

Тестирование данных для конвейеров машинного обучения с использованием Deepchecks, DagsHub и GitHub Actions
17 мая 2022 г.Некоторое время назад я экспериментировал с объединением двух моих интересов: науки о данных и видеоигр. Для небольшого личного проекта я взял изображения из двух моих любимых игр GameBoy (Super Mario Land 2: 6 золотых монет и Wario Land: Super Mario Land 3) и создал классификатор изображений, определяющий, из какой игры это изображение. приходит. Было очень весело!
Но этот проект почти никогда не покидал Jupyter Notebook 🙈 И хотя лично мне нравятся Блокноты как инструмент структурированного повествования (и некоторых специальных экспериментов), такая установка имеет довольно много ограничений. Во-первых, создание любого проекта ML/DL — это итеративный процесс, часто с десятками или сотнями экспериментов. Каждый из них либо обрабатывает данные по-своему, добавляет некоторые новые функции, использует другую модель и ее гиперпараметры и т. д.
Как отследить все это? Мы могли бы создать электронную таблицу и вручную записать все детали. Но я уверен, что уже через несколько итераций это станет очень раздражающим и громоздким. И хотя это может сработать для некоторых пунктов, которые я упомянул, это не решит проблему с данными. Мы просто не можем так легко отслеживать данные и их преобразования в электронной таблице.
Вот почему на этот раз я хотел бы подойти к этому проекту по-другому, то есть использовать доступные инструменты, чтобы иметь правильно версионный (включая данные) проект с отслеживанием экспериментов и некоторыми проверками работоспособности данных. Звучит намного лучше, чем отслеживание экспериментов в электронной таблице, верно?
В этой статье я покажу вам, как использовать такие инструменты, как DagsHub, DVC, MLFlow и GitHub Actions, для создания полноценного проекта ML/DL. Мы рассмотрим следующие темы:
- знакомство с проектом,
- настройка репозитория с DagsHub,
- управление версиями данных с помощью DVC,
- отслеживание экспериментов с MLFlow,
- настройка автоматических проверок работоспособности данных с помощью GitHub Actions и Deepchecks.
Давайте прыгнем прямо в это!
Описание Проекта
Как я уже упоминал во введении, мы попытаемся решить задачу классификации бинарных изображений. Когда я ранее работал над этим проектом, я сравнил производительность модели логистической регрессии с производительностью сверточной нейронной сети. В этом проекте мы реализуем последний с помощью keras.
Ниже вы можете найти пример изображений, с которыми мы будем работать.
Я не буду вдаваться в подробности с точки зрения получения данных, их обработки, построения CNN или даже оценки моделей, так как в прошлом я уже довольно подробно рассказывал об этом. Если вас интересуют эти части, пожалуйста, обратитесь к моим предыдущим статьям:
- [Часть I] (https://towardsdatascience.com/mario-vs-wario-image-classification-in-python-ae8d10ac6d63), описывающая получение данных, их предварительную обработку и обучение логистической регрессии и CNN в
keras,
- [Часть II] (https://towardsdatascience.com/mario-vs-wario-round-2-cnns-in-pytorch-and-google-colab-48b968cf4ace), описывающая обучение CNN в PyTorch.
Для подхода v2 к этой задаче классификации изображений мы используем следующую структуру проекта:
https://gist.github.com/erykml/fb7580867c9e859120c36c5508e0239f
Мы рассмотрим все элементы на протяжении всей статьи, а пока можем кратко упомянуть следующее:
- все данные хранятся в каталоге
data, а в каждом подкаталоге хранятся данные с разных этапов.
- скрытый каталог
.githubотвечает за рабочие процессы GitHub Actions.
- каталог
notebooksсодержит записные книжки, используемые для исследования, которые не имеют отношения к функциям проекта.
- каталог
srcсодержит всю кодовую базу проекта. Каждый сценарий охватывает отдельную часть конвейера.
requiremets.txtсодержит список необходимых библиотек для запуска проекта. «поэзия» могла бы работать так же хорошо.
Установка четкой структуры проекта, безусловно, помогает держать все в порядке и облегчает проведение экспериментов, которые изменяют только части всего конвейера. Мы могли бы еще кое-что добавить в структуру, но давайте не будем усложнять и сосредоточимся на других элементах настройки проекта. О некоторых возможных расширениях мы упомянем в конце статьи.
Настройка репозитория с DagsHub
В качестве первого строительного блока нашего проекта мы будем использовать [DagsHub] (https://dagshub.com/). В двух словах, это что-то вроде GitHub, но созданное специально для специалистов по данным и инженеров машинного обучения (в отличие от разработчиков программного обеспечения). На DagsHub мы можем легко размещать и версионировать не только наш код, но и наши данные, модели, эксперименты и т. д.
Возможно, сейчас вы думаете: «Звучит здорово, но нам нужно подписаться на еще один сервис, и, кроме того, вся наша кодовая база уже находится на GitHub». К счастью, это не проблема. Мы можем либо полностью мигрировать репозиторий, либо — что еще удобнее — отзеркалить уже существующий. Таким образом, мы можем продолжить работу, используя существующий репозиторий GitHub, и он будет отражаться в реальном времени на DagsHub. Для этого проекта мы будем использовать опцию зеркалирования репо — [основной репозиторий GitHub] (https://github.com/erykml/mario_vs_wario_v2) будет зеркально отражен в [этот на DagsHub] (https://dagshub.com /eryk.lewinson/mario_vs_wario_v2).
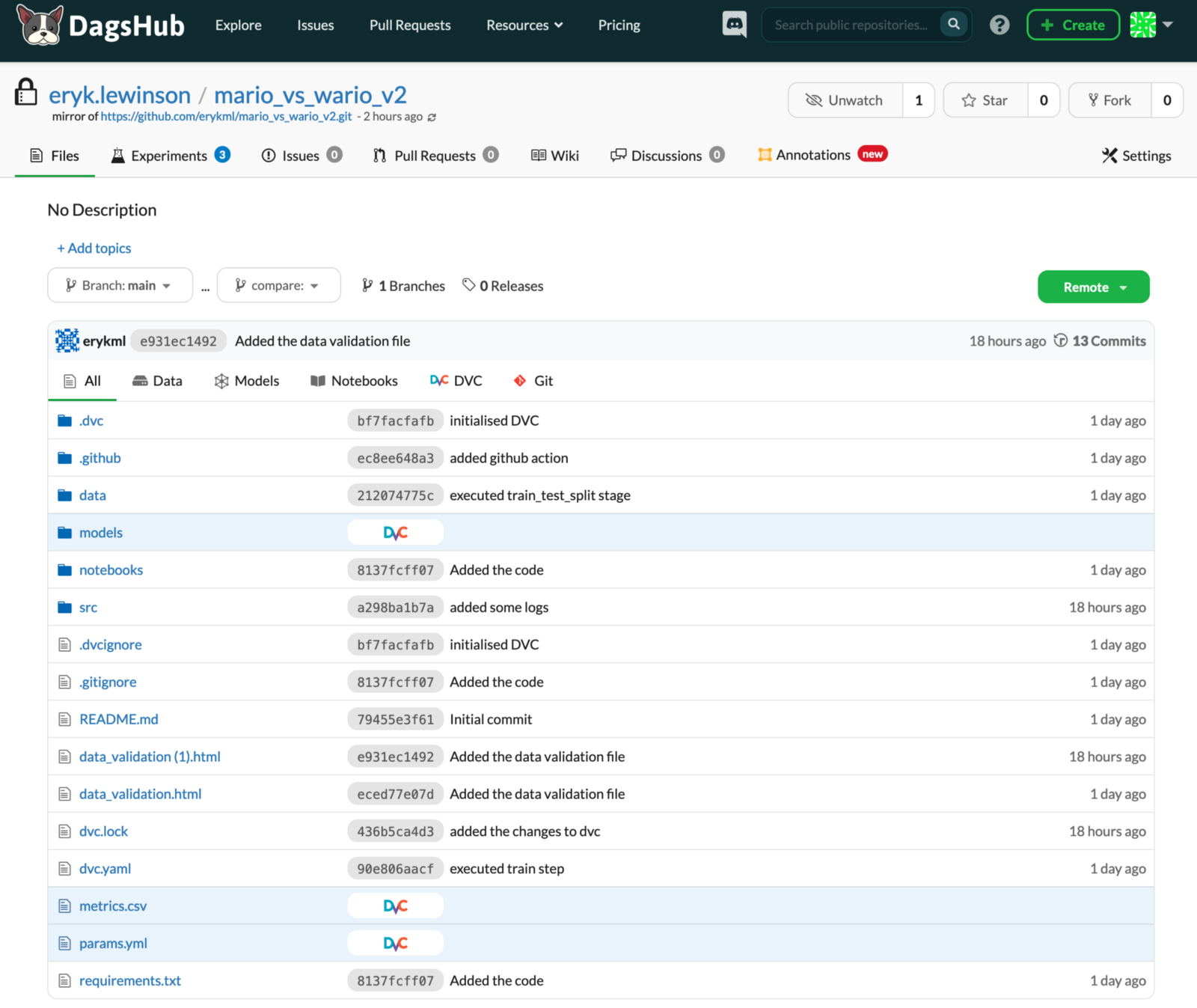
Как вы можете видеть на изображении ниже, пользовательский интерфейс DagsHub очень похож на пользовательский интерфейс GitHub. Таким образом, нам не нужно изучать еще один инструмент с нуля, так как с самого начала все кажется очень знакомым. На изображении ниже вы уже можете видеть, что есть несколько новых доступных вкладок (эксперименты, аннотации), и мы рассмотрим их позже. На изображении мы отображаем все файлы в репозитории, но мы можем легко их отфильтровать, например, чтобы отображались только Блокноты или файлы, отслеживаемые с помощью DVC.
