

Декларативная инженерия: использование Terraform для кодирования конвейеров данных
19 января 2024 г.Данные широко считаются источником жизненной силы организации; однако он бесполезен – и бесполезен – в своей сырой форме. Нужна помощь, чтобы превратить эти данные в животворящую информацию. Часть этой помощи заключается в перемещении этих данных из источника в место назначения через конвейеры данных. Но управлять сквозным жизненным циклом конвейера данных непросто: одни сложно масштабировать по требованию, другие могут привести к задержкам в обнаружении и устранении проблем или их трудно контролировать. Эти и другие проблемы можно решить в парадигме декларативного программирования, и в этой статье мы увидим это на Terraform.
Откуда эти данные?
Данные в этих обширных наборах данных поступают из нескольких разрозненных источников и обычно загружаются в наборы данных в хранилище данных, таком как ClickHouse, через конвейеры данных. Эти конвейеры играют решающую роль в этом процессе, эффективно перемещая, преобразовывая и обрабатывая данные.
Например, представьте, что у вас есть стартап по анализу данных, который предоставляет организациям анализ данных в режиме реального времени. Ваш клиент владеет стартапом по прокату электронных велосипедов, который хочет интегрировать данные о погоде в существующие данные для обоснования своих стратегий маркетинговых сообщений. Несомненно, ваши инженеры по обработке данных установят множество различных конвейеров данных, извлекая данные из многих источников. Два из них, которые нас интересуют, предназначены для извлечения данных из CRM вашего клиента и местной метеостанции.
Уровни современного стека данных
Стек данных – это совокупность различных технологий, логически наложенных друг на друга, обеспечивающих возможности сквозной обработки данных.
Как описано здесь, стек данных может иметь много разных слоев. Современный стек данных состоит из уровней приема (конвейеры данных), хранения (база данных OLAP) и бизнес-аналитики (анализ данных). Наконец, существует уровень оркестрации — например, Kubernetes или Docker Compose — который находится поверх этих слоев и организует все вместе, чтобы стек делал то, что он должен делать; следовательно, получать необработанные данные и использовать расширенную прогнозную аналитику.
Конвейеры данных обычно имеют структуру конвейеров извлечения, преобразования, загрузки (ETL) или извлечения, преобразования загрузки (ELT). Однако разработка, мониторинг и управление этими конвейерами данных, особенно на международных предприятиях с множеством филиалов по всему миру, может быть очень сложной задачей, особенно если процесс сквозного мониторинга конвейера данных выполняется вручную.
Разработка конвейеров данных традиционным способом
Конвейеры данных в целом делятся на две группы: основанные на коде и развернутые в прямом ациклическом графике или инструментах, подобных DAG, таких как Airflow и Apache Fink, или не основанные на коде, которые часто разрабатываются в приложениях на основе SaaS. через интерфейс перетаскивания. У обоих свои проблемы.
Конвейеры данных на основе кода сложно масштабировать по требованию. Цикл разработки/тестирования/выпуска обычно слишком длинный, особенно в критических средах с тысячами конвейеров, ежедневно загружающих петабайты данных в хранилища данных. Кроме того, они обычно внедряются, развертываются и отслеживаются вручную инженерами по обработке данных, что снижает риск возникновения ошибок и значительных простоев.
Поскольку конвейеры данных, не основанные на коде, инженеры не имеют доступа к внутреннему коду, видимость и мониторинг могут быть ограничены, что приводит к задержкам в обнаружении и устранении проблем и сбоев. Кроме того, сложно воспроизвести ошибки, поскольку невозможно сделать точную копию конвейера. Наконец, контроль версий с использованием такого инструмента, как Git, сложен. Контролировать развитие конвейера сложнее, поскольку код не хранится в репозитории, таком как репозиторий GitHub.
Решение: улучшение конвейеров данных с помощью декларативного, воспроизводимого, модульного проектирования
Хорошая новость заключается в том, что существует устойчивое решение этих проблем.
