

Делать больше с меньшими затратами? Не без лучших журналов и лучших инструментов
27 июня 2025 г.С тех пор, как я начал технологию в 1992 году (более трех десятилетий назад!), Я столкнулся с бесчисленными сценариями, где я должен был «делать больше с меньшими затратами». Это означало, что это значит поставить больше с меньшим количеством членов команды или работать в рамках ограниченных аппаратных ресурсов, это мышление было повторяющейся темой.
Один опыт выделяется в качестве бэкэнд -архитектора в проекте модернизации облаков. Чтобы сократить расходы, нас попросилиминимизировать или устранить журнал на уровне обслуживания—Корирование, на что мы полагались на отладому и анализу инцидентов. Решение было обусловлено высокой стоимостью проглатывания журнала на нашей платформе наблюдения.
Это сработало - пока это не было.
Нам действительно нужны эти журналы!
Неизбежно возникла неожиданная проблема, и нам нужны были те недостающие журналы. Они оказались единственным способом определить основную причину. Без них часы, отмеченные без решения, неопределенность росла, а беспокойство следовало за всей командой.
// Sample (but not the real) log line removed during our cost-cutting
{
"timestamp": "2025-03-21T14:05:03Z",
"service": "preference-engine",
"level": "ERROR",
"message": "Worker queue overflow: unable to dispatch to worker pool",
"requestId": "abc123",
"userId": "admin_42"
}
Если бы мы сохранили это, простой структурированный журнал ошибок (например, вышеупомянутое) мог быть легко отфильтрован в платформе журнала с простым журналом (например, ниже) и позволил нам понять, диагностировать и исправить проблему.
_sourceCategory=prod/preference-engine "Worker queue overflow"
| count by userId, requestId
Приглашение резко сократить нашу журнализун, поставив весь проект в уязвимое состояние.
Lean не обязательно означает голод за ресурсы
Чтобы быть ясным, мышление «делать больше с меньшим количеством», не так уж плохо. Многие стартапы процветают, сосредотачиваясь на ключевых приоритетах и используя легкое, эффективное программное обеспечение. Минималистский дизайн может привести к лучшему качеству, при условии, что ключевой инструмент остается на месте.
Но это был не «хороший» тип худой. И наш крайний срок для перемещения в облако было исправлено. Мы участвовали в дате осмотра браузера. Это означало переписывание услуг в облачный дизайн, координацию с командами клиентов и предоставление под давлением. Без времени для полного тестового охвата или глубокой интеграции наблюдения,Мы полагались на журналы, чтобы решить наши проблемыи помочь определить основную причину неожиданных сценариев. Сначала это было нормально, мы просто вставили необходимые журналы во время работы над каждым методом.
Но когда регистрация была сокращена, команда была выставлена. Наша основная сеть безопасности исчезла.
Корневая причина без сети
Внутреннее тестирование прошло хорошо. По мере приближения производства мы чувствовали себя уверенно в нашей новой облачной архитектуре. Мы решили известные проблемы в тестировании и встретили наш крайний срок.
Но вскоре мы поняли, что наша уверенность была неуместна, и наш тестовый охват отсутствовал.
Как только мы были в производстве, и реальные клиенты использовали платформу, появились эти надоедливые случаи. И, конечно же, без подробных журналов или достаточной наблюдаемости, у нас не было возможности исследовать проблему. Ограниченной телеметрии просто было недостаточно, чтобы определить, что пошло не так.
Если бы у нас были журналы как для бэкэнд -тестов, так и для производственных клиентов на фронте, мы могли бы знать, что происходит, и предупредить команду (и пользователя). Это был бы простой журнальный запрос:
_sourceCategory=prod/preference-engine OR prod/frontend error
| join ( _sourceCategory=prod/tester-feedback “queue error” )
on requestId
| fields requestId, _sourceCategory, message
Но без журналов воспроизведение инцидентов локально было практически невозможным. Было слишком много изменчивости в реальных случаях использования. Мы попытались повторно устроить частичную регистрацию, но это только что привело к увеличению затрат на потребление потребления, которые мы попросили сократить, не предоставляя действенную информацию.
В некоторых случаях мы вообще не могли определить основную причину. Это сложная позиция: знать, что есть проблема, затрагивающая пользователей и не в состоянии объяснить это. Это создало распространенное чувство беспомощности по всей команде.
Качество MTTR против сигнала
Еще одна проблема заключалась в том, что в нашем инциденте ретроспективы, среднее время для выздоровления (Mttr) рассматривался как метрика заголовка. Но мы обнаружили, что MTTR чаще всего был симптомом, а не основной причиной.