Мы не будем охватывать все функции DagsHub, но также стоит упомянуть, что он предлагает следующее:
- аннотирование данных с помощью полностью интегрированного Label Studio, инструмента с открытым исходным кодом для маркировки структурированных и неструктурированных данных.
- комментирование и запуск обсуждений под всеми типами файлов.
- всестороннее сравнение (включая diff) любых файлов, которые может захотеть использовать специалист по данным. Пока данные хранятся в DagsHub, мы можем легко сравнивать блокноты, таблицы, файлы CSV, аннотации, различные виды метаданных и даже изображения.
Управление версиями данных с DVC
Вы наверняка уже знакомы с концепцией управления версиями кода с помощью Git. К сожалению, GitHub не так хорошо работает с данными, так как имеет ограничение на размер файла в 100 МБ. Это означает, что загрузка бинарного файла (или видеофайла в нашем случае) уже может превысить этот лимит. Вдобавок ко всему, сравнивать разные версии наборов данных любого рода тоже не самое приятное занятие. Вот почему нам нужен еще один инструмент для работы.
DVC (управление версиями данных) — это библиотека Python с открытым исходным кодом, которая по существу служит той же цели, что и Git (даже с тем же синтаксисом), но для данных вместо кода. Идея DVC заключается в том, что мы храним информацию о разных версиях наших данных в Git, а исходные данные хранятся где-то еще (в облачных хранилищах, таких как AWS, GCS, Google Drive и т. д.).
Для такой настройки требуется немного ноу-хау DevOps. К счастью, DagsHub может избавить нас от некоторых хлопот, поскольку каждая учетная запись DagsHub поставляется вместе с 10 ГБ бесплатного хранилища для DVC.
Во-первых, нам нужно установить библиотеку:
```javascript
пип установить dvc
Затем нам нужно создать экземпляр репозитория DVC:
```javascript
инициализация dvc
Выполнение этой команды создает 3 файла: .dvc/.gitignore, .dvc/config и .dvcignore. Вы можете найти больше информации о том, что они содержат [здесь] (https://dagshub.com/docs/experiment_tutorial/2_data_versioning/). Затем нам нужно подключить наш только что созданный репозиторий DVC к DagsHub. Как мы упоминали ранее, с помощью DagsHub нам не нужно вручную устанавливать подключение к облачному хранилищу. Единственное, что нам нужно сделать, это запустить следующие команды в терминале:
https://gist.github.com/erykml/b879e7f34f0c053b0be5c161240cad39
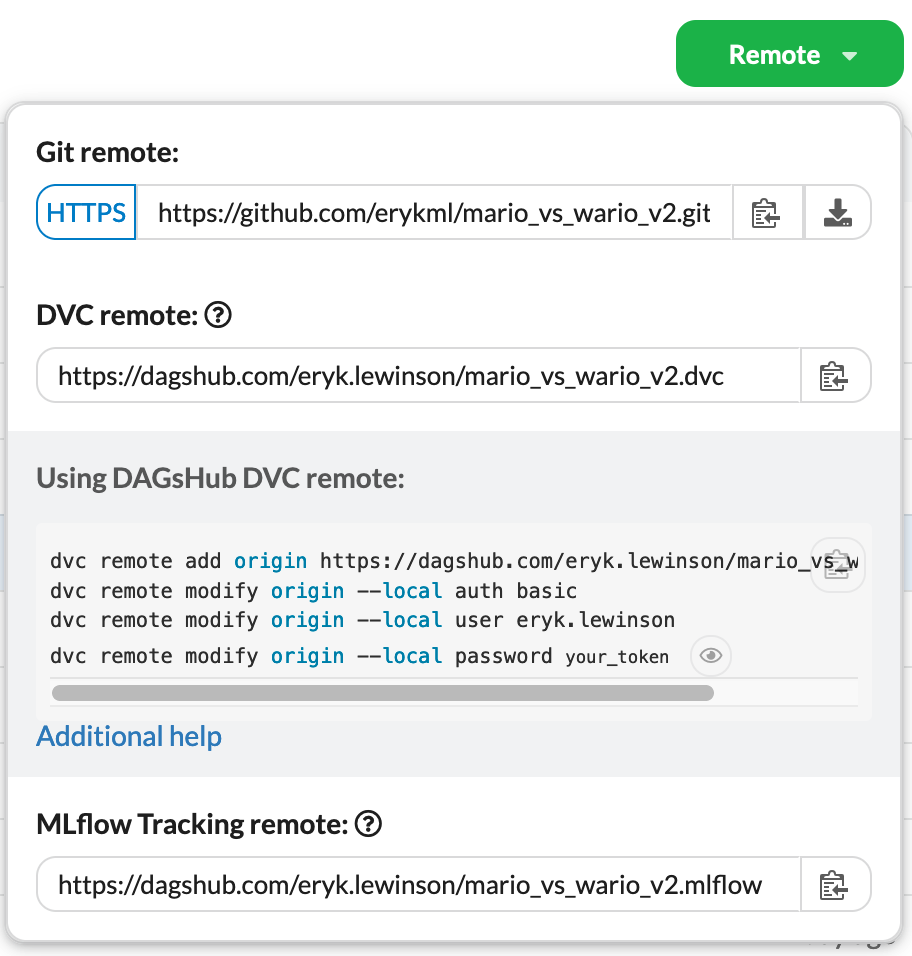
Чтобы сделать это еще проще, DagsHub предоставляет нам все это на вкладке Remote. Нам просто нужно скопировать их в терминал.
Подключившись к удалённому DVC, мы коммитим ранее упомянутые файлы в Git:
```javascript
git добавить.
git commit -m "Инициализированный DVC"
git push
Благодаря функции зеркалирования нам нужно только отправить наши файлы на GitHub, так как DagsHub автоматически синхронизирует оттуда все изменения.
Теперь пришло время построить полный конвейер, в котором выходные промежуточные данные отслеживаются DVC. Чтобы упростить процесс, мы создали отдельный файл .py для каждого шага конвейера. В нашем случае шаги следующие:
get_videos.py– загружает видео двух игр (полный геймплей, от начала до конца) с YouTube. Загруженные видео хранятся в каталоге data/videos.
extract_frames.py— извлекает изображения из видеофайлов mp4. Вывод сохраняется в каталогеdata/raw.
create_train_test_split.py– разделяет извлеченные изображения на обучающие и тестовые наборы. Результаты этого этапа сохраняются в каталоге data/processed.
train.py— обучает CNN классифицировать изображения. Выводит обученную модель в каталогmodels, а некоторые другие файлы (metrics.csvиparams.yml) в корневой каталог.
На основе этих шагов мы можем создать конвейер с помощью команды «dvc run». Для удобства чтения шаги разделены на 4 части, каждая из которых соответствует отдельной стадии конвейера. На практике вам не нужно коммитить и пушить после каждого шага. Мы сделали это для полной прозрачности и управляемости.
https://gist.github.com/erykml/22603287af4c546705c9b4afdc6b8918
Как видно из зафиксированных файлов, DVC сохраняет этапы конвейера в два файла: dvc.yaml (хранится в удобочитаемом формате) и dvc.lock (почти нечитаемый). При создании конвейера мы использовали следующие команды DVC:
-n- название этапа,
-d- зависимость стадии,
-о- выход этапа.
Ниже вы можете увидеть, как выглядит конвейер в файле YAML.
https://gist.github.com/erykml/1dee99105604343dad4d1b9801f1a874
DVC автоматически отследит все каталоги и файлы под outs.
Кроме того, DagsHub предлагает визуальный предварительный просмотр конвейера DVC. Вы можете найти его в списке файлов в репозитории. Как вы можете видеть ниже, это значительно упрощает понимание всего конвейера, чем чтение файла dvc.yml.