Важно напомнить себе о разнице между императивным и декларативным программированием. В императивном программировании вы контролируете, как все происходит. В декларативном программировании логика выражается без указания потока управления.
Ответом на проблемы сквозной разработки, развертывания, мониторинга и обслуживания конвейера данных является использование парадигмы декларативного программирования, то есть абстрагирование логики вычислений. На практике этого лучше всего достичь с помощью Terraform от HashiCorp — проекта с открытым исходным кодом, который представляет собой инструмент разработки инфраструктуры как кода.
Поскольку современная архитектура приложений с интенсивным использованием данных очень похожа на стек данных, на котором работают приложения, Terraform предоставляет платформу, которая сделает ваш стек данных декларативным, воспроизводимым и модульным.
Давайте вернемся к нашему примеру запуска анализа данных, описанному выше, чтобы более подробно прояснить эти концепции. Представьте, что ваше приложение для анализа данных — это веб-приложение, которое выполняется внутри Terraform. Как и ожидалось, наиболее важной частью приложения является база данных ClickHouse.
Мы должны построить два конвейера данных для передачи данных ETL из системы CRM, хранящихся в базе данных PostgreSQL, в базу данных ClickHouse, преобразовывая и обогащая данные перед их загрузкой в ClickHouse. Второй конвейер извлекает данные о погоде в реальном времени из местной метеорологической службы через API и преобразует их, гарантируя отсутствие ошибок и дополняя их, перед загрузкой в ClickHouse.
Использование Terraform для кодирования конвейеров данных
Классическая инфраструктура для современных облачных приложений выглядит так:
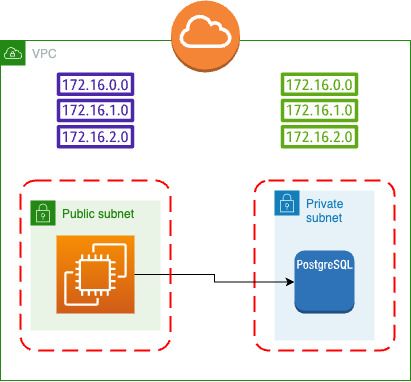
Это чрезмерное упрощение, но более или менее надежный способ создания приложений.
У вас есть общедоступная подсеть с пользовательским API/UI, которая подключена к частной подсети, в которой хранятся данные.
Чтобы упростить задачу, давайте посмотрим, как использовать Terraform для создания первого конвейера данных — для передачи данных ETL из вашей системы РСУБД (в данном случае PostgreSQL) в базу данных ClickHouse.
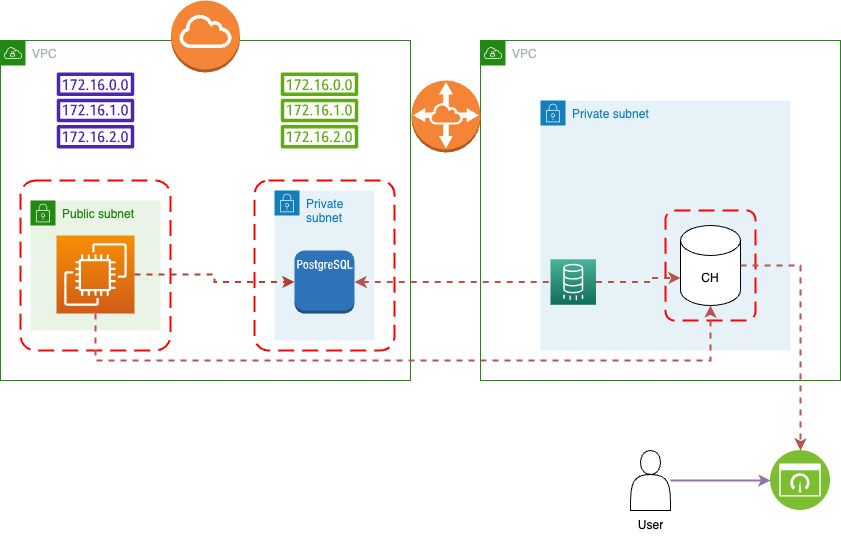
На этой диаграмме визуализирован конвейер данных, который ELT передает данные из базы данных RDBMS в базу данных ClickHouse, а затем представляет их как соединение со службой визуализации.
