

Проектирование масштабируемых внутренних инструментов: уроки из фронта линий Ops Engineering
3 июля 2025 г.Многие компании на ранней стадии полагаются на электронные таблицы и специальные информационные панели для выполнения критически важных рабочих процессов. Эти инструменты могут занять удивительно далеко. Но по мере увеличения масштаба внутренних операций и сложности их хрупкость становится очевидной. Пропущенные обновления, нетронутые решения и сломанные рабочие процессы являются некоторыми общими последствиями полагаться на быстро собранные системы. В этой статье рассматривается, как создать устойчивую внутреннюю инфраструктуру, от производственных переменных рамок до структурированного распределения задач, черта вдохновения из лучших практик как в среде высокого роста, так и более зрелых инженерных организаций.
Управление операциями в областях с высокими ставками
Электронные таблицы и коммуникации по Slack часто питают внутренние операции стартапа. Эти инструменты невероятно мощны при правильном использовании, и предлагают скорость и гибкость, необходимые для быстрого итерации. По мере увеличения масштаба эти частичные системы могут начать потерпеть неудачу. Пропущенные обновления и нетронутые решения становятся повторяющимися проблемами. То, что когда -то было построено с учетом скорости, становится препятствием. Без журналов аудита и видимости в том, что делает каждый сотрудник, оперативная сложность становится все труднее управлять. Это приводит к потраченному впустую времени и непоследовательному исполнению. Управление этой сложностью особенно важно для компаний, чья прибыль зависит от эффективности работы. В частности, в областях с высокими ставками, такими как логистика или здравоохранение, успех зависит от своевременной доставки и прозрачности. Чтобы успешно масштабировать внутренние операции, команды должны перейти от импровизации к более вдумчивому планированию вокруг инструментов, которые поддерживают их ежедневные рабочие процессы.
Автоматизированное распределение задач
В оперативных интенсивных средах динамические системы распределения задач являются одним из инструментов с самым высоким левереджем, которые может реализовать команда. На ранних этапах компании задания могут управляться вручную через электронные таблицы и слабые потоки. Кто -то может сортировать проблему, обновить общий документ и пинговать точку контакта. По мере увеличения объема эта специальная модель вводит риск: дублировать работу, пропущенные задачи и непоследовательную приоритету из-за недопонимания. Нет центрального источника истины, нет четкого аудиторского следа и никакого способа систематического обеспечения бизнес -логики.
Мы можем заменить это на систему маршрутизации задач, управляемую событиями. После каждого события, такого как утвержденный запрос или обновление в статусе, мы можем создать объект задачи (как правило, просто строка базы данных) с такими атрибутами, как статус, приоритет или призывник. Эти задачи могут быть приоритетными на основе срочности и исторического статуса и в конечном итоге направляются на нужного человека. Карта всей этой операционной системы может быть всплываю и отслеживается в RETool. Автоматируемые задачи могут быть выполнены программно, в то время как те, кто требует ввода человека, обостряются до нужного члена команды в зависимости от роли и доступности.
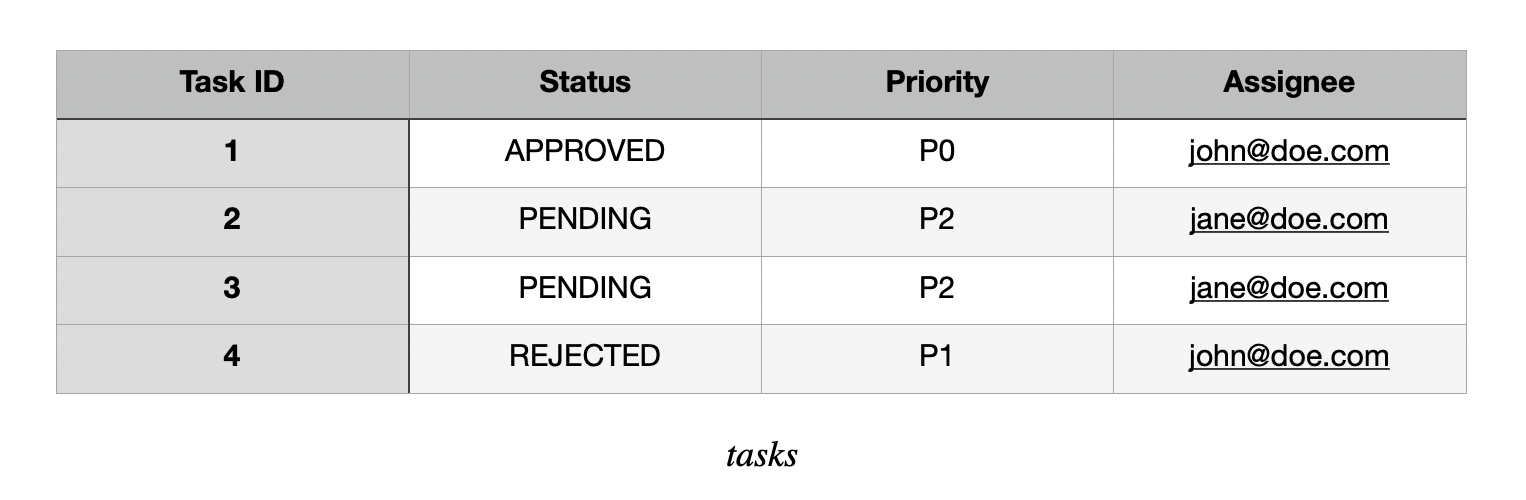 Кодифицируя эту логику маршрутизации (то есть повторно, эскалации и зависимости от задач), мы можем:
Кодифицируя эту логику маршрутизации (то есть повторно, эскалации и зависимости от задач), мы можем:
- Убедитесь, что срочные проблемы решаются в первую очередь
- Предотвратить дубликат работы
- История разрешения треков на гранулярном уровне и в режиме реального времени
Этот слой оркестровки позволяет операторам действовать с уверенностью, зная, что то, что земля в их очереди является ясным, общего и актуальным. Сотрудникам больше не нужно копаться в электронных таблицах или оправдать работу, которую они выполняли.