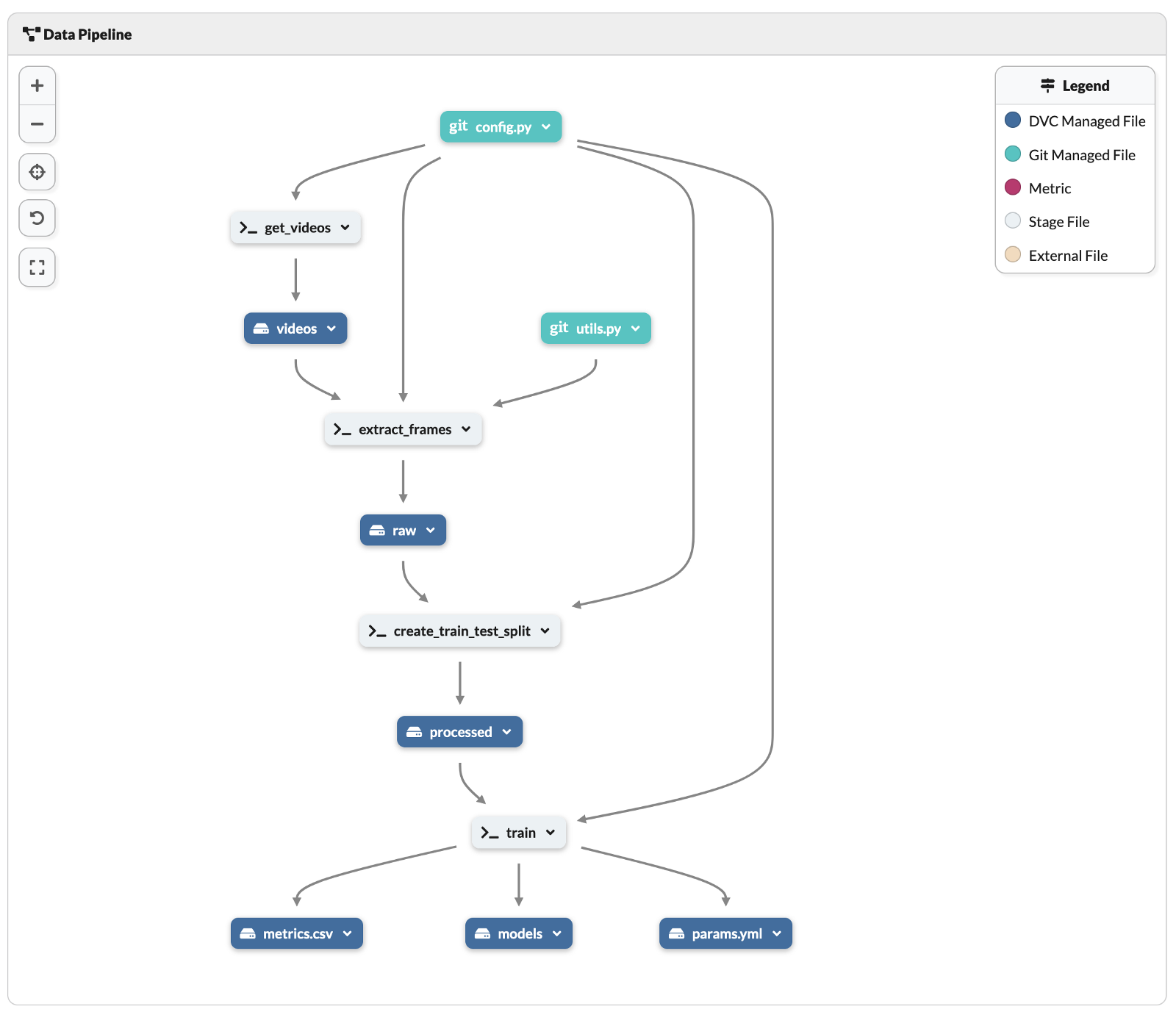
Определив весь конвейер DVC, мы можем использовать команду dvc repro, чтобы воспроизвести полный или частичный конвейер, выполнив этапы, определенные в dvc.yml.
Наконец, стоит упомянуть, что мы можем получить доступ и проверить все данные, хранящиеся с помощью DVC на DagsHub, включая некоторые метаданные. Вы можете увидеть пример ниже.

Отслеживание экспериментов с MLFlow
Следующим пунктом в нашем списке пожеланий для этого проекта является отслеживание экспериментов. Для этого мы будем использовать другую библиотеку с открытым исходным кодом — MLFlow (точнее, отслеживание MLFlow). С помощью функций MLFlow мы будем регистрировать довольно много подробностей о наших экспериментах, начиная с названия через гиперпараметры модели и заканчивая соответствующими оценками.
Как и в случае с DVC, нам также нужен сервер для размещения MFLow. И, как и прежде, этому также способствует DagsHub. Подробности, необходимые для аутентификации, можно найти на вкладке Remote в нашем репозитории DagsHub. После того, как мы настроим удаленный MLFlow, все наши эксперименты будут регистрироваться на вкладке Experiments в нашем репозитории DagsHub.
В приведенном ниже сценарии вы можете увидеть, как реализовать отслеживание с помощью MLFlow. Это сокращенная версия полного обучающего сценария, в котором исключены некоторые не очень важные элементы (создание генераторов данных, определение архитектуры НС и т. д.). Тем не менее, мы упомянем некоторые вещи о реализации MLFlow:
- в строках 7–9 мы подключились к удаленному MLFlow, предоставленному DagsHub,
- в строке 13 мы использовали автологгер MLFlow TensorFlow. Это удобный метод, который избавляет нас от необходимости вручную указывать все потенциальные гиперпараметры и другие характеристики модели. Такие автологгеры существуют практически для всех соответствующих библиотек ML/DL. См. [здесь] (https://mlflow.org/docs/latest/python_api/index.html) список.
- в строке 19 мы указали, что начинаем выполнение MLFlow — библиотека будет отслеживать вещи (указанные вручную или выбранные авторегистратором) в контексте выполнения (указывается с помощью оператора
with).
- в строках 45–54 мы вручную записывали некоторые параметры (размер изображений, скорость обучения и количество эпох) и метрики (потери и точность тестового набора). Хотя в этом явно не было необходимости (поскольку мы используем авторегистратор), мы хотели показать оба подхода.
https://gist.github.com/erykml/079b43c68ae3b1fb25fc3fe3fc5efc18
В качестве небольшого бонуса стоит упомянуть, что существует альтернативный, более легкий способ отслеживания экспериментов — с помощью Git и DagsHub. Для этого мы должны использовать библиотеку dagshub. В строках 36–43 мы показали, как регистрировать некоторые метрики и гиперпараметры с помощью библиотеки dagshub.
Регистратор dagshub создает два файла в корневом каталоге проекта (если не указано иное): metrics.csv и params.yml. Это два файла, которые мы указали на последнем шаге нашего конвейера DVC в качестве выходных данных скрипта train.py. Когда мы зафиксируем эти два файла в git, DagsHub автоматически распознает их и поместит их значения на вкладку Эксперименты. Мы можем легко найти их, глядя на эксперименты, отмеченные меткой Git в исходном столбце.
Самым большим преимуществом использования клиента «dagshub» является то, что эти эксперименты полностью воспроизводимы — «пока мы используем DVC для отслеживания данных, мы можем переключиться на состояние проекта во время завершения эксперимента с помощью одной команды «git checkout». . Такое тоже возможно с MLFlow, но не так просто.
Вы также можете написать свой собственный регистратор, который сочетает в себе лучшие из двух подходов к отслеживанию экспериментов. Вы можете найти пример [здесь] (https://gist.github.com/khuyentran1401/d1f295fe8088b8b0f8ac435a6302e8c7#file-logger-py).
Это все, что касается деталей реализации отслеживания экспериментов. Переходя к проверке некоторых результатов, на следующем изображении показано состояние, в котором эксперимент под названием мечтательный анкилостомид все еще выполнялся — мы видим, что точность и потери обновляются по мере обучения модели.
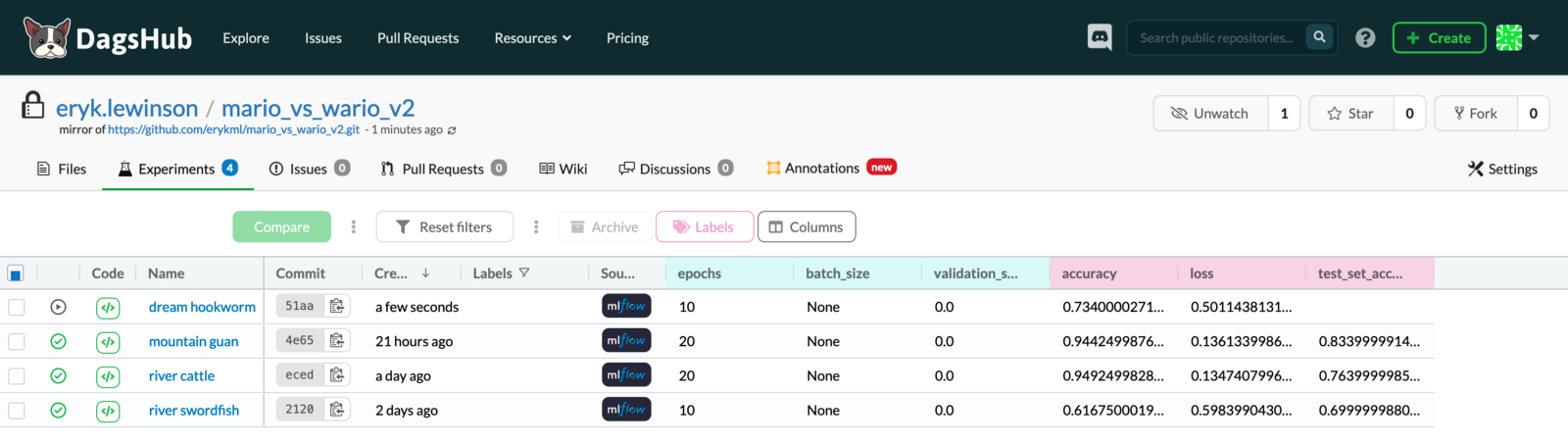
На вкладке Эксперименты мы можем отметить варианты, которые мы хотим сравнить, и нажать кнопку сравнить.