Этот рабочий процесс должен быть воспроизводимым, поскольку в архитектуре информационных технологий вашей компании имеется как минимум три среды: разработка, контроль качества и производство.
Войдите в Терраформ.
Давайте посмотрим, как реализовать этот конвейер данных в Terraform:
:::информация Лучше всего разрабатывать модульный код, сокращенный до мельчайших единиц, который можно многократно использовать повторно.
:::
Первый шаг — начать с файла main.tf, содержащего только определение поставщика.
provider "doublecloud" {
endpoint = "api.double.cloud:443"
authorized_key = file(var.dc-token)
}
provider "aws" {
profile = var.profile
}
nВторым шагом является создание сети BYOA:
data "aws_caller_identity" "self" {}
data "aws_region" "self" {}
# Prepare BYOC VPC and IAM Role
module "doublecloud_byoc" {
source = "doublecloud/doublecloud-byoc/aws"
version = "1.0.2"
providers = {
aws = aws
}
ipv4_cidr = var.vpc_cidr_block
}
# Create VPC to peer with
resource "aws_vpc" "peered" {
cidr_block = var.dwh_ipv4_cidr
provider = aws
}
# Get account ID to peer with
data "aws_caller_identity" "peered" {
provider = aws
}
# Create DoubleCloud BYOC Network
resource "doublecloud_network" "aws" {
project_id = var.dc_project_id
name = "alpha-network"
region_id = module.doublecloud_byoc.region_id
cloud_type = "aws"
aws = {
vpc_id = module.doublecloud_byoc.vpc_id
account_id = module.doublecloud_byoc.account_id
iam_role_arn = module.doublecloud_byoc.iam_role_arn
private_subnets = true
}
}
# Create VPC Peering from DoubleCloud Network to AWS VPC
resource "doublecloud_network_connection" "example" {
network_id = doublecloud_network.aws.id
aws = {
peering = {
vpc_id = aws_vpc.peered.id
account_id = data.aws_caller_identity.peered.account_id
region_id = var.aws_region
ipv4_cidr_block = aws_vpc.peered.cidr_block
ipv6_cidr_block = aws_vpc.peered.ipv6_cidr_block
}
}
}
# Accept Peering Request on AWS side
resource "aws_vpc_peering_connection_accepter" "own" {
provider = aws
vpc_peering_connection_id = time_sleep.avoid_aws_race.triggers["peering_connection_id"]
auto_accept = true
}