Отраслевые тесты обычно показывают, что элитные команды достигают MTTR за час. Но мы поняли, что скорость не просто автоматизация - этосигналы высокой точки зренияПолем Сигналы с низкой точностью, такие как общие ошибки 500 или отсроченное предупреждение от совокупных метрик, не помогают. Они просто вводят двусмысленность и тратят ресурсы (такие как драгоценное время сортировки и бюджет регистрации).
Напротив, подробные контекстуальные сигналы - такие как структурированные журналы с пользователем, user, requestId и сервисного трассировки - выходят непосредственно к основной причине. Платформы наблюдений могут уменьшить MTTR, но только в том случае, если данные, которые вы приглашаете, действуют.
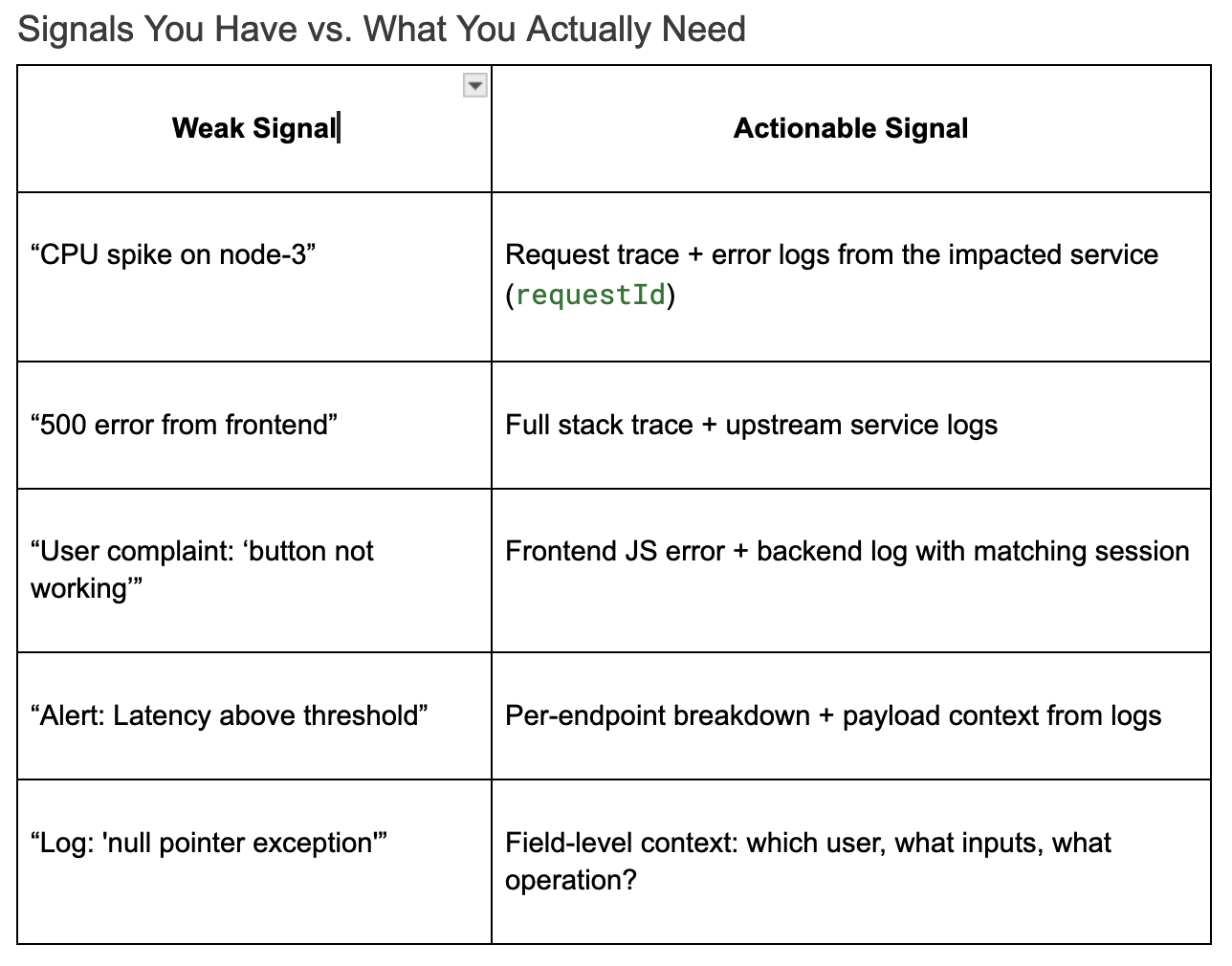
Если ваши журналы не отвечают на эти вопросы, ваш MTTR не о скорости команды, а о ясности сигнала.