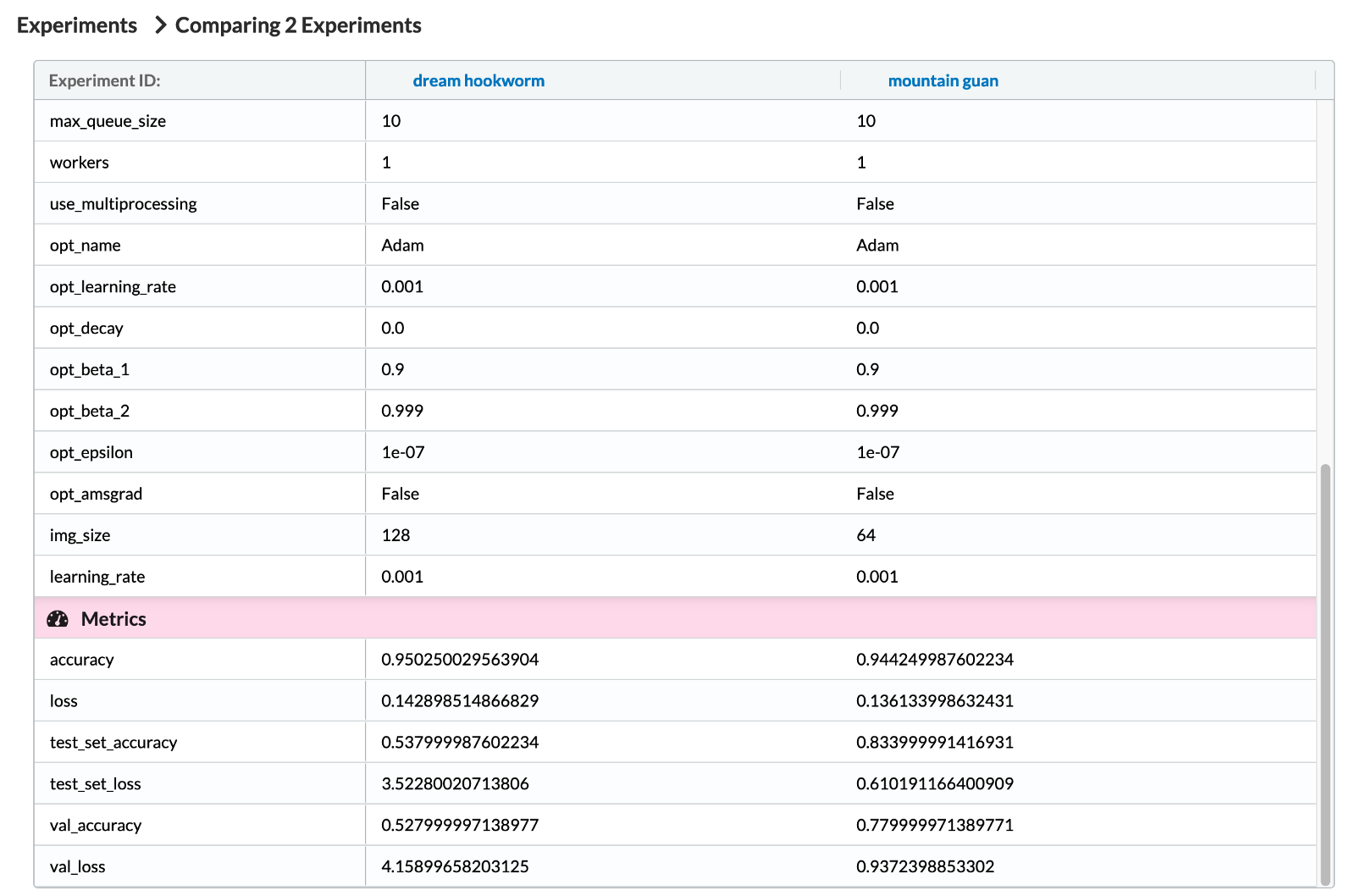
На следующем изображении мы видим некоторые гиперпараметры, отслеживаемые MLFlow. Как вы могли догадаться, мы видим так много гиперпараметров, потому что мы используем автологгер MLFlow TensorFlow. В конце списка также можно увидеть добавленный нами вручную гиперпараметр — «img_size». После этого мы можем увидеть соответствующие метрики.
Два анализируемых эксперимента отличаются двумя гиперпараметрами — количеством эпох и размером рассматриваемого изображения (размером квадратного изображения, передаваемого в первый слой НС). Вы также можете увидеть значения гиперпараметров и соответствующую точность тренировочного набора на следующем графике параллельных координат.
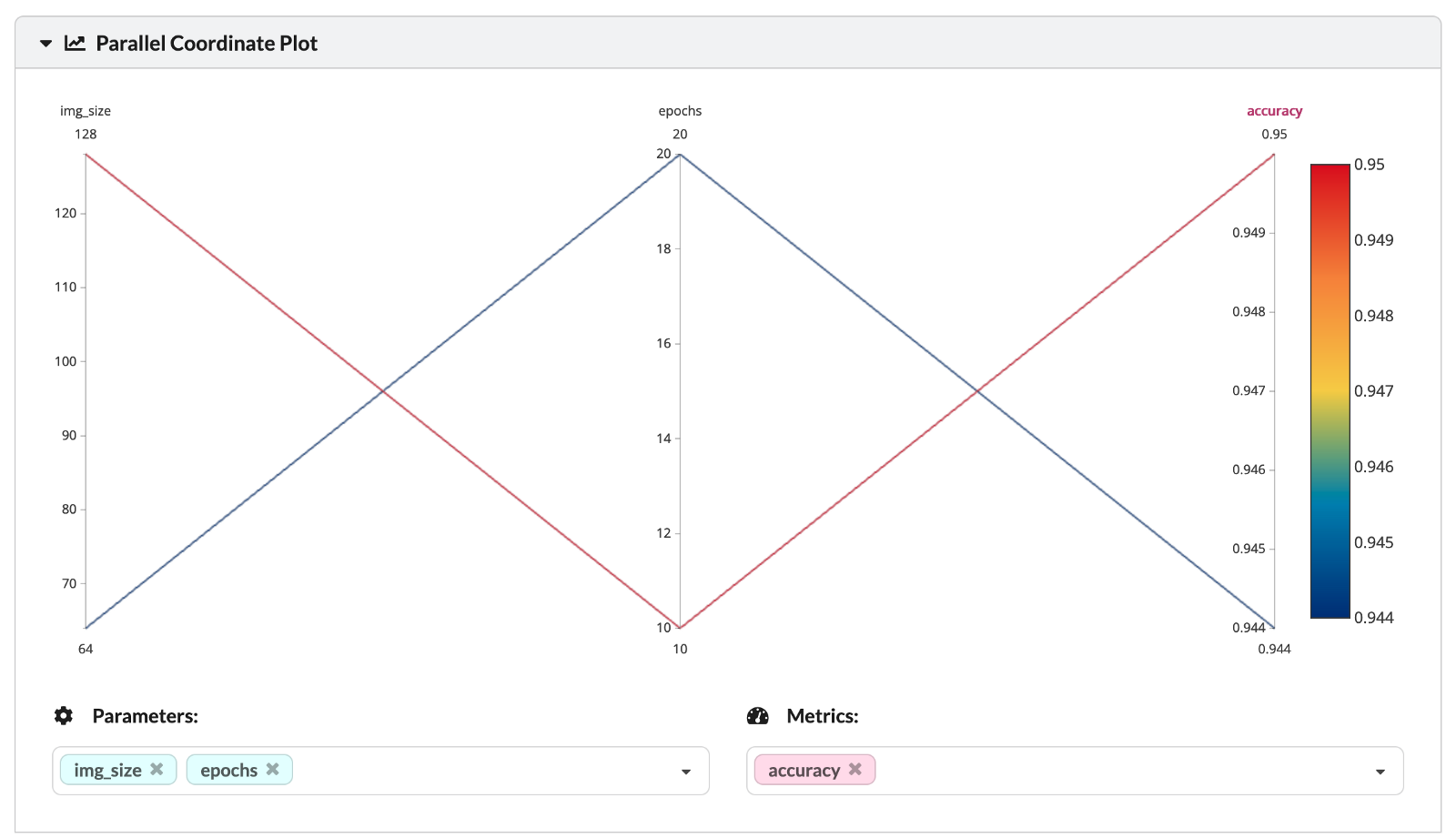
Наконец, мы можем еще глубже погрузиться в анализ различных показателей эффективности экспериментов.