# Confirm Peering creation
resource "doublecloud_network_connection_accepter" "accept" {
id = doublecloud_network_connection.example.id
depends_on = [
aws_vpc_peering_connection_accepter.own,
]
}
# Create ipv4 routes to DoubleCloud Network
resource "aws_route" "ipv4" {
provider = aws
route_table_id = aws_vpc.peered.main_route_table_id
destination_cidr_block = doublecloud_network_connection.example.aws.peering.managed_ipv4_cidr_block
vpc_peering_connection_id = time_sleep.avoid_aws_race.triggers["peering_connection_id"]
}
# Sleep to avoid AWS InvalidVpcPeeringConnectionID.NotFound error
resource "time_sleep" "avoid_aws_race" {
create_duration = "30s"
triggers = {
peering_connection_id = doublecloud_network_connection.example.aws.peering.peering_connection_id
}
}
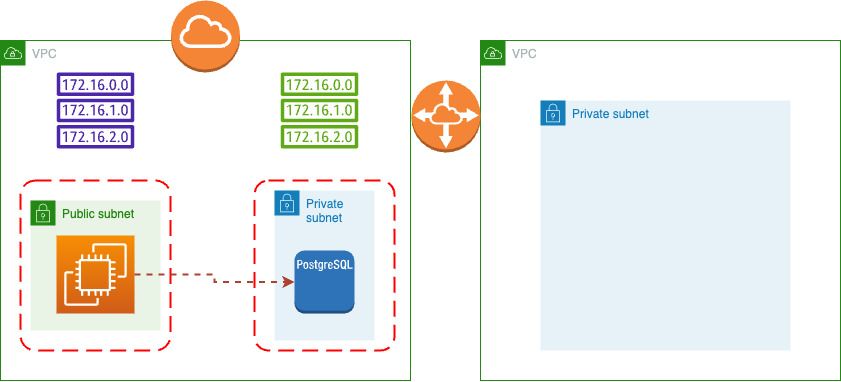
n Это подготовка нашей сцены к последующим кластерам. Архитектура после применения terraform выглядит следующим образом:
Подготовив этап, мы можем создать кластер в этой частной подсети:
resource "doublecloud_clickhouse_cluster" "alpha-clickhouse" {
project_id = var.dc_project_id
name = "alpha-clickhouse"
region_id = var.aws_region
cloud_type = "aws"
network_id = doublecloud_network.aws.id
resources {
clickhouse {
resource_preset_id = "s1-c2-m4"
disk_size = 34359738368
replica_count = 1
}
}
config {
log_level = "LOG_LEVEL_TRACE"
max_connections = 120
}
access {
ipv4_cidr_blocks = [
{
value = doublecloud_network.aws.ipv4_cidr_block
description = "DC Network interconnection"
},
{
value = aws_vpc.tutorial_vpc.cidr_block
description = "Peered VPC"
},
{
value = "${var.my_ip}/32"
description = "My IP"
}
]
ipv6_cidr_blocks = [
{
value = "${var.my_ipv6}/128"
description = "My IPv6"
}
]
}
}
n Это добавлено в нашу сцену для простого кластера Clickhouse.
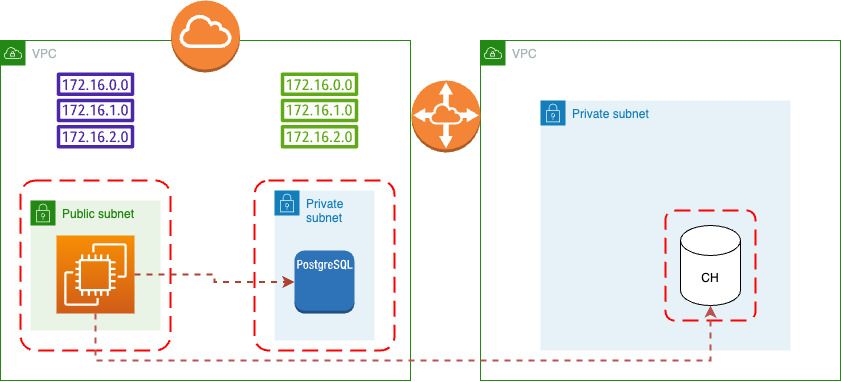
Но этот кластер по-прежнему пуст, поэтому мы должны включить передачу между PostgreSQL и ClickHouse:
resource "doublecloud_transfer_endpoint" "pg-source" {
name = "chinook-pg-source"
project_id = var.dc_project_id
settings {
postgres_source {
connection {
on_premise {
tls_mode {
