythagora записывает все запросы к конечным точкам приложения с ответом и все, что происходит во время запроса. В настоящее время это означает все запросы Mongo и Redis с ответами (в будущем сторонние запросы API, операции дискового ввода-вывода и т. д.).
Вы можете увидеть все захваченные тесты с метаданными в папке pythagora_data в корне вашего проекта. Имея эту папку, любой из вашей команды может запускать эти тесты независимо от базы данных, к которой он подключен.
🚦Выполнение тестов
При выполнении тестов не имеет значения, к какой базе данных подключен ваш Node.js или в каком состоянии эта база данных. На самом деле, эта база данных никогда не трогается и не используется —> вместо этого Pythagora создает специальную эфемерную базу данных pythagoraDb, которую использует для восстановления данных перед выполнением каждого теста, которые существовали на момент записи теста. Благодаря этому тесты можно запускать на любом компьютере или в любой среде.
Если тест выполняет обновление базы данных, Pythagora также проверяет базу данных, чтобы убедиться, что она была обновлена правильно.
Итак, после того, как вы захватили все нужные запросы, вам просто нужно добавить параметр режима --mode test в команду Pythagora, чтобы запустить захваченные запросы.
npx pythagora --initScript ./path/to/your/server.js --mode test
📝 Отчет о покрытии кода
Охват кода – отличный показатель при создании автоматизированных тестов, поскольку он показывает, какие строки кода были покрыты тестами. Pythagora использует nyc для создания отчета о коде, пройденном тестами Pythagora. По умолчанию Pythagora показывает сводку базового отчета о покрытии кода при выполнении тестов.
Если вы хотите создать более подробный отчет, вы можете сделать это, запустив Pythagora с флагом --full-code-coverage-report. Например:
npx pythagora --initScript ./path/to/your/server.js --mode test --full-code-coverage-report
Вы можете найти отчет о покрытии кода в папке pythagora_data в корне вашего репозитория. Вы можете открыть представление отчета в формате HTML, открыв pythagora_data/code_coverage_report/lcov-report/index.html.
Если вы вообще не хотите, чтобы покрытие кода отображалось во время выполнения тестов, вы можете запустить тесты с параметром --no-code-coverage.
🎚 Текущие ограничения
В настоящее время Pythagora весьма ограничена и поддерживает только приложения Node.js с Mongoose и Express, но мы прилагаем все усилия, чтобы распространить эту поддержку на другие технологии и языки. Если Mongoose не используется в кодовой базе, Pythagora будет собирать запросы и ответы API без тестирования базы данных.
Для поддержки наиболее важных технологий для нас будет очень важно, если вы оставите комментарий или отправите нам электронное письмо по адресу hi@pythagora.io с технологиями. вы используете то, что вы хотели бы получить поддержку.
Заключение
Большинство разработчиков, включая меня, не получают удовольствия от создания и поддержки тестов. Это проблема, которую мы пытаемся решить с помощью Pythagora.
Pythagora — это пакет npm с открытым исходным кодом, который может записывать и анализировать активность сервера для создания тестов, имитирующих поведение вашей кодовой базы. Используя его, вы можете сэкономить время и усилия и создать покрытие кода до 90% всего за один час. Это означает, что вы можете тратить больше времени на работу с основной кодовой базой и меньше времени на написание и поддержку тестов.
Вам не нужно беспокоиться о том, к какой базе данных подключен ваш сервер или о состоянии этой базы данных. Pythagora создает специальную эфемерную базу данных pythagoraDb, которую использует для восстановления данных перед выполнением каждого теста, имевшихся на момент записи теста. Это означает, что тесты можно запускать на любой машине или в любой среде, что значительно повышает эффективность тестирования.
Во всяком случае, это все. Надеюсь, вам понравилось. Мы все еще находимся на очень ранней стадии, поэтому мы очень ценим любые отзывы.
Как вы пишете интеграционные тесты для своего сервера API? Не могли бы вы использовать Pythagora вместо/вместе с вашей системой?
Если нет, я хотел бы услышать, что вас беспокоит и почему это не сработает в вашем случае?
Кроме того, если вам нравится Pythagora, будет очень важно, если вы дадите нам звезду на Github — https://github.com/ Пифагора-ио/пифагора
Чтобы получить информацию о бета-версии или дать предложение по технологии (платформе/базе данных), которую вы хотите поддерживать в Pythagora, вы можете 👉 добавьте свой адрес электронной почты / комментарий здесь 👈
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27275)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)