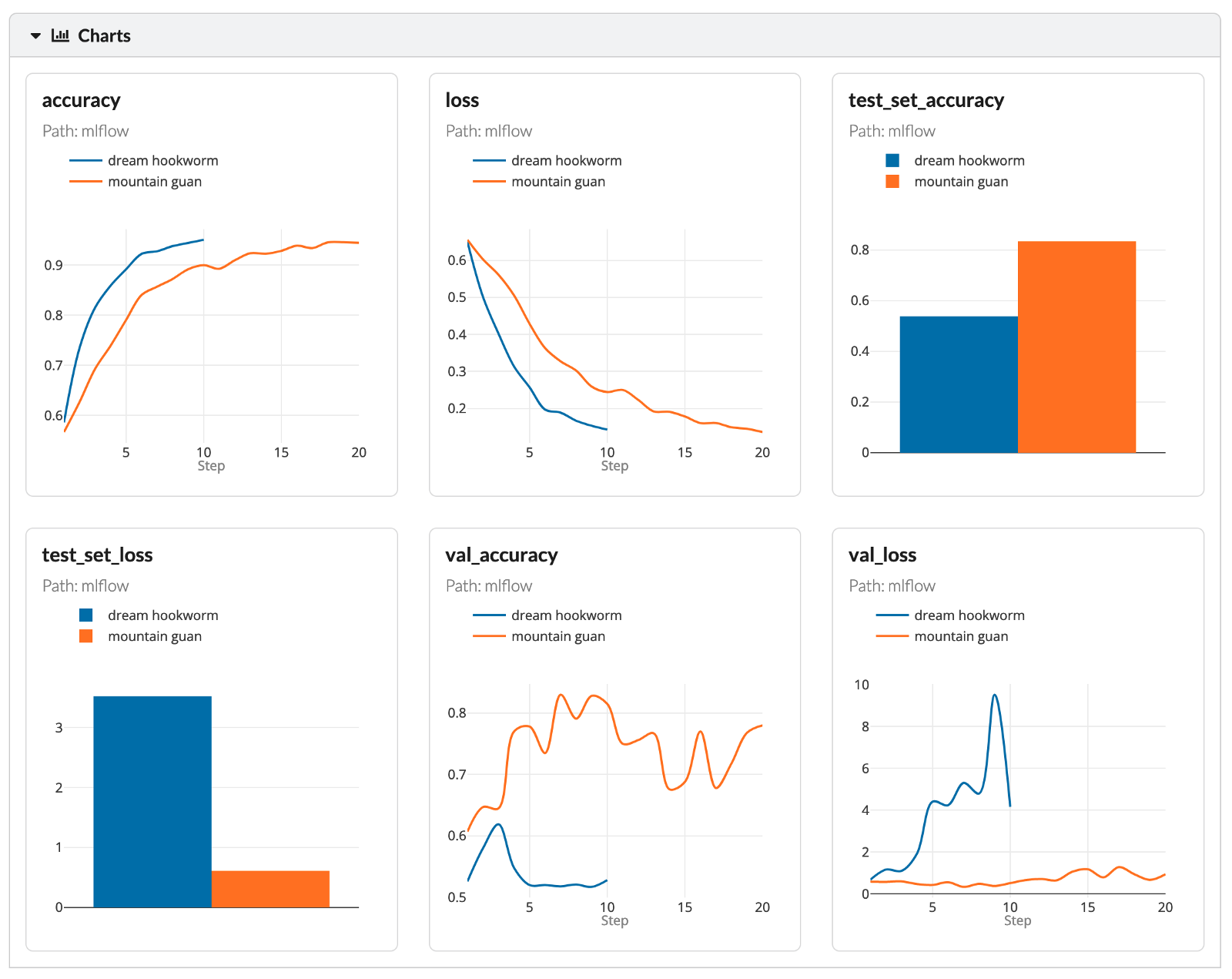
Поскольку цель этой части состояла в том, чтобы просто продемонстрировать функциональные возможности отслеживания MLFlow, мы не будем тратить больше времени на анализ результатов экспериментов.
Автоматизация проверки работоспособности данных с помощью GitHub Actions и Deepchecks
В качестве самого последнего шага нашего проекта мы хотели бы создать автоматические проверки работоспособности для наших данных. Давайте проиллюстрируем это на гипотетическом примере, который можно применить к нашему проекту. В таких видеоиграх, как рассмотренные (жанр платформеров с боковой прокруткой), подавляющее большинство времени тратится на то, чтобы пройти какой-то уровень или просто исследовать его. Мы видим, как наш главный герой бегает и что-то делает (в основном прыгает).
Однако, как и во всех играх, есть и другие экраны (меню, черно-белый переход или загрузочные экраны, конечные титры и т. д.). Мы могли бы возразить, что их не следует включать в данные. Итак, давайте представим, что мы вручную просмотрели изображения и удалили те, которые посчитали неподходящими для нашей выборки данных. Это может вызвать вопрос: наши действия существенно изменили что-то в данных, например, баланс классов? Или, может быть, мы ввели какой-то другой уклон?
Это также может быть очень важно, когда некоторые из наших преобразований данных включают обрезку изображений — мы могли бы вырезать некоторые HUD (игровой жаргон, хедз-ап дисплей или просто строку состояния*)* из одного класса, оставив их там для Другие. Это привело бы к созданию классификатора, который просто проверяет, имеет ли этот конкретный пиксель значение X, а затем уверенно решает, из какой игры взято изображение.
Именно для такого сценария было бы здорово иметь некоторые автоматизированные проверки работоспособности данных. Мы покажем, как создавать их с помощью GitHub Actions и Deepchecks. Но сначала нам нужно ответить на несколько вспомогательных вопросов.
Что такое GitHub Actions?
[GitHub Actions] (https://github.com/features/actions) — это инструмент, используемый для автоматизации рабочих процессов программного обеспечения. Например, инженеры-программисты используют GitHub Actions для автоматизации таких действий, как слияние веток, обработка проблем, выполнение модульных или прикладных тестов и т. д.
Однако это не означает, что они бесполезны для специалистов по данным. Мы можем использовать GitHub Actions для многих вещей, в том числе:
- автоматизация ETL-процессов,
- проверка необходимости переобучения текущей модели,
- развертывание новой модели,
- запуск автоматизированных проверок работоспособности данных.
Некоторые вещи, которые следует помнить о действиях GitHub:
- поддерживает основные языки программирования, используемые для науки о данных: Python, R, Julia и др.
- бесплатно для общедоступных репозиториев и предлагает 2000 минут в месяц для частных репозиториев (для бесплатных учетных записей GitHub),
- отлично работает с основными облачными провайдерами,
- автоматические электронные письма при сбоях рабочего процесса,
- Машины GitHub Action не подходят для очень ресурсоемких задач, например, для обучения моделей глубокого обучения.
Что такое Deepchecks?
Короче говоря, «deepchecks» — это библиотека Python с открытым исходным кодом для тестирования моделей и данных ML/DL. Библиотека может помочь нам с различными потребностями в тестировании и проверке во всех наших проектах — мы можем проверять целостность данных, проверять распределения, подтверждать допустимые разделения данных (например, разделение обучения/тестирования) и оценивать производительность нашей модели, и более!
Действия GitHub + Глубокие проверки
На данный момент пришло время объединить два строительных блока, чтобы автоматически генерировать отчет о достоверности данных каждый раз, когда мы вносим какие-либо изменения в кодовую базу.
Во-первых, мы создаем скрипт, генерирующий отчет о достоверности данных с помощью «глубоких проверок». Мы будем использовать набор библиотеки по умолчанию (на жаргоне «deepchecks» это соответствует набору проверок), используемый для проверки правильности разделения обучения/тестирования. В настоящее время deepchecks предоставляет наборы для задач табличного и компьютерного зрения, однако компания также работает над вариантом NLP.
https://gist.github.com/erykml/248a6599236fab145e0ab5da4c35d90c
Кроме того, мы могли бы указать экземпляр подогнанной модели при использовании метода run. Однако на момент написания этой статьи deepchecks поддерживает модели scikit-learn и PyTorch. К сожалению, это означает, что наш keras CNN работать не будет. Но это, вероятно, изменится в ближайшем будущем, так как deepchecks все еще является относительно новой и постоянно развивающейся библиотекой. Запуск сценария приведет к созданию отчета в формате HTML в корневом каталоге.
Теперь пришло время запланировать запуск проверок работоспособности. К счастью, использовать GitHub Actions очень просто. Нам просто нужно добавить файл .yaml в каталог .github/workflows. В этом файле .yaml мы указываем такие вещи, как:
- название рабочего процесса
- триггером для рабочего процесса — может быть либо cron-расписание, либо, как в нашем случае, push или pull request в основную ветку
- разрешения рабочего процесса
- ОС, на которой будет выполняться рабочий процесс (Ubuntu, Windows или macOS) — для разных систем действуют разные цены в минутах!