ca_certificate = file("global-bundle.pem")
}
hosts = [
aws_db_instance.tutorial_database.address
]
port = 5432
}
}
database = aws_db_instance.tutorial_database.db_name
user = aws_db_instance.tutorial_database.username
password = var.db_password
}
}
}
data "doublecloud_clickhouse" "dwh" {
name = doublecloud_clickhouse_cluster.alpha-clickhouse.name
project_id = var.dc_project_id
}
resource "doublecloud_transfer_endpoint" "dwh-target" {
name = "alpha-clickhouse-target"
project_id = var.dc_project_id
settings {
clickhouse_target {
connection {
address {
cluster_id = doublecloud_clickhouse_cluster.alpha-clickhouse.id
}
database = "default"
user = data.doublecloud_clickhouse.dwh.connection_info.user
password = data.doublecloud_clickhouse.dwh.connection_info.password
}
}
}
}
resource "doublecloud_transfer" "pg2ch" {
name = "postgres-to-clickhouse-snapshot"
project_id = var.dc_project_id
source = doublecloud_transfer_endpoint.pg-source.id
target = doublecloud_transfer_endpoint.dwh-target.id
type = "SNAPSHOT_ONLY"
activated = false
}
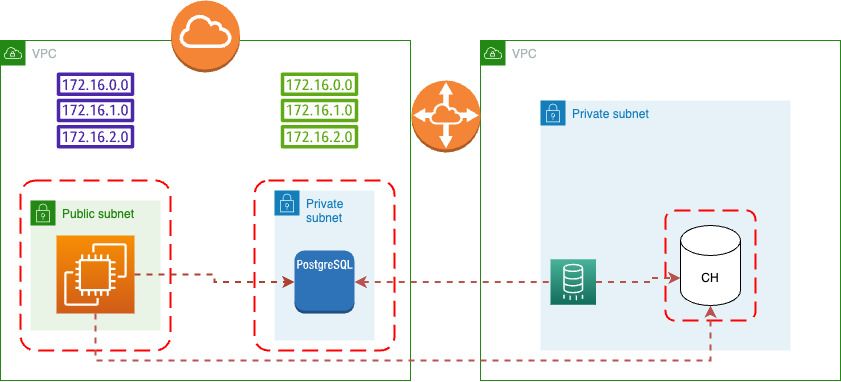
Это добавление процесса моментального снимка ELT между PostgreSQL и ClickHouse.
И наконец, мы можем добавить подключение к этому вновь созданному кластеру к сервису визуализации:
resource "doublecloud_workbook" "dwh-viewer" {
project_id = var.dc_project_id
title = "DWH Viewer"
config = jsonencode({
"datasets" : [],
"charts" : [],
"dashboards" : []
})
connect {
name = "main"
config = jsonencode({
kind = "clickhouse"
cache_ttl_sec = 600
host = data.doublecloud_clickhouse.dwh.connection_info.host
port = 8443
username = data.doublecloud_clickhouse.dwh.connection_info.user
secure = true
raw_sql_level = "off"
})
secret = data.doublecloud_clickhouse.dwh.connection_info.password
}
}
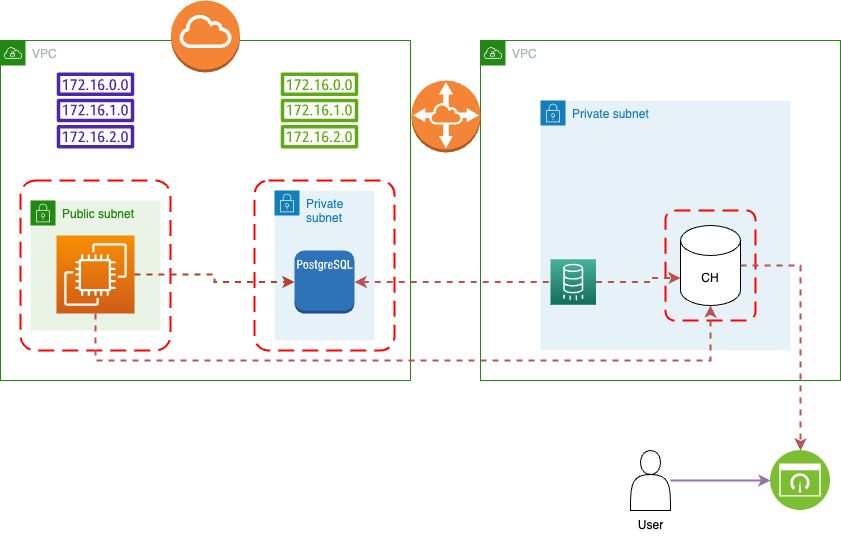
Как видите, большая часть кода состоит из переменных. Таким образом, выполнить этот код для настройки различных сред легко, добавив файл stage_name.tfvars и запустив с ним terraform apply:
:::информация См. документацию по Terraform для получения дополнительной информации о файлах .tvars.