Добавление мониторинга и петли обратной связи
Еще одним преимуществом централизованной системы прослеживаемой маршрутизации задач является то, насколько относительно простой для мониторинга слоев и аналитики сверху. Руководители могут контролировать работу компании с видом на птицы с несколькими линиями SQL. В таких условиях человека в петле простой очередь или отставания недостаточно. Нам нужна аналитика на самих этих отставаниях, чтобы оценить, где работает работа, как долго выполнялись определенные задачи в режиме ожидания и не отстают ли выход.
Каждое задание может быть добавлено в таблицу, и любые изменения, внесенные в статус задачи, также могут быть зарегистрированы в отдельной таблице записей, чтобы отслеживать весь его жизненный цикл. Retool делает невероятно легко строительство панелей мониторинга и визуально представляет результаты запросов, о которых мы заботимся.
Механизмы оповещения также необходимы для улучшения операций. Задачи, застрявшие в состояниях ошибки или в отставании в течение более определенного порога времени могут быть подключены, чтобы вызвать оповещения о слабых. Этот слой создает общий язык между операторами, руководителями и инженерами.
Сделать конфигурацию доступной для всех
Критические конфигурации бизнеса часто строят за кодом. Это реальная проблема в качестве масштабов компании, а разделение между инженерными и другими организациями расширяется. Пороговые значения эскалации, копирование на A/B -тест - это все переменные, которые любой член компании, такие как те, которые работают над ростом или продуктом, может захотеть приспособиться. Тем не менее, изменение их часто влечет за собой просьба инженера вмешаться, толкать код, получить проверку кода, а затем развернуть. Нередко, чтобы не инженеры были заблокированы инженерами таким образом. Даже руководителям может не хватать видимости или контроля, чтобы повлиять на эти переменные сами.
Мы можем создать систему управления конфигурацией для решения этого. Этот интерфейс, опять же, внутренний инструмент, появившийся через RETOOL, служит единственным источником истины для производственных переменных и позволяет всем членам организации не просто смотреть, но и редактировать их в считанные секунды. Вместо того, чтобы похоронить бизнес -логику глубоко внутреннего исходного кода, затмевая от всех, кроме инженерии, переменные могут храниться в таблице Postgres. Эти значения могут быть безопасно изменены авторизованными людьми через визуальный интерфейс. Сам пользовательский интерфейс может включать любую проверку ввода и проверку типов, необходимые для обеспечения того, чтобы ничего не было проблемным. Обработка ошибок также может быть представлена на бэкэнд.
Экстернализуя эту бизнес -логику, команды могут мгновенные обновления своего программного обеспечения, не выдвигая кода и быстро экспериментировать. Инженерам больше не нужно делать тривиальные обновления и может перенаправить эти часы на работу с более высокой стоимостью.

Заключение
Хотя скорость - это одно из немногих преимуществ, которые имеет стартап, это не обязательно означает, что команды должны двигаться в самоустильном режиме. Создание масштабируемой инфраструктуры влечет за собой не только создание инструментов, которые повышают прозрачность, но также делают технические системы разборчивыми для нетехнических сверстников. Внутреннее программное обеспечение также является реальным продуктом, и должно рассматриваться как таковое. Инвестирование в начале этих проектов и обеспечение их устойчивости имеет решающее значение по мере того, как компания и сложность растет.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)