- переменные env (используемые для хранения секретов), к которым мы хотим получить доступ. Чтобы использовать их, нам сначала нужно определить их в нашем репозитории GitHub. Для этого в репозитории перейдите в «Настройки» > «Безопасность» > «Секреты» > «Действия».
- шаги, которые должен выполнять рабочий процесс
https://gist.github.com/erykml/21c60f22655796b89859c2c02b1f9d73
Скрипт выполняет следующие шаги:
- Устанавливает экземпляр Python 3.10 в Ubuntu.
- Устанавливает зависимости из
requirements.txt.
- Извлекает данные из DVC — на этом этапе нам необходимо пройти аутентификацию с использованием имени пользователя и пароля (хранящихся как секреты GitHub Actions). Мы извлекаем данные только из этапа конвейера DVC, который генерирует разделение обучения/тестирования.
- Удаляет старый файл проверки, если он существует.
- Запускает скрипт, генерирующий отчет о проверке данных.
- Фиксирует файлы (используя действие шаблона:
stefanzweifel/git-auto-commit-action@v4).
- Добавляет комментарий (используя действие шаблона:
peter-evans/commit-comment@v1).
После фиксации этого файла на GitHub мы увидим наш новый рабочий процесс на вкладке Действия.
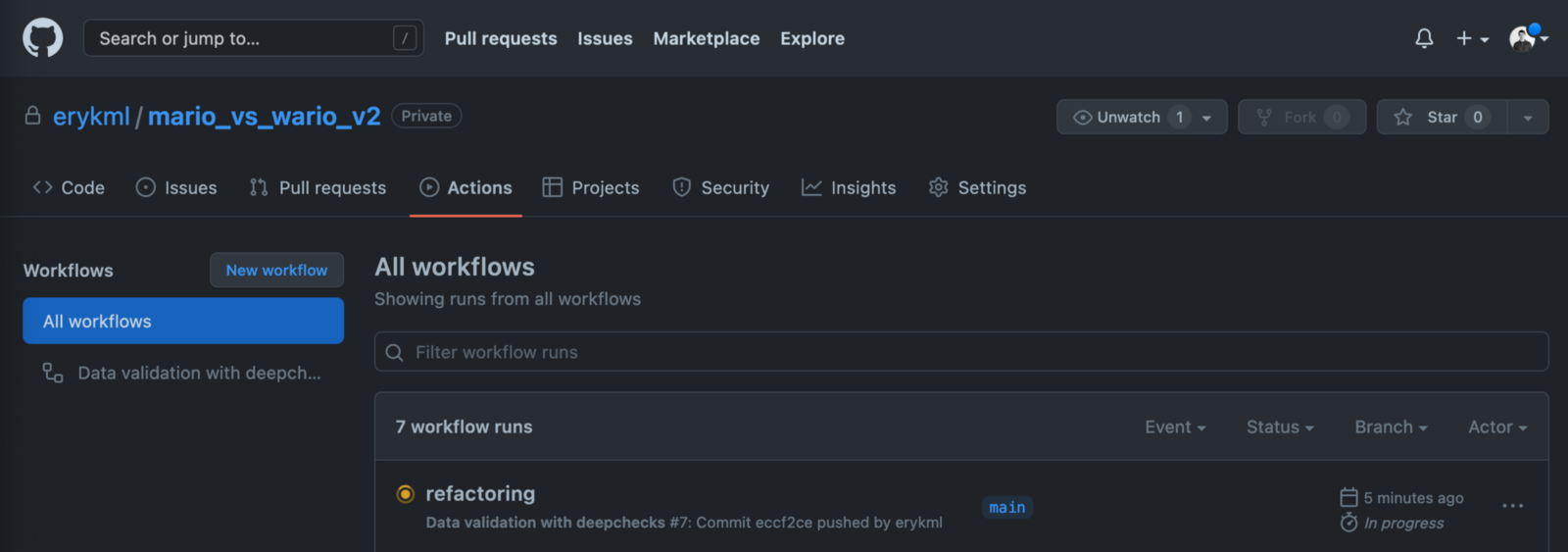
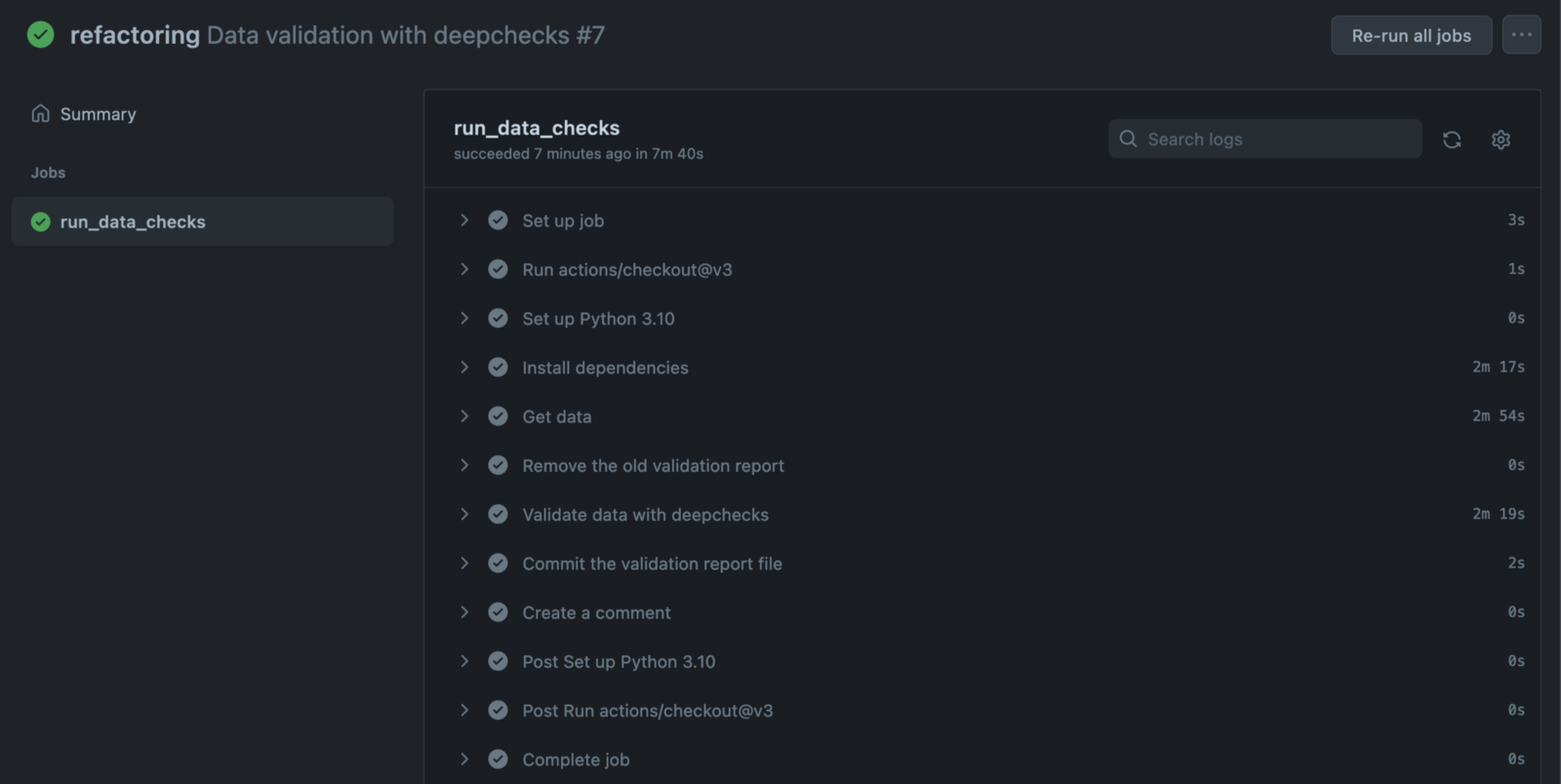
Мы можем погрузиться глубже, чтобы увидеть все этапы рабочего процесса вместе с подробными журналами. Они определенно пригодятся, когда что-то пойдет не так и нам нужно отладить конвейер.
После завершения рабочего процесса мы видим, что бот GitHub опубликовал комментарий к нашему коммиту.