Как модель Sumo Logic могла сохранить день
Итак, что могло бы пойти по -другому - и лучше - в рамках моего проекта модернизации облаков?
Во -первых, я действительно хотел бы, чтобы у нас была бы лучшая аналитика журнала и мониторинг производительности приложений (APM). И наряду с этим APM, управление журналом, обслуживание, оповещения и определенные показатели, тесно связанные с функциональным успехом или неудачей. Я бы хотел (в каждом проекте), что для каждой новой функции у меня была связанная метрика, привязанная к его успеху.
И я хочу, чтобы мои журналы вернулись! В моей предыдущей публикации, «Devsecops: Пора заплатить за ваш спрос, а не прогласить,Я исследовал, какСумо логиканарушил пространство наблюдения, предлагая модель оплаты за анализ. Журналы могут непрерывно проглатываться, но вы платите только тогда, когда вам нужно запросить или проанализировать их.
Вы команда без полного покрытия для тестирования модуля? Страдая от отсутствия оповещений в реальном времени или гранулированных метрик? При ограниченном бюджете? Увядание от недостатка бревен?
Благодаря полному проглатыванию с нулевой стоимостью команды могут зарегистрироваться столько, сколько им нужно без забот. И когда этот инцидент, наконец, произойдет (и это произойдет), анализ может быть инициирован по требованию, по оправданной стоимости, непосредственно связанной с воздействием клиента или непрерывности бизнеса. Бюджетные люди счастливы; Вы счастливы.
Этот подход восстанавливает контроль и снижает беспокойство, потому что команды уполномочены тщательно исследовать, когда это наиболее важно.
Но подождите: вам также нужна сортировка с помощью машины, чтобы прояснить ваши запросы
Но есть еще один шаг. Современная наблюдение - это не просто наличие всех этих красивых данных журнала, а также знают, где смотреть в эти данные. Как упоминалось выше, вам нужно организовать,сигналы высокой точки зренияПолем
Когда у вас есть неограниченное количество проглатывания, у вас есть тонна данных. И когда вы начинаете искать информацию, вам нужно место для начала. Чтобы помочь, Sumo Logic также предоставляетМашинолетние инструменты сортировкиЭто автоматически группирует аномальное поведение, обнаружение выбросов и поверхностные коррелированные сигналы между службами, прежде чем написать один запрос.
За кулисами Sumo Logic использовала статистические алгоритмы и машинное обучение:
- Кластерные журналыпо сходству (даже если сформулироваться по -разному в узлах).
- Обнаружить выбросыВ метрик и журналах (например, вспышки ошибок на услугу, регион или пользовательская когорта).
- Обогащать аномалииС метаданными (например, теги AWS, информация о капсуле Kubernetes, маркеры развертывания).
- Обработка естественного языкаКластеры журналы с помощью семантического сходства, а не только сопоставления строк.
Это особенно полезно в широкой среде безлимитного приема. Вместо того, чтобы просеивать десятки тысяч линий журнала, вы получаете «подписи журналов» - закономерности, которые представляют группы связанных событий.
Пример рабочий процесс
_sourceCategory=prod/* error
| logreduce
Это единственные командные кластеры шумные данные журнала в действующие ведра, такие как:
Error: Worker queue overflow
Error: Auth token expired for user *
Error: Timeout in service *
После складывания команды могут погрузиться в более глубокий контекст:
| where message matches "Auth token expired*"
| count by userId, region
Результат? Меньше слепых поисков. Более быстрые пути решения. Меньше беспокойства во время инцидента.
Заключение
Философия «делай больше с меньшим» »не должна ставят инженерные команды в невыгодное положение. Но это должно сопровождаться правильными инструментами. Без них даже самые способные команды могут почувствовать, что они бесцельно перемещаются во время инцидента - увлекаются разочарованием и стрессом.
Мои читатели могут вспомнить мое личное заявление о миссии, которое, как я чувствую, может применить к любому ИТ -профессионалу:
«Сосредоточьтесь на своем предоставлении функций/функциональности, которые расширяют ценность вашей интеллектуальной собственности. Используйте рамки, продукты и услуги для всего остального». - Дж. Вестер
В этой статье мы рассмотрели, как модель проглатывания с нулевым ценой выравнивается с этой миссией. Это помогает командам быстро выявлять первоначальные причины, снижать время простоя и более низкие уровни стресса - все не нарушая бюджет. Давайте сохраним эти журналы!
Удачного дня!
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)