:::
// This variable is to set the
// AWS region that everything will be
// created in
variable "aws_region" {
default = "eu-west-2" // london
}
// This variable is to set the
// CIDR block for the VPC
variable "vpc_cidr_block" {
description = "CIDR block for VPC"
type = string
default = "10.0.0.0/16"
}
// This variable holds the
// number of public and private subnets
variable "subnet_count" {
description = "Number of subnets"
type = map(number)
default = {
public = 1,
private = 2
}
}
// This variable contains the configuration
// settings for the EC2 and RDS instances
variable "settings" {
description = "Configuration settings"
type = map(any)
default = {
"database" = {
allocated_storage = 10 // storage in gigabytes
engine = "postgres" // engine type
engine_version = "15.4" // engine version
instance_class = "db.t3.micro" // rds instance type
db_name = "chinook" // database name
identifier = "chinook" // database identifier
skip_final_snapshot = true
},
"web_app" = {
count = 1 // the number of EC2 instances
instance_type = "t3.micro" // the EC2 instance
}
}
}
// This variable contains the CIDR blocks for
// the public subnet. I have only included 4
// for this tutorial, but if you need more you
// would add them here
variable "public_subnet_cidr_blocks" {
description = "Available CIDR blocks for public subnets"
type = list(string)
default = [
"10.0.1.0/24",
"10.0.2.0/24",
"10.0.3.0/24",
"10.0.4.0/24"
]
}
// This variable contains the CIDR blocks for
// the public subnet. I have only included 4
// for this tutorial, but if you need more you
// would add them here
variable "private_subnet_cidr_blocks" {
description = "Available CIDR blocks for private subnets"
type = list(string)
default = [
"10.0.101.0/24",
"10.0.102.0/24",
"10.0.103.0/24",
"10.0.104.0/24",
]
}
// This variable contains your IP address. This
// is used when setting up the SSH rule on the
// web security group
variable "my_ip" {
description = "Your IP address"
type = string
sensitive = true
}
// This variable contains your IP address. This
// is used when setting up the SSH rule on the
// web security group
variable "my_ipv6" {
description = "Your IPv6 address"
type = string
sensitive = true
}
// This variable contains the database master user
// We will be storing this in a secrets file
variable "db_username" {
description = "Database master user"
type = string
sensitive = true
}
// This variable contains the database master password
// We will be storing this in a secrets file
variable "db_password" {
description = "Database master user password"
type = string
sensitive = true
}
// Stage 2 Variables
variable "dwh_ipv4_cidr" {
type = string
description = "CIDR of a used vpc"
default = "172.16.0.0/16"
}
variable "dc_project_id" {
type = string
description = "ID of the DoubleCloud project in which to create resources"
}
В заключение…
Вот и все. Небольшой современный стек данных, который передает данные ETL из базы данных PostgreSQL в базу данных ClickHouse.
Лучшая новость заключается в том, что вы можете настроить несколько конвейеров данных — столько, сколько вам нужно — используя код в этом примере. Также вы можете найти полный пример здесь с дополнительными функциями, такими как добавление узла. подключение к существующему VPC и создание образца базы данных ClickHouse с передачей репликации между двумя базами данных.
Удачи вам, играя с вашим небольшим современным стеком данных!
Эта статья также опубликована на DZone .
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27683)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)