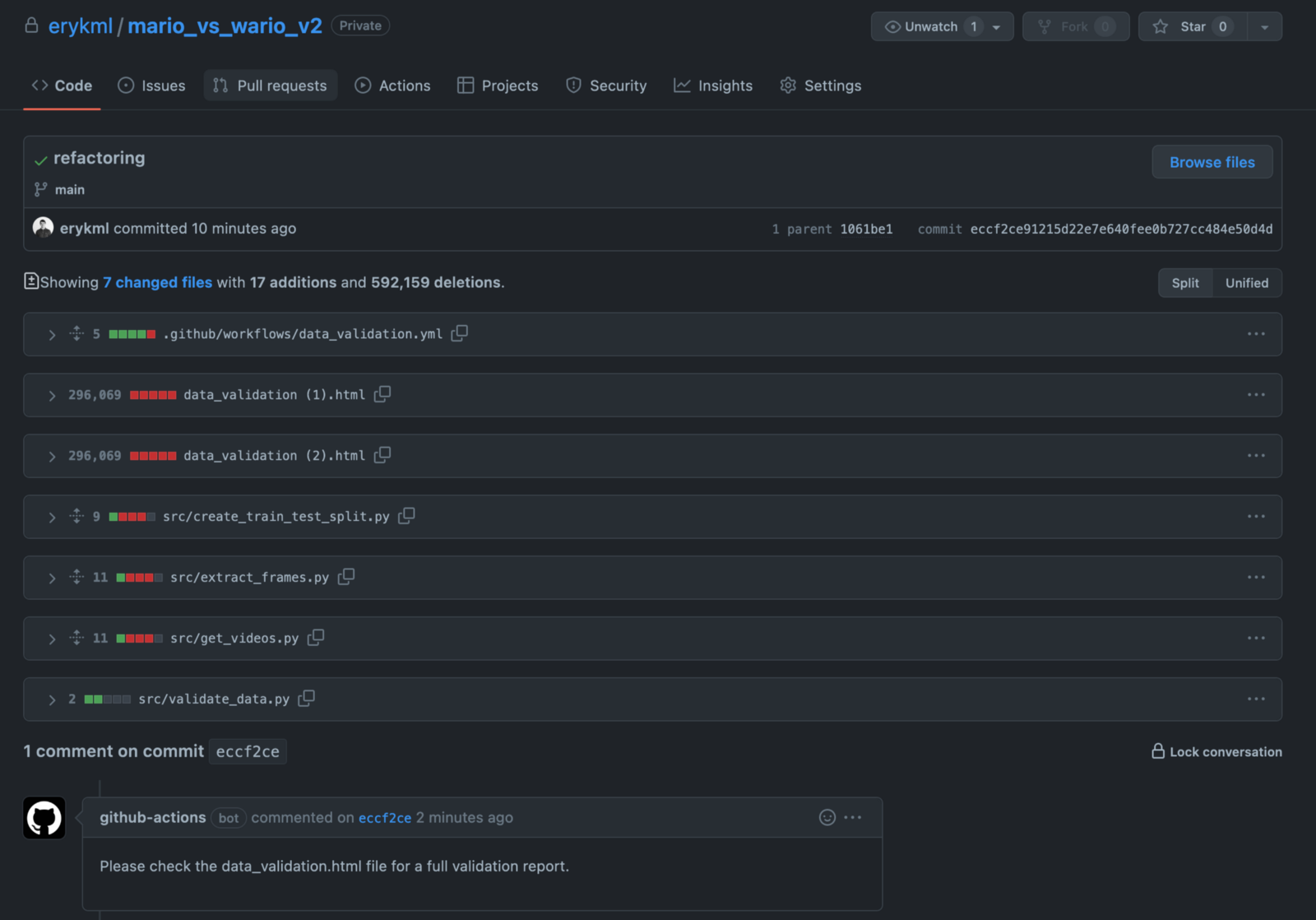
А теперь самое интересное — отчет data_validation.html мы можем найти в нашем репозитории. Он был автоматически добавлен и зафиксирован ботом GitHub. Чтобы иметь его локально, нам просто нужно извлечь из репо.
Для краткости мы представляем только некоторые части отчета о проверке данных. К счастью для нас, библиотека также генерирует полезные комментарии о проверках — что это такое и на что обращать внимание.
На первом изображении мы видим, что классы идеально сбалансированы. Это не должно вызывать удивления, учитывая, что именно так мы определили разделение.
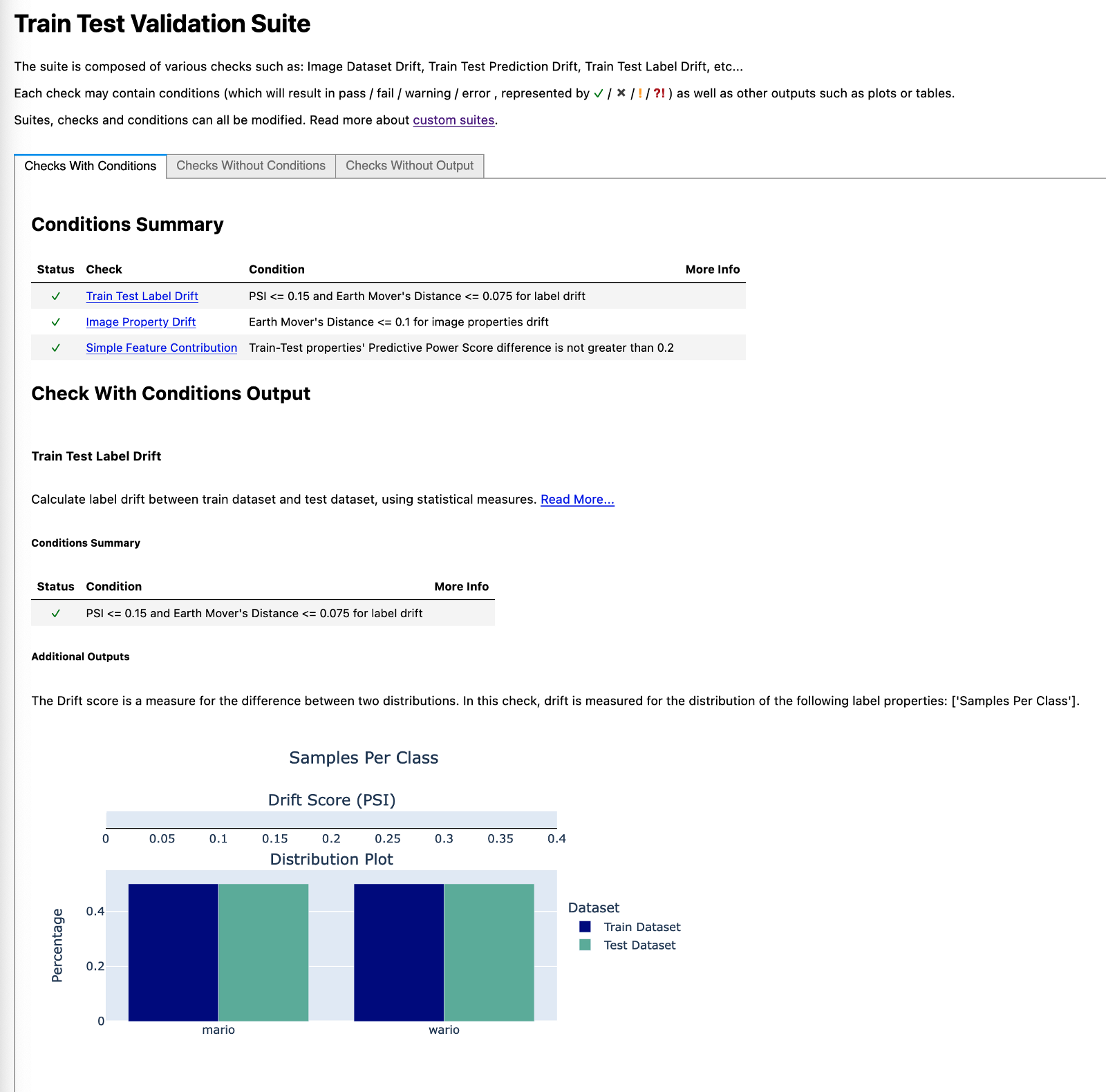
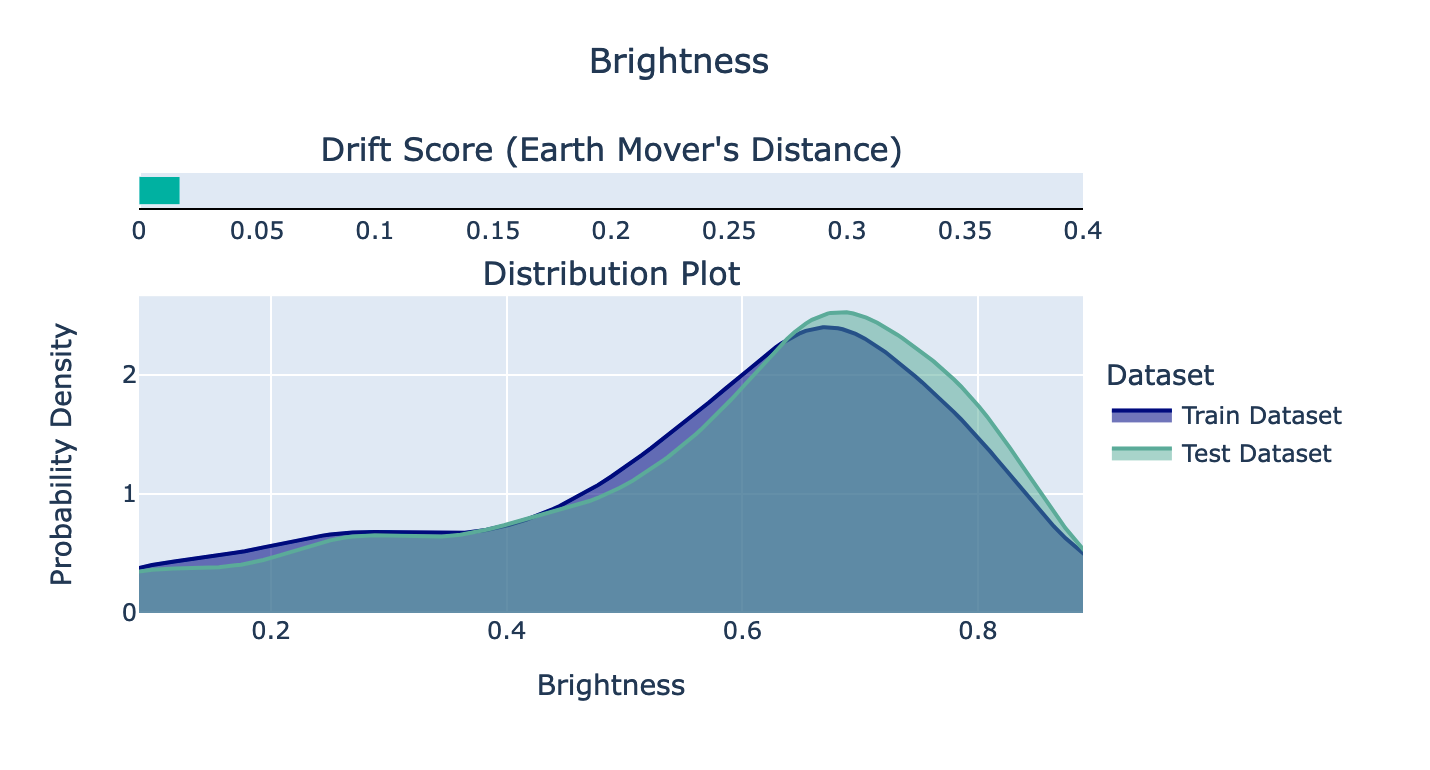
На втором изображении мы видим график распределения яркости изображений по поезду и тестовым наборам. Похоже, что раскол удался, так как они очень похожи. Согласно документации, было бы тревожно, если бы показатель дрейфа (расстояние Earth Mover) превышал 0,1.
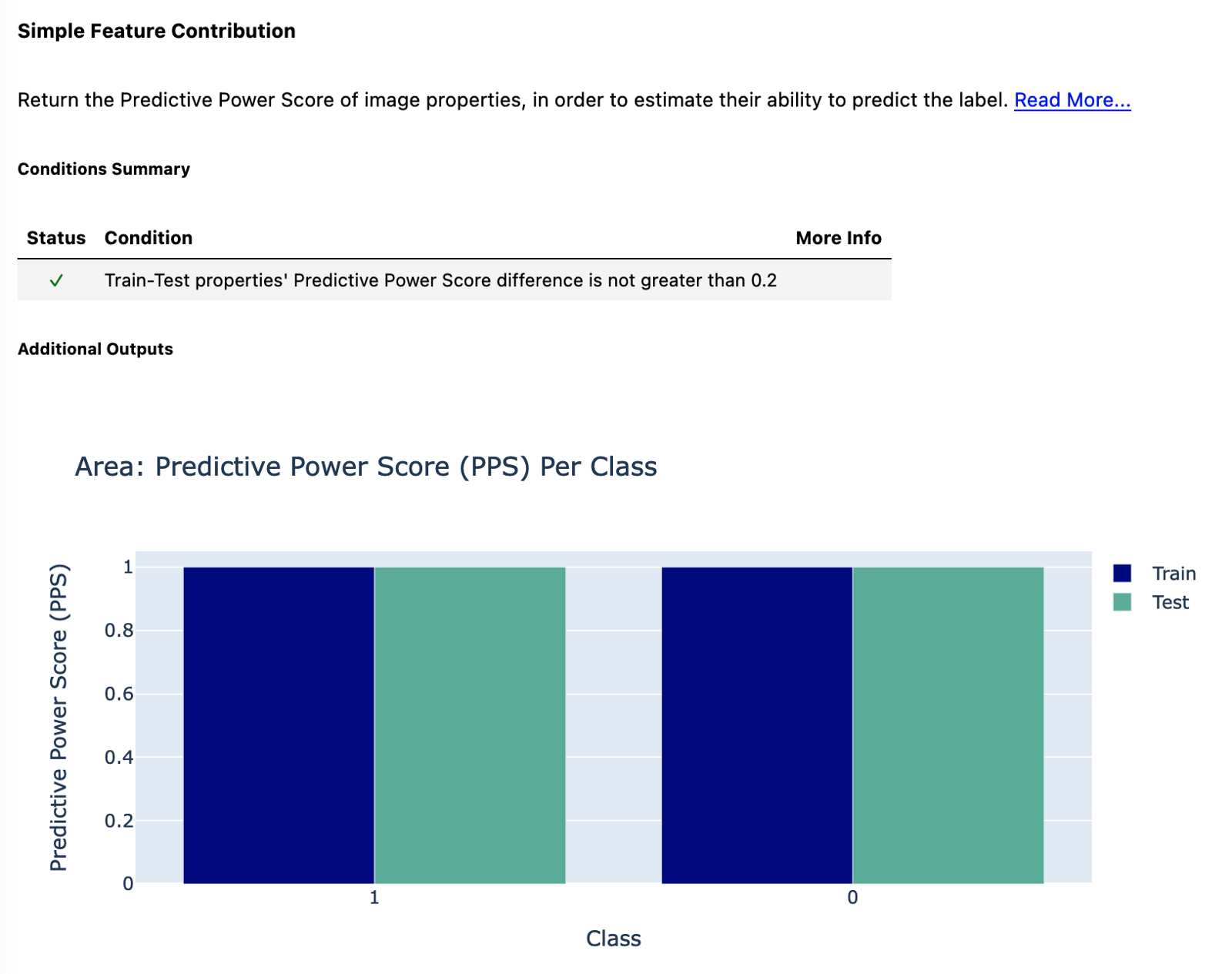
Наконец, мы смотрим на [Прогнозную оценку мощности] (https://towardsdatascience.com/rip-correlation-introduction-the-predictive-power-score-3d90808b9598) области изображения. Как видно из комментариев, разница в PPS должна быть не больше 0,2. Это условие выполняется, так как у нас идеальный PPS, равный 1, для всех классов и наборов данных. Это почему? Просто изображения из двух видеоигр имеют разный размер. Изображения из игры Mario имеют размер 160x144, а изображения Wario — 320x288 (в два раза больше). Вероятно, это как раз из-за того, что видео записывались с разными настройками эмулятора (изначально игры были для одной консоли, поэтому у них был одинаковый выходной размер). Хотя это означает, что мы можем использовать область изображения для точного предсказания класса, в реальной модели это не так, поскольку там мы изменяем форму изображений при их загрузке с помощью ImageDataGenerator.
Есть еще кое-что
Мы уже достаточно много рассмотрели в этой статье. От всего, что хранится в одном блокноте Jupyter, до полностью воспроизводимого проекта с управлением версиями данных и отслеживанием экспериментов. Сказав это, есть еще несколько вещей, которые мы могли бы добавить к нашему проекту. На ум приходят следующие:
- poetry — для улучшенного управления зависимостями.
- hydra — библиотека, используемая для управления конфигурационными файлами, то есть для доступа к параметрам, хранящимся в каком-либо конфигурационном файле, из скрипта Python. Это полезно, чтобы избежать жесткого кодирования определенных значений.
- pre-commit — мы могли бы настроить процесс автоматического форматирования кода Python с помощью средства форматирования по выбору (например, black), проверка стиля и качества кода (flake8), сортировка списков импорта (isort) и т. д.
- добавление модульных тестов для наших пользовательских функций.
Подведение итогов
В этой статье мы продемонстрировали современный подход к созданию проектов ML/DL с управлением версиями кода и данных, отслеживанием экспериментов и автоматизацией таких частей деятельности, как создание отчетов о проверке работоспособности данных. Это определенно требует больше работы, чем наличие одного Jupyter Notebook для всего, но дополнительные усилия быстро окупаются.
На этом этапе*,* я хотел поблагодарить службу поддержки DAGsHub за помощь с некоторыми вопросами.
Вы можете найти код, использованный для этой статьи, на моем GitHub или DagsHub. Также приветствуются любые конструктивные отзывы. Вы можете связаться со мной в Twitter.
Ресурсы
ДВК
МЛФлоу
Увеличение данных в Keras
Глубокие проверки
Действия на GitHub
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
15 наборов данных Excel для начинающих аналитиков данных
20 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27164)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)